개발
웹소켓으로 AWS 비용 10억을 날리고 얻은 교훈

9분
2024.12.23.인기
31.8K
본문은 요즘IT와 번역가 David가 함께 Recall.ai 의 엘리엇 르빈(Elliot Levin)의 글 <How WebSockets cost us $1M on our AWS bill>을 번역한 글입니다. Recall.ai의 엔지니어링 팀 리드로 활동하고 있으며, 고성능 비디오 및 오디오 데이터 처리 시스템의 개발을 주도하며, AWS 비용 최적화와 관련된 기술적 문제를 해결하는 데 기여했습니다. 이번 글에서는 클라우드 서비스 사용 시에는 비용 예측과 분석을 철저히 하고, 서비스 규모에 맞는 대체 기술을 고려하는 것이 중요하다는 점을 강조하고 있습니다.
필자에게 허락을 받고 번역했으며, 글에 포함된 각주(*표시)는 ‘번역자주’입니다. 글에 포함된 링크는 원문에 따라 표시했습니다.
IPC*는 클라우드 비용 최적화를 고려할 때 흔히 간과되는 부분입니다. 하지만 AWS에서 초당 1TB의 영상을 IPC로 처리할 때 비효율적으로 구현하면 엄청난 비용이 발생할 수 있다는 사실을 알게 되었습니다.
*IPC(Inter-Process Communication): 프로세스 간에 데이터를 주고받는 통신 방식
웹소켓* 사용으로 연간 100만 달러의 AWS 비용이 발생했던 사례와, 이를 해결하기 위해 고대역폭·저지연 IPC를 구현하게 된 과정을 심도 있게 분석해 보고자 합니다.
*웹소켓: 웹 브라우저와 서버 간의 실시간 양방향 통신을 가능하게 하는 통신 프로토콜
우리는 수백 개 기업에 미팅 봇 서비스를 제공하고 있습니다. 매월 수백만 건의 미팅을 처리하고 있으며, 이를 위해 방대한 인프라를 운영하고 있습니다. 또한 모든 인프라를 AWS에서 운영하고 있죠. 클라우드 컴퓨팅은 매우 편리하지만 비용이 많이 든다는 것이 단점이며, 이러한 이유로 성능과 효율이 매우 중요한 과제가 되었습니다. 고객들에게 더 효율적인 비용의 서비스를 제공하기 위해, 하드웨어의 성능을 최대한 끌어올리는 것을 목표로 하고 있습니다.
최근 몇 년간 클라우드 제공업체들의 GPU 가용성이 불안정했기 때문에, 저희는 GPU 대신 CPU에서 영상 처리를 수행하고 있습니다. 최적화 작업을 시작하기 전에는 봇이 원활하게 작동하기 위해 일반적으로 4개의 CPU 코어가 필요했는데요. 이 4개의 CPU 코어는 미팅 참여를 위한 헤드리스 크로미움*부터 미디어 수집을 위한 실시간 영상 처리 파이프라인까지 봇의 모든 기능을 처리했습니다.
*크로미움: 구글이 만든 오픈소스 웹 브라우저 프로젝트
*헤드리스 크로미움: GUI 없이 작동하는 크로미움 브라우저
저희는 CPU 사용량을 절반으로 줄이고, 이를 통해 클라우드 컴퓨팅 비용도 절반으로 낮추는 것을 목표로 설정했습니다. 이는 매우 도전적인 목표였으며, 첫 단계는 봇의 성능을 프로파일링하는 것이었습니다.
영상 처리에 매우 많은 컴퓨팅 자원이 필요하다는 것은 모두 알고 있는 사실입니다. 저희가 엄청난 양의 영상을 처리하고 있기 때문에, 처음에는 CPU 사용량의 대부분이 영상 인코딩과 디코딩에 사용될 것이라고 예상했습니다.
하지만 실행 중인 봇들을 프로파일링해 보니 충격적인 사실을 발견했습니다. CPU 시간의 대부분이 __memmove_avx_unaligned_erms와 __memcpy_avx_unaligned_erms 이 두 함수에 사용되고 있던 것입니다. 이 함수들이 하는 일을 간단히 설명하겠습니다.
memmove와 memcpy는 메모리 블록을 복사하는 C 표준 라이브러리 함수입니다. memmove는 중첩된 메모리 범위로 복사할 때 발생하는 몇 가지 예외 상황을 처리하지만, 큰 틀에서 보면 이 두 함수 모두 “메모리 복사”를 수행하는 함수라고 볼 수 있습니다.
avx_unaligned_erms 접미사는 이 함수가 고급 벡터 확장(AVX)을 지원하는 시스템에 최적화되어 있으며, 정렬되지 않은 메모리 접근에도 최적화되어 있다는 의미입니다. erms는 Enhanced REP MOVSB/STOSB의 약자로, 최신 인텔 프로세서에서 빠른 메모리 이동을 위한 최적화를 의미합니다. 간단히 말해 이 접미사는 “특정 프로세서에 최적화된 더 빠른 구현”이라고 이해하면 됩니다.
프로파일링 결과, 이러한 함수들을 가장 많이 호출하는 것은 데이터를 수신하는 파이썬 웹소켓 클라이언트였고, 다음으로는 데이터를 전송하는 크로미움의 웹소켓 구현이었습니다.
이러한 결과를 곰곰이 생각해 보니 이해가 되기 시작했습니다. 헤드리스 크로미움을 사용해 통화에 참여하는 봇들의 경우, 크로미움의 자바스크립트 환경에서 디코딩된 원본 영상을 인코더로 전송하는 방법이 필요했습니다. 처음에는 로컬 웹소켓 서버를 실행하고, 자바스크립트 환경에서 이에 연결한 뒤, 해당 채널을 통해 데이터를 전송하는 방식을 채택했죠.
웹소켓은 저희가 원하는 기능에 잘 맞는 것처럼 보였습니다. 웹 API 중에서는 빠른 편이었고, JS 런타임 내에서 사용하기 편리했으며, 바이너리 데이터를 지원했고요. 가장 중요한 점은 크로미움에 이미 내장되어 있었다는 것입니다. 여기서 복잡한 요소는 원본 영상의 대역폭이 놀라울 정도로 크다는 점이었습니다. 1080p 30fps의 단일 영상 스트림은 비압축 I420 형식으로 1080 * 1920 * 1.5 (픽셀당 바이트) * 30 (초당 프레임) = 93.312MB/s나 됩니다.
저희의 모니터링 결과에 따르면, 전체 규모에서 p99 봇은 초당 150MB의 영상 데이터를 수신합니다. 이는 엄청난 양의 데이터 이동입니다. 다음 단계는 웹소켓 전송이 왜 이렇게 많은 컴퓨팅 자원을 소모하는지 구체적인 원인을 파악하는 것이었습니다. 새로운 문제를 만들지 않고, 웹소켓의 단점을 피할 수 있는 해결책을 찾기 위해서는 근본 원인을 찾아야 했습니다.
웹소켓 RFC와 크로미움의 웹소켓 구현을 살펴보고 프로파일 데이터를 분석한 결과, 두 가지 주요 성능 저하 원인을 발견했습니다. 바로 단편화와 마스킹입니다.
웹소켓 명세는 메시지 단편화를 지원합니다. 이는 큰 메시지를 여러 웹소켓 프레임으로 나누는 과정입니다.
단편화의 주된 목적은 메시지를 시작할 때 크기를 알 수 없는 메시지를 버퍼링하지 않고도 전송할 수 있게 하는 것입니다. 단편화가 불가능하다면, 첫 바이트를 전송하기 전에 전체 메시지를 버퍼링하여 길이를 계산해야 할 것입니다. 단편화를 통해 서버나 중간 매개체는 적절한 크기의 버퍼를 선택하고, 버퍼가 가득 차면 단편을 네트워크로 전송할 수 있습니다.
단편화의 부차적인 용도는 멀티플렉싱*입니다. 하나의 논리적 채널에서 큰 메시지가 출력 채널을 독점하는 것이 바람직하지 않을 때, 멀티플렉싱은 메시지를 더 작은 단편으로 나누어 출력 채널을 더 잘 공유할 수 있게 해야 합니다.
*멀티플렉싱: 하나의 통로나 자원을 통해 여러 신호나 데이터를 동시에 전송하는 기술
서로 다른 웹소켓 구현은 각기 다른 기준을 가지고 있습니다. 크로미움 웹소켓 소스코드를 살펴보면, 131KB보다 큰 메시지는 여러 웹소켓 프레임으로 단편화됩니다. 1080p 원본 영상 프레임 하나의 크기는 1080 * 1920 * 1.5 = 3110.4 KB이므로, 크로미움의 웹소켓 구현은 이를 24개의 개별 웹소켓 프레임으로 단편화하게 됩니다. 이는 너무나 많은 복사와 중복 작업을 발생시킵니다.
웹소켓 명세는 클라이언트에서 서버로 전송되는 데이터가 반드시 마스킹 되어야 한다고 규정합니다.
네트워크 중개자(인터셉터와 같은,,)의 혼란을 방지하고 10.3절에서 자세히 설명하는 보안상의 이유로, 클라이언트는 서버로 전송하는 모든 프레임을 반드시 마스킹해야 합니다.
데이터 마스킹은 32비트 랜덤 마스킹 키를 생성하고, 원본 데이터의 바이트를 32비트 단위로 이 마스킹 키와 XOR 연산하는 과정입니다. 이는 클라이언트가 네트워크상에 나타나는 바이트를 제어하지 못하게 함으로써 보안상의 이점을 제공합니다. 이것이 중요한 정확한 이유를 알고 싶다면, 여기에서 살펴볼 수 있습니다.
이는 보안 측면에서는 훌륭하지만, 웹소켓으로 전송되는 모든 바이트를 한 번 더 처리해야 한다는 단점이 있습니다. 일반적인 웹 사용에서는 큰 문제가 되지 않지만, 초당 100MB 이상을 처리할 때는 상당한 작업량이 됩니다.
웹소켓을 대체할 필요성을 인식하고, 크로미움에서 데이터를 추출할 새로운 메커니즘을 찾기 시작했습니다. 웹소켓보다 훨씬 더 효율적인 것을 원한다면 브라우저 API가 심각하게 제한적이라는 것을 빠르게 깨달았습니다. 이는 크로미움을 포크하고 커스텀 구현이 필요하다는 것을 의미했습니다. 하지만 이는 동시에 효율성 측면에서 무한한 가능성이 열렸다는 의미이기도 했습니다. 우리는 세 가지 옵션을 고려했습니다: raw TCP/IP*, 유닉스 도메인 소켓, 그리고 공유 메모리입니다.
*TCP: 인터넷에서 데이터를 안전하고 순서대로 전달하기 위한 통신 규약
*IP: 인터넷에서 컴퓨터들이 서로를 찾고 통신하기 위한 주소 체계
크로미움의 웹소켓 구현과 웹소켓 명세 자체가 특히 나쁜 성능 문제를 일으킵니다. 한 단계 더 깊이 들어가서 루프백* 장치를 통해 raw TCP/IP 패킷을 전송할 수 있도록, 크로미움에 확장 기능을 추가하는 것은 어떨까요?
*루프백: 네트워크 통신에서 자기 자신을 가리키는 특별한 주소나 경로
이렇게 하면 웹소켓의 단편화와 마스킹 문제를 우회할 수 있고, 구현도 상당히 간단할 겁니다. 또한 루프백 장치는 최소한의 지연만을 발생시킬 거고요. 하지만 몇 가지 단점이 있었습니다. 첫째, TCP/IP 패킷의 최대 크기가 저희의 원본 영상 프레임 크기보다 훨씬 작아서, 여전히 단편화 문제가 발생합니다.
이더넷으로 연결된 일반적인 TCP/IP 네트워크에서는 표준 MTU(Maximum Transmission Unit)가 1500바이트이며, 이로 인해 TCP MSS(Maximum Segment Size)는 1448바이트입니다. 이는 저희의 3MB+ 원본 영상 프레임보다 훨씬 작습니다.
TCP/IP 패킷의 이론상 최대 크기인 64k조차도 저희가 전송해야 하는 데이터보다 훨씬 작으므로, 단편화 없이 TCP/IP를 사용하는 것은 불가능했습니다. 또 다른 문제도 있었습니다. 리눅스 네트워킹 스택이 커널 공간에서 실행되기 때문에, TCP/IP를 통해 전송하는 모든 패킷은 사용자 공간에서 커널 공간으로 복사되어야 합니다. 대용량 데이터를 전송할 때 이는 상당한 오버헤드를 추가합니다.
네트워킹 스택을 완전히 벗어나 전통적인 유닉스 도메인 소켓을 사용하는 방안도 검토했습니다. IPC를 위한 고전적인 선택이며, 유닉스 도메인 소켓이 실제로 상당히 빠를 수 있다는 것이 밝혀졌습니다. 가장 중요한 점은 유닉스 도메인 소켓이 저희 봇이 실행되는 리눅스 운영체제의 기본 기능이며, 유닉스 소켓을 통해 데이터를 전송하는 기존의 함수와 라이브러리가 있다는 것입니다.
하지만 한 가지 단점이 있습니다. 유닉스 도메인 소켓을 통해 데이터를 전송하려면 사용자 공간에서 커널 공간으로, 그리고 다시 되돌아오는 복사 과정이 필요합니다. 저희가 다루는 데이터양을 고려하면, 이는 상당한 오버헤드입니다.
여기서 한 단계 더 나아갈 수 있다는 것을 깨달았습니다. TCP/IP와 유닉스 도메인 소켓 모두 최소한 사용자 공간과 커널 공간 사이의 데이터 복사가 필요합니다. 약간의 DIY를 통해 공유 메모리를 사용하면, 더욱 효율적으로 만들 수 있었습니다. 공유 메모리는 여러 프로세스가 동시에 접근할 수 있는 메모리입니다. 이는 크로미움이 메모리 블록에 쓴 데이터를 영상 인코더가 중간에 어떤 복사도 필요 없이 직접 읽을 수 있다는 것을 의미합니다.
하지만 공유 메모리를 통한 데이터 전송에는 표준 인터페이스가 없습니다. TCP/IP나 유닉스 도메인 소켓과 같은 표준이 아닙니다. 공유 메모리 방식을 선택한다면, 전송 계층을 처음부터 직접 구축해야 하며, 많은 문제가 발생할 수 있습니다.
AWS 청구서를 흘깃 보니 앞으로 나아갈 결심이 섰습니다. 최대의 효율성을 위해서는 공유 메모리가 최선의 선택이었습니다.
지속적으로 공유 메모리에 데이터를 순차적으로 읽고 쓸 필요가 있었기 때문에, 상위 레벨 전송 설계로 링 버퍼를 선택했습니다. 러스트 커뮤니티에는 여러 링 버퍼 구현체가 있지만, 저희 구현에는 몇 가지 특별한 요구사항이 있었습니다.
기존의 링 버퍼 구현체들을 평가해 봤지만, 저희의 요구사항에 맞는 것을 찾지 못했습니다. 그래서 직접 구현하기로 했습니다.
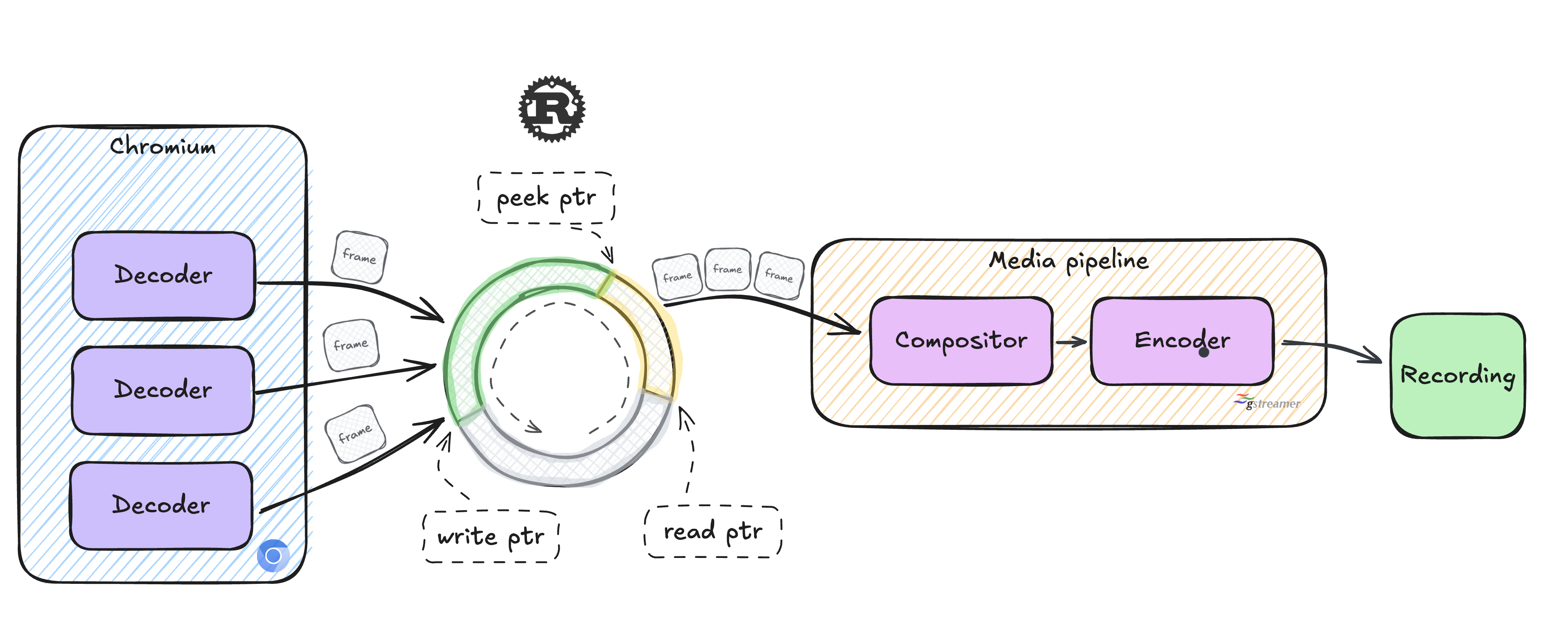
저희 링 버퍼 구현에서 가장 비표준적인 부분은 복사 없는 읽기 기능 지원입니다. 일반적인 두 개의 포인터 대신 세 개의 포인터를 사용합니다.
복사 없는 읽기 기능을 지원하기 위해 엿보기 포인터의 프레임을 미디어 파이프라인에 제공하고, 프레임이 완전히 처리된 후에만 읽기 포인터를 전진시킵니다. 이는 미디어 파이프라인이 링 버퍼 내부의 데이터에 대한 참조를 안전하게 유지할 수 있다는 것을 의미합니다. 데이터가 완전히 처리되고 읽기 포인터가 전진할 때까지 해당 참조가 유효하다는 것이 보장되기 때문이죠.
포인터를 스레드 세이프 한 방식으로 업데이트하기 위해 단일 연산을 사용하고, 새로운 데이터나 버퍼 공간이 사용 가능함을 알리기 위해 명명된 세마포어를 사용합니다. 이 링 버퍼를 구현하고 다른 몇 가지 최적화와 함께 프로덕션에 배포한 후, 봇의 CPU 사용량을 최대 50%까지 줄일 수 있었습니다.
이처럼 CPU 효율성을 높이기 위한 IPC 최적화 작업은 AWS 비용을 연간 100만 달러 이상 절감하는 성과로 이어졌습니다. 이는 단순한 기술적 개선을 넘어, 시간과 자원을 투자할 가치가 있던 매우 큰 성과라고 할 수 있습니다.
<원문>
How WebSockets cost us $1M on our AWS bill
©️위 번역글의 원 저작권은 Elliot Levin에게 있으며, 저작권법의 보호를 받는 바, 무단 전재와 복사, 배포 등을 금합니다