개발
양질의 데이터를 판별하는 5가지 방법 : ③ 관계형 데이터베이스인가?

5분
2021.10.19.23.8K
양질의 데이터를 판별하는 5가지 방법 : ① 데이터 양은 충분한가?
양질의 데이터를 판별하는 5가지 방법 : ② 믿을 수 있는 데이터인가?

지난 ‘양질의 데이터를 판별하는 5가지 방법’ 2편에서는 양질의 데이터를 판별하기 위해 데이터 신뢰성을 정확히 파악하는 것이 중요함을 살펴보았습니다. 데이터 신뢰성을 판별하기 위해서는 데이터에 대한 면밀한 관찰이 선행되어야 했습니다. 하지만 데이터의 내용적 측면이 아닌 데이터 형식 자체만 보더라도 이 데이터가 고품질의 데이터인지 어느 정도 판가름을 할 수 있습니다. 빅데이터는 분명 다양한 방법으로 수집되어 다양한 모습을 띄고 있습니다. 보통 빅데이터의 특성을 이야기할 때 3V라는 단어를 언급하는 경우가 많습니다. Velocity(속도), Volume(양), Variety(다양성)까지 V로 시작하는 3가지 단어의 묶음입니다. 이때 Variety(다양성)이라는 단어는 오해를 발생시키기 쉽습니다. 아무리 다양한 모습을 가지는 빅데이터라고 할지라도 활용하기 좋은 데이터들은 지키고 있는 공통의 형식이 분명히 있습니다. 이번 시간에는 양질의 데이터라면 반드시 지켜야 하는 ‘데이터 형식’에 대해 이야기하려 합니다.
분석하기 좋은 양질의 데이터라면 반드시 지켜야 할 데이터 형식은 다음 한 마디로 표현할 수 있습니다. 바로 관계형 데이터베이스 형식입니다. 관계형 데이터베이스는데이터베이스 모델 중 하나로, 데이터를 행(Row)과 열(Column)의 테이블 형태로 저장하여 서로 관계있는 데이터를 관리하는 방식입니다. 1970년대에 그 개념이 고안되어 아직까지 널리 쓰이고 있습니다. 이 세상에 존재하는 셀 수없이 다양한 종류의 데이터를 알맞게 구분 짓고, 나누어 저장하기에 더할 나위 없이 적합한 형식입니다. 관계형 데이터베이스는 아래 그림처럼 행과, 열을 구성 요소로 하는 테이블을 데이터의 기본 단위로 삼습니다. 일반적으로 데이터를 상상하면 떠오르는 엑셀 형식의 모양이 바로 테이블 형식입니다.
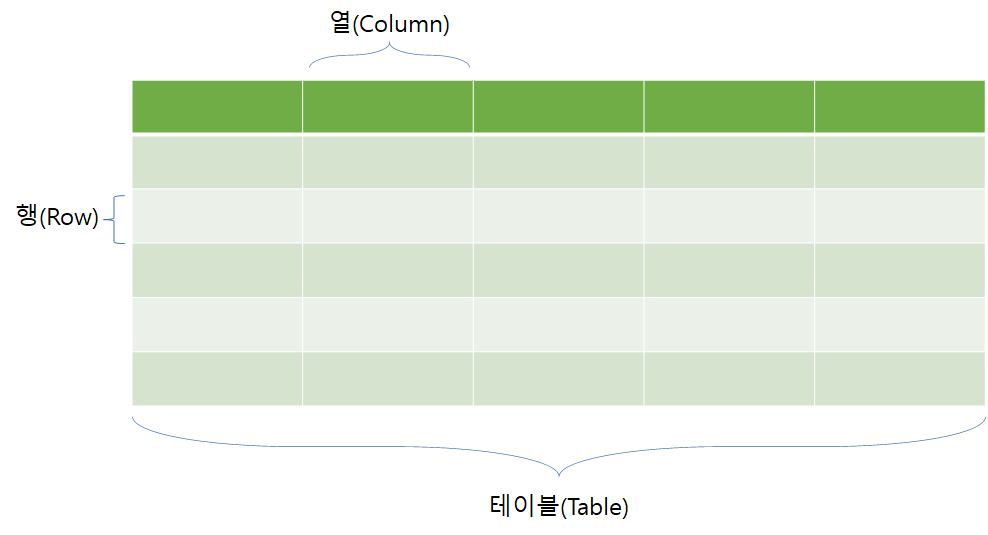
언뜻 보면 관계형 데이터베이스는 우리가 이해하기 쉽게 데이터를 표현하는 역할만을 하는 것으로 이해할 수 있습니다. 하지만 관계형 데이터베이스가 중요한 이유는 단순히 행, 열이라는 편리한 구조에만 그치지 않습니다. 행, 열의 형식은 관계형 데이터베이스의 구조일 뿐, 사실 ‘관계형 데이터베이스’로 불리기 위해서는 추가적인 조건을 만족해야 합니다. 관계형 데이터베이스로 불리기 위한 이 추가 조건들은 너무나 기본적이면서도 필수적인 내용들입니다. 그렇기에 이 조건을 지키지 않고 있다는 것은 곧 데이터로써 활용 가치에 한계가 명확하다는 것을 의미합니다.
또한, 기본적으로 관계형 데이터베이스는 연관 있는 여러 데이터들을 편리하게 표시해 주기 위해 개발된 양식입니다. 즉 관계형 데이터베이스 양식을 지키고 있는 데이터라면, 다른 데이터와 연결하기가 쉽다는 것을 의미합니다. 지난 ‘양질의 데이터를 판별하는 5가지 방법’ 2편에서, 대부분의 데이터들은 독립적으로 탄생하는 것이 아니라 다른 데이터와 결합되어 가공되는 것이라고 설명했습니다. 즉 단 하나의 데이터만을 이용할 것이라면 상관없겠지만, 보유한 다른 데이터와 유기적으로 연결하여 더 넓은 시야를 가질 수 있도록 데이터를 분석하려면 관계형 데이터베이스 양식을 따라야 하는 것이 선제 조건입니다.

앞서 행과 열은 단순히 관계형 데이터베이스를 표현하는 형식일 뿐 추가적인 관계형 데이터베이스의 구성 조건이 있다고 했습니다. 그리고 그 구성 조건이 너무나 기본적이면서 필수적인 내용이기에 관계형 데이터베이스 여부를 따지는 것이 중요하다고 했습니다. 이제 이 사실을 알았기에 다음으로 보아야 할 것은 과연 ‘어떻게 관계형 데이터베이스 양식을 지키고 있는지 파악하는가?’입니다. 그 해답은 테이블(Table)에 있습니다. 테이블은 관계형 데이터베이스에서 데이터의 기본 단위입니다. 따라서 테이블이 되기 위한 구성 조건을 모두 지키고 있다면 그것은 곧 관계형 데이터베이스 양식을 지키고 있다는 것을 의미합니다. 결국 테이블 형식을 지키지 않는 데이터를 판별한다면 그것이 곧 양질의 데이터를 판별하는 행동이 됩니다.
보유한 데이터를 테이블이라 부를 수 있으려면, 모든 데이터에 키(Key)가 존재해야 합니다. 데이터에서 키(Key)란 데이터의 속성(열) 중 식별자로 이용 가능한 속성을 의미합니다. 이해를 돕기 위해 한 가지 예시를 들어보겠습니다. 우리나라 국민의 정보를 수집하여 데이터화한다고 할 때 그 데이터 안에는 이름, 주민번호, 나이, 성별 등 다양한 정보가 적재될 것입니다. 그러한 각 정보들은 모두 속성(열)으로 불리게 됩니다. 이제 우리가 가진 데이터를 테이블이라 부르기 위해서는 이 속성 중 키가 있어야 합니다. 즉, 하나의 속성만 보더라도 데이터 자체를 식별할 수 있는 값이 필요합니다. 우리나라에는 같은 나이, 성별, 이름을 가진 사람들이 많기에 이 정보만으로는 정확히 특정 개인을 식별할 수 없습니다. 그러나 주민번호는 분명히 모든 개인이 각기 다른 값을 가지고 있습니다. 따라서 이 예시라면, 주민번호가 키가 될 수 있으며 키가 있기에 이 데이터는 테이블로 부를 수 있습니다.
사실 데이터 분석가 입장에서 데이터에 키가 없다는 것은 끔찍한 상황입니다. 기본적으로 데이터에 키가 없다면 이 데이터가 어떤 개인 혹은 상황을 의미하는지 전혀 파악할 수 없습니다. 열심히 데이터를 분석하고 인사이트를 도출한다 한들, 그 결과를 실제 상황에 전혀 적용할 수 없습니다. 각 데이터가 무엇을 식별하고 있는지를 알 수 없기 때문입니다. 그리고 데이터에 키가 없다면 다른 데이터 테이블과 결합을 하는 게 불가능합니다. 어떤 데이터를 특정하게 식별할 수 없다는 같은 이유 때문입니다. 테이블 A에서의 키 a와 테이블 B에서의 키 b가 있어야 a와 b의 값을 비교하여 특정 대상에게 A에서의 정보와 B에서의 정보를 모두 할당할 수 있습니다.
데이터 테이블에서 키로 추정되는 속성이 존재한다면, 마지막으로 확인할 것은 이 키가 진짜 키의 조건을 제대로 만족하고 있는지 살펴보는 것입니다. 그리고 그 조건은 크게 유일성과 무결성으로 나눌 수 있습니다. 유일성은 하나의 키가 하나의 식별 값을 정확히 식별할 수 있을 때, 무결성은 데이터에서 키값이 비어 있거나 중복되지 않아야 함을 이야기하는 조건입니다. 키의 정의를 생각해 본다면 당연한 이야기입니다. 주민등록번호는 그 자체만으로 특정 개인을 추정할 수 있도록 만들어져야 합니다. 그리고 똑같은 주민번호를 가진 사람이 2명 이상 있으면 안 되며, 모든 개개인이 모두 주민등록번호를 가질 수 있도록 해야 합니다.
결국 관계형 데이터베이스 형식을 지키고 있는 것과 데이터 테이블 형식을 지키고 있는 것, 키를 가지고 있는 것을 파악하는 것은 모두 같은 작업입니다. 최종적으로 우리가 양질의 데이터를 판별하기 위해 해야 할 것은 키(Key)의 후보군을 찾고 키가 유일성과 무결성을 만족시키고 있는지를 보면 됩니다. 실제 데이터 분석 상황으로 생각하면, 데이터를 처음 받았을 때 모든 데이터를 확실하게 식별할 수 있는 속성을 찾습니다. 그리고 그 속성이 모든 데이터에 하나도 빠짐없이 값이 기록되어 있는지, 값이 중복되어 있지는 않는지를 파악합니다. 그리고 정확히 조건을 만족하는 키가 없다면 해당 데이터는 활용하기에는 힘든 저품질의 데이터로 판별을 할 수 있습니다.

이번 시간에는 관계형 데이터베이스 형식을 지키는 것의 중요성에 대해 살펴보았습니다. 아무리 데이터 형식에 있어서 다양성이 존중되는 빅데이터 생태계일지라도 분석을 위한 기본적인 형식은 반드시 지키고 있어야 합니다. 다시금 말하지만 이처럼 관계형 데이터베이스 형식을 지키고 있는 것은 양질의 데이터의 기본적인 전제 조건입니다. 유일성, 무결성 원칙을 지키는 키가 존재한다고 할지라도 무조건 양질의 데이터는 아닙니다. 하지만 그렇지 않다면 저품질의 데이터라고 판별해도 좋습니다. 물론 꼭 지켜야 하는 것은 아니지만 지키면 분석하기 좋은 ‘우대 사항’ 정도의 데이터 형식도 존재합니다. 이에 대해서는 ‘양질의 데이터를 판별하는 5가지 방법’ 4편에서 살펴보도록 하겠습니다.
©️요즘IT의 모든 콘텐츠는 저작권법의 보호를 받는 바, 무단 전재와 복사, 배포 등을 금합니다.