


이미 사용 중인 스크랩북 이름입니다.
다른 이름을 지정해 주세요.
빅데이터나 인공지능 관련 업종에 있는 사람들은 어떤 프로그래밍과 툴, 프레임워크 등을 사용하냐에 대해 많은 이야기를 나눕니다. 그 대표적인 예로 ‘파이썬 vs R’이라는 주제는 데이터 사이언티스트들에게 늘 뜨거운 이야깃거리였습니다. 하지만 최근 들어서 적어도 어떤 툴을 가지고 데이터 분석 작업을 진행하느냐에 대해서는 이 논란이 많이 줄어들었습니다. 바로 아나콘다(Anaconda)라는 툴킷(Toolkit)이 어느새 대세로 자리 잡았기 때문입니다. 이번 시간에는 아나콘다란 무엇인지, 그리고 이 아나콘다가 어떤 장점이 있길래 많은 데이터 사이언티스들이 선택하고 있는지 알아보도록 하겠습니다.


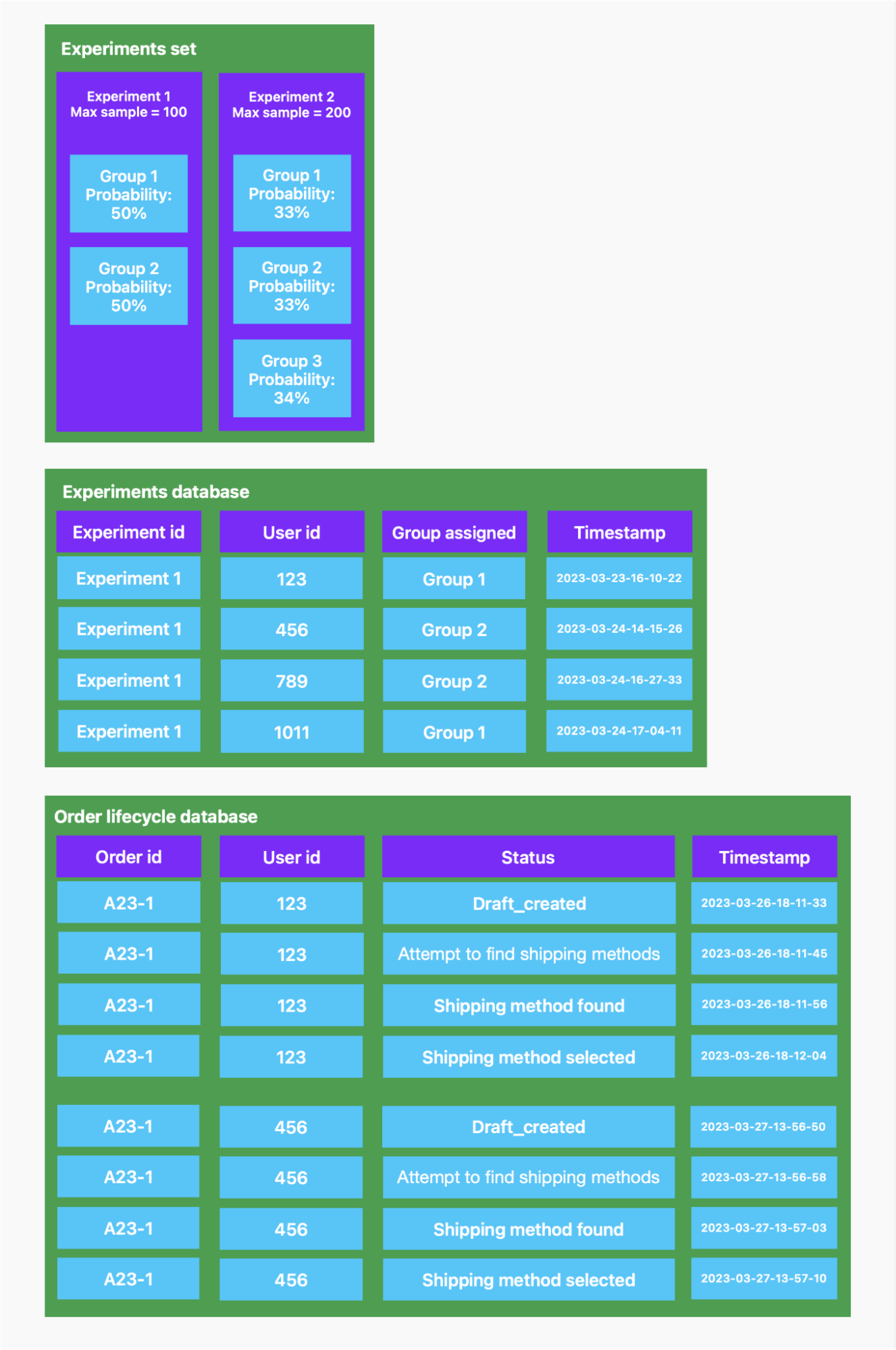
PO(Product Owner)는 옵션 A를 진행할지, 옵션 B를 진행할지, 또는 더 나은 결과를 얻으려면 어떤 버전의 화면을 구현해야 하는지 고민하는 경우가 많습니다. 특히 제한된 리소스로 촉박한 마감 시한에 쫓기는 경우 이러한 결정을 내리는 것은 어려운 일일 수 있습니다. 게다가 이러한 결정은 개인적인 판단이나 경쟁사의 접근 방식을 모방하여 이루어지기 때문에 최적의 결과를 얻지 못할 수 있습니다. 다행히도 비교적 적은 노력으로 간단한 실험 환경을 세팅하면 이러한 함정을 피할 수 있습니다. 이 글에서는 이를 달성하는 방법을 설명하고자 합니다.

데이터 분석가로 취업을 준비할 때 어떻게 공부해야 할지, 어떤 책이 도움이 될지 고민한 적 있으신가요? 데이터 분석가에게 필요한 역량은 데이터 문해력, 실험, 지표 등 범위가 넓습니다. 저 또한 같은 고민을 했던 사람이라, 실제 데이터 분석가로 일하면서 도움받았던 도서 6권을 소개하고자 합니다. 논리, 통계, 그로스 해킹 등 도움이 될 만한 주요 역량을 바탕으로 책을 선정했습니다. 이번 글은 주니어 데이터 분석가 또는 데이터 분석가로 성장하고 싶은 취업 준비생에게 도움이 될 만한 책이니 참고해 보시길 바랍니다.


함수형 프로그래밍을 배우면서 깨달은 것이 있습니다. 실제 함수형 프로그래밍의 본질은 그렇게 어려운 것이 아닌데 이걸 설명하기 위해서는 대단히 어려운 일이 많았습니다. 아마 함수형 프로그래밍에 쓰이는 용어들이 대부분 낯설기 때문일지도 모릅니다. 최근 함수형 프로그램을 더 깊이 공부하다가 실제로 알려주고 싶었던 것이 방법이나 용어가 아닌, 코드를 함수형으로 생각하는 ‘함수형 사고 패러다임’이라는 걸 깨달았습니다. 그래서 오늘은 함수형 사고 패러다임을 바탕으로 새롭게 함수형 프로그래밍에 관한 글을 써보려고 합니다.


양질의 데이터 조건 첫 번째는 ‘충분한 양의 데이터’입니다. 최근 빅데이터라는 단어가 기승을 부리고 있으며 빅데이터는 기본적으로 방대한 양의 데이터를 의미합니다. 하지만 현실적으로 마주하게 되는 데이터들이 모두 방대한 양을 지니고 있지는 않습니다. 1,000개가 되지 않는 데이터를 보는 것은 다반사이며, 심한 경우에는 단 한 줄의 데이터가 ‘데이터’라는 이름으로 유포되고 있기도 합니다. 기본적으로 적은 데이터 수는 곧바로 분석 결과의 신뢰성 하락으로 연결됩니다. 많은 데이터를 통해 충분히 검증한 결과와 그렇지 않은 결과의 차이입니다.

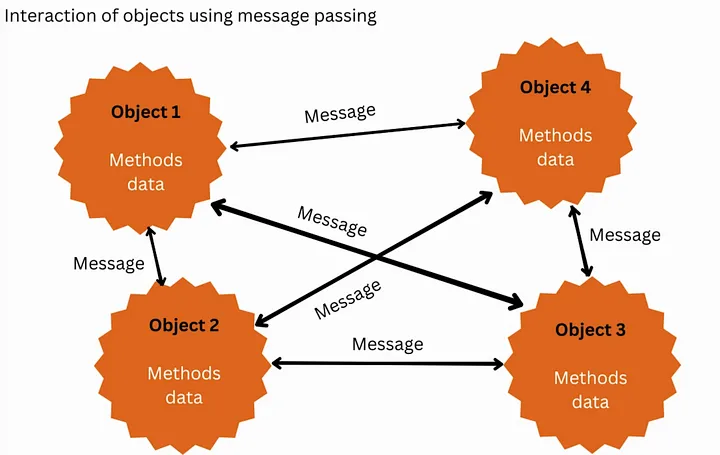
객체지향 프로그래밍(Object-Oriented Programming, OOP)은 클래스(Class)를 통해 데이터와 행위를 묶어 관리하는 프로그래밍 패러다임입니다. 그렇지만 OOP의 사용에 대한 모호함에 대한 논의는 끊임없이 진행되고 있습니다. 이러한 배경 속에서 예호나단 샤르빗(Yehonathan Sharvit)이 데이터 지향 프로그래밍(Data Oriented Programming)이라는 새로운 개념을 제안했습니다. 전편 ‘개발자가 알아야 할 데이터 지향 설계란?’에 이어, 이번 글에서는 데이터 지향 프로그래밍은 어떤 내용인지 알아보겠습니다.