회원가입을 하면 원하는 문장을
저장할 수 있어요!
다음
앞선 두 편의 글에서, ‘실제 A/B 테스트를 설계할 때 우리가 진짜 궁금한 질문’과 ‘A/B 테스트 실험 결과의 유의미한 방안’, 그리고 이를 바탕으로 ‘A/B 테스트의 설계 및 해석에 필요한 기초 통계 지식’에 관해 살펴보았다. 이번 글에서는 여러 이론적 개념을 참고하되, 과학 연구 실험이 아닌 '비즈니스'의 실험이라는 가설 아래 A/B 테스트의 설계, 수행, 해석에 관한 참고 사항에 대해 자세히 알아보고자 한다.
회원가입을 하면 원하는 문장을
저장할 수 있어요!
다음

앞선 두 편의 글에서, ‘실제 A/B 테스트를 설계할 때 우리가 진짜 궁금한 질문’과 ‘A/B 테스트 실험 결과의 유의미한 방안’, 그리고 이를 바탕으로 ‘A/B 테스트의 설계 및 해석에 필요한 기초 통계 지식’에 관해 살펴보았다. 이번 글에서는 여러 이론적 개념을 참고하되, 과학 연구 실험이 아닌 '비즈니스'의 실험이라는 가설 아래 A/B 테스트의 설계, 수행, 해석에 관한 참고 사항에 대해 자세히 알아보고자 한다.
‘구글 옵티마이저(Google Optimize)’과 같은 A/B 테스트 툴에서는 전환율과 더불어 표본 크기에 따른 유의미한 결과를 계산해 최종 판단에 도움을 준다. 참고로 Optimize는 앞에서 설명한 방식과는 다른 방식으로 작동하는 툴이지만, 기획자와 PM, 마케터의 입장에서 ‘우연이 아닌 게 맞나?’라는 맥락은 똑같다.
그런데 만약 A/B 테스트를 위한 솔루션을 사용하지 않거나, 이 솔루션으로 응용할 수 없는 실험을 설계했으면 이 계산은 어떻게 해야 할까? 숫자를 엑셀에 일일이 넣어서 함수를 통해 구현해야 할까? 혹은 SPSS나 파이썬(Python) 같은 통계 패키지를 이용해 코드를 몇 줄이라도 짜야만 결과를 볼 수 있을까?
결론부터 말하자면 '아니오'라고 단언하겠다. 이미 간단한 숫자 입력, 세팅만으로 A/B 테스트 계산을 제공하는 다양한 웹 서비스가 존재한다.
무료로 A/B 테스트 결과를 제공하는 계산기로, 사이트에서 제공하는 세팅에 간단한 숫자만 입력해도 유의미한 결과를 낼 수 있다. |
‘AB Testguide’는 별다른 툴 없이도 쉽게 A/B 테스트 결과를 알 수 있어 자주 쓰는 곳이다. 그러면 이 사이트에서 기초 통계 지식을 바탕으로 계산기를 세팅하고 데이터를 해석하는 방법에 관해 설명해 보겠다.
먼저 해당 사이트에 접속하면 왼쪽에 몇 가지 세팅이 보이는데, 크게 3가지로 구분할 수 있다.
각 그룹의 표본 크기와 그룹별 최종 전환 숫자를 뜻한다. 실험을 통해 각 그룹에 모인 트래픽과 그중에서 우리가 원하는 결과로 최종 전환된 트래픽을 직접 입력하면 된다.
이전 글(2부 링크)에서 단측 검정과 양측 검정에 관해 설명했는데, 이 세팅이 바로 그 결과를 보기 위한 기능이다. 쉽게 말해 '두 그룹에 차이가 있다는 전제하에, 특정 한쪽이 무조건 우세하다고 생각하고 실험을 할 건지' 아니면 '두 그룹에 차이가 있긴 있는데 어느 쪽이 우세할지 모르겠으니 열어놓고 보겠다'인지로 이해하면 된다.
신뢰 수준에 몇 %로 설정하는지 묻는 설정이다. ‘똑같은 실험을 100번 했을 때 그중 몇 번의 '우연'을 봐줄 것인가?’로 이해하면 된다. 세밀한 분석이 필요하면 99%까지도 설정할 수 있지만, 보통 95%로 충분하다.
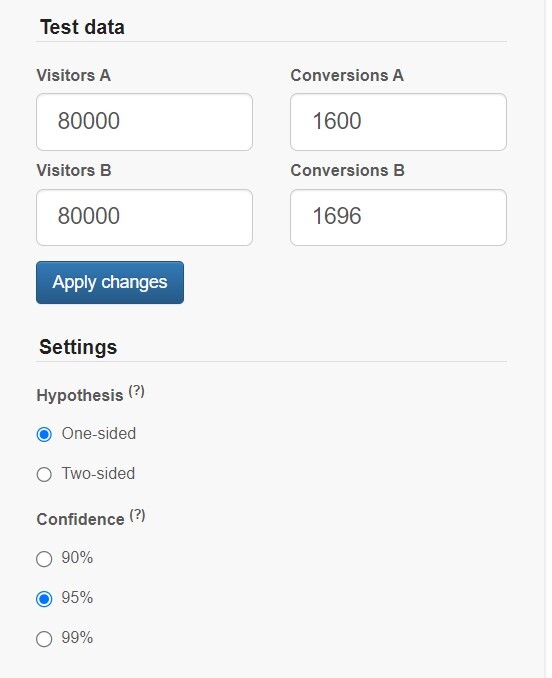
Test Data는 우리가 모은 트래픽을 정직하게 입력하면 되고, 신뢰 수준은 보통 95%면 된다고 하니까 95%를 선택하면 되는데, 그러면 양측 검정과 단측 검정 중 어느 쪽을 해야 할까?
사실 우리는 실험을 설계할 때 ‘특정 방안이 더 나을 것 같다’라는 암묵적인 기대 또는 가정을 갖고 시작한다. 하지만 어떤 방식으로든 A/B 테스트를 이미 진행해본 경험자라면 '고객의 반응은 우리의 기대, 예상과는 종종 다르다'는 걸 체감했을 것이다. 그래서 보통은 ‘양측 검정(two-sided)’을 진행하는 게 조금 더 보수적이고, 안전한 접근이다.
이 부분과 관련해서는 양측 검정이 조금 더 '보수적인', '안전한' 접근인 이유에는 사실 앞선 글(2부 링크)에서 설명한 신뢰 수준, 유의 수준, 그리고 P-value에 관한 이해가 조금 더 필요하다.
만약 우리가 신뢰 수준 Confidence를 90%로 세팅했다고 가정하자. 이 경우 우리가 실험에 기대하는 건 아래와 같다.
그러면 이를 단측 검정으로 진행하면 어떤 의미가 될까?
반면 이를 양측 검정으로 한다는 것은 어떤 의미일까?
이게 실험 세팅과 어떤 관련이 있는 걸까?
우리의 결과가 어느 한쪽으로 무조건 나올 것이라는 보장이나 기대가 없는 상황에서 ‘단측 검정’을 하면, 차이는 있지만 더 큰 게 아니라 기대했던 것보다 더 작은 경우(혹은 반대의 경우)에 ‘우연’으로 계산되어 버린다.
반면 양측 검정이었다면 ‘더 크진 않지만 그래도 더 작네? 차이가 있는 게 맞네? 그럼 우연 아니지! 인정이지!’ 또는 ‘더 작진 않은데 그래도 더 크네? 차이가 있는 게 맞네? 그럼 우연 아니지! 인정이지!'라고 테스트 결과를 인정할 수도 있게 된다.
정리하면, 단측 검정이었으면 ‘차이가 유의미하지 않다’라는 결과가 양측 검정에서는 ‘차이가 유의미하다’라는 내용으로 나올 수가 있게 된다. 따라서 앞서 설명한 것처럼 보수적이고 안전한 실험을 할 때는 양측 검정을 할 때가 많다.
위의 내용을 바탕으로 세팅을 무사히(?) 완료하면, 감사하게도 계산은 알아서 해준다. 그리고 두 그룹의 전환율 차이가 유의미한지, 즉 우연이 아니라 앞으로도 동일한 고객을 대상으로 특정 방안이 더 나은 것인지 어느 정도 확신할 수 있게 된다.
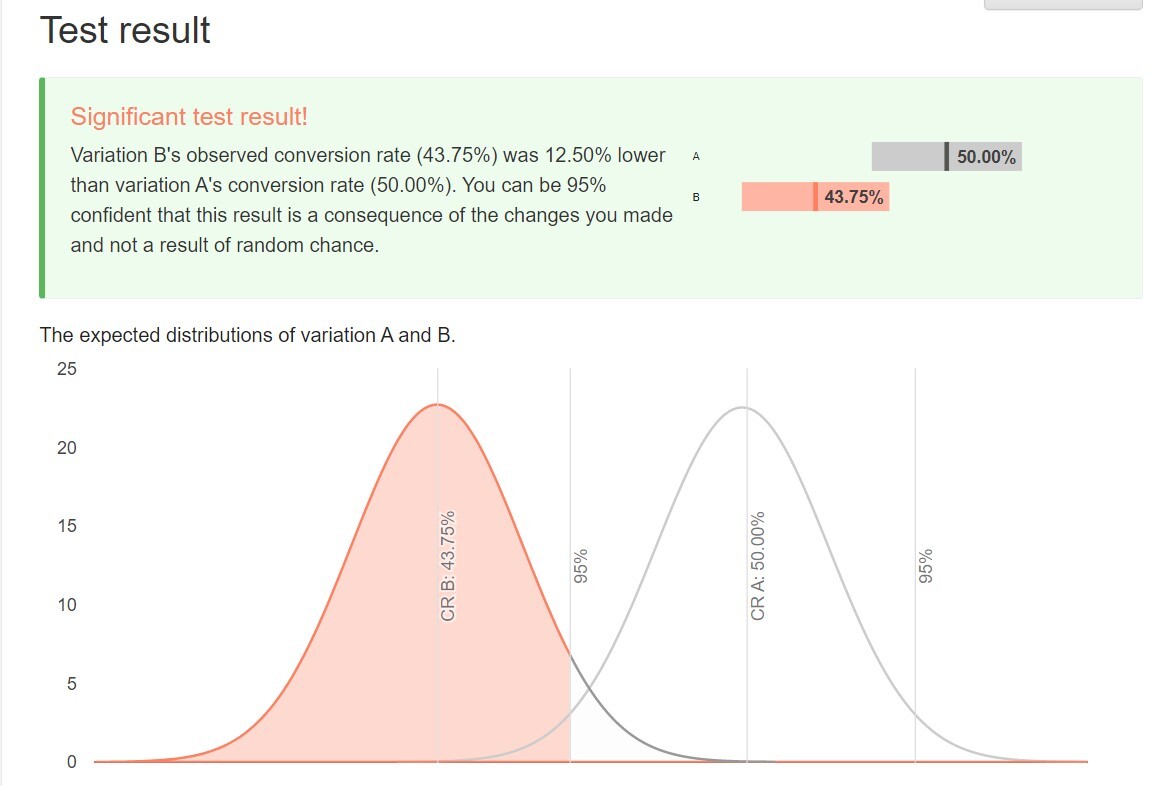
그리고 이 결과는 앞선 글에서 설명한 P-value에 따라 나오게 된다. 95% 신뢰 수준 confidence로 실험을 진행했을 때 P-value가 0.05(=5%) 이하라면 유의미하고, 이보다 크면 유의미하지 않다고 판별하는 것이다.
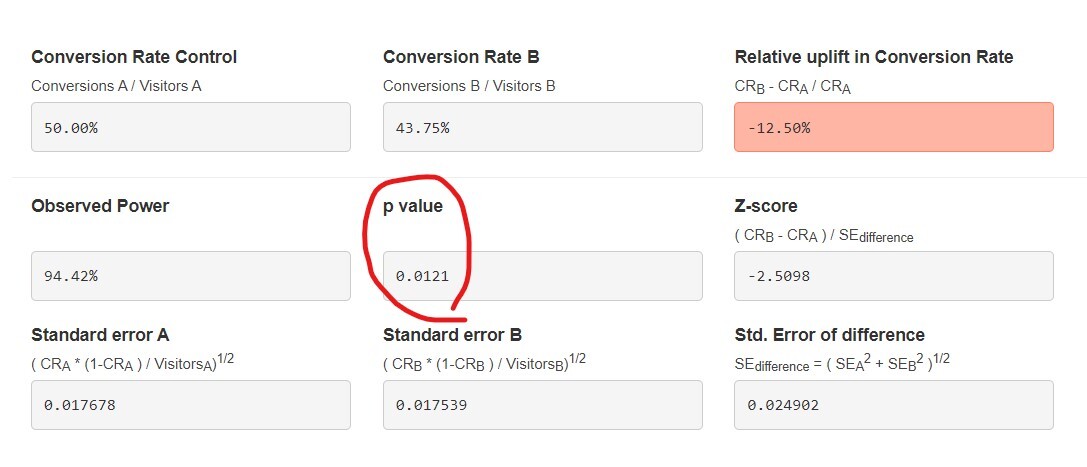
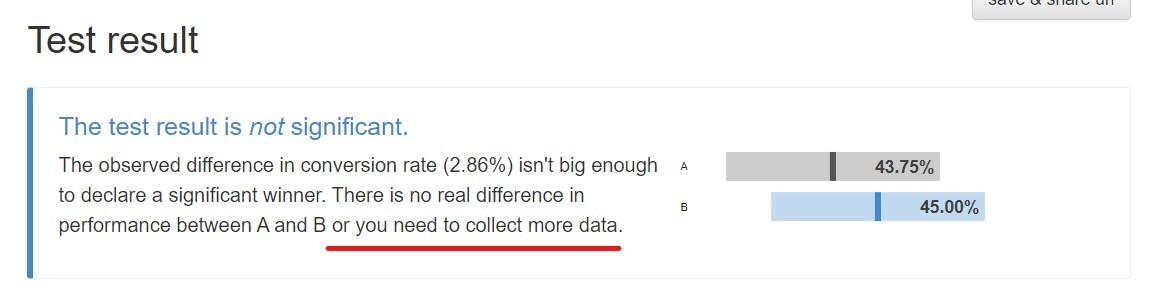
물론 어떤 경우에는 실험 결과가 유의미하지 않을 수도 있다. 그럼 이 경우에는 Test Result가 'not significant'하다면서 아래의 문구를 보여준다.
(...) There is no real difference in performance between A and B or you need to collect more data
“애초에 두 그룹 사이에 별 차이가 없거나” 아니면 “(의역해서)네가 모아 온 그 쥐꼬리만 한 표본으로는 누가 더 나은 건지, 이게 이번에만 우연인지 아닌지 나도 모르겠어!”라는 뜻이다.
지금까지 우리가 무료로 찾을 수 있는 A/B 테스트 사이트와 이를 세팅하는 방법, 그리고 그 결과를 바탕으로 어떤 결론을 낼 수 있는지를 알아봤다. 그런데 이때 결과가 ‘not significant’가 나오면 ‘아~ 차이가 없구나’하고 넘어갈 게 아니라 아래와 같은 고민을 해볼 필요가 있다.
1) 잠깐, 그래서 A와 B 사이에는 정말로 차이가 없는 거야? 이번 기획 아이디어 자체가 망한 건가?
2) 아니면 차이가 있을 수도 있는데, 표본이 부족해서 알 수가 없는 건가? 좀 더 길거나 크게 실험해서 표본 트래픽을 더 모으면 되나?
그래서 다음 글에서는 ① A/B 테스트에서 표본(트래픽)의 크기와 유의미한 결과가 어떤 관계가 있는지, ② A/B 테스트에서 표본(트래픽)을 얼마나 모아야 하는지? ③ 이와 관련해 실제 A/B 테스트를 진행할 때 주의할 사항은 없는지 등에 관해 이야기해 보겠다.

좋아요
댓글
공유
공유