디자인
데이터 시각화 101: ②직관적인 데이터 시각화 만들기

8분
2022.11.17.12.5K

‘데이터 시각화 101’ 시리즈의 첫 번째 글에서는 데이터 시각화가 왜 중요한가에 대한 이야기를 다루었습니다. 데이터를 시각화하여 전달하면 우리의 뇌는 빠른 속도로 많은 양의 정보를 처리할 수 있고, 데이터 테이블에 비해 트렌드나 패턴, 아웃라이어 등을 쉽게 파악할 수 있습니다. 때문에 데이터를 쉽게 이해하고 데이터를 기반으로 한 의사결정에 도움을 줍니다.
하지만 모든 데이터 시각화가 쉽고 직관적으로 이해되지는 않습니다. 그 이유는 무엇일까요? 바로 데이터에서 발견한 정보가 시각 요소로 적절하게 디자인되지 않았기 때문입니다. 이번 글에서는 우리의 뇌가 시각 정보를 처리하는 과정을 이해하고, 직관적인 데이터 시각화를 만드는 방법에 대해 살펴보겠습니다.
시각화를 연구하는 콜린 웨어(Colin Ware) 박사는 우리의 뇌가 시각 정보를 처리하는 과정을 세 단계로 나누어 설명합니다. 아래의 데이터 시각화를 이용해, 시각 정보가 어떻게 뇌에 입력되고 해석되는지 살펴보겠습니다.
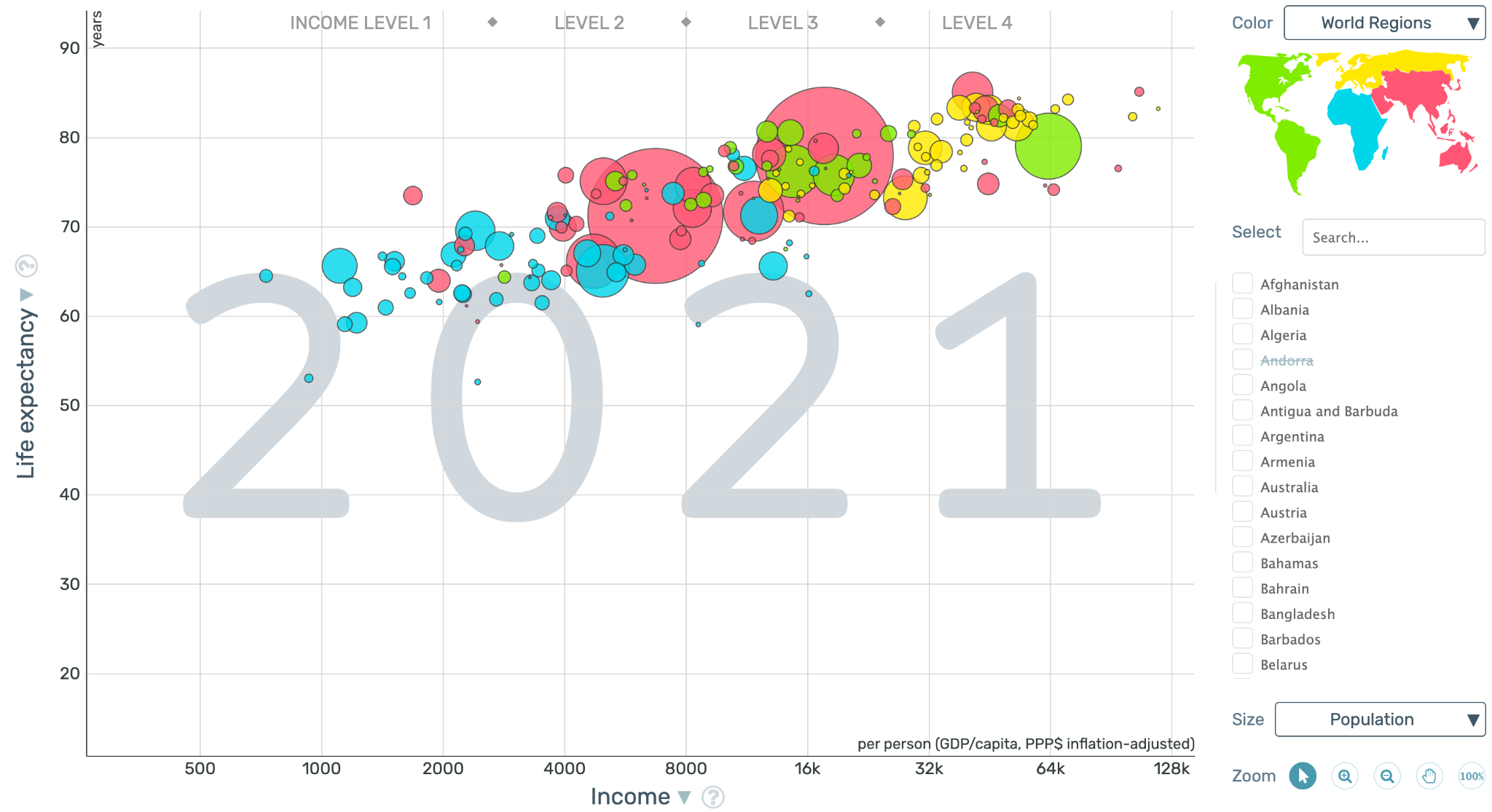
1단계에서는 시각 정보가 눈의 신경 세포에 입력되어 뇌로 전달됩니다. 각각의 신경 세포들이 동시에 색, 질감, 선의 두께, 방향, 배열 등의 기본적인 시각 요소들을 빠른 속도로 추출하기 시작합니다. 그중 뚜렷한 시각 요소들이 감각 기억에 저장됩니다. 위의 시각화에서는 다음과 같은 특징들이 추출될 수 있겠죠.
2단계에서는 앞서 추출한 시각 요소들의 공통점과 차이점을 발견합니다. 윤곽선을 찾아 나누거나, 동일한 색이나 질감, 방향성 등에 따라 그룹으로 분류하며 패턴을 인식합니다. 그럼 위의 시각화에서는 어떤 패턴들이 추출될 수 있을까요?
3단계에서는 전 단계에서 추출된 시각 요소 및 패턴을 이용하여, 뇌에서 능동적으로 의미를 부여하고 해석합니다. 텍스트를 이미지와 연결하여 해석하기도 하고, 이미 가지고 있던 정보를 바탕으로 시각 요소나 패턴에 의미를 부여해 새로운 정보를 찾습니다. 위의 시각화에서는 아래와 같은 내용이 해석될 수 있겠죠.
이와 같이 데이터 시각화가 해석되는 3단계는 그전의 단계에서 추출된 시각 요소와 패턴에 큰 영향을 받습니다. 우리는 1, 2단계에서 추출되는 시각 정보들을 의도적으로 디자인하여, 해석 단계에 도움을 줌으로써 직관적인 데이터 시각화를 만들 수 있습니다.
1단계에서 우리의 뇌는 사물을 보자마자, 눈의 신경세포들을 통해 빠른 속도로 시각 요소들을 추출합니다. 이때 무엇을 보자마자 주의를 기울이지 않아도 알아차리는 시각 요소들을 전주의적 속성(Preattentive attributes)이라고 합니다. 전주의적 속성을 이해하면, 데이터 시각화 내의 중요한 시각 정보들이 눈에 띄도록 디자인할 수 있습니다. 다음은 대표적인 전주의적 속성들을 정리한 이미지입니다.
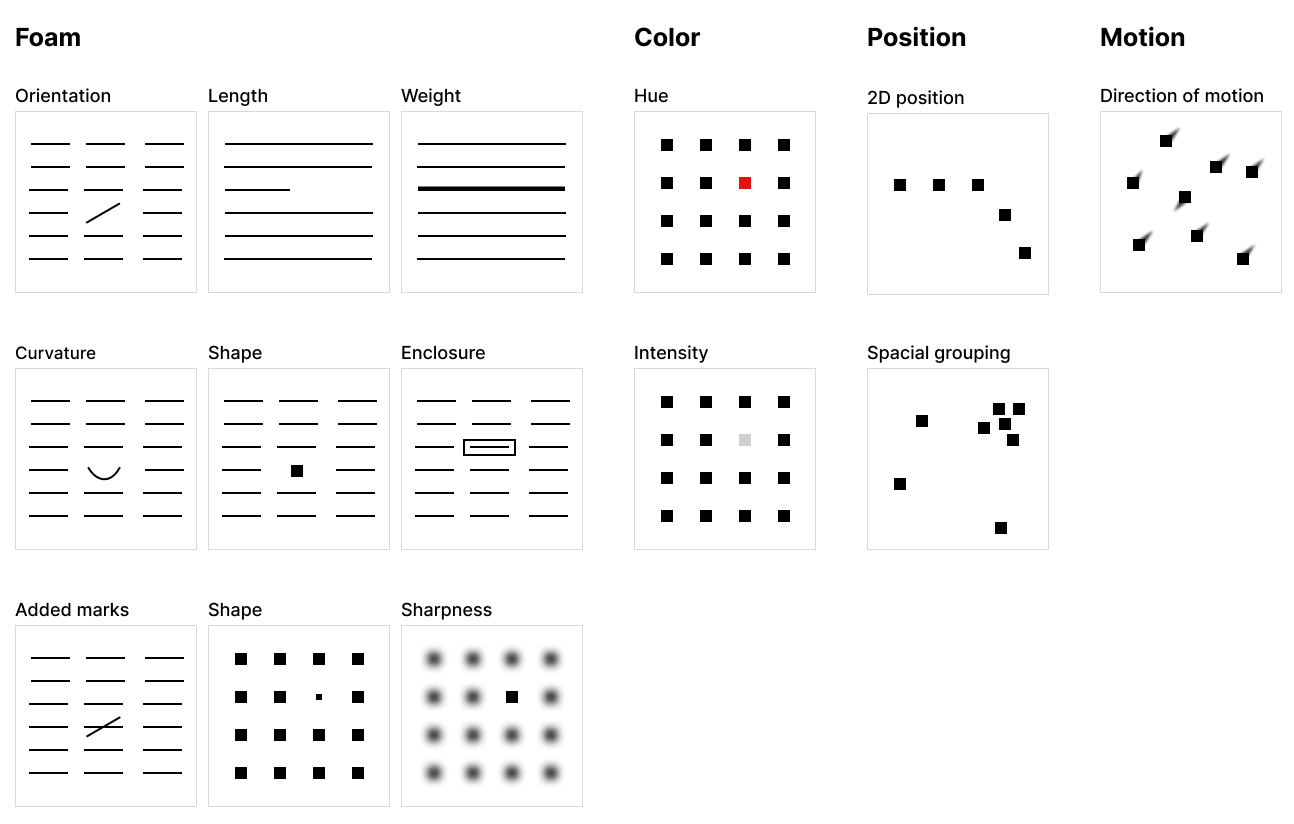
어떤 부분이 보자마자 눈에 들어오나요? 직관적인 데이터 시각화는 이러한 전주의적 속성들을 디자인에서 의도적으로 사용하는 것입니다. 우리의 눈에 어떤 시각 요소들이 눈에 띄는지 이해하고, 중요한 정보가 가장 먼저 눈에 들어오도록 디자인합니다. 아래의 데이터 시각화에 어떻게 사용되었는지 살펴보겠습니다.
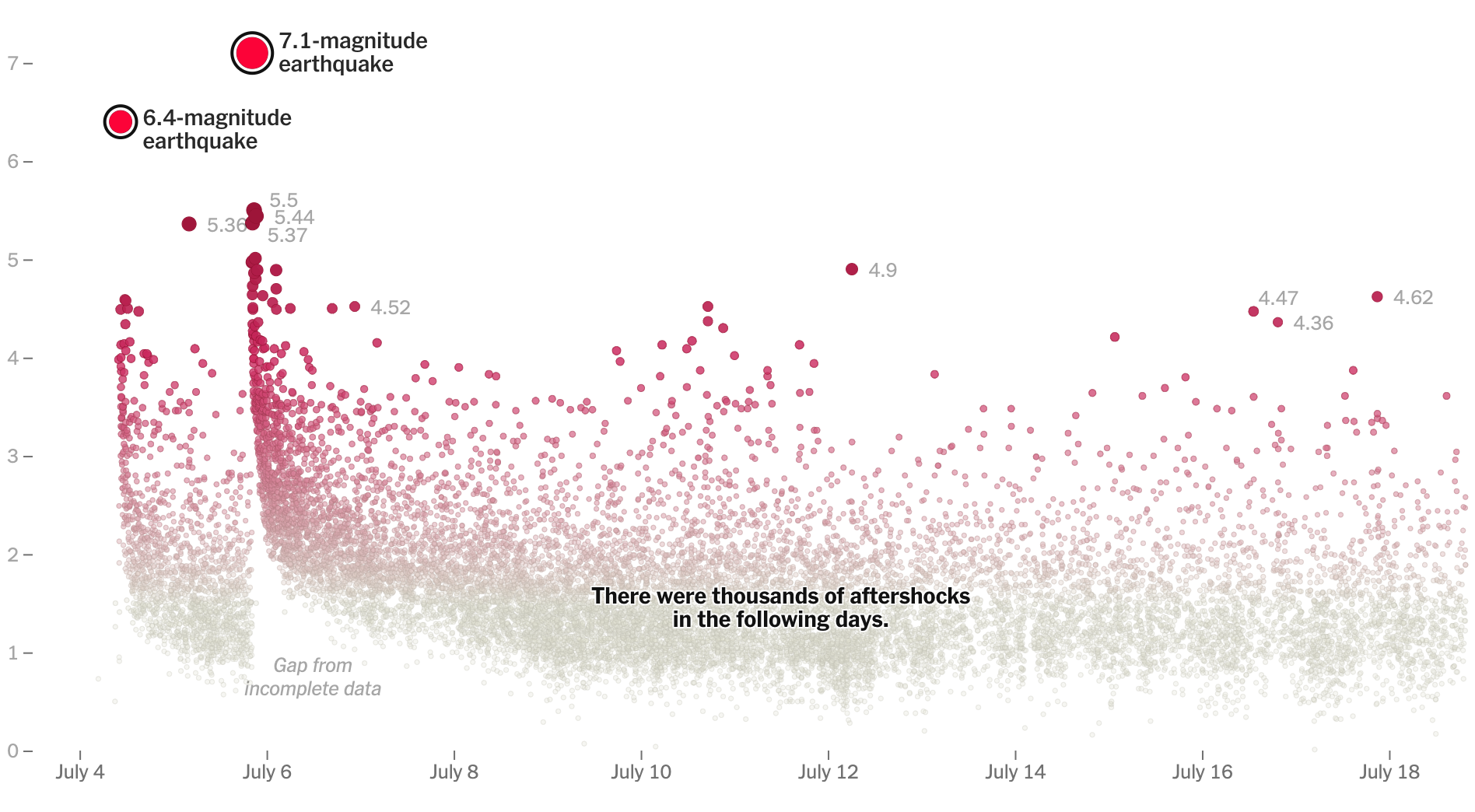
어떤 시각 요소들이 가장 먼저 눈에 들어오나요? 아마 다음과 같을 것입니다.
이 시각화를 보자마자 우선 왼쪽 위에 있는 두 개의 원이 눈에 띕니다. 다른 원에 비해 상대적으로 크고 뚜렷한 붉은색을 사용했고, 굵은 선이 원을 감싸고 있습니다. 왜 이런 전주의적 속성들이 사용되었는지 데이터 시각화 내용을 살펴보겠습니다.
위의 데이터 시각화는 두 개의 큰 지진이 16,000개 이상의 다른 지진을 촉진시켰다는 정보를 전달합니다. 따라서, 큰 두 개의 지진을 강조해야 하는 시각화입니다. 그리고 전체 지진들을 날짜별, 크기별로 배열하고, 지진의 크기에 따라 원의 크기 및 색을 디자인하였습니다. 이렇게 전주의적 속성을 사용함으로써 우리는 두 개의 큰 지진이 다른 지진들을 촉진시켰다는 정보를 뚜렷하게 인식할 수 있습니다.
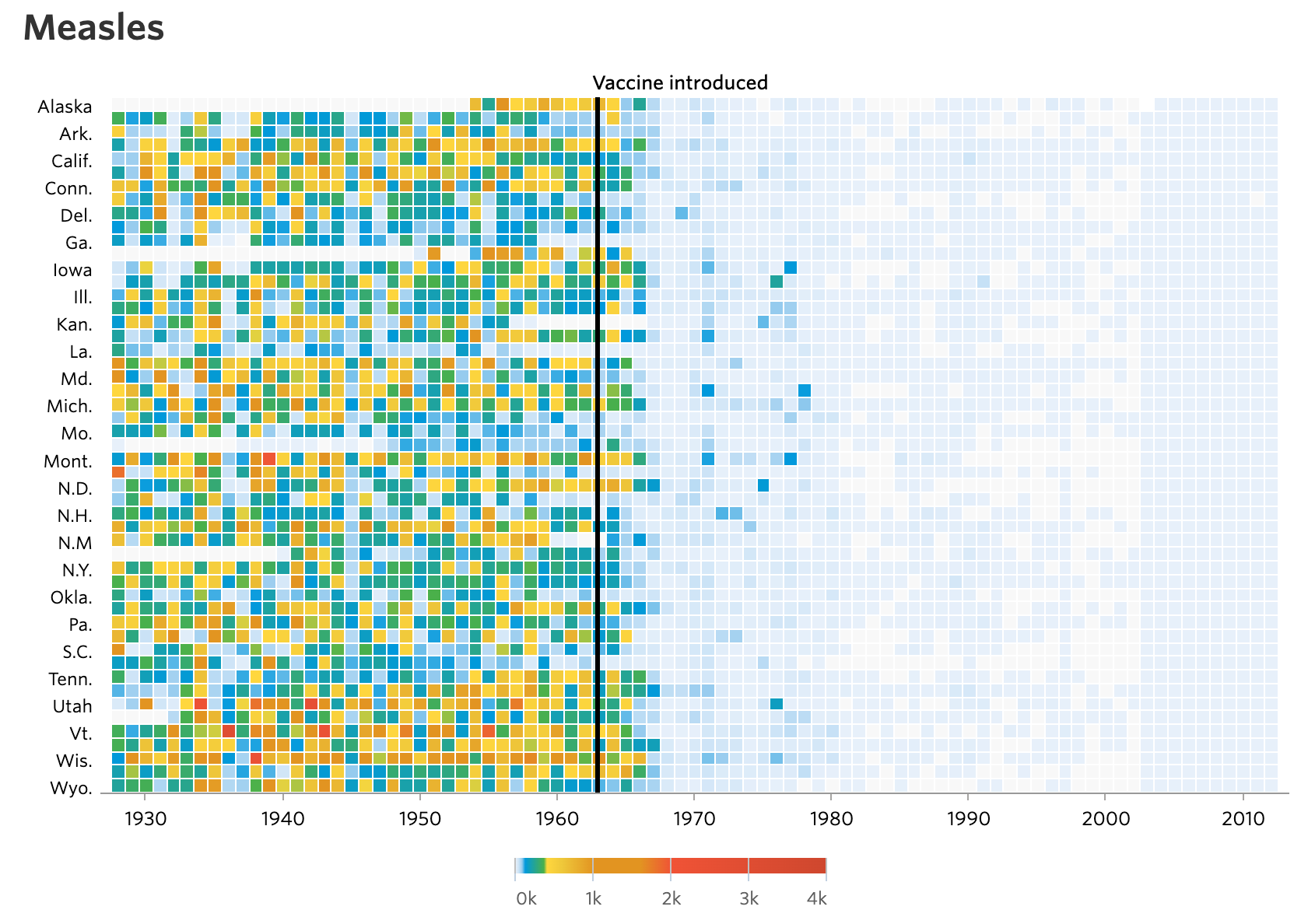
위의 시각화에서 우리 눈에 띄도록 디자인된 전주의적 속성은 무엇이 있을지 찾아보겠습니다.
이 시각화를 보면 가장 눈에 띄는 것은 중간을 가로지르는 굵은 선입니다. 어떤 것을 구분 짓는 듯합니다. 그리고 많은 사각형들이 붉은색부터 옅은 파란색으로 이어지는 색의 배열을 가지고 있습니다. 왜 이런 전주의적 속성들이 디자인되었을까요?
위의 데이터 시각화에서 전달하고자 하는 정보는 백신의 효과입니다. 무엇보다 백신이 소개된 시점이 강조되어야 하기 때문에 이 부분이 굵은 선으로 눈에 띄게 디자인되었습니다. 작은 사각형들이 미국의 주 별로 그리고 연도에 따라 배열되어 있습니다. 확진자 수가 많으면 눈에 띄는 붉은색으로, 적으면 옅은 푸른색으로 나타나기 때문에 한눈에 백신이 소개된 이후로 확진자 수가 급감한 것을 확인할 수 있죠.
이와 같이 전주의적 속성을 이해하면, 데이터 시각화의 중요한 정보들이 보자마자 눈에 띄도록 디자인할 수 있습니다. 하지만 많은 속성들을 한 번에 사용하면 오히려 어떤 정보가 중요한지 알 수 없게 됩니다. 따라서 전주의적 속성을 이용할 때는 너무 많은 속성을 이용하지 않도록 주의하고, 실제로 의도한 시각 정보가 눈에 띄는지 유저 테스팅을 통해 확인하는 것이 중요합니다.
2단계에서는 앞서 추출된 시각 요소들 안에서 패턴을 찾기 시작합니다. 여기에 우리의 뇌가 사물의 형태를 지각하는 원리를 정리한 게슈탈트 원리(Gestalt principles)를 적용해 볼 수 있습니다.
게슈탈트 원리(Gestalt principles)에 따르면, 우리의 뇌는 사물을 구성 요소로 분해하는 것보다 큰 전체를 이해하는 데 탁월합니다. 또한 특정 규칙이 적용될 때, 요소들을 연관된 하나의 그룹으로 인식하는 경향이 있습니다. 이 과정을 통해 복잡한 시각 정보를 좀 더 이해하기 쉬운 형태로 정리함으로써 패턴을 인식할 수 있는 것입니다. 그럼 실제 시각화에서 이용될 수 있는 게슈탈트의 원리를 살펴보겠습니다.
근접성(proximity)의 원리는 서로 가까이 있는 요소들은 서로 멀리 떨어져 있는 요소들에 비해 더 연관되어 보인다는 것입니다. 아래의 시각화에서 어떻게 활용되었을까요?
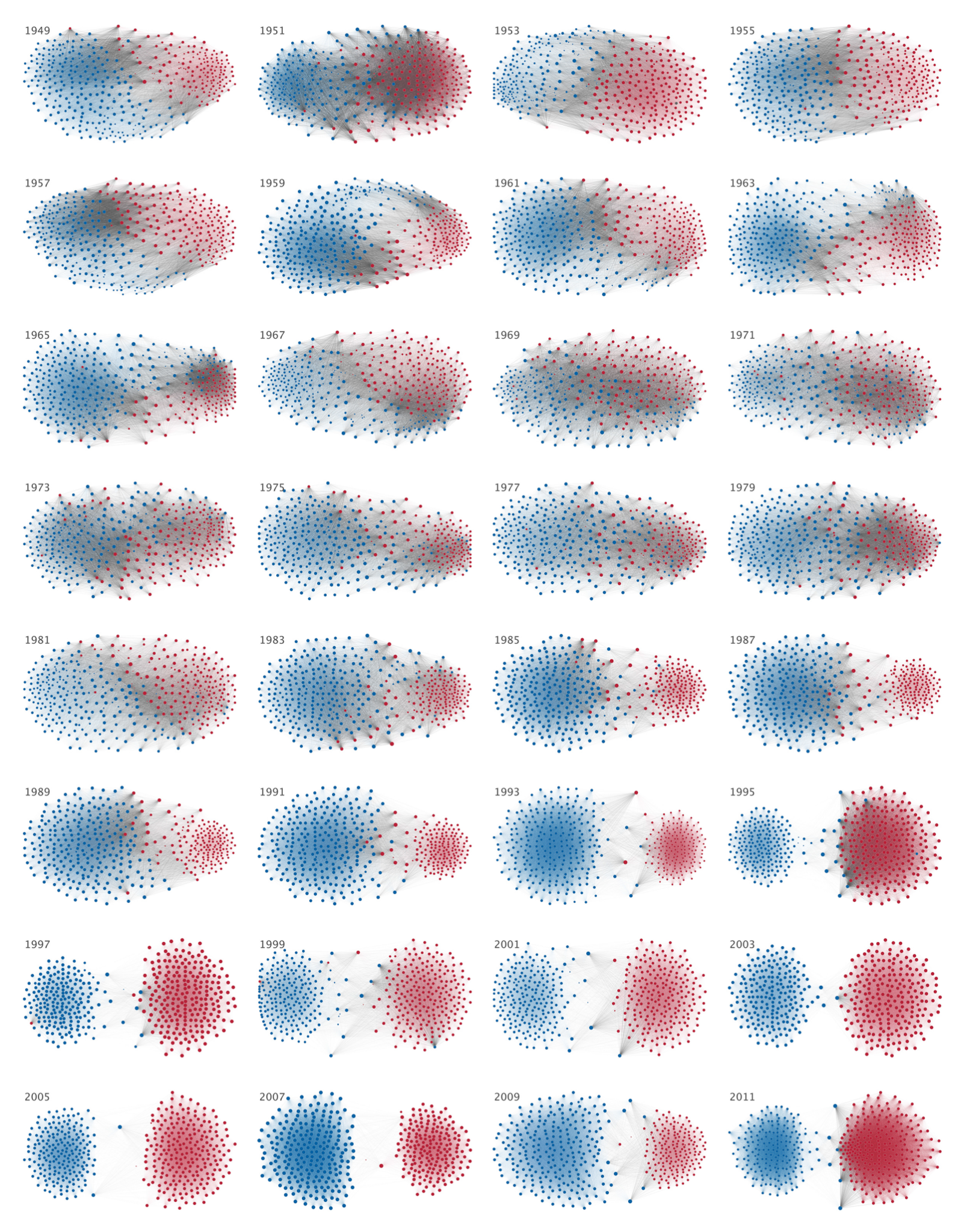
우리는 이 시각화를 보자마자 빨간색, 파란색의 많은 점들이 있고, 점들을 이은 선을 알아차릴 수 있습니다. 그리고 왼쪽 위에서 오른쪽 아래로 내려올수록 다른 색의 점을 잇는 선들이 줄어들고, 같은 색의 점끼리 모여있는 패턴을 파악할 수 있습니다.
위의 데이터 시각화는 지난 60년 동안 미국의 하원 의원들의 투표 경향이 변화되었음을 보여줍니다. 민주당은 파란색, 공화당은 빨간색 점으로 표시되었습니다. 같은 당을 투표한 경우 같은 색의 선으로 연결되고, 상대 당을 투표한 경우 회색 선으로 연결됩니다. 1960년대 이전에만 해도 회색 선이 많이 보이고 다른 색의 점들이 서로 엉켜있습니다. 즉, 서로 상대 당을 위해 투표하는 것이 꽤 흔한 일이었습니다. 하지만, 1980년대 이후로 가면서 회색 선이 줄어들고, 같은 색의 점들이 따로 모여있는 것으로 보입니다. 점차 본인의 당에만 투표를 하는 경향이 보이며, 양극화 현상이 진행되고 있는 것을 시각화를 통해 확인할 수 있습니다.
유사성(similarity)의 원리는 비슷한 특징을 가지고 있는 요소들은 그렇지 않은 요소들에 비해 더 연관되어 보인다는 것입니다. 아래의 시각화에서 어떻게 활용되었을까요?
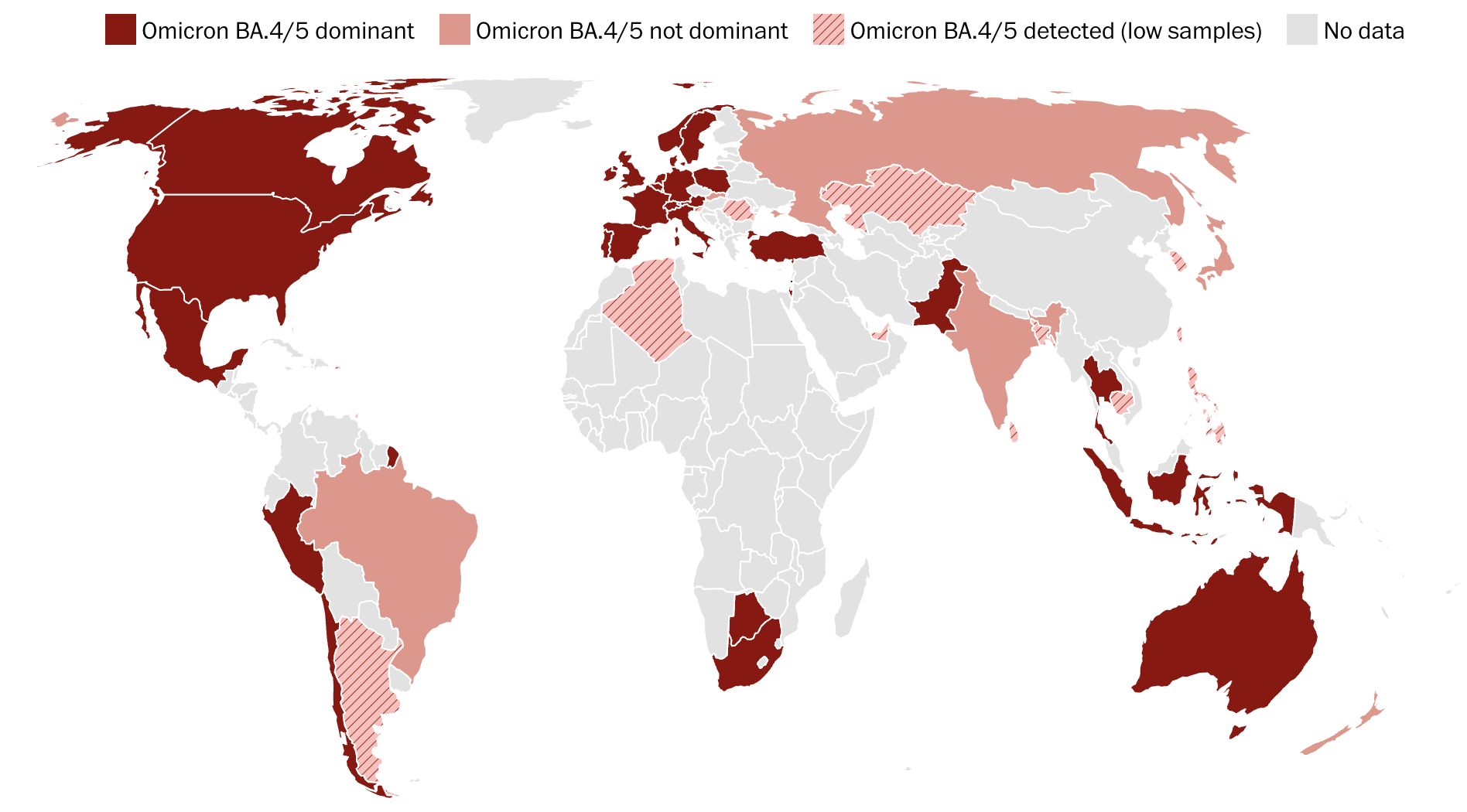
우선 지도와 그 위의 붉은색이 보입니다. 비슷한 붉은색이지만 다른 텍스처와 밝기가 눈에 띕니다. 우리는 각 색상의 밝기별, 텍스처별로 이 지도 안에 있는 국가들을 그룹화하여 인식합니다.
이 데이터 시각화는 코로나 바이러스 변이 중 하나인 오미크론 BA.4와 BA.5가 전 세계 어느 국가에서 얼마나 우세한지 보여줍니다. 여러 색을 사용하지 않고, 공통적으로 붉은색을 사용한 이유는 동일한 변이의 확산을 보여주기 위해서입니다. 변이가 얼마나 우세한지 그 정도의 차이를 보여주기 위해서 다른 밝기와 텍스처가 사용되었습니다. 이 당시에는 오미크론 BA.4와 BA.5가 미국이나 유럽 등지에서 매우 우세하게 확산되고 있지만, 한국 등지에서는 많이 발견되지 않은 것을 알 수 있습니다.
공동 운명(common fate)의 원리는 같은 방향으로 움직이는 요소들은 움직이지 않거나, 서로 다른 방향으로 움직이는 요소들에 비해 더 연관되어 보인다는 것입니다. 아래의 시각화를 살펴보겠습니다.
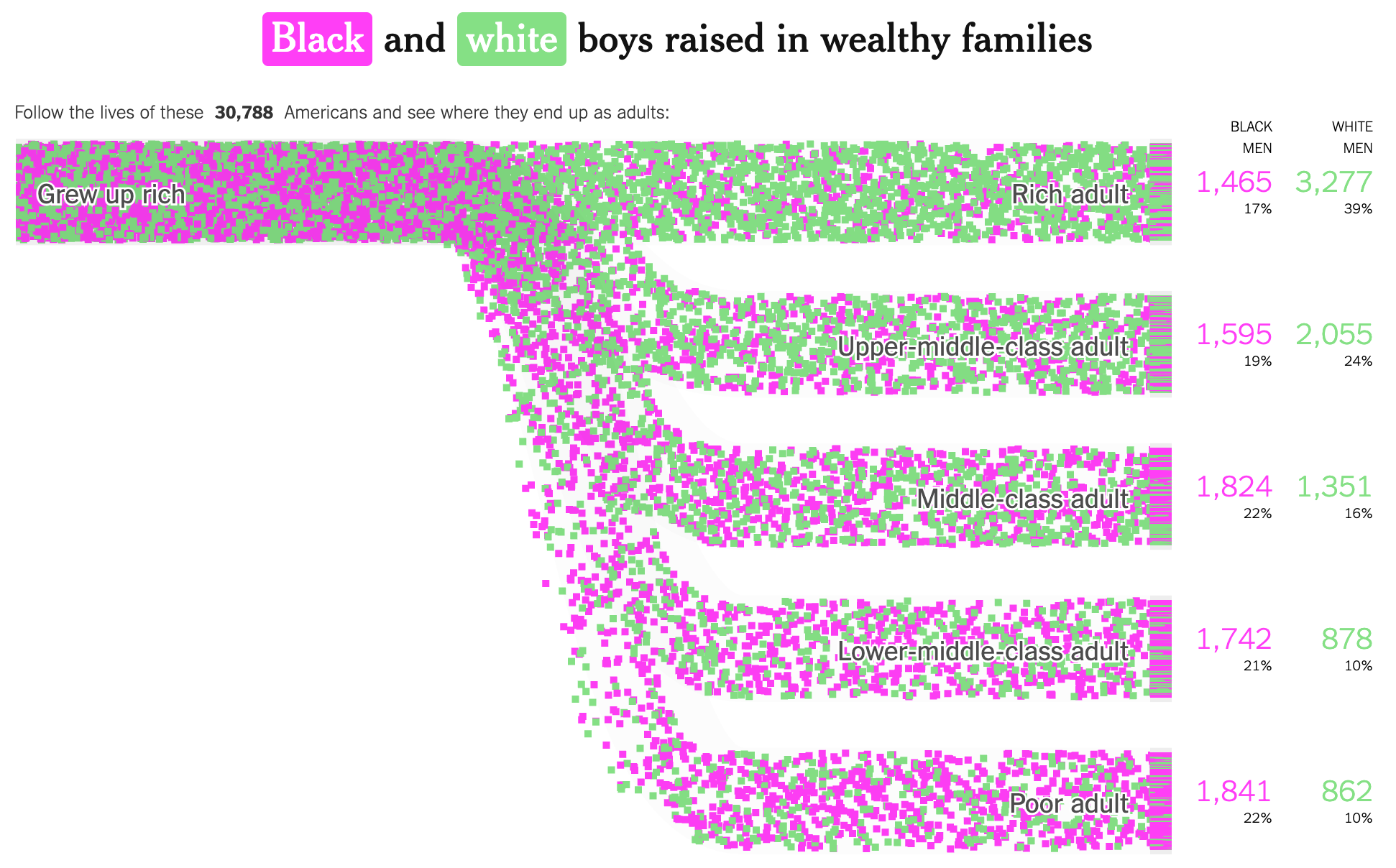
보자마자 밝은 보라색과 연두색의 무수한 점들을 확인할 수 있습니다. 이 이미지에서는 볼 수 없지만, 실제 시각화에서는 이 점들이 왼쪽에서 오른쪽으로 계속 이동합니다. 그 이동방향을 보면, 하나의 그룹이었던 점들이 점차 다른 그룹으로 나누어지는 것으로 인식됩니다.
이 데이터 시각화는 미국 내의 성별, 인종별 소득 이동에 대한 것입니다. 흑인 소년은 밝은 보라색, 백인 소년은 밝은 연두색으로 디자인되었습니다. 왼쪽에 모여있는 점들은 부유하게 자란 백인 소년들과 흑인 소년들을 모두 나타냅니다. 그리고 오른쪽에서 성인이 되었을 때의 소득 수준에 따라 이들을 나눕니다. 부유하게 자란 백인 소년들은 비슷한 환경에서 자란 흑인 소년들에 비해, 성인이 되어서도 부를 유지할 확률이 높았음을 보여줍니다.
균일한 연결(uniform connectedness)의 원리는 시각적으로 연결된 요소들은 연결되지 않은 요소들에 비해, 더 연관성있는 것처럼 인지된다는 것입니다.

위의 시각화를 보자마자 많은 이름들이 눈에 띕니다. 이름들이 선으로 연결되어 있는 것을 알 수 있습니다. 그중 몇몇 이름들은 더 눈에 띕니다. 이 이름들은 크기도 더 크고, 대문자에 흰색으로 디자인되었습니다. 선으로 연결된 이름들끼리는 각각 그룹을 형성하는 듯이 인식됩니다.
이 데이터 시각화는 영화계에서 감독들과 배우들의 관계를 보여줍니다. 감독과 배우의 이름을 구별하기 위해, 감독의 이름이 좀 더 눈에 띄도록 디자인되었습니다. 그리고 감독을 중심으로 함께 작업한 이들의 이름이 연결되어 있는 것을 알 수 있죠. 한 배우와만 작업하는 감독도 확인할 수 있고, 조니 뎁(Johnny Depp)의 경우 여러 감독들과 작업한 것으로 보입니다.
직관적인 데이터 시각화를 디자인하기 위해서는 우리의 뇌가 시각 정보를 처리하는 과정을 이해해야 합니다. 콜린 웨어(Colin Ware) 박사는 우리의 뇌가 시각 정보를 처리하는 과정을 세 단계로 나누어 설명합니다.
데이터 시각화를 만들 때 1, 2단계에서 추출되는 시각 정보들을 의도적으로 디자인하여, 해석 단계에 도움을 줌으로써 직관적인 데이터 시각화를 만들 수 있습니다. 이렇게 디자인된 데이터 시각화는 독자들이 쉽게 이해할 수 있도록 돕습니다.
하지만 데이터 시각화는 때론 거짓말을 하기도 합니다. 직관적으로 이해된 시각화가 부정확한 정보를 전달하기도 하고, 시각적으로 오해를 불러일으키기도 합니다. 때문에 우리는 이러한 문제점이 왜 일어나는지 이해하고, 데이터 시각화를 정확하게 판단하며 볼 수 있는 눈을 길러야 합니다. 다음 시리즈에서는 이 부분에 대해 좀 더 자세히 다뤄보도록 하겠습니다.
©️요즘IT의 모든 콘텐츠는 저작권법의 보호를 받는 바, 무단 전재와 복사, 배포 등을 금합니다.