개발
[쉽게 배우는 AI] 13. 강화학습이란?

1분
2023.07.14.5.3K

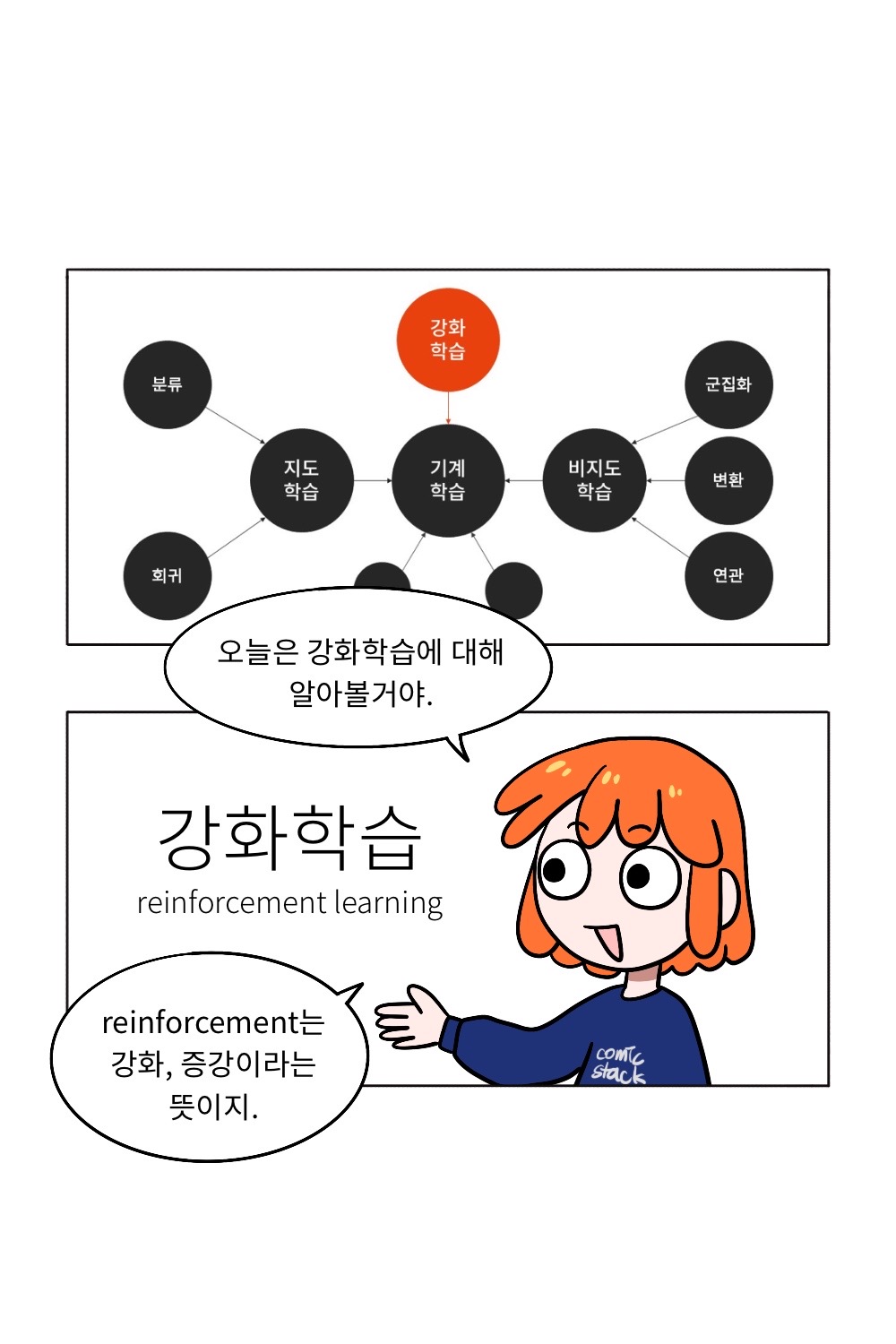






이번 편에서는 머신러닝의 강화학습에 대해 살펴보고자 합니다. 강화학습은 경험을 축적하는 것을 말합니다. 이는 사람이 무언가를 배우는 것과 비슷한데요. 경험을 통해 실력을 키워가는 과정이기 때문입니다.
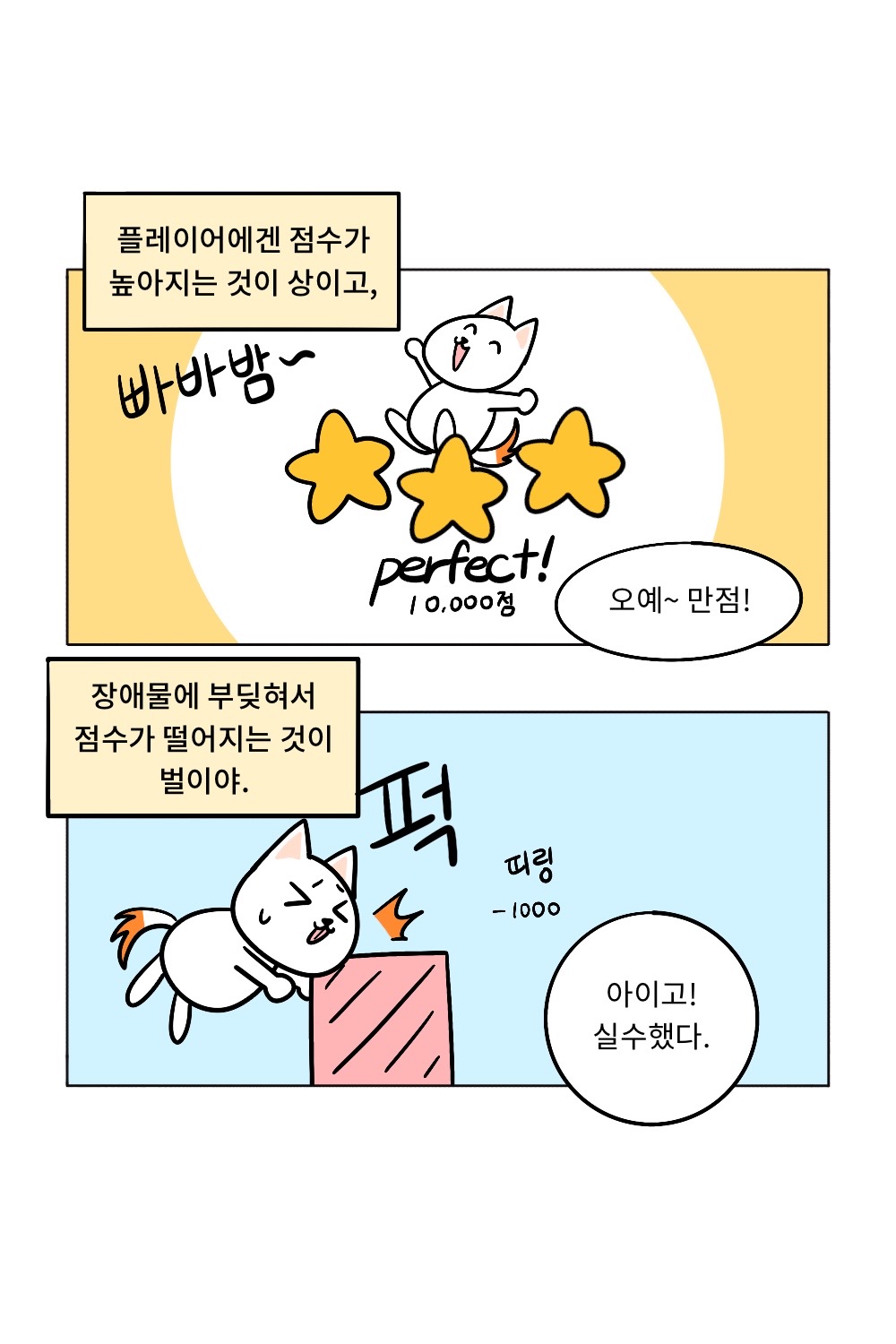
강화학습의 핵심은 일단 시도해 보고, 결과에 점수를 매기는 것인데요. 행동의 결과가 자신에게 유리했다면 보상을 받고, 불리했다면 벌을 받습니다. 이를 계속 반복하면서 더 나은 점수(보상)를 받기 위한 방향으로 학습하는 것이죠. 게임을 예시로 한번 생각해 보겠습니다. 플레이어는 게임에서 보다 높은 점수를 얻기 위해 장애물을 더 잘 피하는 방법이나, 함정의 위치 등을 학습하고 그에 맞는 대응을 할 것입니다. 즉, 판단력이 강화되어 게임을 더 잘하게 됩니다.
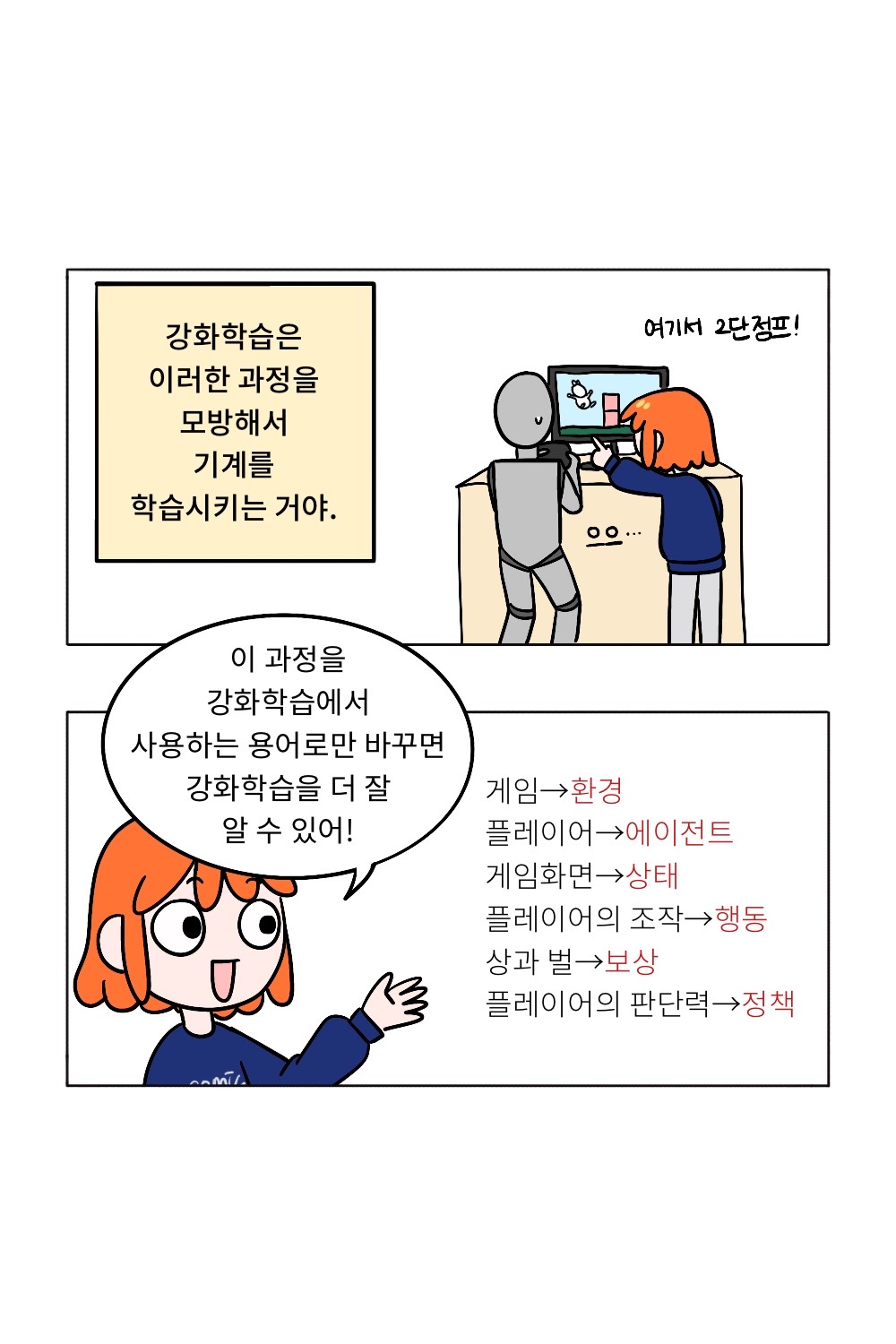
강화학습은 이러한 과정을 모방하여 기계를 학습시킵니다. 2016년 이세돌 9단과의 바둑 경기로 유명해진 ‘알파고’ 역시 강화학습을 통해 바둑 게임 전체를 읽는 능력을 길렀다고 합니다. 스스로 훈련을 통해 더 좋은 선택을 배우는 강화학습은 어찌 보면 인간의 통찰력과도 닮아있다고 볼 수 있습니다.
[쉽게 배우는 AI] 시리즈 보러 가기
<원문>
©️요즘IT의 모든 콘텐츠는 저작권법의 보호를 받는 바, 무단 전재와 복사, 배포 등을 금합니다.