회원가입을 하면 원하는 문장을
저장할 수 있어요!
다음
*FEConf2024에서 발표한 <아�니 이 글자 왜 들어간 거예요? (부제: 알아두면 가끔 쓸모 있는 한글 유니코드 완전 정복)>를 정리한 글입니다. 발표 내용을 2회로 나누어 발행합니다. 1회에서는 유니코드에 대해 알아보고, 유니코드에서의 한글에 대해 알아보겠습니다. 2회에서는 물음표 특수문자가 왜 생겨나는지, 이를 어떻게 해결하는지에 대해 알아봅니다. 본문에 삽입된 이미지의 출처는 모두 이 콘텐츠와 같은 제목의 발표 자료로, 따로 출처를 표기하지 않았습니다.
회원가입을 하면 원하는 문장을
저장할 수 있어요!
다음
*FEConf2024에서 발표한 <아�니 이 글자 왜 들어간 거예요? (부제: 알아두면 가끔 쓸모 있는 한글 유니코드 완전 정복)>를 정리한 글입니다. 발표 내용을 2회로 나누어 발행합니다. 1회에서는 유니코드에 대해 알아보고, 유니코드에서의 한글에 대해 알아보겠습니다. 2회에서는 물음표 특수문자가 왜 생겨나는지, 이를 어떻게 해결하는지에 대해 알아봅니다. 본문에 삽입된 이미지의 출처는 모두 이 콘텐츠와 같은 제목의 발표 자료로, 따로 출처를 표기하지 않았습니다.
‘아�니 이 글자 왜 들어간 거예요? (부제: 알아두면 가끔 쓸모 있는 한글 유니코드 완전 정복)’
제한재 데니어 CTO
지난 글에서 유니코드에 대한 설명과 유니코드에서의 한글에 대해 알아봤습니다. 이번 글에서는 이상한 물음표가 왜 등장하는지 알아보고, 그 문제를 해결하기 위한 방법을 소개하겠습니다.
그럼 본격적으로 알 수 없는 물음표가 들어가는 이유에 대해 알아보겠습니다.

먼저 ‘윈도우의 인코딩 방식 때문에 발생하는 문제인가’라는 가정을 두고 시작해 보겠습니다. 윈도우는 UTF-8이 아니라 euc-kr이라는 인코딩을 주로 사용해서 문자를 저장합니다. 표준명으로는 KS X 1001이고, 옛날 이름으로는 KSC 5601-1987입니다. 이 표준안에 한글과 한자를 배치하고 있습니다. 87년 스펙에 배치된 한글은 2,350자만 포함합니다. 가장 많이 쓰는 한글을 추려서 배치한 것인데, 전체가 11,172자인 것을 생각하면 20% 수준에 불과한 것입니다. 이렇게 빠진 글자가 많기 때문에 한글을 표기할 때 다양한 문제가 발생합니다.
여러 문제점에 대해 알아보기 전에, 인코딩과 문자표의 차이에 대해 간단하게 살펴보겠습니다. 문자표란 글자 하나가 어떤 숫자에 대응하는지 표기하는 것입니다. 즉, 유니코드는 어떤 문자가 어떤 숫자에 대응한다는 것을 설명하기 위한 문서입니다. 한편 인코딩이란 앞서 말한 것들을 메모리에 저장하거나 네트워크 트래픽에 전송할 때 표현하는 방법입니다.
간혹 인코딩과 문자표를 구분하지 않고 설명하기도 하는데, 많은 문자표는 그 자체가 인코딩으로 동작하는 경우도 많습니다. euc-kr 또한 한글을 숫자로 대체하는 표현이 있으며 그 숫자 그대로 저장하기 때문에, 그 자체로 문자표이면서 또 한편으론 인코딩이라고도 합니다.
인코딩의 대표적인 예는 UTF-8, 문자표의 대표적인 예는 유니코드라고 할 수 있습니다.

앞서 설명한 2,350자의 한글 코드가 먼저 표준화로 쓰이며 당시 전산망에서 대부분의 한글이 이 표준 기반으로 표현되기 시작했습니다. 곧 이로 인한 다양한 문제가 발생했습니다.

‘서설믜’라는 이름을 가진 분에 대한 이야기가 대표적입니다. ‘믜’라는 글자가 euc-kr 범위에 포함되지 않았기 때문에 이분은 인터넷 환경은 물론 은행에서 계좌를 개설할 때나, 수능 원서에 이름을 작성할 때도 문제가 생겼다고 합니다.
또 다른 재밌는 사례는 ‘한글 815’라는 에디터 툴입니다. euc-kr에는 ‘쓩’이라는 글자는 있지만, ‘쓔’라는 글자가 없습니다. 그 때문에 당시 다른 에디터에는 ‘ㅆ’과 ‘ㅠ’를 타이핑한 직후 문자를 표현할 방법이 없어 타이핑이 넘어가지 않는 버그가 있었습니다. 그래서 한글 815 에디터 광고에서 ‘쓩’이라는 글자를 표현할 수 있다고 자랑하기도 했습니다.
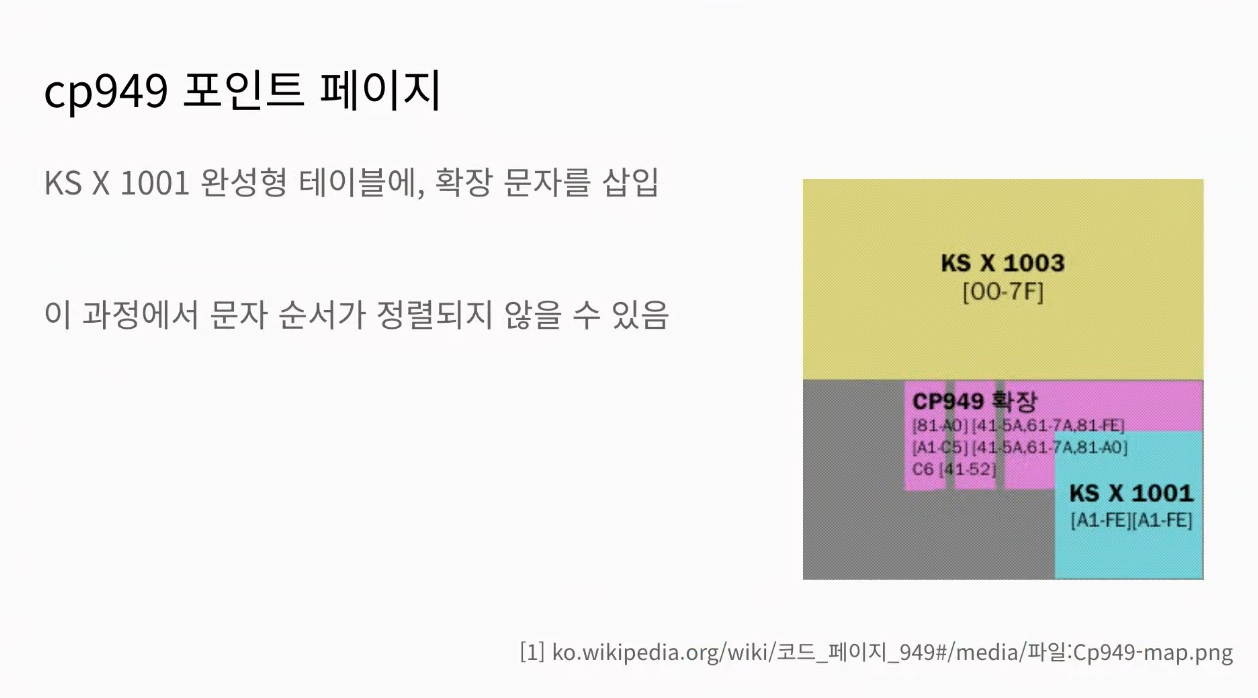
이러한 euc-kr의 문제를 해결하기 위해 나온 cp949라는 문자 셋이 있습니다. euc-kr의 2,350자를 제외한 나머지 글자까지 포함시킨 문자 셋입니다. 다만 이 cp949는 공식 이름은 아닙니다. HTML에서는 euc-kr로 표기하도록 되어 있죠. 다만 대부분의 머신에서 cp949로 처리를 합니다.

cp949는 2,350자의 위치를 유지하며 나머지 글자를 끼워 넣은 방식입니다. 따라서 가나다 정렬 순서가 맞지 않습니다. 아래 그림을 보면 노란색으로 표시되어 있는 앞부분은 기호나 숫자, 혹은 알파벳입니다. 그 뒤에 있는 KS X 1001이 최초의 2,350자입니다. 나머지 글자들을 저 보라색 영역에 끼워 넣은 형태입니다. 그러다 보니 cp949에 있는 문자열들을 가나다 순서대로 정렬하려면 별도로 순서를 맞추는 과정이 필요합니다.
그래서 euc-kr 문서의 인코딩이 깨지거나 잘못 처리한 경우에는 물음표, 또는 읽기 어려운 이상한 한글로 깨져서 나오게 됩니다.
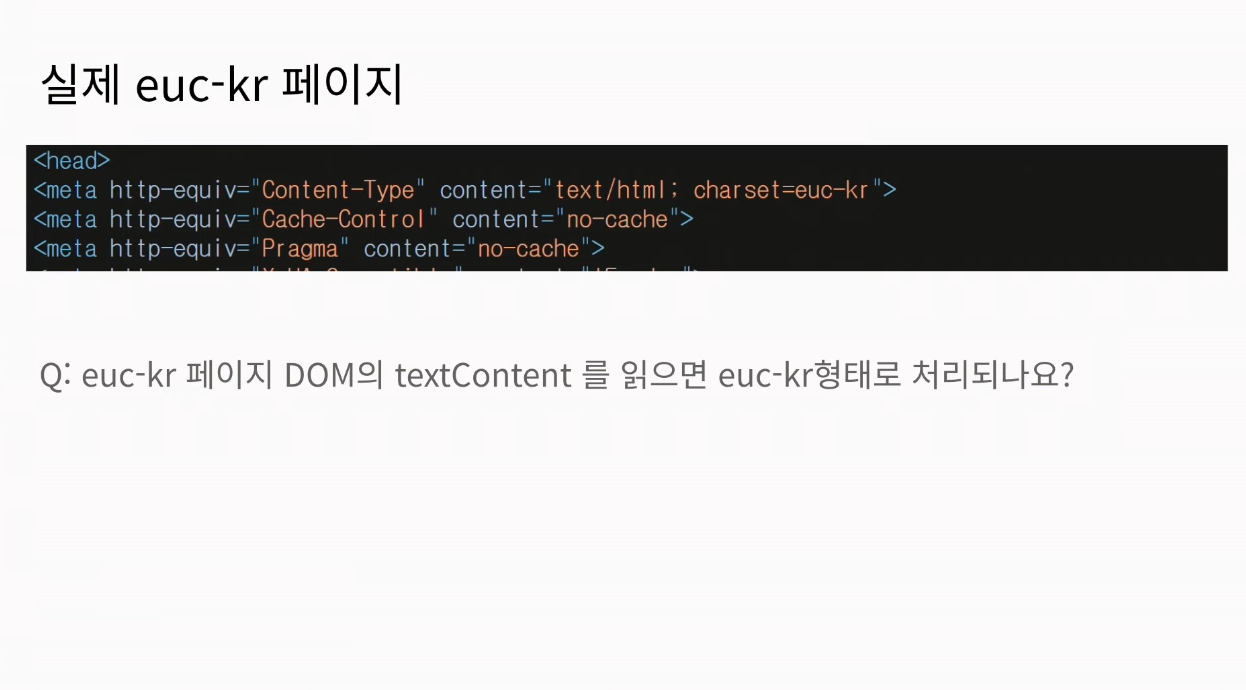
euc-kr로 이루어진 페이지는 보통 cp949로 표현합니다. 다만 실제 메타태그에는 아래와 같이 euc-kr로 저장을 하게 됩니다. 또 다른 의문점이 하나 생길 수 있습니다. euc-kr 페이지 DOM의 textContent를 읽으면 실제로 euc-kr로 처리가 될까요?
위 질문에 답하기 전, 그에 앞서 UTF-8을 알아보겠습니다.
UTF-8은 1992년에 고안되었습니다. 유니코드는 91년, 한글 표준이 87년도였으니, 비교적 최신 기술이라고 할 수 있습니다. UTF-8은 가변 길이로 텍스트를 표현하고, ASCII 코드 영역인 1바이트 영역부터 보통 3바이트, BMP 영역까지 표현합니다. 그래서 한글을 UTF-8로 표현하면 보통 3바이트 이하로 표현됩니다. 이모지는 4바이트로 표현됩니다.
*참고로 utf-8은 물리적으로 5바이트, 6바이트까지 표현할 수 있지만, 2003년 개정에서 5바이트 이상은 사용하지 않겠다고 선언했습니다.
그렇다면 자바스크립트에서 문자열은 어떻게 표현할까요? 자바스크립트는 UCS-2와 UTF-16을 주로 사용하여 문자열을 처리합니다. UCS-2란, 2바이트로 하나의 유니코드를 표현한다는 의미입니다. 다만 UCS-2는 BMP 영역까지만 표현할 수 있습니다. 그래서 좀 더 긴 영역을 표현하기 위한 방법으로 UTF-16을 사용합니다. UTF-16은 UCS-2표기를 그대로 준용하되, 이모지와 같은 더 긴 영역을 4바이트로 확장해서 표현하는 방법입니다.

UTF-8과 자바스크립트에서의 문자열 처리 방법에 대한 이해를 바탕으로 앞서 궁금증을 해결하겠습니다.
euc-kr 문서를 읽어 자바스크립트 변수에 저장하면 어떻게 될까요? 자바스크립트에서는 UCS-2로 변환되어 저장됩니다. 즉, 모든 브라우저는 여러 방법으로 인코딩된 문서를 읽지만, 이를 자바스크립트로 처리할 때는 UTF-16으로 바꿔서 저장하고 처리합니다.

그렇다면 많은 웹 문서가 UTF-8로 인코딩하는데, 왜 자바스크립트는 UTF-16으로 구현되었을까요? UTF-8은 알파벳이나 기호, ASCII 코드들은 1바이트에 표기를 하기에 압축해서 표현할 수 있으며, 한글이나 다른 기호들은 2바이트, 3바이트로 이어서 표기할 수 있습니다. 따라서 UTF-8은 전송에 유리한 표기법입니다.
다만, 그런 장점 대비 가변 길이 문자열의 길이를 구하는데 어려움이 있습니다. 자바스크립트는 어떤 길이의 문자열도 빠르게 처리하기 위해 모든 길이를 UTF-16 혹은 UCS-2로 표기합니다.
그렇다면 실제 자바스크립트에서는 어떻게 길이를 표현할까요? 아래 그림의 첫 번째 예시를 보면, 가로 막대 3개로 이루어진 특수문자는 UTF-16 문자 2개로 표현됩니다. 오리 이모지 같은 경우는 1F986 영역 즉, BMP 영역을 벗어났기 때문에 길이가 2입니다. 마지막으로 가족 이모지는 4명의 사람 이모지와 연결 글자를 포함해서 길이가 11이 됩니다.

앞선 UCS-2를 설명할 때, 자바스크립트는 모든 문자열을 2바이트로 처리한다고 했습니다. 그렇기 때문에 문자열에서 특정 문자를 확인하는 charAt은 무조건 2바이트 기반으로 값을 가져옵니다.

오리 이모지에 charAt(0)을 적용하면, ‘D83E’라고 하는 문자를 반환합니다. 반면 유니코드를 구하기 위해 codePointAt을 사용하면 ‘1F986’라는 값을 반환합니다.
지금까지 euc-kr과 UTF, 자바스크립트에서의 문자열 표현까지 알아봤습니다. 사실 이 문제는 윈도우에서 euc-kr를 사용해 생긴 문제만은 아닙니다. 맥에서도 동일한 문제가 발생하기 때문입니다.
다시 물음표 특수문자 그 자체에 대해 알아볼 필요가 있습니다. 유니코드 스펙에서 이 물음표 문자를 찾아보니 ‘U+FFFD’라는 BMP 영역의 끝자락에 기록된 문자란 것을 알게 되었습니다. 유니코드 스펙에서 이 문자는 유니코드로 표현이 불가능한 문자라고 설명하고 있습니다. 더 자세히, 유니코드 스펙 3.0을 살펴보니 아래와 같은 설명이 있습니다. ‘U+FFFD’라는 문자, UTF로 해석할 수 없는 값에 대해 추천하는 3가지 처리 방법입니다.

에러를 반환하거나, 해당 코드를 지우거나, U+FFFD 마커를 넣어 UTF 글자가 깨졌다는 것을 표기하라는 것입니다.
드디어 물음표 글자가 생기는 원인을 알았습니다. “UTF 상에서 글자가 깨졌기 때문”입니다. 이 힌트를 기반으로 제가 작성한 코드를 확인해 봤습니다.
에디터에서 발생하는 문제인지 살펴보니 http 응답상에는 문제가 없었습니다. DB에도 U+FFFD라는 표현이 저장되어 있으니 문제가 없다는 것도 확인했습니다. 마지막으로 백엔드 코드에서 문제가 생겼는지 살펴보았습니다. 곧 UTF-8 문자를 1000 바이트 단위 chunk로 나눠서 처리하는 코드를 발견했습니다.
3바이트인 UTF-8 한글 문자를 이 코드로 처리하다 보니 중간에 깨지는 문자가 생겼습니다. 다시 chunk에 toString을 실행하는 과정에서 U+FFFD가 생긴 것입니다.
문제를 알려준 매니저님의 말을 들어보니 항상 한글에서만 글자가 깨진다고 했습니다. 그 결과, 이 문제가 맞다는 확신을 가지게 되었습니다.
위와 같은 문제점을 확인하고 chunk를 쪼개는 과정에서 문자가 깨지지 않도록 백엔드 로직을 수정했고, 문제를 해결했습니다.
지금까지 물음표 문자가 생기는 이유를 알기 위해 유니코드에 대해 알아보고, 한글 문자 구성도 확인했고, euc-kr과 함께 UTF까지 알아봤습니다. 이 과정을 거쳐 유니코드의 U+FFFD라는 스펙까지 찾아냈고, 문제를 해결할 수 있었습니다.
이번 글로 한글이 어떤 식으로 저장이 되고, 브라우저에서는 어떤 식으로 표현되는지 기억해 주면 좋겠습니다. 또 제가 문제를 해결한 과정을 힌트 삼아 백엔드 인코딩 과정에서 문제가 생기지는 않았는지 살펴보면, 비슷한 문제를 해결하는 데 도움이 될 것이라 생각합니다.
요즘IT의 모든 콘텐츠는 저작권법의 보호를 받는 바, 무단 전재와 복사, 배포 등을 금합니다.

좋아요
댓글
공유
공유