개발
트랜잭셔널 메시징에도, 그냥 PostgreSQL 쓰세요

5분
2024.11.06.인기
14.1K
애플리케이션을 개발하다 보면 데이터 분석을 위해 다른 시스템으로 데이터를 보내거나 사용자에게 알림을 주기 위해 문자와 메일을 보내는 등 비동기로 처리해야 하는 상황을 생각보다 자주 맞이한다. 해결 방법으로 흔히 아파치 카프카(Apache Kafka)나 AWS SQS 같은 메시지 큐(Message Queue)를 도입하곤 한다. 다만 문제는 애플리케이션 데이터베이스와 메시지 큐를 데이터베이스 단일 트랜잭션으로 묶기 어려워 데이터 일관성이 깨질 수 있다는 것이다.
예를 들어, 비즈니스 로직에 의해 데이터베이스를 수정한 다음 메시지 큐에 메시지를 보낸다. 이때 트랜잭션 내에서 수행한 후속 비즈니스 로직에서 오류가 생기면 데이터베이스는 롤백(Rollback)될 것이다. 그러나 메시지 큐에 보낸 메시지를 다시 회수하기는 어렵다.
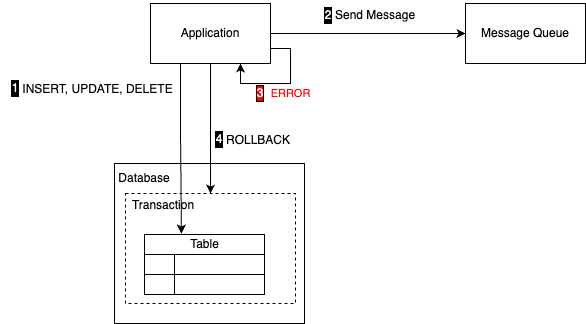
이를 막기 위해 순서를 바꿔 중간에 메시지를 보내는 대신 데이터베이스 트랜잭션 커밋 후에 메시지를 보낼 수도 있다. 하지만 네트워크 문제는 놀랄 만큼 흔하기에 장애로 메시지를 보내는 데 실패할 수 있다. 이러한 실패에 대비하려면 어디엔가 메시지를 저장하고 다시 시도해야 한다. 이 ‘어디엔가 저장해야 한다’는 전제는 우리를 다시 데이터 일관성 문제로 보낸다.
트랜잭셔널 메시징(Transactional Messaging)은 이러한 문제를 해결한다. 트랜잭셔널 메시징이란 “메시지를 데이터베이스 트랜잭션의 일부로 발행하는 것”을 의미한다.* 애플리케이션 비즈니스 로직에 의해 데이터베이스를 수정하는 작업과 메시지 큐에 메시지를 발행하는 작업, 두 가지 작업을 원자적으로 수행하여 데이터 일관성을 보장하는 것이다.
*마이크로서비스 패턴, 크리스 리처드슨, 길벗
이 글에서는 트랜잭셔널 메시징을 구현하는 두 가지 패턴을 소개한다. 이어 포스트그레스큐엘(PostgreSQL)을 이용하여 이를 더 단순하게 만드는 방법을 다룬다.
<마이크로서비스 패턴>의 저자 크리스 리차드슨은 트랜잭셔널 메시징을 구현하는 두 가지 패턴을 언급한다. 두 패턴 모두 아웃박스(Outbox)라는 테이블을 메시지 큐로 사용한다.
먼저 소개할 패턴은 트랜잭셔널 아웃박스(Transactional outbox) 패턴으로, 메시지 큐에 메시지를 바로 보내지 않고 데이터베이스의 아웃박스 테이블에 넣는 방식이다. 이어 데이터베이스 트랜잭션이 커밋되면 주기적으로 아웃박스 테이블 내용을 읽어 메시지 큐에 보내는 것이다.
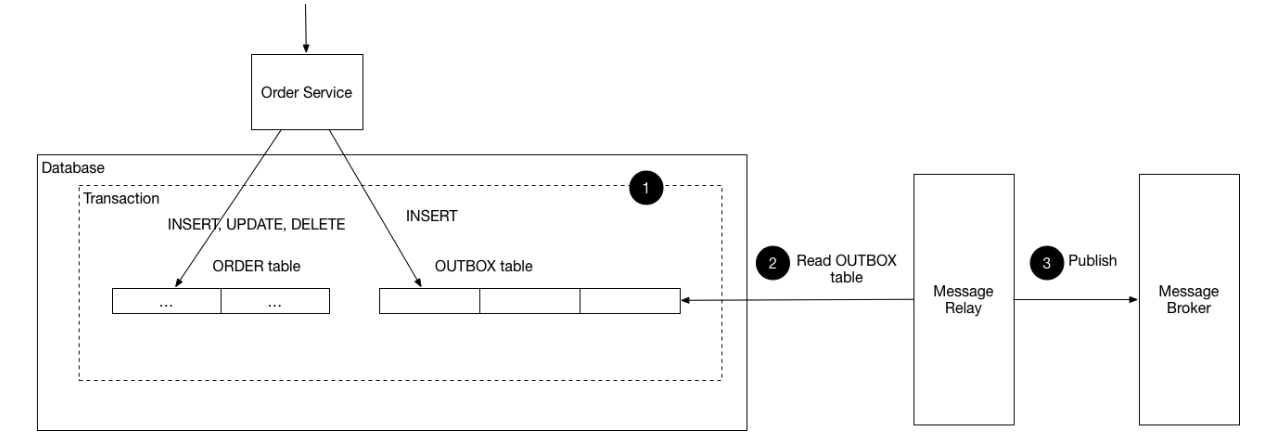
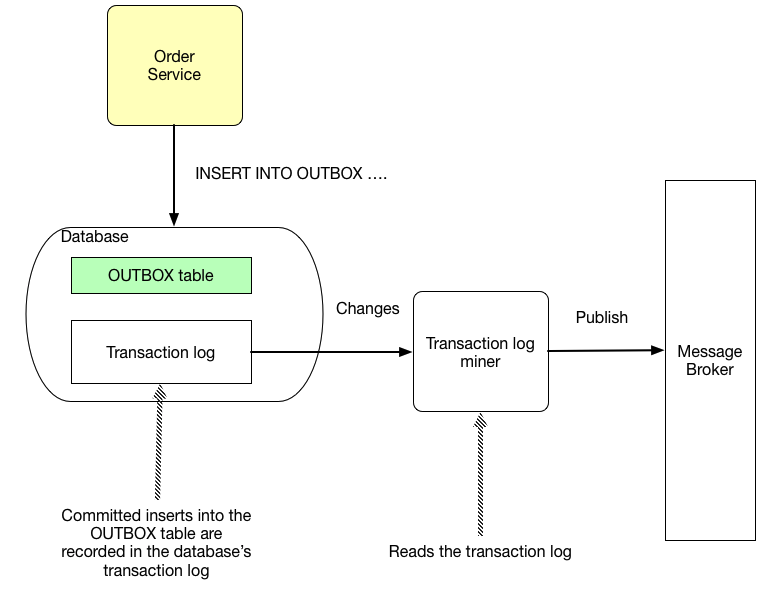
또 다른 하나는 트랜잭션 로그 테일링(Transaction log tailing) 패턴이다. 아웃박스 테이블에 큐에 보낼 메시지를 저장하는 것까지는 같지만 아웃박스 테이블의 내용을 읽는 방식이 다르다. 이 패턴을 적용하면 데이터베이스의 트랜잭션 로그*를 읽고 아웃박스 테이블의 데이터 변경만을 필터링(Transaction log miner)해 메시지 큐에 보낸다.
*데이터베이스는 변경 사항(예. 테이블 생성, 테이블 데이터 변경 등)을 로그로 기록하는 데 이를 트랜잭션 로그 혹은 바이너리 로그라고 부른다.
1986년 튜링상 수상자이자 책 <맨먼스의 미신>, 그리고 “은탄환은 없다”라는 말로 잘 알려진 프레드 브룩스는 소프트웨어 엔지니어링에서 복잡성을 두 가지 유형(Types of complexity)으로 구분한다.
본질적 복잡성은 도메인 자체에서 비롯되는 복잡성이다. 즉, 비즈니스 범위를 줄이지 않고는 제거할 수 없는 것으로 쉽게 말하자면 다루는 업무가 복잡한 것이다.*
* 복잡한 업무 예시는 ‘복잡한 업무 코드를 빠르게 분석하기’를 참고하라.
반면 우발적 복잡성은 최적화나 통합 등의 이유로 도입한 프레임워크, 데이터베이스들에서 비롯되는 복잡성이다.
비동기 처리를 위해 메시지 큐를 도입하고, 데이터베이스와 메시지 큐 사이의 데이터 일관성을 보장하려 트랜잭셔널 아웃박스 혹은 트랜잭션 로그 테일링을 구현하는 과정은 이러한 우발적 복잡성을 증가시킨다.
나는 시스템을 설계할 때 불필요한 복잡성을 제거하는 쪽으로 만들어야 한다고 생각한다. 경험적으로 소프트웨어 비용 중 많은 부분이 의사소통으로 소비되기 때문이다. 시스템이 단순할수록 그만큼 의사소통할 일도 줄어든다.
얼마 전 ‘그냥 Postgres 쓰세요’라는 글이 뜨거운 관심을 받았다. 비슷한 결로 이전에는 ‘PostgreSQL면 충분하다’라는 글도 있었다. 이런 글은 포스트그레스큐엘이 객체-관계 데이터베이스(object-relational database)를 표방*하고 있지만, 확장을 통해 메시지 큐, 그래프, 캐시, 벡터 등을 지원한다는 사실을 바탕으로 쓰였다.
*포스트그레스큐엘 공식 문서: What is PostgreSQL

이러한 포스트그레스큐엘의 다양한 쓰임새는 규모가 작거나 MVP(Minimum Viable Product)를 만들어 결과를 빨리 내야 하는 조직에 매력적이다. 기술 스택이 불필요하게 복잡해지는 것을 막아 우발적 복잡성을 증가시키지 않고 더 단순하게 해결할 방법을 제시해 주기 때문이다.
첫머리에서 언급한 것처럼 트랜잭셔널 메시징의 핵심은 애플리케이션 비즈니스 로직에 의해 데이터베이스를 수정하는 작업과 메시지 큐에 메시지를 발행하는 작업, 두 작업의 원자적 수행이다. 문제는 데이터베이스와 메시지 큐를 단일 트랜잭션으로 묶기 어려운 데 있었다.
PGMQ(Postgres Message Queue)는 포스트그레스큐엘을 메시징 큐로 확장한 것이다. 포스트그레스큐엘과 PGMQ를 함께 사용하면 데이터베이스 단일 트랜잭션으로 두 가지 작업을 묶을 수 있다. 비즈니스 로직을 수행하다 오류로 트랜잭션을 롤백하면, PGMQ에 넣었던 메시지 역시 함께 롤백한다는 뜻이다.
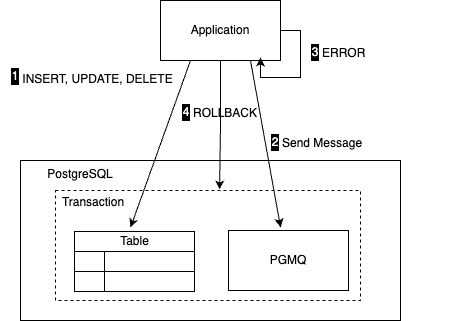
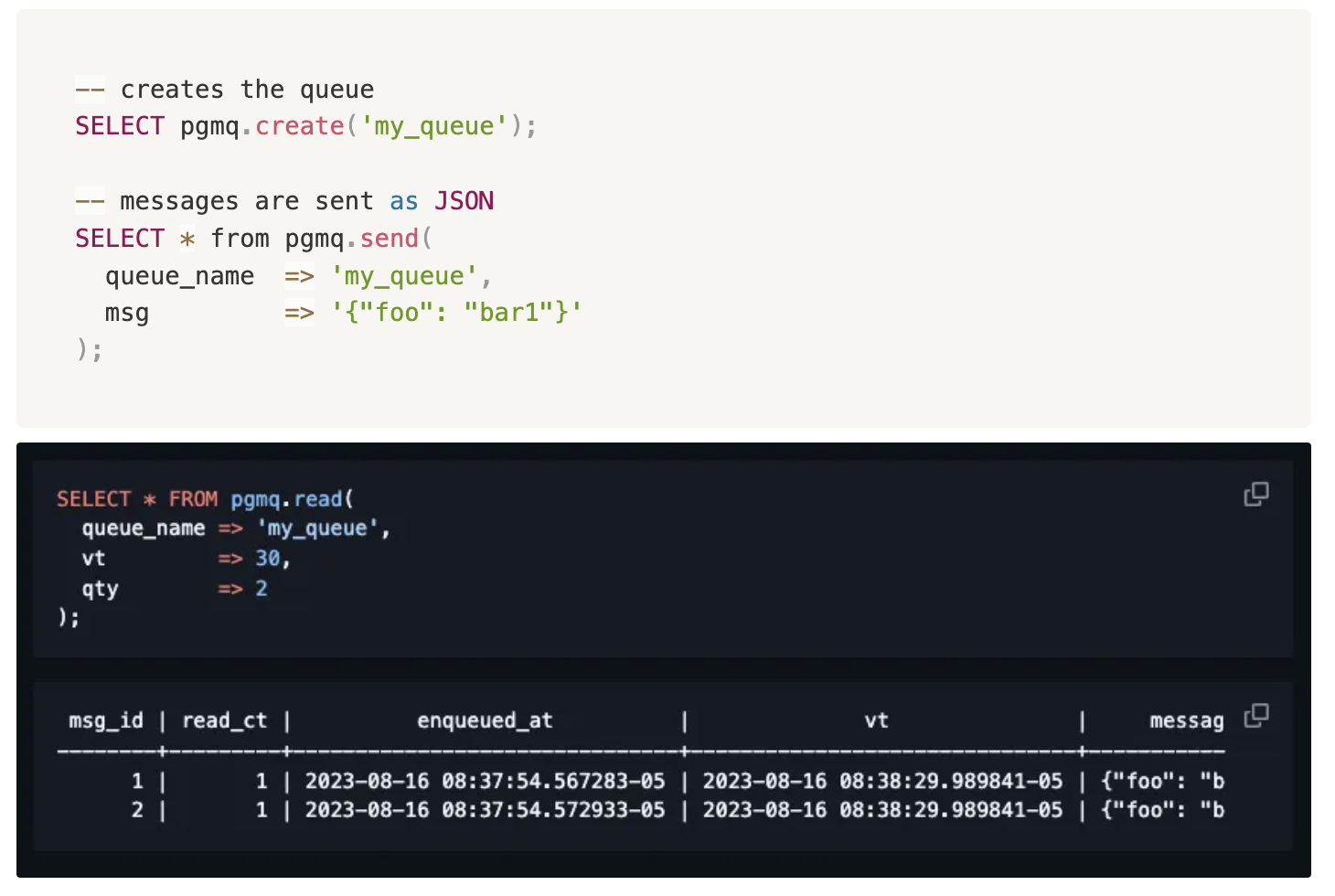
PGMQ 사용법은 매우 단순하다. 포스트그레스큐엘 데이터베이스 안에서 SQL을 사용하기 때문이다.
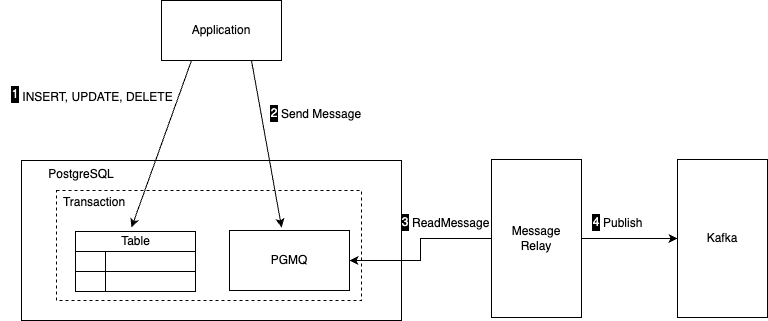
분산 환경 중앙에 카프카를 두고 데이터를 통합하는 시나리오에서 카프카로 메시지를 보낼 때에도 이 방식은 유효하다. PGMQ의 메시지를 읽어 카프카로 보내는 메시지 릴레이(MessageRelay)를 추가할 수 있기 때문이다.
누군가는 이렇게 쓰면 “아웃박스 테이블을 쓰는 것과 무엇이 다르냐”고 반문할 수 있겠다. 그러나 트랜잭셔널 아웃박스 패턴에서는 아웃박스 테이블을 직접 구성해야 한다. 또, 메시지를 다시 보내지 않기 위해 메시지 큐에 보낸 메시지를 삭제하거나 표시하는 메커니즘 역시 직접 구현해야 한다. 게다가 아웃박스 테이블을 큐로 사용하기 때문에 메시지 릴레이가 여러 개가 될 경우, EIP(Enterprise Integration Patterns)에서 말하는 경쟁 소비자(Competing Consumers)까지 고려해야 한다.
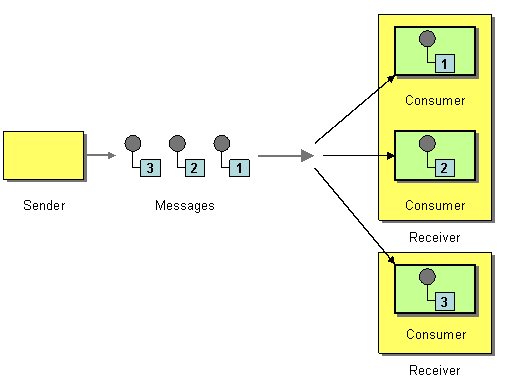
반면 PGMQ는 메시지를 삭제하는 메커니즘을 제공한다. 그뿐만 아니라 메시지를 읽을 때 VT(Visibility Timeout) 옵션을 제공하기 때문에 경쟁 소비자를 구현하는 게 손쉽다.
트랜잭셔널 메시징은 생각보다 다루기 까다로운 문제다. 그러나 포스트그레스큐엘로 우발적 복잡성을 증가시키지 않고 더 단순하게 문제를 다룰 수 있다.
나는 모든 곳에 포스트그레스큐엘을 쓰자고 주장하는 것은 아니다. 각자가 처한 맥락에 따라 기술 선택은 달라질 수밖에 없기 때문이다. 다만 어떤 기술이 내가 처한 맥락에서 효율적인지 판단하기 위해서는 여러 선택지를 알아야 하는 법이다. 이 글이 기술 선택을 고민하는 개발자에게 다양한 선택지 중 하나가 되기를 바란다.
©️요즘IT의 모든 콘텐츠는 저작권법의 보호를 받는 바, 무단 전재와 복사, 배포 등을 금합니다.