개발
API 게이트웨이 톺아보기: 스로틀링과 알고리즘 구현

7분
2023.02.16.15.3K

요즘 대부분의 개발자는 마이크로서비스 아키텍처(Microservice Architecture, 이하 MSA)를 한 번쯤은 들어봤을 것입니다. 마이크로서비스 아키텍처를 포함하여 모든 분산시스템 환경에서는 네트워크를 통해서 데이터를 주고받습니다. 이때 API(Application Programming Interface)를 이용합니다. API는 HTTP, Websocket 등의 프로토콜과 Json, XML 등의 데이터 포맷 방식과 함께 요청 작업의 식별자를 제공하는 것을 말합니다.
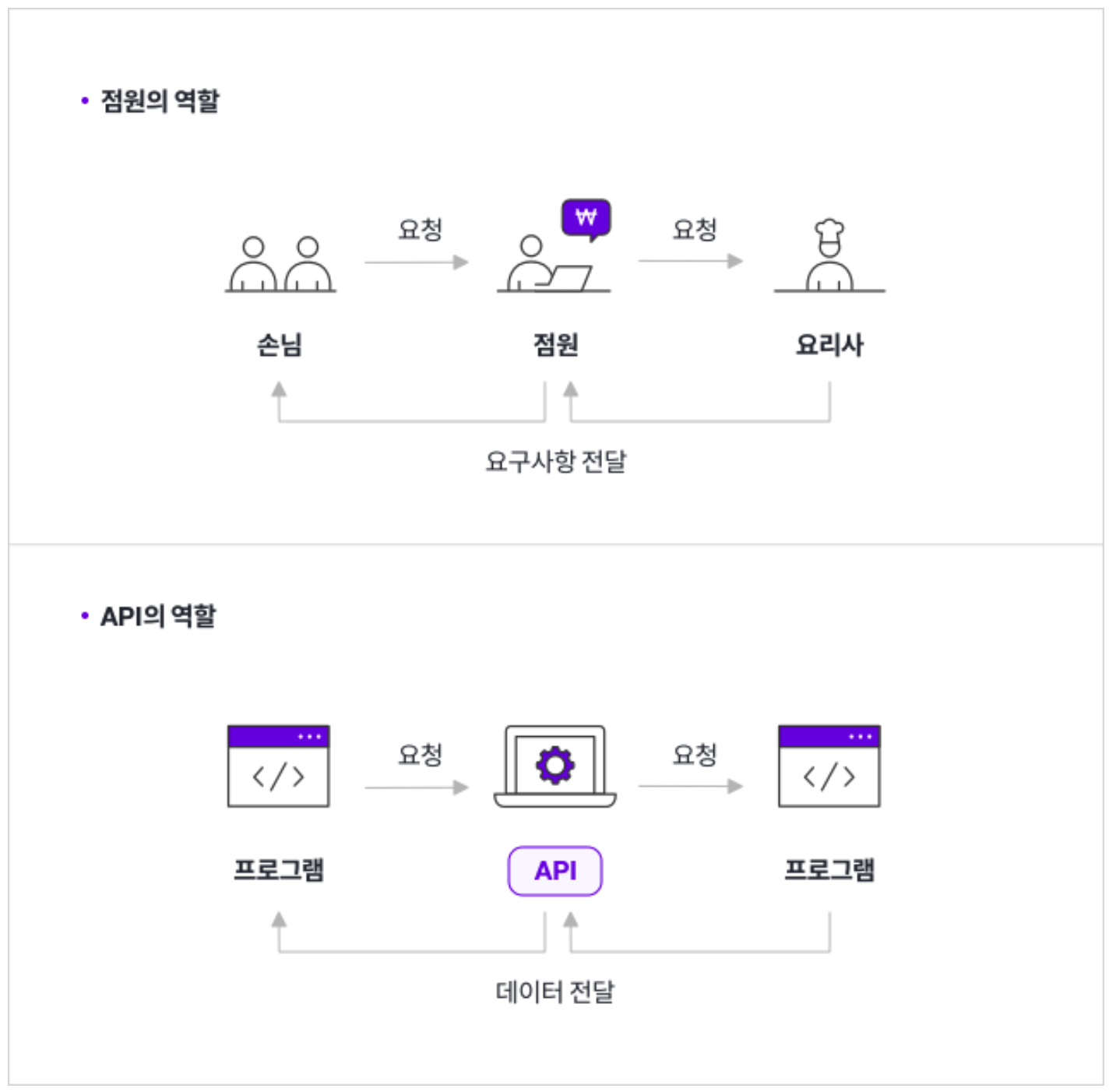
API는 다른 시스템에게 데이터의 조회, 생성, 삭제, 수정을 요청하기 위해 사용됩니다. 특히 빠른 시간 주기로 데이터가 추가되거나 갱신되는 데이터를 활용할 때 API를 이용합니다. 일반적으로 API는 사용자가 API 클라이언트 도구를 이용해서 직접 사용하는 일은 거의 없습니다. API 호출 테스트를 할 때를 제외하고는 대부분이 자동화된 프로세스에 연동하여 사용합니다. 그렇기에 자동화된 프로세스라는 사용자의 특성으로 인해 API 개발자들은 비밀성과 가용성 부분에서의 보안적인 요소나 사용량 제어 등의 목표를 위해서 API 게이트웨이(API Gateway)를 이용합니다.
이번 글에서는 API를 제공하는 시스템에서 꼭 고려해야 하는 API 게이트웨이와 기능 중 하나인 API 스로틀링(Throttling), 관련 알고리즘에 대해 살펴보고자 합니다.
API를 제공하는 시스템에서는 보안을 위해서 필요한 항목이 많습니다. 특히 비밀성과 가용성 보장 등을 위한 구현을 반드시 고려해야 합니다. MSA 환경에서는 해당 기능의 책임을 별도의 모듈시스템으로 분리하고, API 게이트웨이로 부르는 패턴을 이용합니다. (API-Gateway-Pattern 참고)
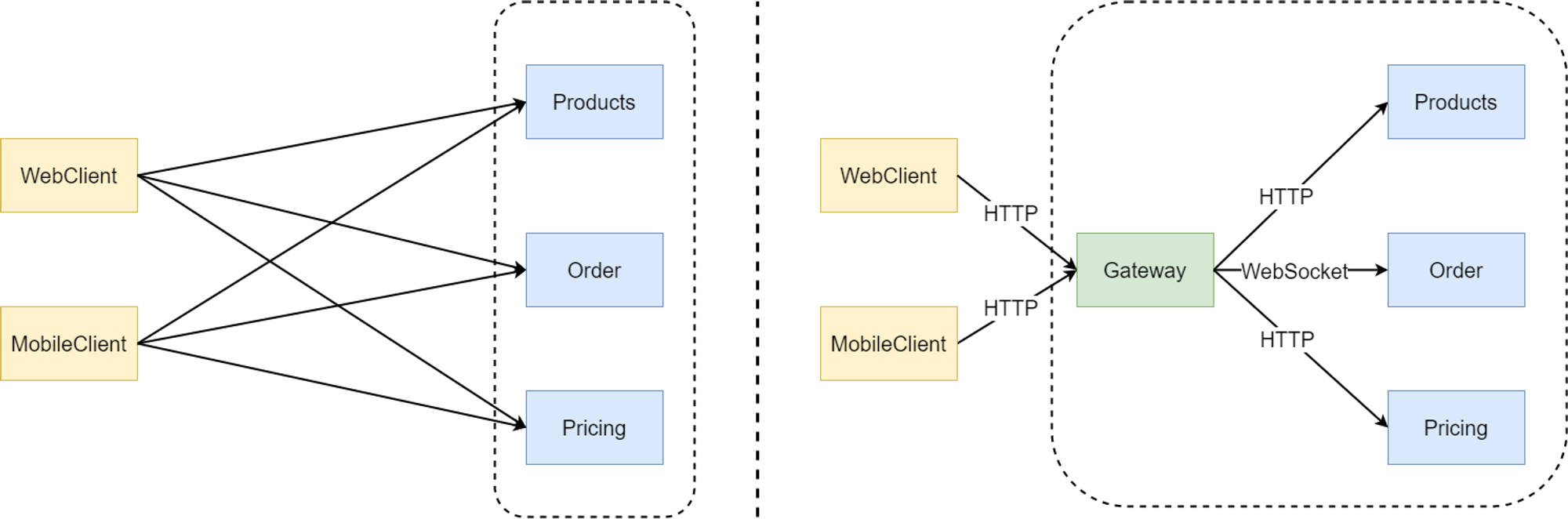
API 게이트웨이의 역할과 책임은 인증과 권한 등의 자원 접근에 대한 비밀성을 보장하고자 할 때와 API 시스템으로의 트래픽의 과도한 증가로 인한 비가용적인 상황을 막기 위해, 속도의 제한이나 부하의 분산 등을 위해서 사용됩니다. API 게이트웨이는 일반적으로 다음과 같은 목적으로 사용합니다.
API 스로틀링(Throttling, 이하 스로틀링)은 API 요청에 속도와 횟수를 제한하는 것을 말합니다. 이를 속도 제한(Rate Limit) 기능으로 부르기도 합니다.
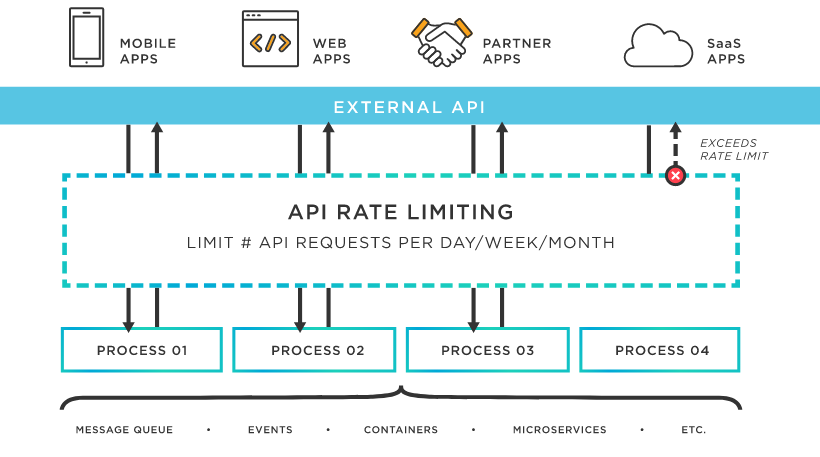
API 스로틀링은 먼저 보안성 강화를 위해서도 이용합니다. 만약 특정 사용자가 만든 프로그램이 버그가 있어서 요청량이 폭증하거나, 악의적인 사용자가 DoS(Denial of service)와 같은 공격을 시도해서 API 요청과 응답시간이 늦거나 안된다고 가정해 보겠습니다. 이런 경우 서비스 가용성(Availability)에 문제가 생겼다고 하며, API 시스템의 보안성 강화를 위해 API 스로틀링을 사용합니다.
또한 과금의 조율을 위해서도 API 스로틀링을 사용합니다. 만약 API를 이용하는 회사 A와 B가 있고, 모든 사용자는 정상적인 이용을 하고 있다고 가정해 봅시다. 그런데 A 사의 API 요청 건이 B 사의 요청 건보다 훨씬 많은데, 계약 금액은 B 사가 더 높습니다. 이때 어떤 선택을 할 수 있을까요?
가장 먼저 서버의 CPU나 메모리 등을 업데이트하는 스케일업이나, 분산처리를 위해 동일 스펙의 시스템을 추가로 구입하여 늘리는 스케일아웃을 통해 서버 자원을 확장하는 방법이 있습니다. 그런데 이 선택은 API 제공 회사의 비용 부담으로 확장되는 방법입니다.
이 방법은 API 제공 회사가 서비스를 통해 얻는 수익이 서버 자원 확장 비용보다 많다면 문제가 되지 않습니다. 그러나 API 제공 회사에서 서버 자원을 확장하는 비용이 API 서비스를 이용하는 회사들과 계약한 금액보다 높은 경우에는 난처할 것입니다. 수익성이 별로 없는 사업임에도 울며 겨자 먹기로 시스템 운영을 해야 하는 상황일 테니까요. A 사와의 계약 파기를 통해 해결할 수도 있지만, 만약 A사와 우호적인 관계를 유지해야 한다면 선택은 더 어려워질 것입니다.
위와 같은 일이 벌어지지 않으려면 API를 개발할 때 API 게이트웨이를 통해 API 스로틀링을 도입하여, 각 회사의 요청 속도를 제어할 수 있어야 합니다. 그래야 원활한 SLA(Service Level Agreement, 주로 호스팅 업체가 사용자와 맺는 계약) 협의가 가능하기 때문입니다.
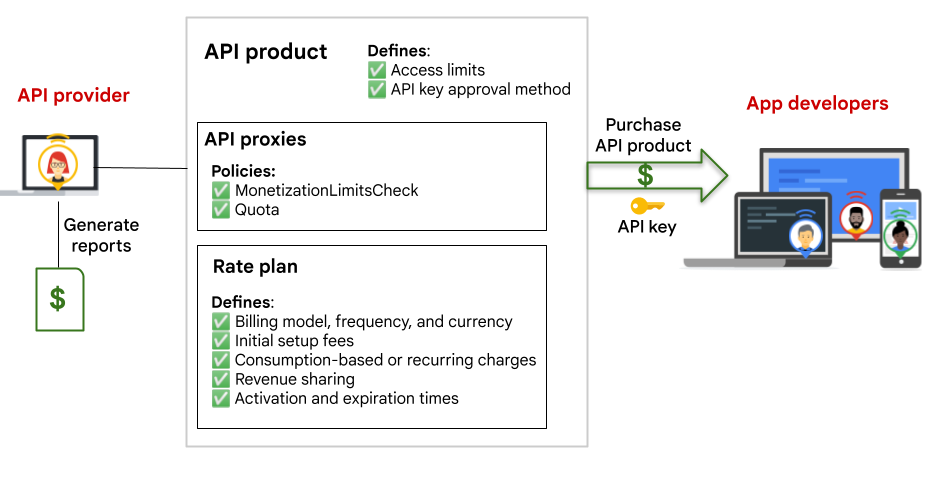
대표적으로 구글의 Apigee 등 일부 API 게이트웨이는 과금 정책을 별도로 설정하여, API 사용 기업 혹은 개인으로부터의 과도한 요청을 막고 사용량을 측정해 요금을 부과할 수 있는 기능을 지원하고 있습니다.
그렇다면 API 스로틀링을 통한 API 속도 지연은 어떤 원리로 동작하는 것일까요? 먼저 API 스로틀링에는 일반적으로 Bucket과 Window를 컨셉으로 한 알고리즘이 사용됩니다.
오늘은 이 중에서 가장 이해하기 쉬운 Leaky Bucket 알고리즘에 대해 살펴보겠습니다.
직역하면 '구멍 난 양동이'. 우리 정서에는 '깨진 독에 물 붓기'쯤 되겠습니다. 깨진 독에 물을 붓는 일이 언제나 바보 같은 일은 아닙니다. 단지 ‘물을 저장한다.’라는 목적에서라면 문제가 되는 것입니다. 우선 단순하게 깨진 독에 물을 부었을 때, 일어나는 일을 정리해 보겠습니다. 구멍의 크기만큼 물이 빠져나가고, 급수량이 양이 배수량보다 빠르면 물이 독에서 넘치게 됩니다.
Leaky Bucket 알고리즘 또한 비슷한 원리입니다. 고정된 버킷 최대깊이(T)의 버킷에 네트워크 요청 유입 속도의 한계값(τ)을 정합니다. 그리고 지정된 속도에 맞춰서 일정하게 처리합니다. 만약 한계값을 초과하면 요청은 버립니다.
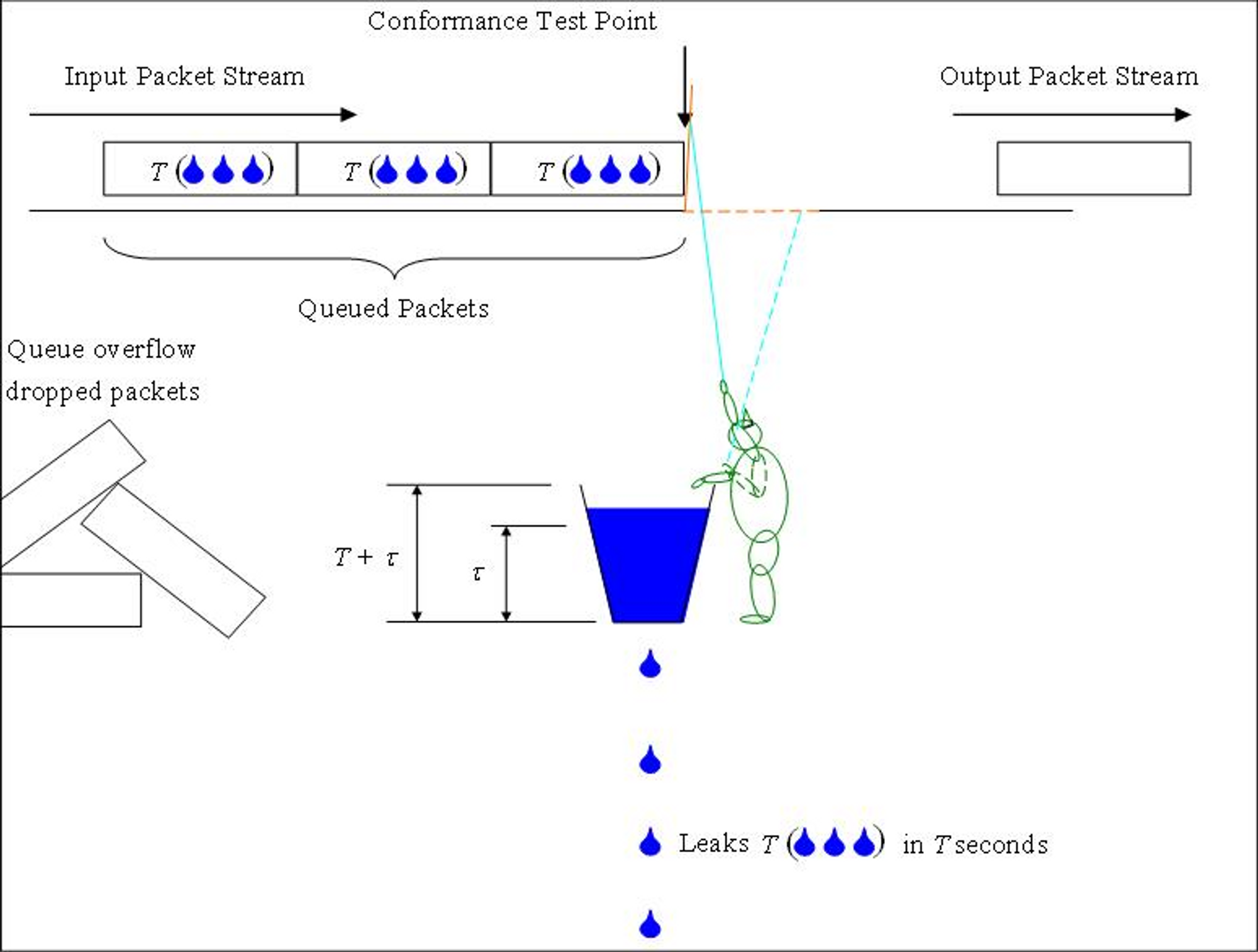
API 게이트웨이가 HTTP API를 처리하는 상황에서는 다음과 같은 맥락으로 이해할 수 있습니다. “고정된 API 요청 최대량(T)에 Http request의 한계값(τ)을 정한다. 그리고 지정된 속도에 맞춰서 일정하게 HTTP Request를 처리 및 각 서비스로 포워딩한다. 그리고 한계 값을 초과하면 요청은 HTTP 429 Response를 반환한다.”
이번엔 5초당 2건씩 최대 100건을 처리할 수 있는 아주 작은 API Gateway를 구현해 보겠습니다.
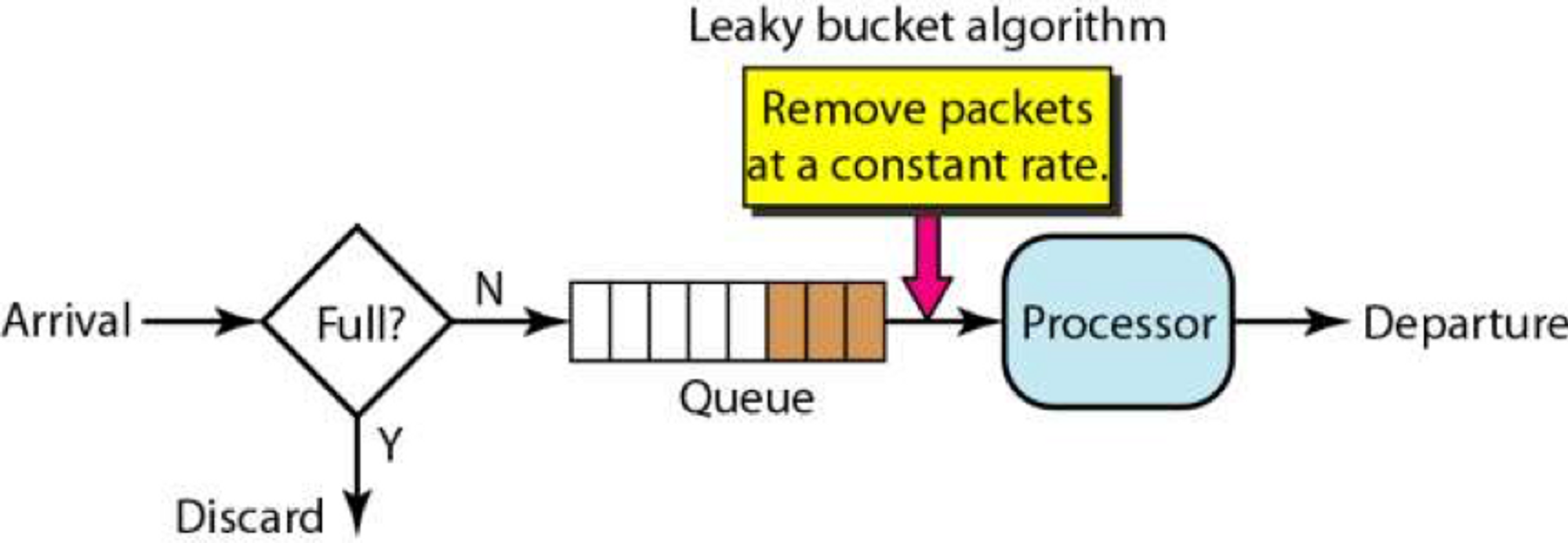
요청된 순서대로 처리해야 되서 적당한 자료구조로 큐(Queue)를 선택했습니다. 알리바바에서도 큐를 이용해 Leaky Bucket의 구현을 설명하고 있습니다.
그다음 빠른 개발을 위해 Node.js에서 동작하도록 간단하게 자바스크립트로 작성해 보겠습니다. 아마 이 글을 읽는 분들은 대부분 국내에서 개발자로 일하며, 스프링과 자바로 개발하는 경우가 많을 것 같아, DI(Dependency Injection)의 기능이나 모양이 최대한 비슷한 타입스크립트 기반의 Nest.js를 사용했습니다.
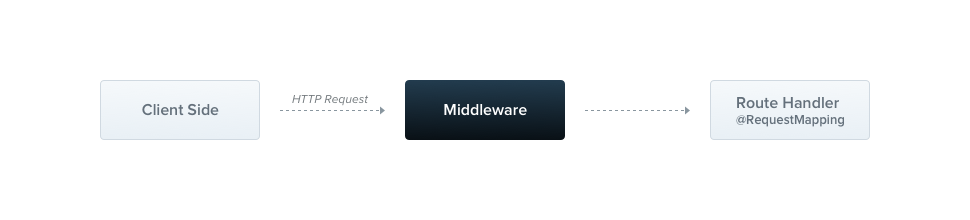
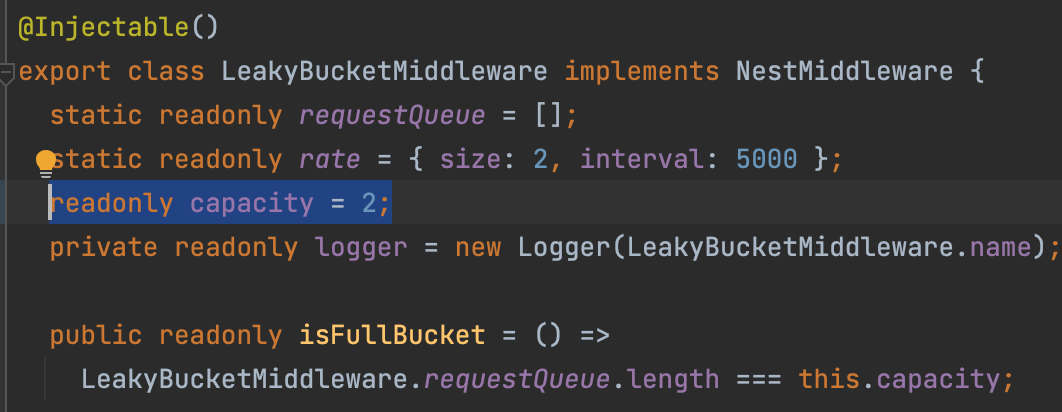
알고리즘의 구현은 Nest의 미들웨어(Middleware)를 활용하면 좋습니다. Nest의 미들웨어는 클라이언트로부터 들어온 요청을 각 컨트롤러의 요청 핸들러가 처리하기 이전에 코드를 실행할 수 있는 기능입니다. 이번 글에서는 LeakyBucketMiddleware 미들웨어 내부에 요청 큐와 버킷의 크기 및 처리량에 대해 관리하도록 구현했습니다.
프로젝트의 구조는 대략적으로 위와 같습니다.
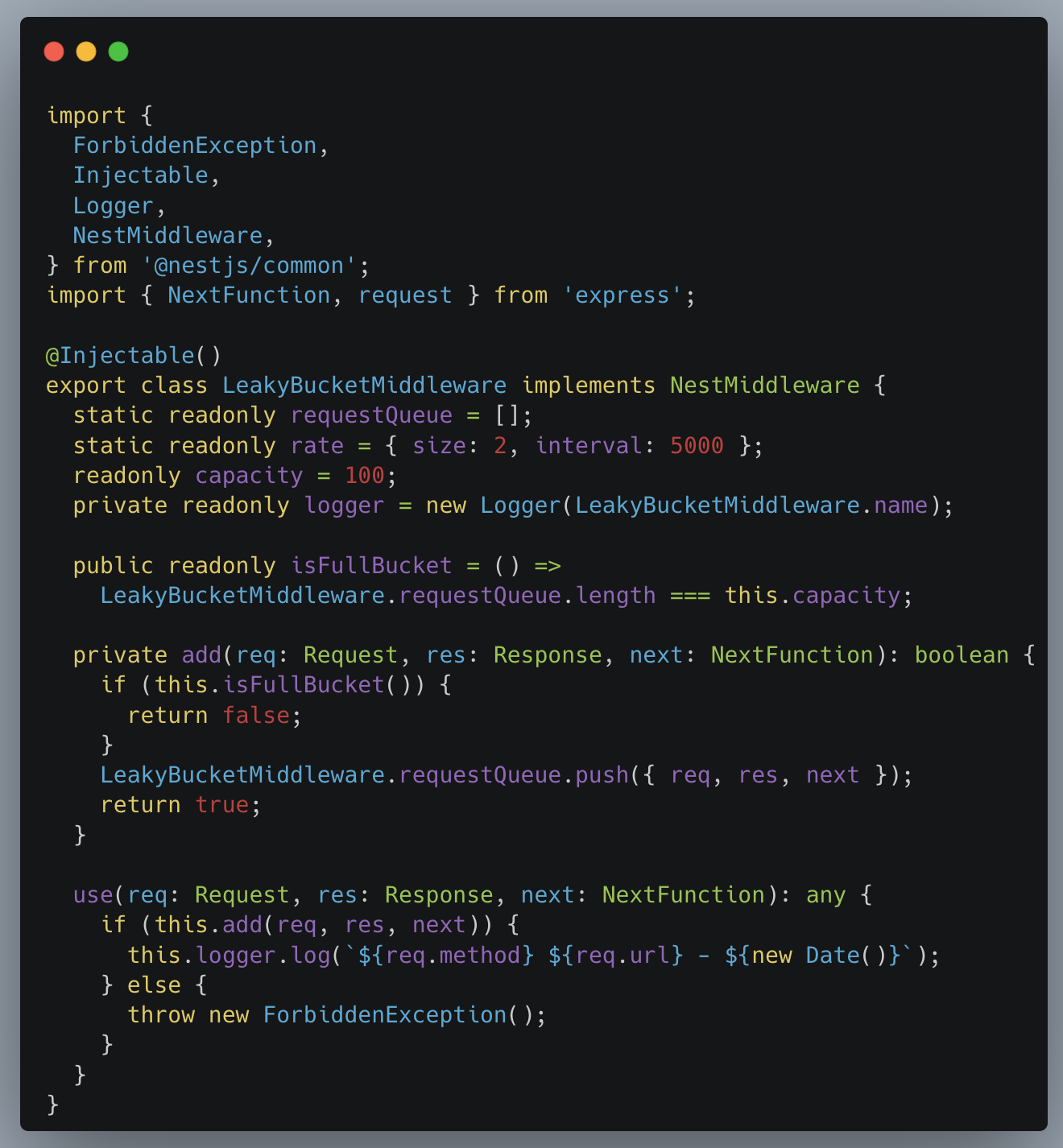
LeakyBucketMiddleware은 버킷에 요청된 API Request를 Static Queue에 추가하는 역할을 합니다. Request를 담을 수 있는 requestQueue를 static으로 선언하고, 처리량을 조절할 변수 rate와 capacity를 선언 및 할당합니다.
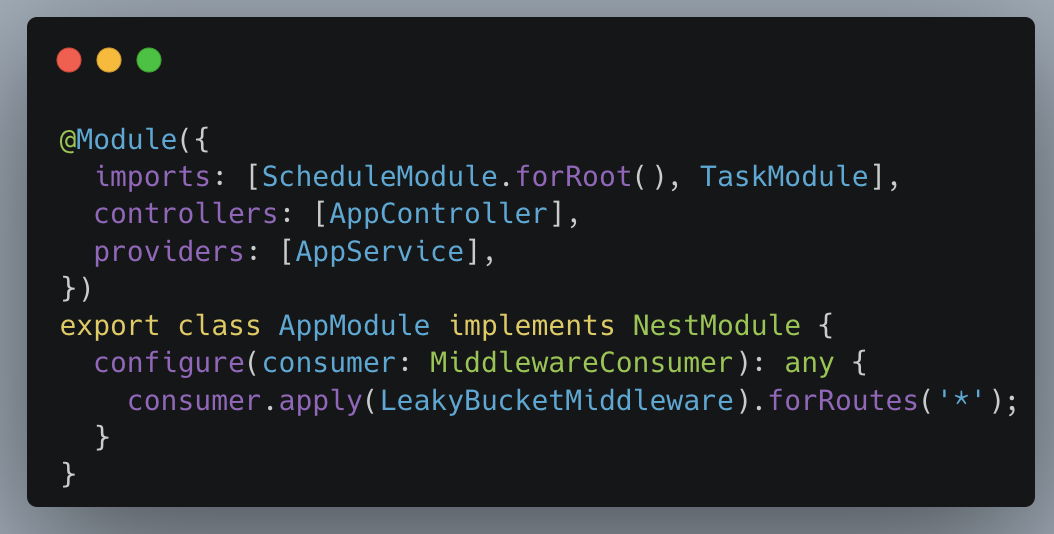
이렇게 만들어진 미들웨어 LeakyBucketMiddleware는 모든 API의 경로에서 사용하도록 설정했습니다.
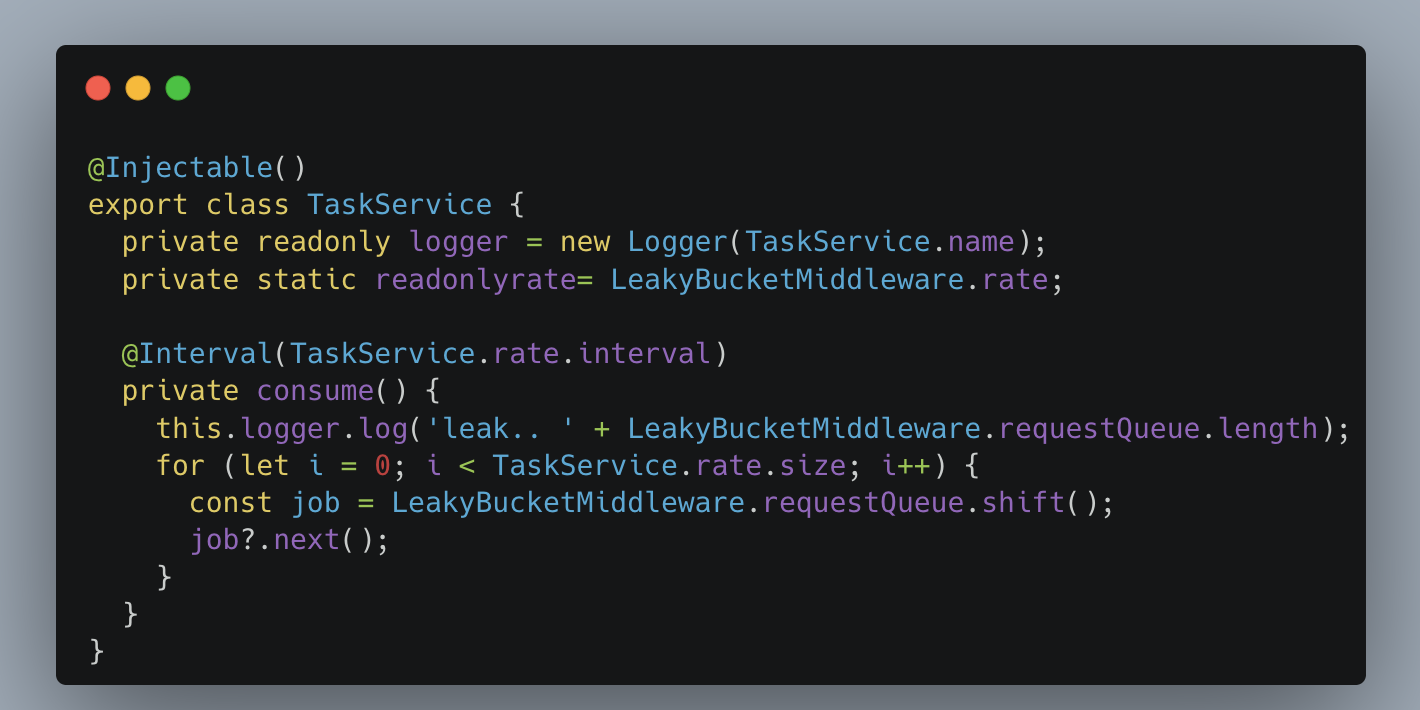
TaskService은 설정된 버킷의 rate 값을 기준으로 반복해서 작업을 수행하는 역할을 합니다. 여기서 @Interval를 이용하여 일정 주기로 API 요청에 대한 수행과 응답을 하게 합니다. @Interval은 Nest.js에서 반복적인 일을 수행하도록 하는 모듈입니다. 따라서 TaskService는 @Interval을 이용하여 미들웨어 LeackyBucketMiddleware에서 설정한 처리량을 수행합니다.
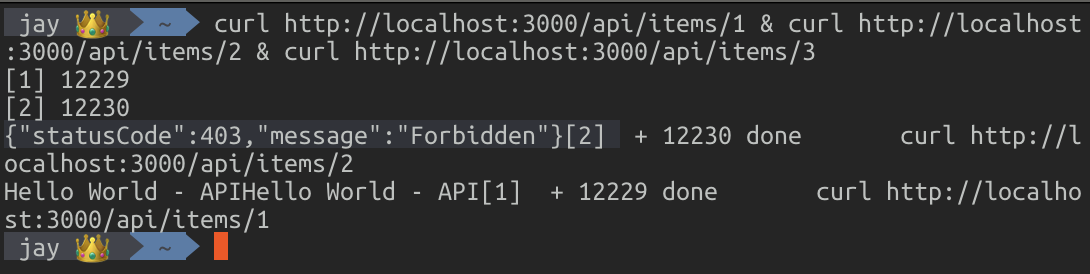
테스트를 위해서 최대 가능 건수를 2건으로 조율하고, 버킷 큐의 크기를 2로 줄입니다. 그리고 curl 명령어를 이용해서 3회의 API 호출을 하게 되면 Forbidden 에러가 발생하는 모습을 확인할 수 있습니다.
Leaky Bucket 알고리즘의 장점은 고정된 처리량(개수/속도)를 기반으로 동작하여 안정된 처리율과 메모리 사용을 나타냅니다. 단점으로는 API 요청량이 급증하는 시간에 적절한 Rate 인자를 배정하지 못하면, 신규 요청 건들이 큐에서 넘쳐버리게 됩니다. 즉, 일부 시간에 트래픽이 몰리는 서비스라면 적합하지 않을 수 있습니다. 또한 다음 Rate Time까지 기다려야 합니다.
개인적으로 Leaky Bucket 알고리즘은 고객의 요청보다 현재 시스템의 안정적인 가용성이 더욱 중요할 때 사용하는 것을 추천합니다. 우버나 쇼피파이 같은 서비스에서도 Leaky Bucket 알고리즘을 사용하고 있습니다.
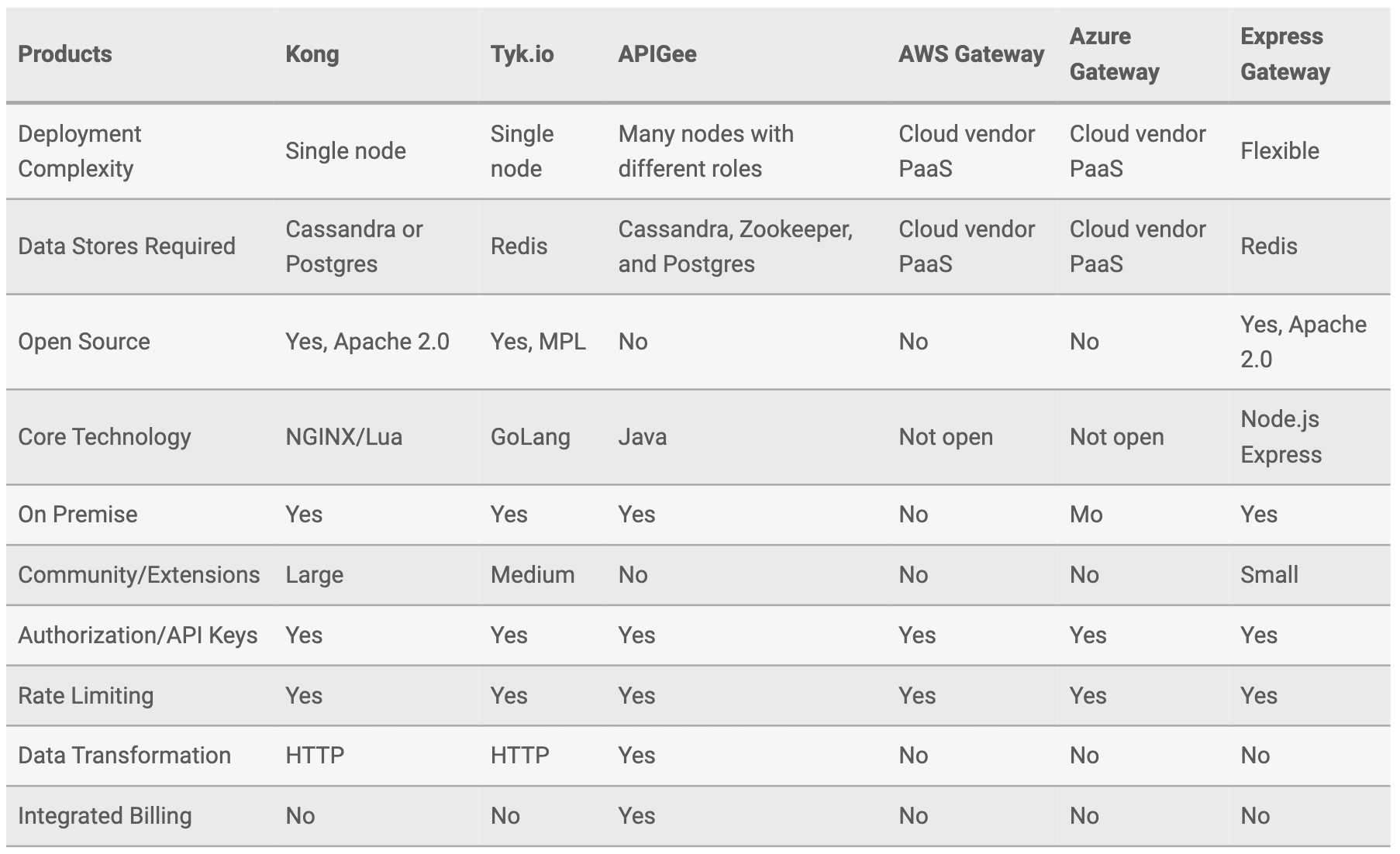
오늘은 API 게이트웨이와 API 스로틀링, Leaky Bucket 알고리즘까지 함께 살펴봤습니다. 이번 글을 통해 아이디어를 얻거나, 추가 알고리즘을 학습해 직접 개발하려는 분들도 있을 것 같습니다. 하지만 API 게이트웨이를 직접 구축하는 일은 생각보다 많은 시간과 노력이 필요할 것입니다.
만약 빠른 서비스 론칭이 필요한 경우라면, 기존에 나와있는 API 게이트웨이 구현체들을 살펴보는 것을 추천합니다. 이미 훌륭한 서비스들이 있으니 직접 구현하는 것보다, 이를 이용하는 것이 훨씬 편리하니까요. 이번 글을 통해 서비스에 맞는 API 설계 및 구현에 도움이 되길 바랍니다.
<참고 자료>
1. Mimul 블로그, 서비스 가용성 확보에 필요한 Rate Limiting Algorithm에 대해
2. Stripe 블로그, Scaling your API with rate limiters
3. 책, 가상 면접 사례로 배우는 대규모 시스템 설계 기초
4. AWS 개발자 안내서
©️요즘IT의 모든 콘텐츠는 저작권법의 보호를 받는 바, 무단 전재와 복사, 배포 등을 금합니다.