개발
파이썬 초보자가 저지르는 10가지 실수

8분
2022.07.26.23.2K

본문은 요즘IT와 번역가 Mr.P가 함께 만든 해외 번역 콘텐츠입니다. 이 글을 작성한 Frank Andrade는 데이터 과학 및 프로그래밍 기술에 관한 다양한 글을 업데이트하고 있으며, 총 400만이 넘는 누적 조회수를 기록할 정도로 인기 에디터입니다. 이번 글은 파이썬을 처음 배우는 초보자들이 흔히 실수하는 나쁜 코딩 습관들에 관해 소개하고 있습니다.

파이썬을 처음 배울 때, 우리는 자신도 모르게 몇 개의 나쁜 코딩 습관들을 갖게 됩니다. 처음에는 문제없이 작동했지만, 나중에 정상적으로 작동하지 않거나 뒤늦게 문제를 더 쉽게 해결할 수 있는 내장 함수를 찾는 경우도 있습니다.
파이썬을 처음 접하는 대부분의 사람은 처음 배울 때 가진 나쁜 습관을 여전히 하나 이상 가지고 있습니다. 오늘은 그 나쁜 습관들을 쉽게 고칠 수 있는 방법들에 관해 설명해 보겠습니다.
가끔 코딩하다 귀찮으면 from xyz import *를 사용해서 모든 모듈[1]을 한 번에 불러옵니다. 이것은 여러 가지 이유로 좋은 습관이 아닙니다.
몇 가지 예를 들면 다음과 같습니다:
이 문제를 어떻게 해결할 수 있을까요? 우리는 사용하려는 특정 객체를 불러오거나, *를 사용하지 않고 전체 모듈을 불러온 후 객체를 사용하기 전에 모듈명을 명시할 수 있습니다.
# Using import *
# Bad
from math import *
print(floor(2.4))
print(ceil(2.4))
print(pi)
# Good
import math
from math import pi
print(math.floor(2.4))
print(math.ceil(2.4))
print(pi)
저는 오랫동안 이것을 무시해왔습니다. 덕분에 ‘파이참(Pycharm)’을 사용하면서 못생긴 밑줄과 함께 나타나는 PEP 8: do not use bare ‘except’라는 경고문을 셀 수 없이 많이 봐왔습니다. 이것은 PEP 8 가이드라인에서 권장되지 않습니다.
# Try - except
# Bad
try:
driver.find_element(...)
except:
print("Which exception?")
# Good
try:
driver.find_element(...)
except NoSuchElementException:
print("It's giving NoSuchElementException")
except ElementClickInterceptedException:
print("It's giving ElementClickInterceptedException")
bare ‘except’의 문제는 SystemExit와 KeyboardInterrupt 예외(exception)를 잡아서, Control-C로 프로그램을 중지하기 어렵게 만든다는 것입니다. 다음에 try/except를 사용할 때에는 except 절에 예외를 꼭 지정하십시오.
우리는 파이썬이 삶을 더 생산적이고 쉽게 만드는 패키지를 많이 가지고 있다는 사실을 종종 잊어버리곤 합니다. Numpy는 수학 계산에 사용되는 그러한 패키지 중 하나입니다. Numpy는 수학 연산을 푸는 데 있어서 for 루프를 사용하는 것보다 더 빠르게 해결해 줍니다.
우리가 random_scores 배열을 가지고 있고, 시험에 실패한 사람들의(score <70) 평균 점수를 얻으려고 한다고 가정해봅시다. 이것을 for 루프로 해결해 보겠습니다.
import numpy as np
random_scores = np.random.randint(1, 100, size=10000001)
# Bad (solving problem with a for loop)
count_failed = 0
sum_failed = 0
for score in random_scores:
if score < 70:
sum_failed += score
count_failed += 1
print(sum_failed/count_failed)
이제 Numpy로 해결해보겠습니다.
# Good (solving problem using vector operations)
mean_failed = (random_scores[random_scores < 70]).mean()
print(mean_failed)
둘 다 실행해보면 Numpy가 더 빠르다는 것을 알 수 있습니다. 왜냐하면 Numpy는 작업을 벡터화[2]하기 때문입니다.
파이썬으로 열었던 파일을 다시 닫아야 하는 건 모두가 알고 있는 사실입니다. 이것이 우리가 작업할 때마다 open, write/read, close를 사용하는 이유입니다. 여기까진 괜찮습니다. 그러나 우리가 write/read 메소드를 사용할 때 예외가 발생하게 된다면 이미 열린 파일은 닫히지 않습니다.
이 문제를 피하기 위해 우리는 다음과 같은 with 구문을 사용해야 합니다. 이 경우 예외가 발생하더라도 파일을 정상적으로 닫을 수 있습니다.
# Bad
f = open('dataset.txt', 'w')
f.write('new_data')
f.close()
# Good
with open('dataset.txt', 'w') as f:
f.write('new_data')
PEP8은 파이썬을 공부하는 사람이라면 반드시 읽어봐야 할 문서입니다. PEP8은 코드 작성에 대한 최고의 코드 샘플과 가이드라인을 제공합니다. (이 글의 몇몇 조언 또한 PEP8에서 발췌했습니다)
이 지침을 모두 따르는 것은 파이썬을 처음 접하는 사람들에게는 다소 부담이 될 수 있습니다. 다행히도 일부 PEP8 규칙이 IDE에 통합되어 있습니다. (이것이 제가 bare except 규칙에 대해서 알게 된 이유입니다).
파이참(Pycharm)을 사용한다고 가정할 때 PEP8 가이드라인에 따르지 않은 경우, 아래 이미지와 같이 이 못생긴 밑줄을 볼 수 있습니다.
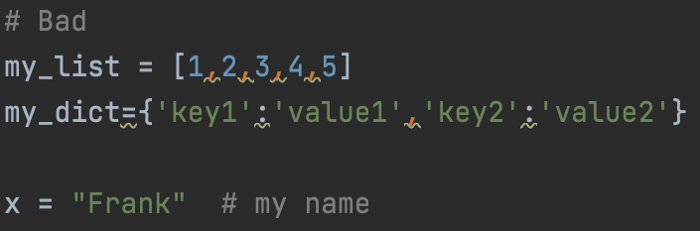
밑줄 위로 마우스를 가져다 대면 밑줄 친 부분을 수정하는 방법에 대한 가이드라인이 표시됩니다. 위의 이미지의 경우 , 와 : 뒤에 공백을 한 칸 추가하면 해결됩니다.
# Good
my_list = [1, 2, 3, 4, 5]
my_dict = {'key1': 'value1', 'key2': 'value2'}
my_name = "Frank"
또한 변수명 x를 my_name으로 변경했습니다. 이것은 파이참(Pycharm)에서는 제안되지 않았지만, PEP8은 이해하기 쉬운 변수명 사용을 권장합니다.
저는 이 글을 읽는 독자들이 .keys와 .values가 무엇인지 알고 있다고 생각합니다. 혹시라도 모르는 분들을 위해 아래 코드를 통해 예시를 보고 넘어가겠습니다.
dict_countries = {'USA': 329.5, 'UK': 67.2, 'Canada': 38}
>>>dict_countries.keys()
dict_keys(['USA', 'UK', 'Canada'])
>>>dict_countries.values()
dict_values([329.5, 67.2, 38])
여기서 문제는 우리가 가끔 그것을 제대로 사용하지 않는 것입니다. 딕셔너리를 반복하여 key를 얻으려고 가정해 보겠습니다. 당신은 .keys 메소드를 사용하게 될 것입니다. 그러나 .keys를 사용하지 않고 딕셔너리를 반복하는 것만으로 key값을 얻을 수 있다는 점을 알고 계셨나요? 다음과 같은 예시를 살펴보겠습니다.
# Not using .keys() properly
# Bad
for key in dict_countries.keys():
print(key)
# Good
for key in dict_countries:
print(key)
또한 딕셔너리의 value 값을 얻기 위한 해결 방법을 고민할 때 .items()를 사용하면 더 쉽게 해결할 수 있습니다.
# Not using .items()
# Bad
for key in dict_countries:
print(dict_countries[key])
# Good
for key, value in dict_countries.items():
print(key)
print(value)
컴프리헨션은 이미 정의된 시퀀스를 기반으로 새로운 시퀀스(리스트, 딕셔너리 등)를 생성하려는 경우 더 짧은 코드로 해결할 수 있게 도와줍니다.
Countries 리스트의 모든 요소를 소문자로 치환하고 싶다고 가정해보겠습니다. 이것을 for 루프로 처리하는 대신 리스트 컴프리헨션으로 이것을 간단하게 처리할 수 있습니다.
# Bad
countries = ['USA', 'UK', 'Canada']
lower_case = []
for country in countries:
lower_case.append(country.lower())
# Good (but don't overuse it!)
lower_case = [country.lower() for country in countries]
컴프리헨션은 매우 효율적입니다. 그러나 그것을 과도하게 사용하지는 마세요! “단순한 것이 복잡한 것보다 낫다”라는 파이썬의 정도를 기억하시기 바랍니다.
우리가 초보자일 때 배운 첫 번째 함수 중 하나는 range와 len입니다. 따라서 대부분의 사람이 리스트를 반복할 때 range(len())을 사용하는 나쁜 습관을 지니게 되는 것은 놀랍지 않습니다.
두 개의 리스트 countries와 populations을 가지고 있다고 가정해보겠습니다. 만일 우리가 두 리스트를 동시에 반복하기 원한다면, 당신은 아마 range(len())을 사용할 것입니다.
# Using range(len())
countries = ['USA', 'UK', 'Canada']
populations = [329.5, 67.2, 38]
# Bad
for i in range(len(countries)):
country = countries[i]
population = populations[i]
print(f'{country} has a population of {population} million people')
이렇게 해도 작업은 완료됩니다. 그렇지만 당신은 enumerate를 사용해서 작업을 더 단순화할 수 있습니다. (혹은 두 가지 리스트를 함께 반복하는 경우 zip이 더 효율적입니다)
# OK
for i, country in enumerate(countries):
population = populations[i]
print(f'{country} has a population of {population} million people')
# Much Better
for country, population in zip(countries, populations):
print(f'{country} has a population of {population} million people')
아마도 우리가 처음 파이썬에서 배우는 것 중 하나는 + 연산자를 사용해 문자열을 결합하는 방법입니다. 이것은 유용합니다. 그러나 문자열을 결합하는 데는 비효율적인 방법입니다. 게다가 가독성마저 좋지 않습니다. 더 많은 문자열을 결합해야 하는 경우에 더 많은 + 연산자를 사용해야 합니다.
+ 연산자를 사용하는 대신에, f-스트링(f-strings)을 사용할 수 있습니다.
# Formatting with + operator
# Bad
name = input("Introduce Name: ")
print("Good Morning, " + name + "!")
# Good
name = input("Introduce Name: ")
print(f'Good Morning, {name}')
f-스트링의 좋은 점은 문자열 결합에 유용할 뿐만 아니라 다양한 응용방법이 있는 것입니다.
Mutable value(ex: 리스트)를 함수의 디폴트 매개변수로 포함하면, 다음과 같은 예상치 못한 동작이 일어나게 됩니다.
# Bad
def my_function(i, my_list=[]):
my_list.append(i)
return my_list
>>> my_function(1)
[1]
>>> my_function(2)
[1, 2]
>>> my_function(3)
[1, 2, 3]
위에 코드에서, my_function 함수를 호출할 때마다, 리스트 my_list는 이전 호출의 값을 계속 저장합니다. (우리가 함수를 호출할 때 빈 리스트로 시작하는 것을 원한다고 가정합니다) 이러한 동작을 피하기 위해서, 우리는 my_list의 디폴트 값을 None으로 설정하고 if 구문을 아래에 추가해야 합니다.
# Good
def my_function(i, my_list=None):
if my_list is None:
my_list = []
my_list.append(i)
return my_list
>>> my_function(1)
[1]
>>> my_function(2)
[2]
>>> my_function(3)
[3][1] 하나의 파이썬(.py) 파일을 의미하는 단어로 다른 파이썬 프로그램에서 사용하게끔 만들어 놓은 파일.
[2] 선형대수의 벡터 개념을 사용해 같은 인덱스에 위치한 원소들끼리 연산을 수행해서 반복문을 사용하지 않고 같은 위치의 값끼리 연산할 수 있는 것.
<원문>
10 Python Mistakes That Tell You’re a Nooby
©️위 번역글의 원 저작권은 Frank Andrade에게 있으며, 요즘IT의 모든 콘텐츠는 저작권법의 보호를 받는 바, 무단 전재와 복사, 배포 등을 금합니다.