기획
A/B 테스트 제대로 이해하기: ②A/B 테스트를 위한 기초 통계 이해하기

7분
2022.08.16.11.6K

앞선 글에서 A/B 테스트를 설계하거나 수행할 때 ‘목표를 달성하기 위한 방안으로 A와 B 중 어느 게 더 나은가?’ 뒤에 숨은 진짜 질문에 관해 살펴보았다. 이번 글에서는 이러한 우리의 진짜 질문에 관한 답을 얻기 위한 A/B 테스트를 설계하고, 그 결과를 해석하는 데 필요한 기초 통계의 개념을 설명하고자 한다.
예를 들어 우리가 설계하는 실험이 네이버 지식in에 답변을 남기는 이들을 대상으로 진행한다고 가정해보자. 특정 콘텐츠를 제공받은 그룹 A가, 콘텐츠를 받지 못한 그룹 B보다 더 좋은 답변을 작성해서 채택 답변으로 전환하는 비율(%)이 더 높을 것이라고 실험하는 테스트이다.
이 실험은 결국, ‘지식in에 답변을 작성하는 지식인들이 정말 더 좋은 답변을 작성할지, 아닐지’에 관해 알고 싶은 방법이다.
그런데 우리가 실험을 통해 알 수 있는 지식인은 서비스에 존재했고, 존재하고 있고, 앞으로도 존재할 '모든' 지식인일까? 아무리 실험을 꼼꼼하게 설정해도 그럴 수는 없다. 실험의 기간은 한정되어 있고, 누군가는 실험 기간 동안 답변을 작성하지 않을 수도 있고, 누군가는 어떤 이유로 답변이 노출되지 않을 수도 있다. 심지어 지금 당장은 지식in 서비스의 지식인이 아니지만, 며칠 뒤에 가입하게 될 예비 고객을 생각하면 이 실험군은 영원히 ‘일부’일 뿐이다.
결국 우리는 '전체'에 대해서는 알 수 없다. 다만 실험을 통해 만나는 '일부'에 대해서만 알 수 있다. 그것도 실험 기간 동안 실험에 노출된 일부 고객에 대해서만 알 수 있다.
통계에서는 이 전체를 '모집단'이라고 부르고, 이 일부를 '표본'이라고 부른다.
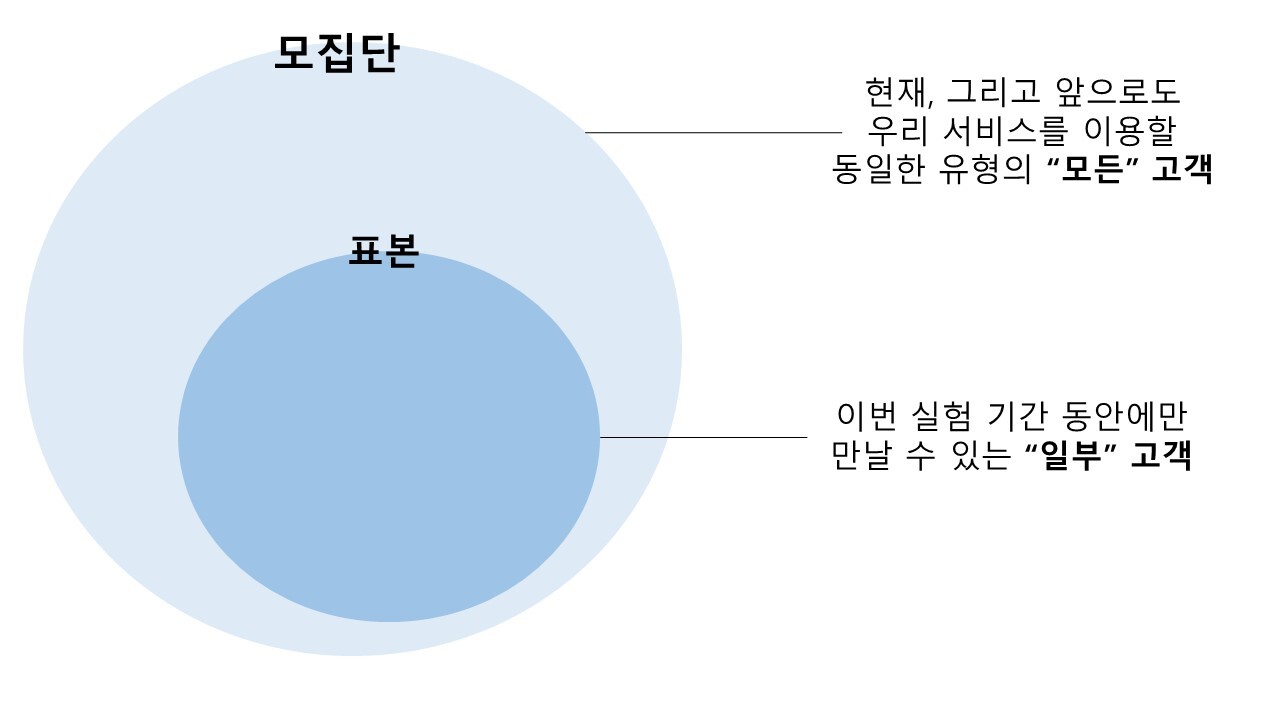
우리가 실험하는 대상이라 '일부'라면, 과연 이걸 토대로 '전체'에 대해 평가해도 되는 걸까? 결과적으로는 가능하다. 아무리 '일부'일지라도 이 숫자가 충분하면, 일부를 통해 전체에 대해서 추측, 추론, 추정할 수 있는 것이다.
다만 이는 A/B 테스트를 설계하거나 실행, 해석할 때의 고려 요소가 아니라 우리의 일상 속 모든 '통계적 추측' 뒤에 숨은 대전제에 가깝다. 따라서 우리는 이러한 개념과 원리를 전제로 삼고 A/B 테스트를 진행하면 된다.
결국 우리는 '표본'을 대상으로 실험하고, 그 안에서 A와 B 또는 더 나아가 C, D, E... 등으로 무수히 많은 그룹을 나눈 뒤 실험을 하게 된다. 그리고 각 그룹의 결과에 '평소라면 차이가 없지만, 이번 실험으로 인해 차이가 생길 것'이라고 가정한다.
평소에는 우리가 무언가를 하지 않으면 아무런 일이 일어나지 않으므로, 표본을 A와 B, 혹은 C, D, E로 나누든 결과에는 차이가 없다. 이러한 평소의 상태에 대한 가설을 ‘귀무가설’이라고 한다.
그런데 우리는 이 표본을 A와 B 등으로 나누어 특정 조치를 한 뒤에, A와 B 사이의 결과에 차이가 생길 거라고 가정한다. 즉, 평소와 다른, 반대되는 상황이 발생할 것이라고 가정한다. 이를 ‘대립 가설’이라고 한다. 평소의 상황(=차이가 없다)과 대립하는 결과(=차이가 생긴다)가 나올 것이라고 가정하는 셈이다.
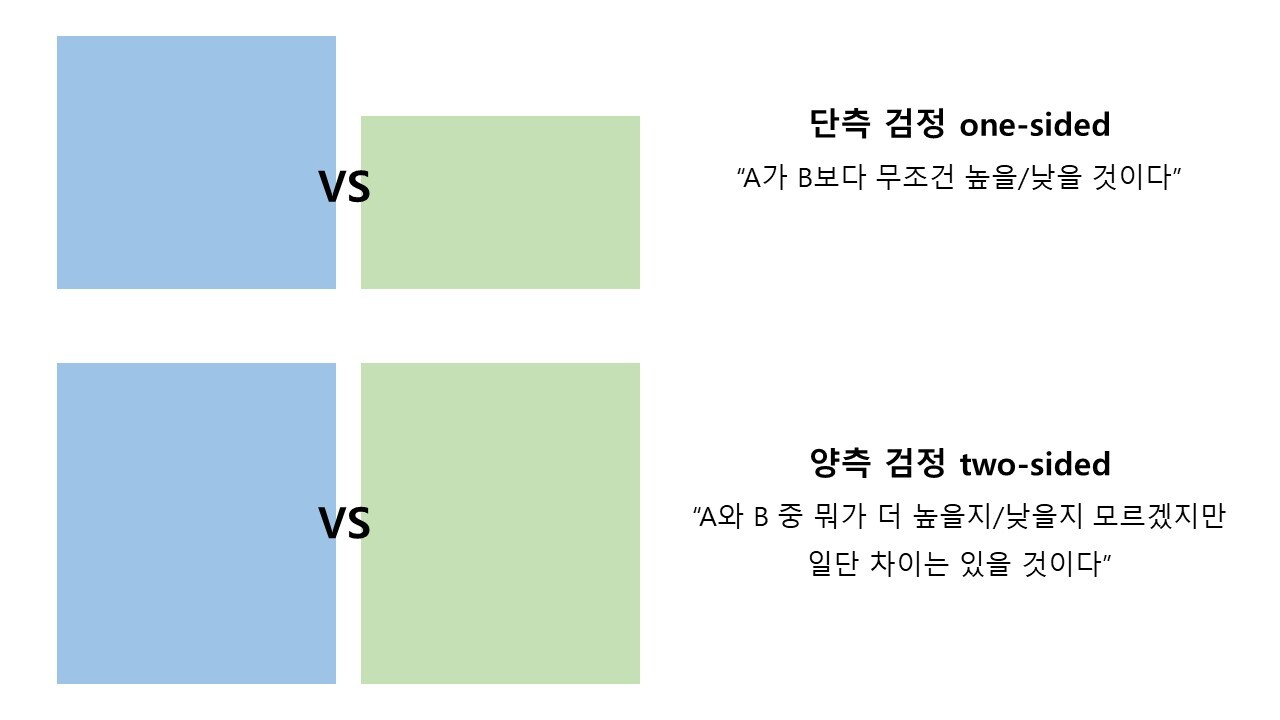
그런데 이때, 차이가 있긴 한데 그래서 한쪽이 무조건 더 나은 걸까? 아니면 어떤 쪽이 나을지는 해봐야 아는 걸까?
보통 우리가 웹/앱에서 실험할 때는 특정 방안(가령 A안), 즉 ‘그룹 A의 숫자가 더 높거나 낮을 것’이라고 가정한다. A/B 테스트를 하면, 두 그룹에 차이가 있어서 더 나은 결과가 있을 것이라고 가정한다. 이때 ‘정말 더 나은 결과인지’ 확인하는 실험을 ‘단측(한쪽으로 알아보는, One-sided) 검정’이라고 한다.
반면 길고 짧은 건 대봐야 아는 법이듯이, 차이가 있긴 있되 어느 쪽이 더 나을지는 미리 가정할 수 없는 경우를 ‘양측(양쪽으로 알아보는, Two-sided) 검정’이라고 한다.
그런데 A/B 테스트의 결과는 무조건 옮은 걸까? 당연히 아니다. 우리가 진행하는 A/B 테스트는 어디까지나 우리가 관심 있는 특정 유형의 고객 중 실험에 노출된 일부를 바탕으로 해당 유형 고객의 전체를 '추측'한 것뿐이다. 다만 우리는 이 추측이 제법 유효한지, 공정한지, 정확한지 알아가려는 과정이고, 최대한 유효하고 공정하고 정확한 A/B 테스트를 만들기 위해 노력할 뿐이다.
100%가 아니라면, ‘그럼 우리의 추측이 어느 정도로 신뢰할 수 있는가?’라는 질문을 하게 된다. 이때 우리의 추측을 신뢰할 수 있는 수준을 신뢰 수준'이라고 한다.
쉽게 비유하면 '내가 얼마나 엄밀하게 A/B 테스트를 실험하고 싶은가?'의 의미로, 보통은 95%를 기준으로 한다. 이는 '100번 중 95번은 내가 생각하는 결과가 나오겠지만, 나머지 5번은 아닐 수도 있다. 즉, 100번 중 5번은 실은 이 결과가 우리의 실험에서 설계한 장치와 별개로 순전히 우연에 의해 일어난 걸 수도 있다'는 뜻이다.
사실 신뢰 수준에 관해 이야기하기 위해서는 점 추정과 구간 추정, 표준 오차, 신뢰 구간 등 여러 용어 필요하다. 하지만 A/B 테스트의 직접적인 설계 및 수행, 해석에는 당장 필요하진 않아서 아래와 같이 간략히 설명한 것으로 대신하겠다.
그런데 앞선 글에서 살펴본 것과 같이 만약 이번 실험 결과가 꽤 차이가 있는데, 만약 이게 이번 한 번만의 우연한 결과, 또는 극단적인 결과라면? 이번 결과가 우연인지 아닌지는 어떻게 알 수 있는 걸까?
이는 실험 결과와 함께 표기되는 P-value를 통해 알 수 있다.
신뢰 수준이 95%라는 건 ‘100번 중 95번은 실험의 결과가 내가 생각한 범위 내 결과를 도출하지만 나머지 5번은 아닐 수 있다’는 뜻이다. 바꿔 말해 ‘5번은 틀리더라도 봐준다’라는 뜻이다. 이 5번, 즉 5%를 ‘유의 수준’이라고 한다. A와 B가 정말로 유의미하게 차이가 있어도 봐줄 수 있는 수준, 또는 마지노선인 셈이다.
만약 신뢰 수준 95%의 실험에서 결과로 나온 ‘P-value’가 4%라면, 앞서 실험의 유의미함을 판단하는 기준으로 세운 5% 안에 안착했으므로 ‘A와 B는 정말로 차이가 있는 게 맞다’라고 판단하게 된다.
반면 P-value가 6%라면? 이는 신뢰 수준 95%의 기준인 5%를 넘겼으므로 실험은 타당하지 않은 것으로 판단한다. 이 경우 우리가 실험을 통해 얻은 결과는 우연일 가능성이 우리가 세운 기준보다 크기 때문에 A와 B에는 실질적인 차이가 없다고 판단한다.
그런데, 애초에 '우연'이라는 개념은 왜 나오는 걸까? 왜 신경 써야 하는 걸까? 애당초 이번 실험에서 특정 결과 이겼으면 끝난 것 아닌가?
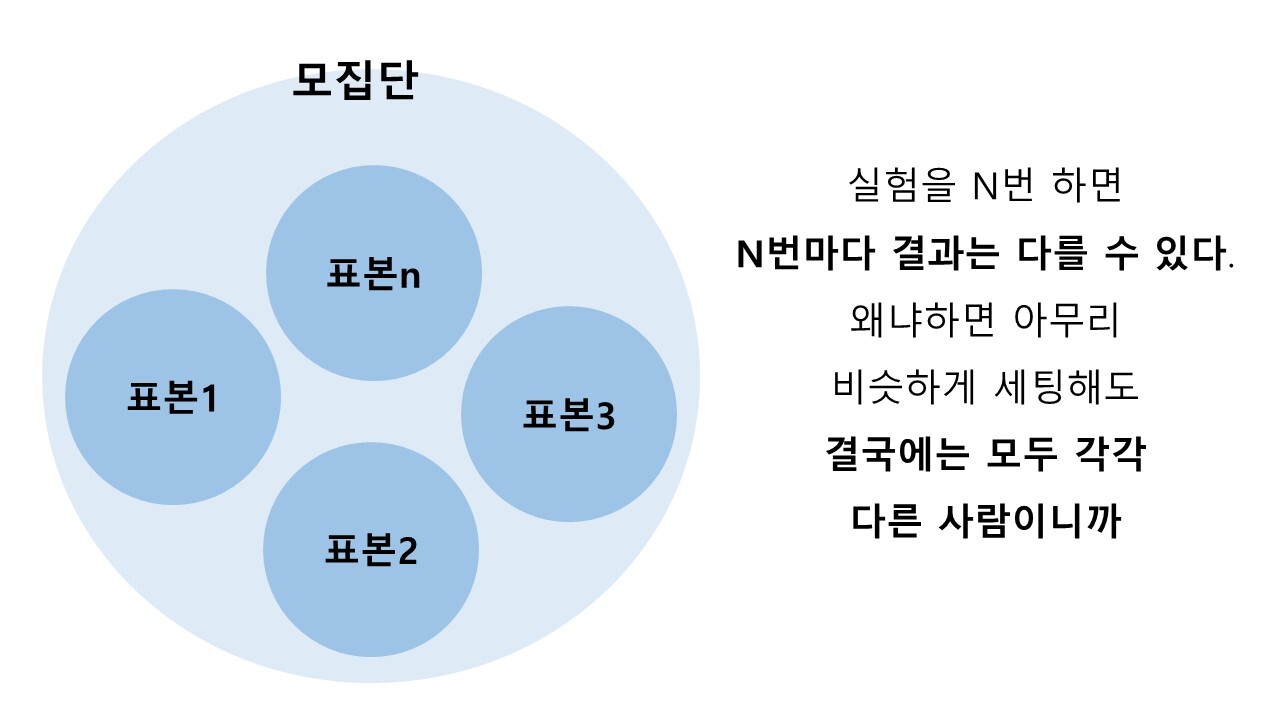
그건 앞서 말했듯이 우리가 '일부'를 통해 '전체'를 추측하기 때문이다. 문제는 매일 또는 매번 우리의 A/B 테스트에 노출되고 있는 '일부'는 사실은 동일 인물이 아닌 서로 다른 사람들이 모인 '일부'이다. 다른 사람들이 모인 ‘일부’라서 그 결과가 매번 다를 수도 있다.
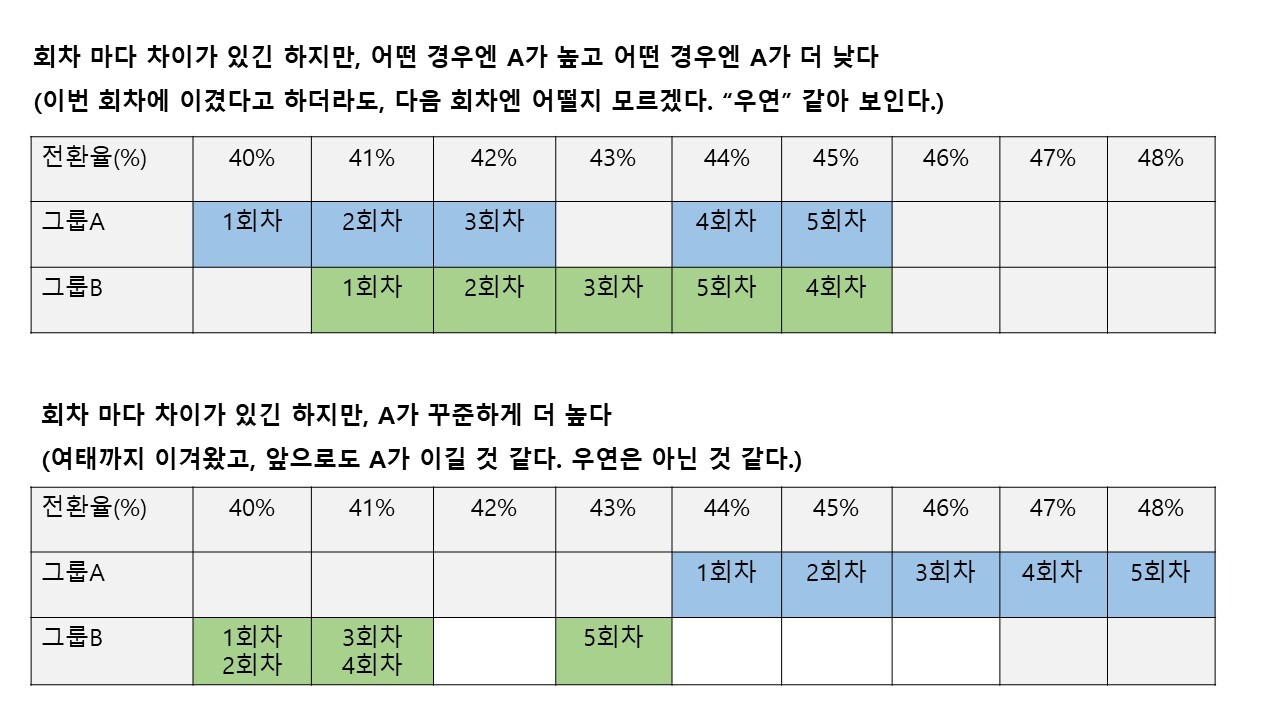
가령 우리가 이틀 동안 트래픽을 5:5로 나누는 실험을 했다고 가정해보자. 그럼 7/30(토)의 A그룹의 전환율과 7/31(일)의 A그룹의 전환율은 100% 일치할까? 당연히 아니다. 왜냐하면 7/30(토)에 테스트에 노출된 A그룹의 유저와 7/31(일)에 테스트에 노출된 A그룹의 유저는 결국 '다른 사람'이니까.
매번 결과가 다르고, 이런 경우가 반복되면 A/B 테스트를 하는 우리 입장에서 어느 쪽이 확실하게 이겼다고 말하기 어렵다. 그래서 우리는 지금까지의 승리, 즉 결과가 정말 이 실험 덕분에 생긴 결과인지, 혹은 우연인 건지 등을 P-value와 유의 수준을 통해 비교 및 확인하는 것이 매우 중요하다.
오늘은 우리가 A/B 테스트를 할 때 가정한 질문을 제대로 알기 위해 기초 통계가 왜 필요하고, 중요한지를 알아보았다. 무엇보다 가설을 통한 실험은 우연히 발생할 수밖에 없기 때문에 적절한 기초 통계를 활용해 우리가 원하는 답을 찾기 위해 노력해야 한다. 이어지는 글에서는 이러한 기초 통계 지식을 바탕으로, A/B 테스트 계산기를 세팅하고 해석하는 방법에 대해 살펴보고자 한다.
©️요즘IT의 모든 콘텐츠는 저작권법의 보호를 받는 바, 무단 전재와 복사, 배포 등을 금합니다.