기획
비개발자를 위한 엑셀로 이해하는 SQL: ④ GROUP BY와 HAVING

6분
2022.10.27.7.7K

앞선 세 편의 글에서는 비개발자, 비데이터 직군인 일반 사무직으로써 자주 사용하는 엑셀을 통해 온라인 서비스의 데이터베이스 중 하나인 RDB와 이를 활용해 데이터를 조회/추출하기 위한 SQL의 문법 중 기초 문법 일부를 살펴보았다.
이어지는 이번 글부터는 조금 더 본격적이고 구체적인 문법과 함수들을 살펴볼 예정이다. 다만 이는 여전히 우리가 엑셀에서도 평소에 데이터를 정리/보고하던 때 사용하던 맥락과 모두 동일하며, 함수도 대부분 엑셀에서의 함수와 동일하거나 매우 유사하니 참고 바란다.
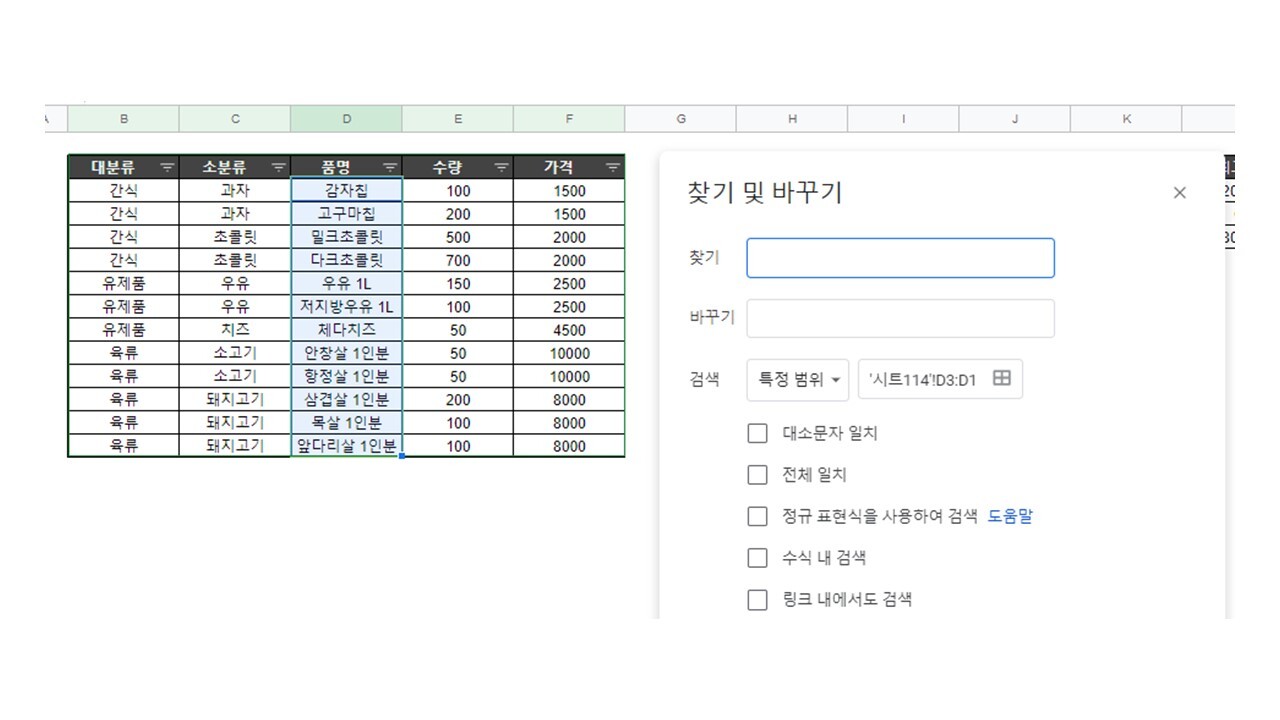
우리는 계속해서 평소 엑셀에 기록해두고 조회, 관리하는 데이터를 예시로 들고 있다. 그런데 우리가 엑셀에서 데이터를 조회하고, 이를 바탕으로 무언가를 확인하고, 보고서를 올릴 때를 떠올려 보자. 엑셀에 존재하는 데이터 행을 일일이 하나하나 뜯어봤을까? 실은 '상품 유형별 판매량'이라든가, '반별 인원수'라든가, '부서별 식비 총합'과 같이 그룹/유형별로 분류한 전체적인 내역을 정리하여 보고 싶을 때가 더 많지 않았을까?
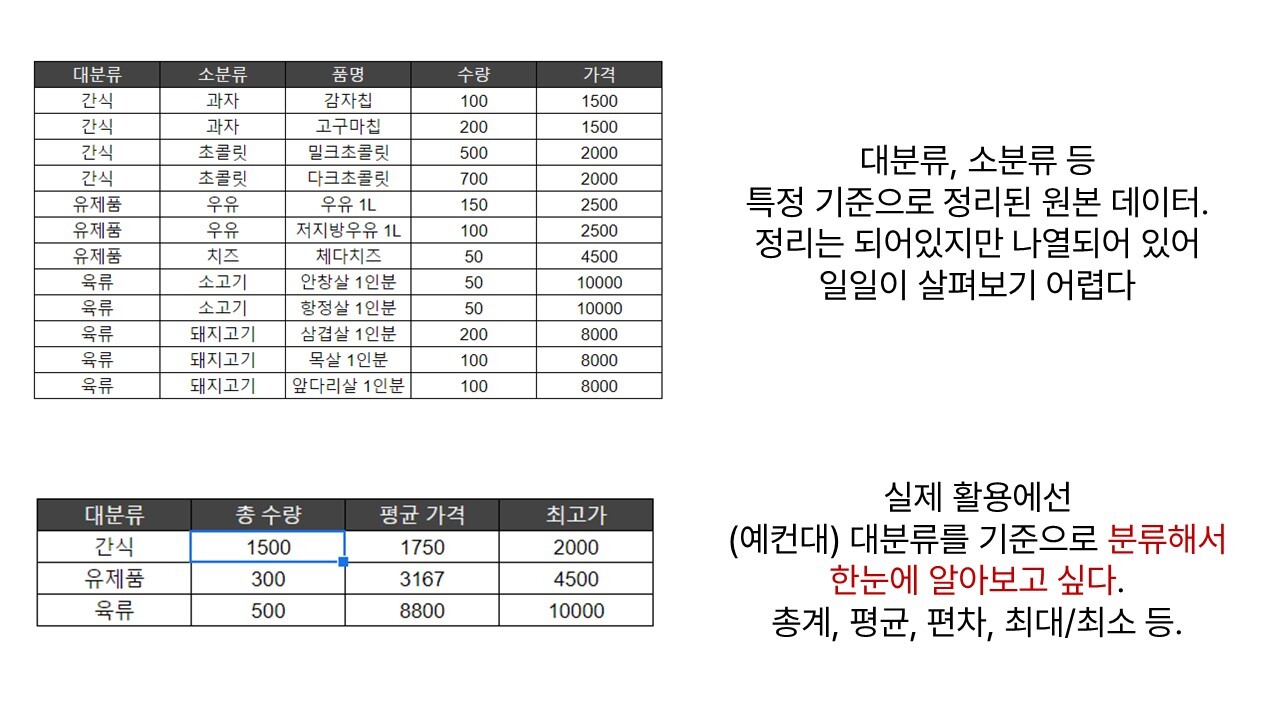
위와 같은 답을 얻어내기 위해 우리는 엑셀에서 원하는 그림으로 표를 만든 뒤 1) 원본 데이터에서 필터를 이용해 골라낸 뒤 다시 일일이 함수를 사용하거나 2) 필터 대신 SUMIF, COUNTIF와 같은 함수를 이용해 자료를 만들다. 이처럼 우리는 이미 엑셀에서도 '그룹별로 묶어 분류한 뒤 대표적인 값을 구해내는 작업'을 하고 있다.
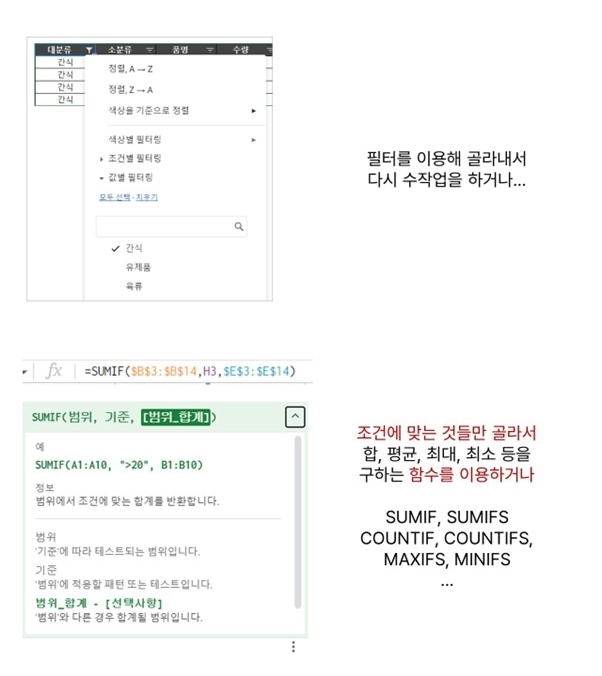
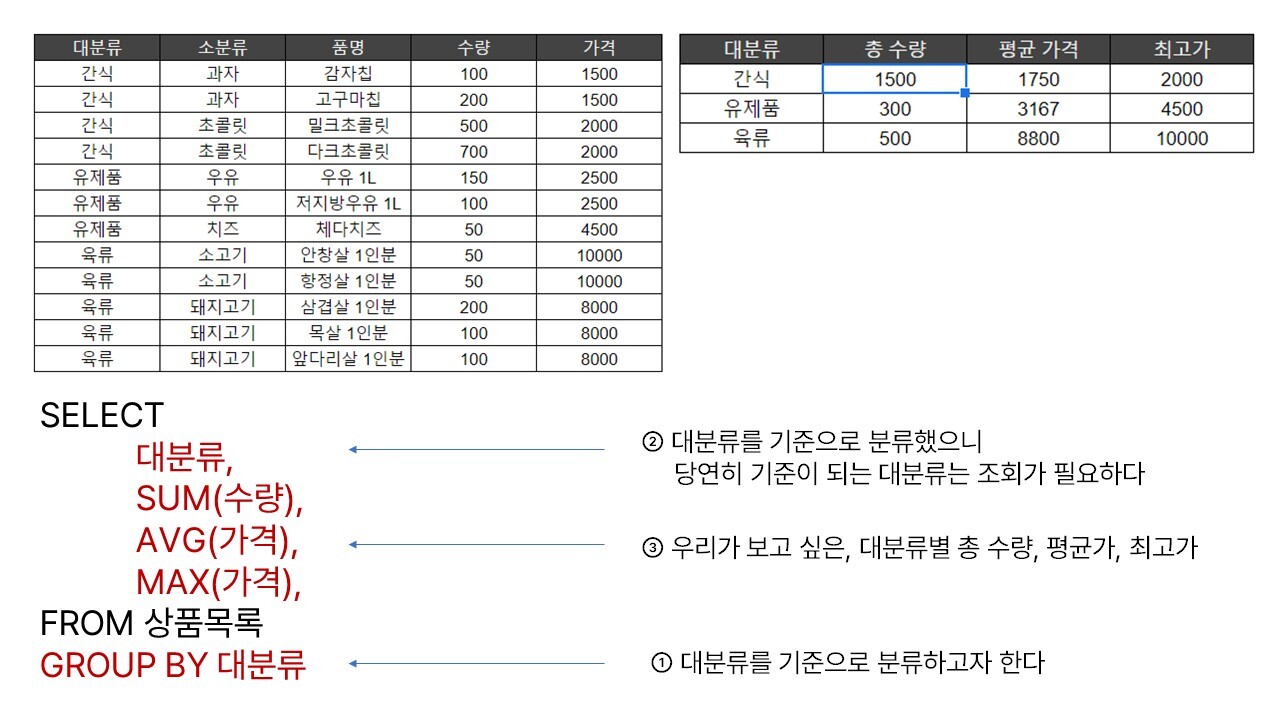
SQL의 GROUP BY는 이와 동일한 맥락으로, 딱 두 가지만 생각하면 된다.
※ 열의 이름 대신 열의 순서(1,2,3,...)을 이용할 수도 있지만 추천하지 않는다. 이는 GROUP BY 1 같은 식으로 작성하는 방법인데, 쿼리가 길어지거나 다른 이가 나의 쿼리를 보는 경우엔, 1이 대체 무엇인지 알아보기 어렵다.
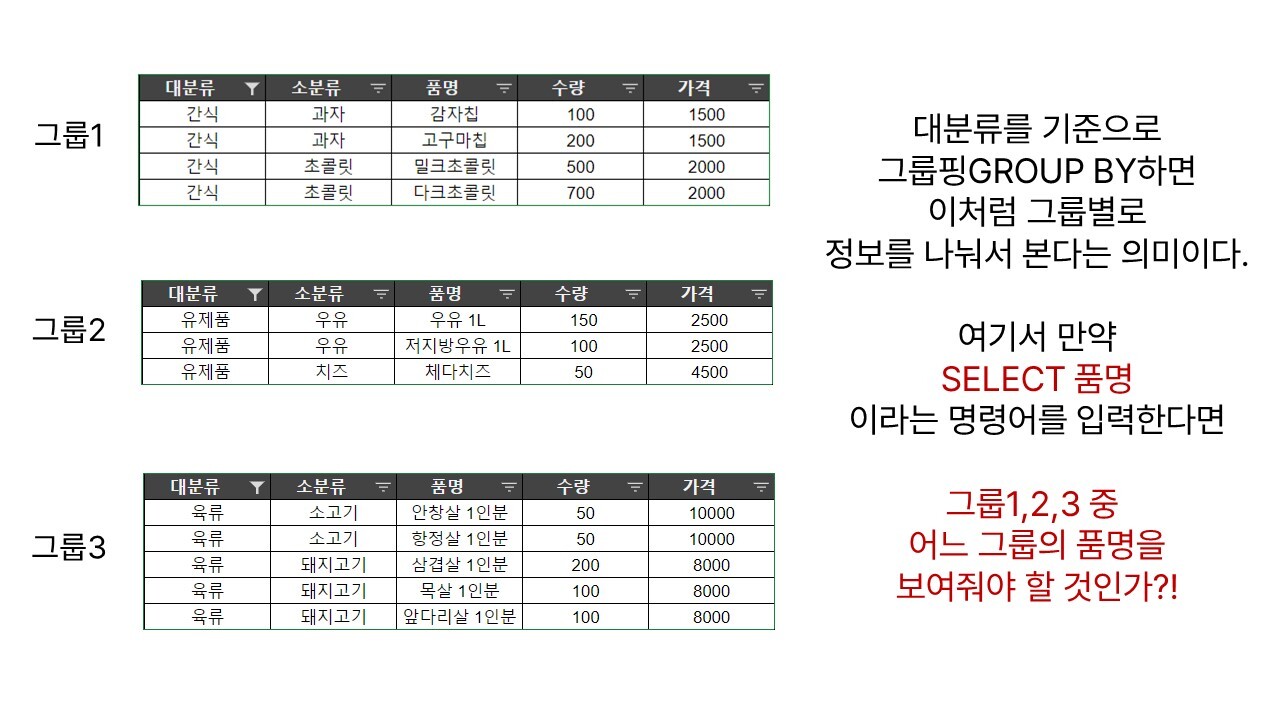
단, 이때 주의할 점이 있다. 특정 열을 기준으로 그룹핑을 한 뒤에는 더 이상 개별 데이터를 쭉 나열할 수 없다. 말 그대로 그룹별로 묶어버렸으니까. 우리가 그룹핑을 하는 건 앞서 말한 것처럼 특정 기준으로 분류하여 전체적으로 표현하겠다는 의미라서 더 이상 개별 데이터를 하나하나 뜯어보진 않겠다는 뜻이기 때문이다.
가령 위의 자료에서 대분류를 기준으로 그룹핑을 한다면 {간식]그룹, {유제품}그룹, {육류}그룹이 생겨나는 셈인데, 여기에서 대뜸 SELECT 품명, 같은 명령어를 입력하면 위의 세 그룹 중 대체 어느 그룹에서 데이터를 가져와야 할지 헷갈리게 된다.
우리는 앞선 글에서 WHERE 명령어를 통해 수많은 원본 데이터/행에서 조건에 맞는 값만 가져오기 위한 방법에 대해 살펴봤다. 그리고 우리는 방금, 원본 데이터/행을 특정 기준에 따라 그룹핑하는 방법에 대해 살펴봤다. 그럼 혹시 이 둘을 합쳐서, 수많은 행을 특정 열을 기준으로 그룹핑한 뒤에 그중에서 내가 생각하는 조건에 맞는 값만 가져올 방법은 없는 걸까?
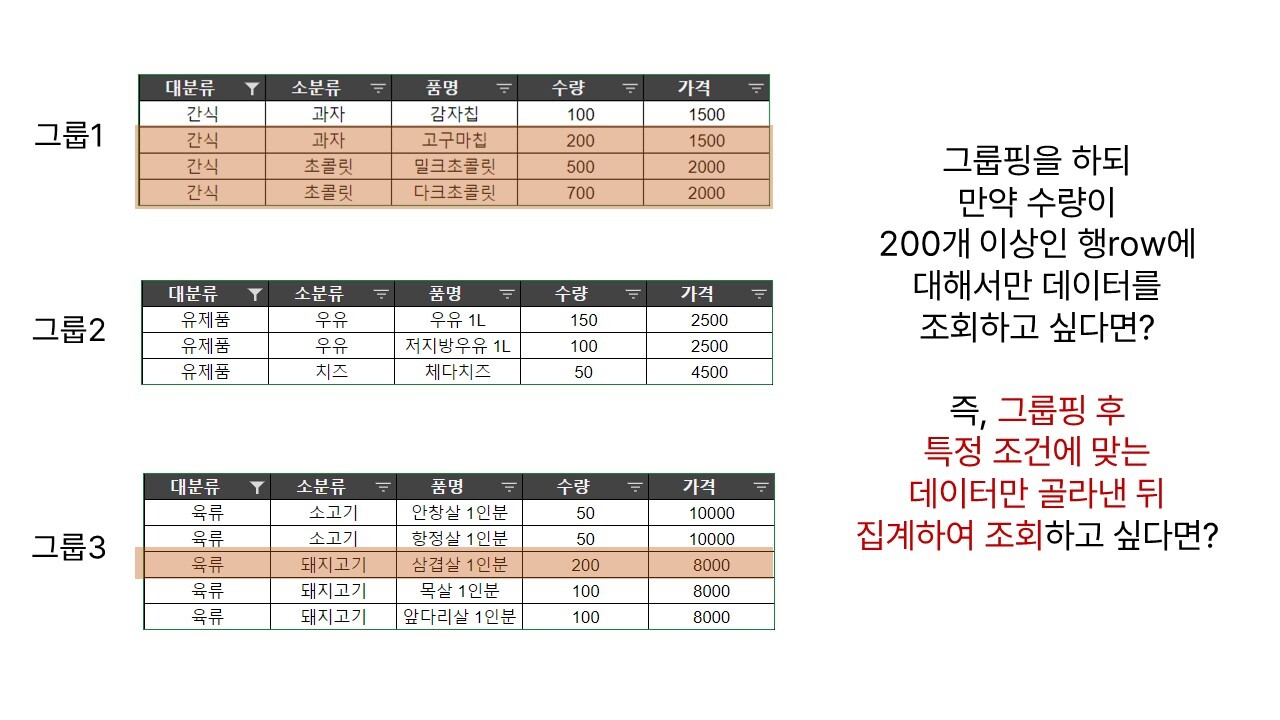
이 경우 우리는 GROUP BY 뒤에 HAVING이라는 명령어를 통해 그룹핑한 뒤에 값을 집계하기 이전에 특정 조건에 맞는 데이터만 골라낼 수 있다.
HAVING은 WHERE과 마찬가지로 논리 연산자(같다, 같지 않다), 비교(초과, 미만, 이상, 이하), 범위 또는 목록, 문자열 등을 조건으로 가질 수 있다, 또한 WHERE과 마찬가지로 콤마(,)를 통해 연결하여 여러 개의 조건을 가질 수도 있다.
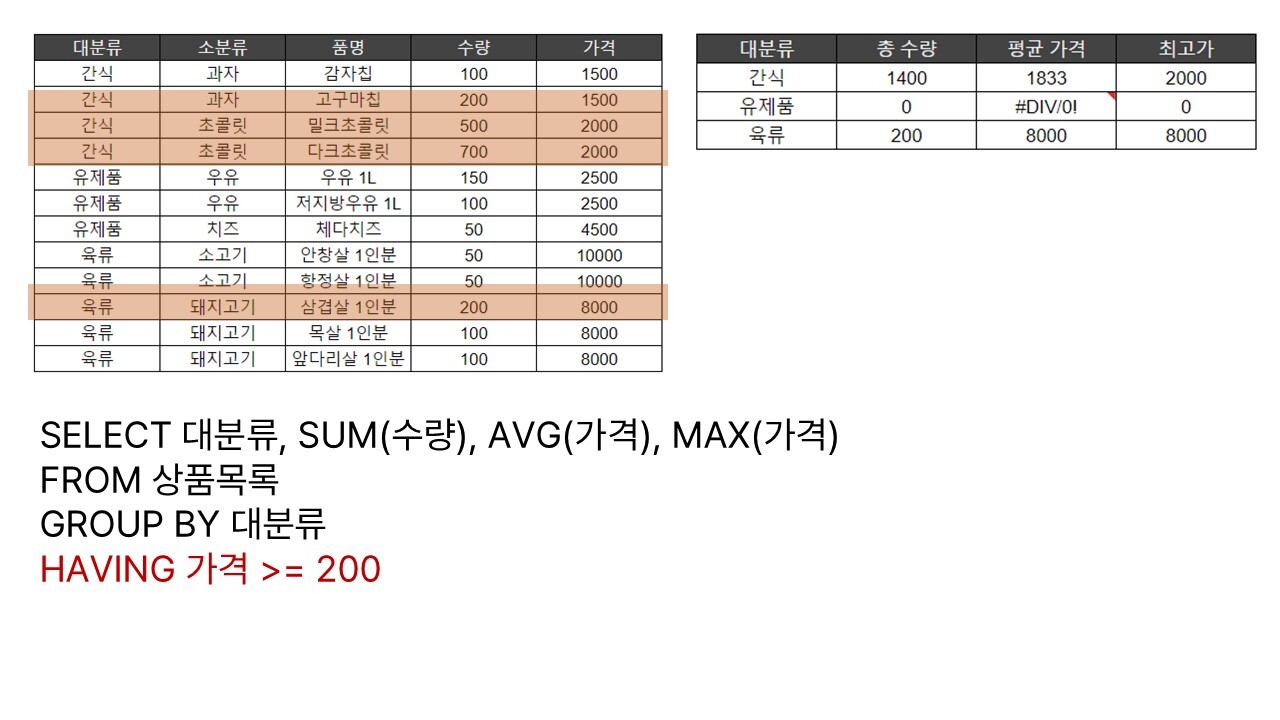
HAVING이 WHERE과 마찬가지로 조건에 맞는 데이터만 골라내는 역할을 하면 둘의 차이는 과연 무엇일까? 사실 결과만 보면 간단한 구문을 작성할 때는 둘의 사용에 차이가 없다. 다만 SQL 문장에는 문장을 읽는 순서 개념이 있는데, 이에 대해 잠깐 살펴보자.
우리는 지금까지 SQL의 FROM, SELECT, WHERE, ORDER BY, GROUP BY, HAVING을 배웠다. 그리고 이 명령어 사이에는 작성하는 순서와 실제로 실행되는 순서가 정해져 있다.
작성하는 순서는 말 그대로 우리가 SQL 환경에서 쿼리를 작성할 때 작성하는 순서를 의미한다. 이는 어떤 명령어를 쓰더라도, 아무리 길고 복잡한 쿼리 문장을 작성하더라도 똑같이 정해져 있는 일종의 약속이다. 그래서 대부분의 SQL과 관련된 강의나 교재 역시 작성하는 순서에 맞춰 설명한다.
반면 실행되는 순서란, 우리가 작성한 순서와 별개로 실제 서버에서 SQL 쿼리를 처리하는 순서다. 이는 사실 SQL이 아니더라도, 우리가 평소에 엑셀에서 데이터를 조회하고 수정/관리할 때의 순서와 동일하다. 다만 우리가 이를 평소에 의식하지 않았을 뿐이다.
1) 어느 파일/시트에서 데이터를 조회할지 선택한다.
2) 필터를 통해 조건에 맞는 것만 골라낸다.
3) 골라낸 데이터에서 다시 특정 기준을 토대로 데이터를 분류한다.
4) 분류한 것 중 특정 조건에 맞는 것만 골라낸다.
5) 최종적으로 내가 원하는 값만 골라내서 표를 만든다.
6) 정렬 순서를 보기 좋게 가다듬는다.
중요한 건 우리가 엑셀에서 데이터를 조회하고 처리할 땐 저 순서가 뒤섞이거나 바뀌어도 마우스와 버튼으로 수정하고 다시 조정할 수 있다. 물론 번거롭다. 하지만 SQL에선 각 명령어를 정해진 순서에 따라 처리한 후 다음 명령어로 넘어갈 수 있기 때문에 이 순서에 맞지 않는 명령어가 작성되어 있으면 오류가 발생할 수 있다.
가령, FROM에서 참고하지도 않은 테이블에 있는 열을 WHERE에서 언급한다든가, SELECT에서 언급하지 않은 열을 기준으로 ORDER BY로 순서를 정렬하려고 하면, 서버 입장에선 ‘앞에서 언급한 적도 없는 걸로 내가 대체 어떻게 조건을 만들거나 순서로 정렬하라는 거야?!’로 되묻는 셈이다.

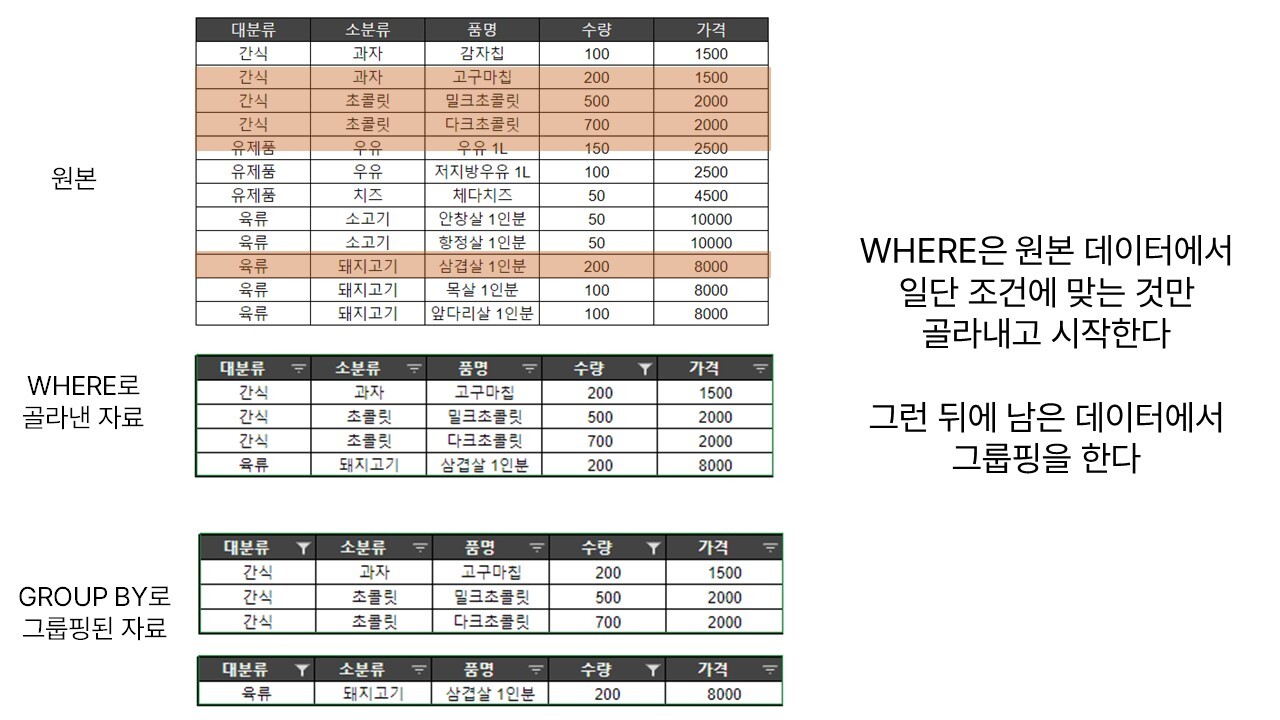
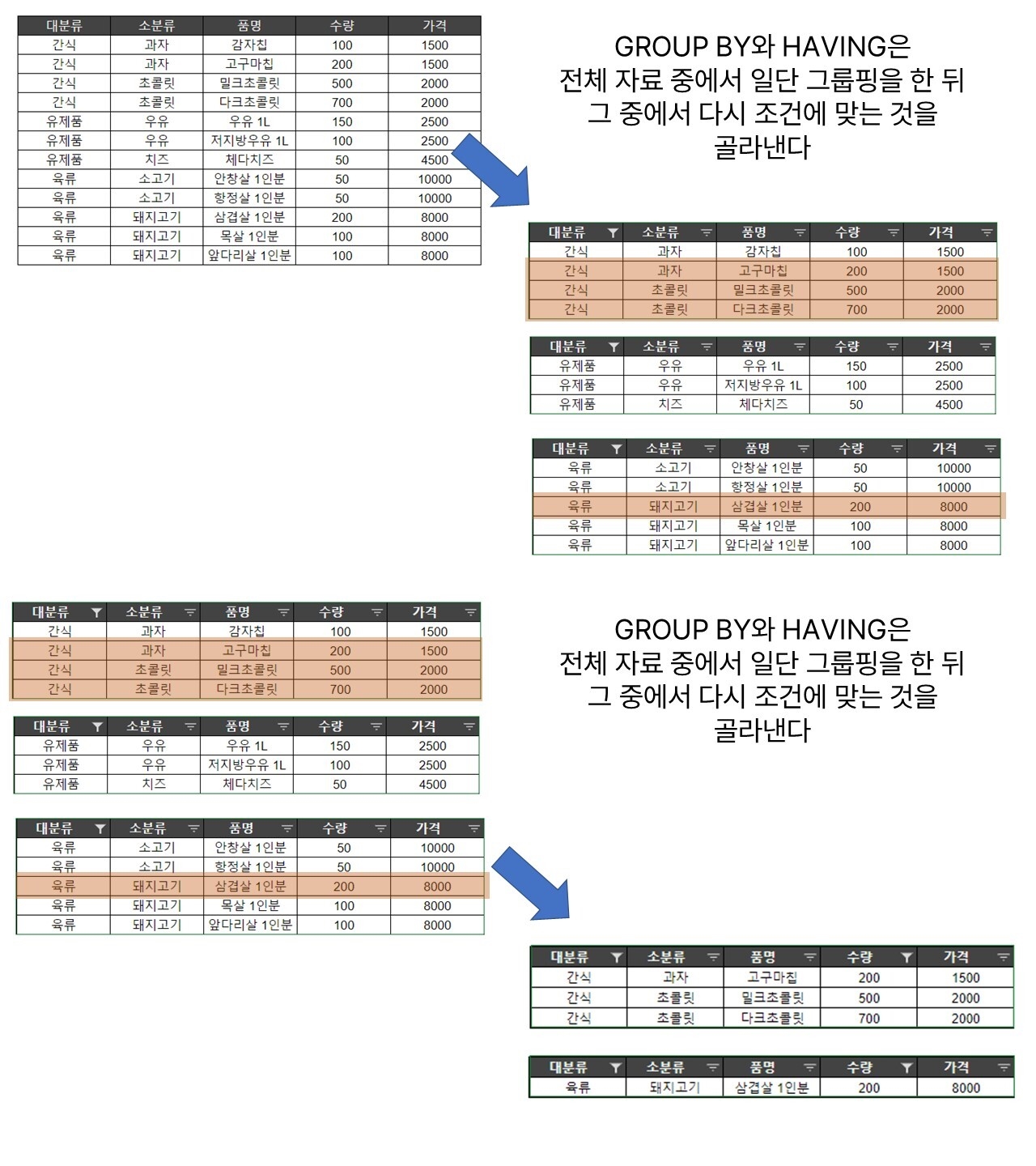
위의 설명에 따라 WHERE를 통해 조건을 적용한다면, FROM으로 참고한 원본 데이터를 우선 모두 골라낸 뒤에 남은 데이터만으로 GROUP BY를 하게 된다. 반면 HAVING을 통해 조건을 적용하면 모든 데이터를 이용해 일단 그룹핑을 하고 그 뒤에 조건을 적용하는 셈이 된다.
WHERE는 GROUP BY보다 먼저 실행되고, HAVING은 GROUP BY 뒤에 실행되기 때문이다.
지금까지 데이터를 조회/추출하기 위한 SQL의 구체적인 문법과 함수들을 알아봤다. 비개발자 직군이 봤을 때 문법과 함수가 다소 어렵다고 느껴질 수 있겠지만, 우리가 자주 사용하는 엑셀과 비교했을 때 사용법의 차이만 있을 뿐이다. 이어지는 다음 글에서는 엑셀을 통해 특정 조건에 맞는 값들을 한 번에 바꿔주는 것처럼 SQL에서도 데이터를 조회할 때 값을 변환시키는 방법에 대해 살펴보고자 한다.
©️요즘IT의 모든 콘텐츠는 저작권법의 보호를 받는 바, 무단 전재와 복사, 배포 등을 금합니다.