요즘IT
위시켓
AIDP
콘텐츠
프로덕트 밸리
요즘 작가들
컬렉션
물어봐
놀이터
광고 상품
광고 상품
작가 지원
로그인
회원가입
콘텐츠
프로덕트 밸리
요즘 작가들
컬렉션
물어봐
놀이터
새로 나온
인기
개발
AI
IT서비스
기획
디자인
비즈니스
프로덕트
커리어
트렌드
스타트업
요즘 에디터의 추천 컬렉션
장대청
요즘 뜨는 인기 컬렉션
지금 회원가입하고 실무 꿀팁을 스크랩해 보세요.
회원가입
많이 스크랩된 콘텐츠
독자들의 성장을 이끈 문장
요즘 뜨는 작가
요즘IT 활용 백서
스크랩
다시 읽고 싶은 콘텐츠 꺼내보기
성장 습관
원하는 시간에 받는 신규 콘텐츠
슬랙봇
동료와 함께 읽고 싶을 때
물어봐 AI
일하다 막힐 때 바로 찾는 지식
에디터가 직접 고른 실무 인사이트 매주 목요일에 만나요.
0명 뉴스레터 구독 중
무료로 구독하기
전체 동의하기
개인정보 수집·이용 동의
(필수)
개인정보 마케팅 활용 동의
(선택)
마케팅 정보 수신 동의
(선택)
새로운 IT 소식은 여기서!
로그인
회원가입
요즘IT 소개
콘텐츠 제안하기
광고 상품 보기
4월 2주 인기
HTTP로 요청을 보냈을 때 서버에서는 어떻게 처리를 할까요? 서버에서는 HTTP 요청을 받아서 다양한 처리를 할 수 있는 프로그램을 실행시켜야 합니다. 클라이언트의 요청은 이미지 같은 파일일 수도 있고, 데이터 처리 작업일 수도 있습니다. 백엔드에서는 파일이나 이미지 같은 정적인 파일을 서비스하는 서버를 웹 서버, 데이터를 처리하는 서버를 WAS(Web Application Server)라고 부릅니다. 대표적인 웹 서버로 아파치(Apache)와 엔진엑스(Nginx)가 있으며 WAS로는 톰캣(Apache Tomcat), 웹스피어(WebSphere) 등이 있습니다.
누구도 알려주지 않는 백엔드 로드맵
HTTP와 더불어 함께 알아야 하는 것이 DNS(Domain Name System)입니다. IP는 인터넷에서 주소 역할을 합니다. IP는 총 32비트로 이루어진 IPv4와 128비트로 이루어진 IPv6가 있습니다. 보통 이런 주소값을 외우지는 않기 때문에 사람이 외우기 편한 언어로 된 주소를 사용하는데 이것이 도메인이고 이런 도메인 주소를 IP 주소로 변경하는 것이 DNS입니다.
누구도 알려주지 않는 백엔드 로드맵
배포는 개발하고 테스트가 완료된 코드를 서버에 전달(deploy)하고 실행하는 것을 의미합니다. 영어 음차 그대로 디폴로이라고도 부릅니다. 소스 코드를 배포해서 실행하는 경우도 있고, 자바처럼 jar과 같은 패키지 형태를 받아서 실행하는 경우도 있습니다. 컨테이너 환경(예: 도커, Docker)을 이용하면 개발과 실제 운영 서버의 환경을 동일하게 맞추어 테스트할 수 있습니다. 배포는 스크립트를 만들어서 배포하는 경우도 있으며, 컨테이너 환경의 경우 쿠버네티스(Kubernetes)라는 기술을 사용해 배포를 하기도 합니다.
누구도 알려주지 않는 백엔드 로드맵
이벤트 기반 아키텍처는 이벤트를 발생시키는 프로듀서(producer)와 이벤트를 전달하는 브로커(broker), 이벤트를 받는 컨슈머(consumer)로 구성됩니다. 이벤트 기반 아키텍처는 모든 요청을 비동기로 처리합니다. 그래서 확장성이 좋고 아키텍처 내 컴포넌트 간 의존성을 줄일 수 있습니다. 프로듀서, 브로커, 컨슈머 각각 수평 확장이 용이하기 때문입니다. 반면에 이벤트를 비동기로 처리하므로 이벤트 순서를 보장하기 어렵습니다. 에러 발생가 발생했을 때 이벤트를 새로 받을지, 무시할지, 에러 처리를 할지 고려해야 합니다.
누구도 알려주지 않는 백엔드 로드맵
요즘IT 멤버가 되어
형광펜
해보세요.
회원가입
1
멀티 AI 터미널 도구 3대장, 뭐가 다를까? 클로드코드 vs 코덱스CLI vs 제미나이CLI
AI
7분
인기
2
NEW
개발자를 위한 Claude Code 토큰 사용량 최적화 전략
AI
7분
3
NEW
클로드 코드와 MCP 연결로 디자인 감도 높이는 법
기획
7분
인기
4
NEW
20년 전 게임 ‘건즈 온라인’을 브라우저로 이식한 개발자
프로덕트
8분
14
개발자 필독서
제렘이
1.2K
4
21
5
바이브 코더스 인터뷰 모아보기
요즘AI
157
1
1
10
프로덕트 메이커 찐 트렌드
요즘프로덕트메이커
108
2
0
8
요즘IT도 광고해요
AD
요즘IT관리자
987
3
4
11
직무별 추천 도서
트파원
8.1K
14
70
11
[PICK] MCP 총정리: 개념과 사용기
호랑이
4.8K
8
51
22
회사에서 봐도 뭐라 안 하는 인기 글 모음
덕파
4.2K
2
15
8
요즘IT도 광고해요
AD
요즘IT관리자
987
3
4
103
CEO로서 도움되었던 자료들
꼼꼼한티동이315606
3.8K
29
56
14
트랜드를 가장 쉽게 얻는 방법, 뉴스레터 구독
제렘이
3.8K
9
28
18
포폴이야 이력서야?!? 포폴이야 이력서야!?!
자율적인티동이65882
3.6K
9
54
8
요즘IT도 광고해요
AD
요즘IT관리자
987
3
4
콘텐츠 AX, '프롬프트' 말고 '파일'을 보세요: 콘텐츠 AX 실험기 ②
AI
8분
요즘IT
스크랩
AI로 프로젝트 10개 만든 개발자가 서류에서 떨어지는 이유
개발
7분
개발자H
스크랩
“오늘 뭐부터 하지?” AI 비서 에이전트 만들어봤습니다
개발
문돌이 PM이 만든 AI 세션에 대기자 200명이 몰린 이유
AI
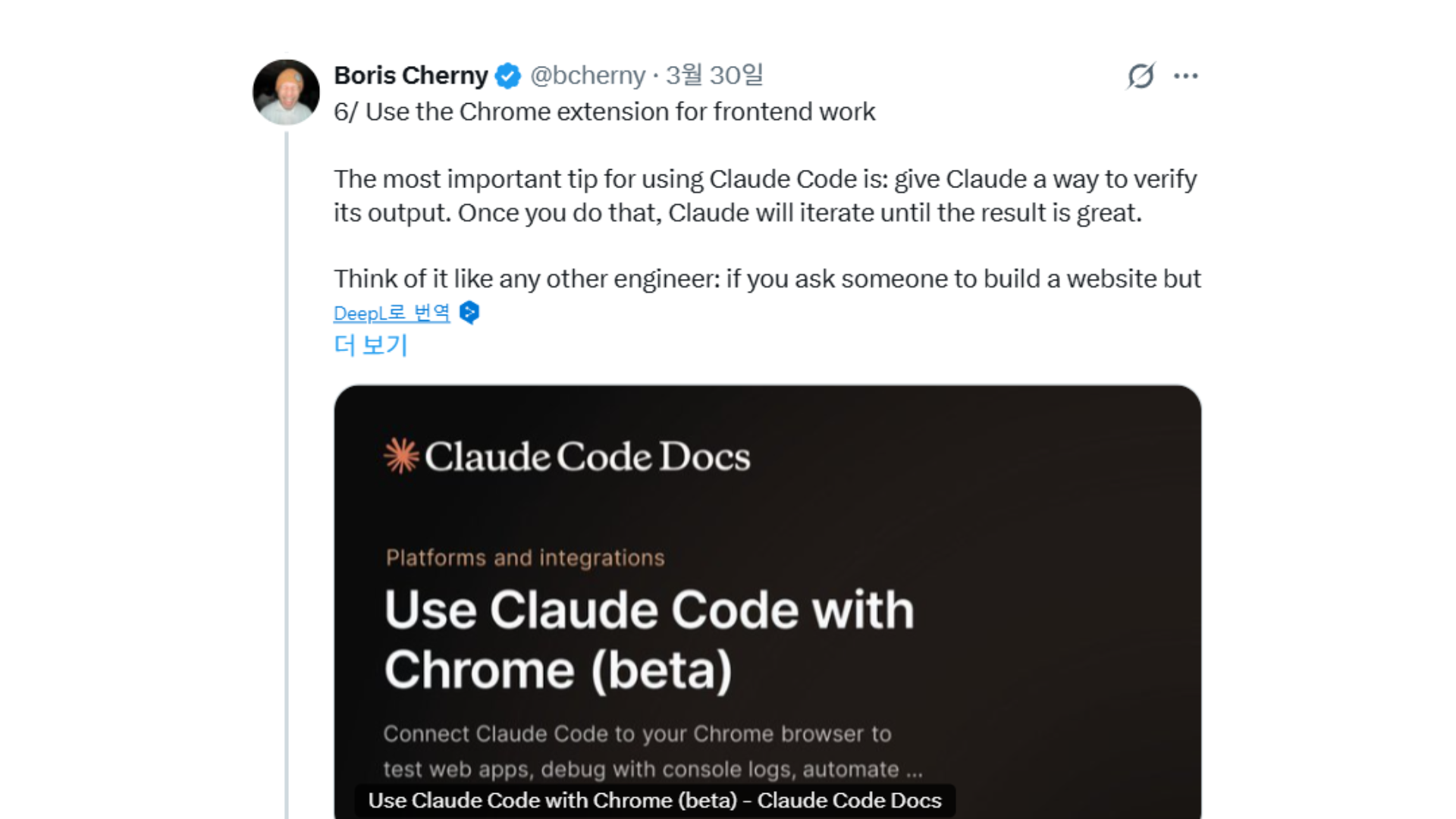
Claude Code를 만든 Boris Cherny가 직접 추천한 기능 15가지
프로덕트
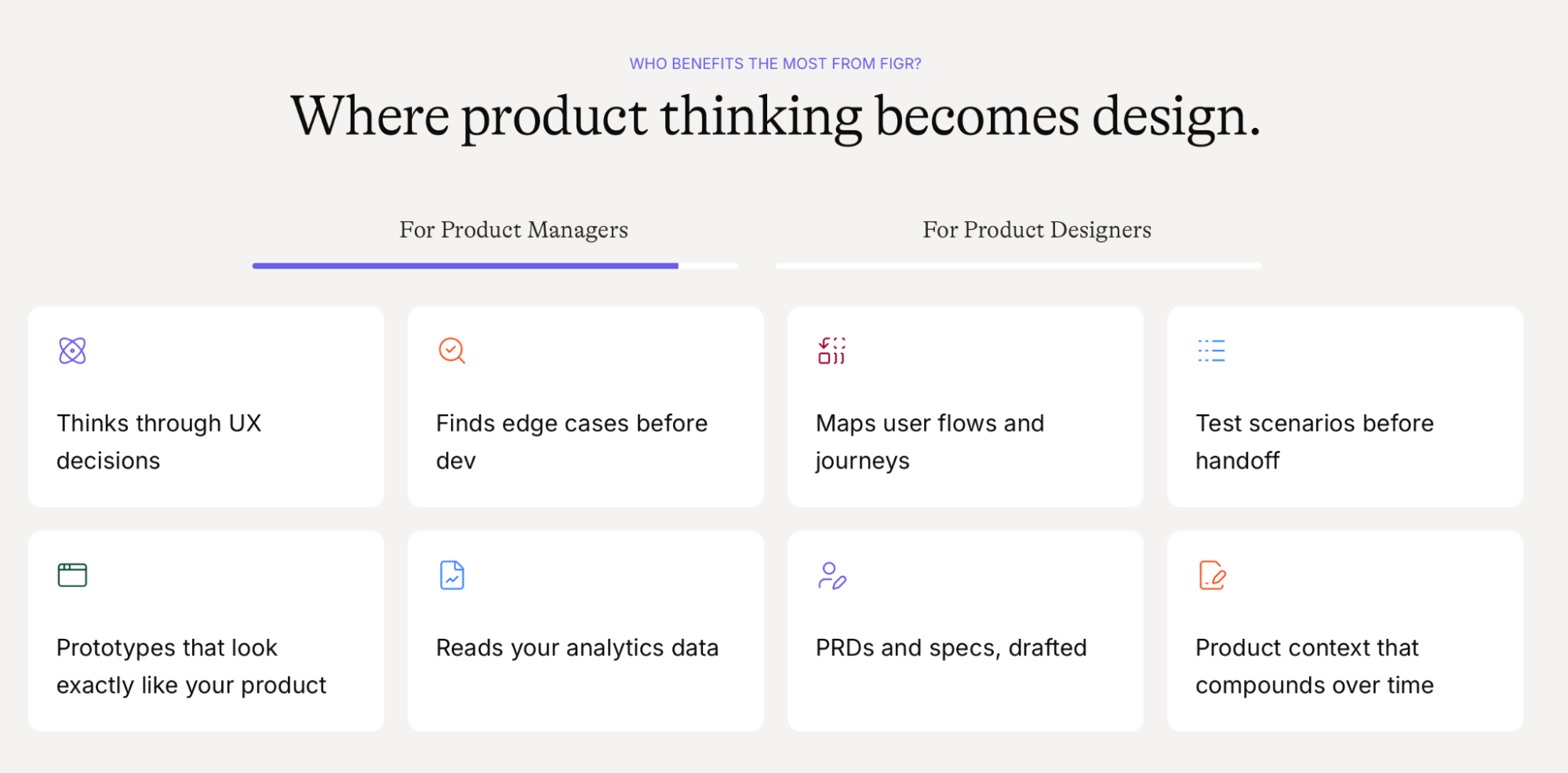
AI가 UX를 설계하는 방식: 화면보다 흐름이 먼저인 ‘Figr’
디자인
효율적인 디자인을 위한 크롬 확장 프로그램 7가지
디자인
오늘의 토픽
1
0
1
NEW
왜 우리는 아직도 AI에게 일을 제대로 못 시킬까?
AI
10분
인기
flamelet
스크랩
1
NEW
왜 우리는 아직도 AI에게 일을 제대로 못 시킬까?
AI
10분
인기
flamelet
스크랩
2
NEW
효율적인 디자인을 위한 크롬 확장 프로그램 7가지
디자인
8분
김태길
스크랩
2
NEW
효율적인 디자인을 위한 크롬 확장 프로그램 7가지
디자인
8분
김태길
스크랩
3
NEW
Claude Code를 만든 Boris Cherny가 직접 추천한 기능 15가지
프로덕트
9분
인기
요즘 프로덕트 메이커
스크랩
3
NEW
Claude Code를 만든 Boris Cherny가 직접 추천한 기능 15가지
프로덕트
9분
인기
요즘 프로덕트 메이커
스크랩
4
NEW
AI가 UX를 설계하는 방식: 화면보다 흐름이 먼저인 ‘Figr’
디자인
7분
지금 써보러 갑니다
스크랩
4
NEW
AI가 UX를 설계하는 방식: 화면보다 흐름이 먼저인 ‘Figr’
디자인
7분
지금 써보러 갑니다
스크랩
5
NEW
개발자를 위한 Claude Code 토큰 사용량 최적화 전략
AI
7분
길벗
스크랩
5
NEW
개발자를 위한 Claude Code 토큰 사용량 최적화 전략
AI
7분
길벗
스크랩
6
NEW
몰트북(Moltbook)의 성공에서 반드시 읽어야 할 3가지 포인트
프로덕트
10분
개발자H
스크랩
6
NEW
몰트북(Moltbook)의 성공에서 반드시 읽어야 할 3가지 포인트
프로덕트
10분
개발자H
스크랩
요즘IT
요즘IT가 주목한 이야기, 요즘IT가 일하는 이야기를 전합니다.
알림
콘텐츠 AX, '프롬프트' 말고 '파일'을 보세요: 콘텐츠 AX 실험기 ②
요즘IT 독자 선정 국내 1등 협업툴은 무엇이 다른가
더 보기
골든래빗
골든래빗은 쓰고 읽고 펴내면서 더 나은 나를 만드는 시간, 가치가 성장하는 시간이 되는 책을 만듭니다. 나눌수록 더 커지는 지식. 지식을 글로 정리하고, 나누는 책을 통해 더 큰 가치를 만들어갑니다. <개발자원칙> <처음부터 다시 배우는 서비스 디자인씽킹> <텐초의 파이토치 딥러닝 특강>등을 펴냈습니다. 홈페이지 : https://goldenrabbit.co.kr/
알림
문서 정리의 끝판왕 ‘PARA’ 시작하기(feat. 옵시디언)
아마존, 삼성전자 등 데이터 리더 9인 추천 도서 30권
더 보기
지금 써보러 갑니다
작지만 가치 있는 변화를 이끌어내는 서비스를 만들기 위해 노력하고 있습니다. 국내외 다채로운 IT 서비스와 트렌드를 살펴보는 것이 좋아 '지금 써보러 갑니다, 팁스터 뉴스레터'를 운영하고 있어요.
알림
AI가 UX를 설계하는 방식: 화면보다 흐름이 먼저인 ‘Figr’
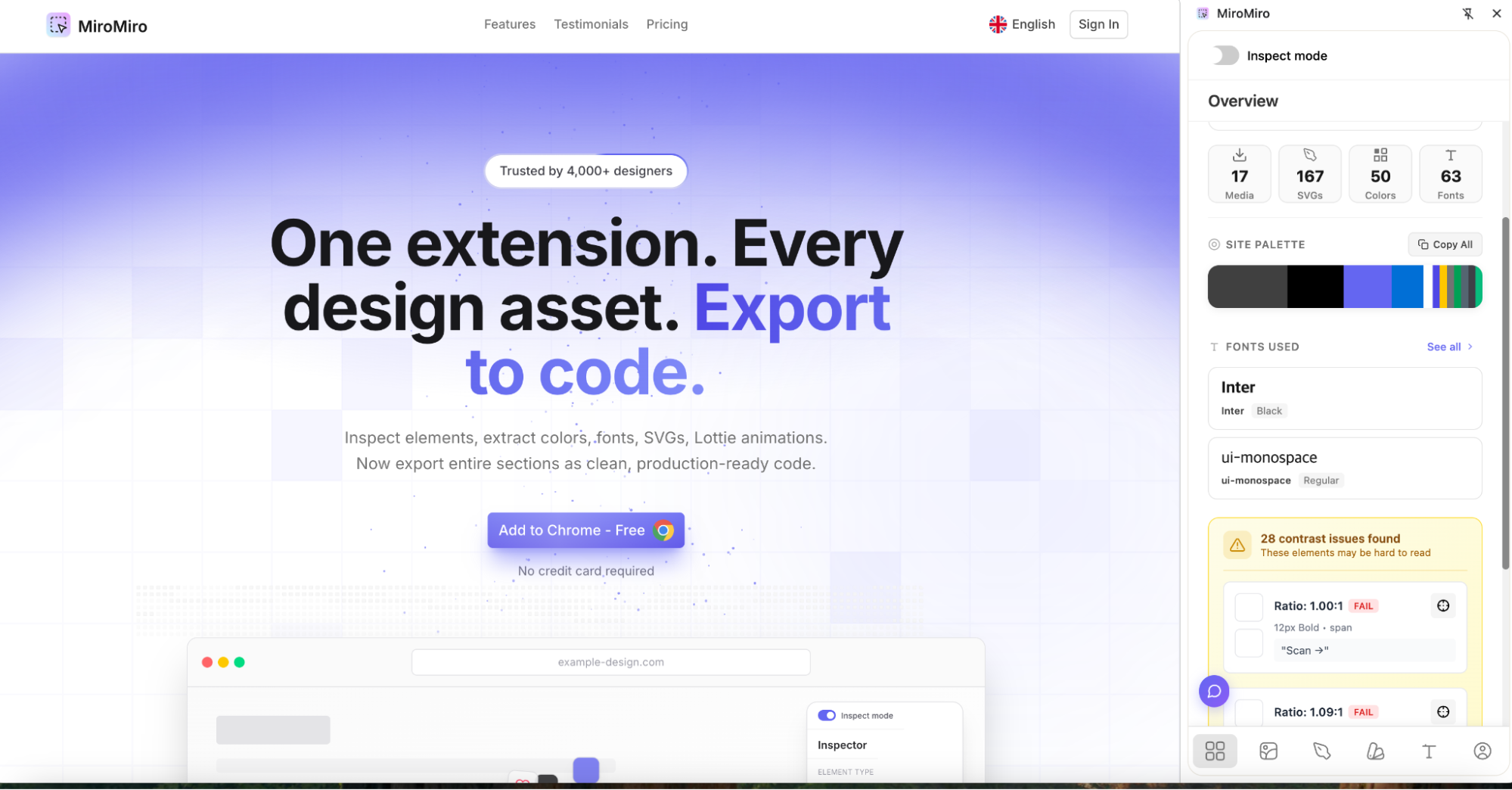
클릭 한 번으로 디자인 시스템 가져오는 'MiroMiro'
더 보기
 0명 뉴스레터 구독 중
0명 뉴스레터 구독 중