기획
AB 테스트 인사이트의 새로운 차원, 베이지안 통계적 가설 검정

12분
2021.09.17.8.9K
* 시리즈로 구성된 글입니다. 저번 글에서는 AB 테스트를 결과를 분석하는 빈도주의 통계적 가설 검정에 대해 다뤘습니다. 이번 편에서는 베이지안 통계 방식에 입각한 가설 검정을 살펴봅니다.
대안의 전환율 개선이 95% 신뢰구간에서 통계적으로 유효하다는 말은, 대안이 무의미하다고 가정하면 해당 전환율이 관측될 확률이 5% 이하로 희박하니 대안의 전환율 개선을 유의미하다고 봐야 한다는 뜻입니다. AB 테스트 결과를 빈도주의 통계적 가설 검정으로 분석하는 과정을 설명한 저번 편의 결론이었습니다.
AB 테스트를 하고 결과를 공유할 때면 ‘대안이 원본보다 나을 확률’에 관해 물어보는 사람이 꼭 한 명쯤은 생깁니다. 단순한 지표 비교를 넘어서, AB 테스트로 얻은 결과가 정말로 의미 있는지 묻는 간단한 질문이지만 빈도주의 접근법으로는 답할 수가 없습니다. 신뢰구간, p값에 대해 설명하고 이 결과를 무효로 돌리기에는 너무 확률이 적다고 이야기합니다. 적당히 수긍하는 듯한 반응이 되돌아오고 회의에는 다음 논제가 들어섭니다. 통계학적 난해함이 AB 테스트가 전사적 문화로 발전하는 과정에서 걸림돌이 되는 상황입니다. 해결책이 필요합니다.
빈도주의 통계학은 들쭉날쭉한 이해도를 가진 조직 구성원 사이에서 AB 테스트로 협업하는데 적절한 언어를 제공하지 않습니다. AB 테스트 설계자는 이제 3가지 선택을 강요받습니다. 첫째, 가설 검정에 대해서는 ‘그냥 그런가 보다’하고 넘어가도록 하기. 몇몇 상황에서 해석 문제가 생길 수 있습니다. AB 테스트는 결국 과정을 이해하는 소수의 전유물이 될 것입니다. 둘째, 전 조직원이 빈도주의 통계학을 익히기. 어려운 일일뿐더러 아래서 설명할 빈도주의의 한계를 해결할 수는 없습니다. 셋째, ‘그냥 그런가 보다’하고 넘어가도 문제없는 협업이 가능한 접근법을 사용하기. 이번 글에서 설명할 내용은 마지막 선택지, 베이지안 통계학(Bayesian Statistics)에 대한 것입니다.
AB 테스트를 실행하고 언제 결과를 체크하나요? 하루? 이틀? 실험 종료는? 1천 명의 고객이 다녀간 후에? 아니면 2천 명? AB 테스트 초보자라면 난데없는 위의 질문에 고개를 갸우뚱할 수도 있을 겁니다. 짬짬이 결과를 보다 통계적 유의성이 달성된 순간에 종료하면 그만 아니었나요? 예시를 보며 어떤 상황이 벌어질 수 있는지 확인해보겠습니다.
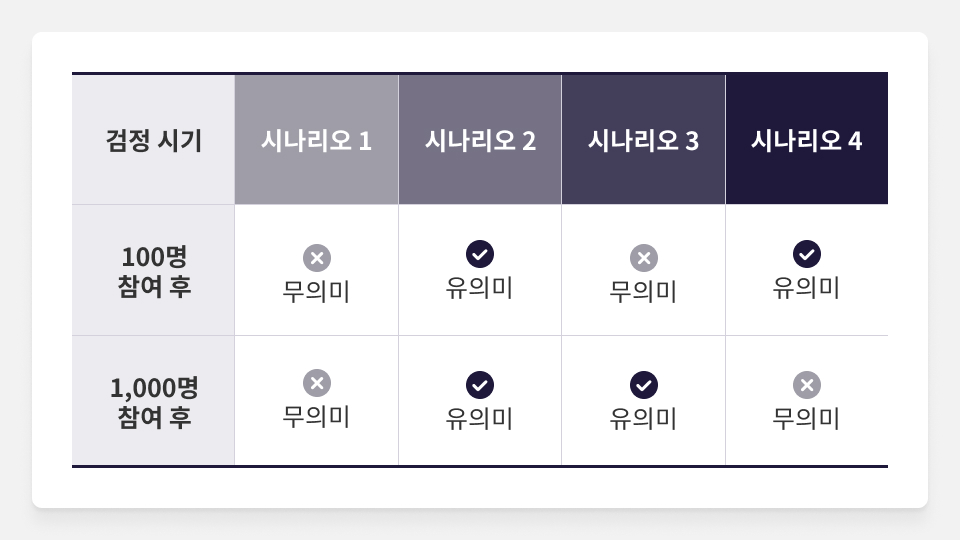
예시는 4개의 상황에서 각각 1천 명과 2천 명의 고객이 실험에 참여했을 때 95% 신뢰구간에서 통계적 가설 검정을 시도한 결과입니다. 처음부터 끝까지 통계적으로 무의미하거나 유의미한 경우, 처음에는 무의미했다가 나중에 유의미해진 경우, 반대로 처음에 유의미했다가 나중에 무의미해진 경우가 있습니다. 마지막 상황이 중요합니다. 1천 명의 고객이 실험에 참여한 결과만을 보고 실험을 종료하여, 데이터가 좀 더 모였을 때 통계적으로 무의미해지는 사실을 모르고 지나갈 수 있다는 겁니다.
대립가설을 지지하는 데이터가 실험 초반에 몰려 발생하는 사고[1]입니다. 이를 제1종 오류(Type I Error)라고 합니다. 반대로 실제로는 유의미한 차이가 있지만 대립가설에 반하는 데이터가 몰려 AB 테스트를 일찍 단념할 수도 있습니다. 이를 제2종 오류(Type II Error)[2]라고 합니다. 두 오류는 충분한 양의 데이터를 관측하기로 정해서 그 이전에 섣부르게 실험 종료하지 않겠다고 합의한다면 해결할 수 있습니다. 그런데 얼마나 더 많이 모아야 할까요? 통계적 가설 검정을 도입하기 전에 생겼던 문제가 다시 일어나고 있습니다.
빈도주의가 비즈니스적 필요를 만족시키기 어렵다는 것도 문제입니다. AB 테스트는 실험이 진행되는 기간의 수익 일부를 탐색비용으로 지불하여 더 큰 가치를 찾아내는 일입니다. 따라서 AB 테스트의 결과가 어느 정도의 손익을 가져다주는지 알 필요가 있습니다. 저번 글을 읽었다면 알겠지만, 같은 10%p 전환율 개선이라도 90% 신뢰구간을 간신히 만족했을 경우와 99% 신뢰구간에서 넉넉하게 유의미한 경우의 예상 손익은 다를 것입니다.
하지만 빈도주의 통계는 실험 결과가 어느 범위 내에서 확실한가, 그렇지 않은가만을 알려주기 때문에 위와 같은 문제에서 도움이 되지 않습니다. 대안 B의 전환율이 원본 A보다 10%p 더 높지만 그 차이가 유의미할 확률이 50%, 차이가 없을 확률이 50%로 같다고 가정해봅시다. 이 상황에서 대안 B를 채택하는 일은 현명한 비즈니스 결정입니다. 통계적으로 유의미한 결과는 아니지만, 대안 B는 분명 더 나은 선택입니다. AB 테스트, 전환율 최적화는 과학 논문 출판보다 주식 거래에 가까운 일[3]입니다. AB 테스트에서 대안의 승리는 바람직하지만 필수적인 것은 아니며, 비긴 결과도 허용됩니다. 다만 패배만을 필수로 피해야 할 뿐입니다.
베이지안 통계학 또는 베이즈 통계학은 확률을 해당 사건이 일어날 믿음의 정도(Degree of Belief)로 보는 베이지안 확률론에서 비롯된 통계적 접근법[4]입니다. 확률에 대한 해석은 빈도주의 방식과 비교해보면 명료해집니다.

AB 테스트에서 베이지안 통계로 얻을 수 있는 결론은 ‘특정 기준에 만족하므로 대안의 결과는 유의미’가 아니라 ‘대안의 결과가 원본보다 나을 확률은 몇 퍼센트’, 그리고 ‘대안을 선택했을 때 예상 손실은 몇 퍼센트’입니다. 빈도주의 통계는 유의미 혹은 무의미, 양자택일의 명료한 결과만을 돌려주지만, 베이지안 통계는 비즈니스에 있어서 훨씬 도움이 되는 인사이트를 만들어 줍니다. 구글 옵티마이즈[5], VWO[6], 그리고 이전에 소개했던 Growth Book과 같은 AB 테스트 플랫폼이 베이지안 통계를 활용하는 이유가 여기 있습니다.
베이지안 통계가 가지고 있는 기본 원리는 베이즈 정리(Bayes’s Theorem)입니다. 내용은 다음과 같습니다.
(어떤 데이터가 주어졌을 때 가설이 참일 확률) = {(가설이 참일 때 어떤 데이터가 주어질 확률) * (가설이 참일 확률)} / (어떤 데이터가 주어질 확률)
이를 도식화하면 다음과 같습니다.
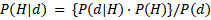
어떻게 쓰이는 식인지 감이 잘 잡히지 않을 겁니다. 어느 날 갑자기 바이러스 X가 유행한 상황을 가정해봅시다. 바이러스 X 확진 검사가 빠르게 개발되었습니다. 확진자에게 이 검사를 시행하면 99% 확률로 확진 사실을 알아맞히고, 비확진자에게 검사하면 99% 확률로 확진되지 않았다는 사실을 알아냅니다. 한 마을의 전체 주민 1%가 바이러스 X에 확진되었을 때, 이 검사로 확진자라는 판단을 받은 주민은 얼마의 확률로 진짜 확진자일까요? 베이즈 정리를 활용해서 이 문제를 풀면 재미있는 결과[7]가 나옵니다.
(검사에서 확진 판단받았을 때, 확진자일 확률) = {(확진자가 검사에서 확진 판단받을 확률) * (확진자일 확률)} / (검사에서 확진 판단받을 확률)
= (0.99 * 0.01) / (확진자가 검사에서 확진 판단받을 확률) *(확진자일 확률) + (비확진자가 검사에서 확진 판단받을 확률) * (비확진자일 확률)
= (0.99 * 0.01) / (0.99 * 0.01 + 0.01 * 0.99)
= 0.5
베이즈 정리에 따르면 검사에서 확진을 판단받은 주민이 정말 확진자일 확률은 50%입니다. 직관적인 생각과 매우 다른 결과가 나오죠. 확진 검사의 민감도(Sensitivity)와 특이도(Specificity) 정보가 더해지면서 전체 주민 중 1%가 바이러스 X에 확진되었다는 사실의 확실성은 절반이 되었습니다. 이때 전체 주민 1%가 확진되었다는 주어진 확률을 사전 확률(Prior Probability), 검사 정보를 받아들인 후 절반이 된 확률을 사후 확률(Posterior Probability)이라고 합니다.
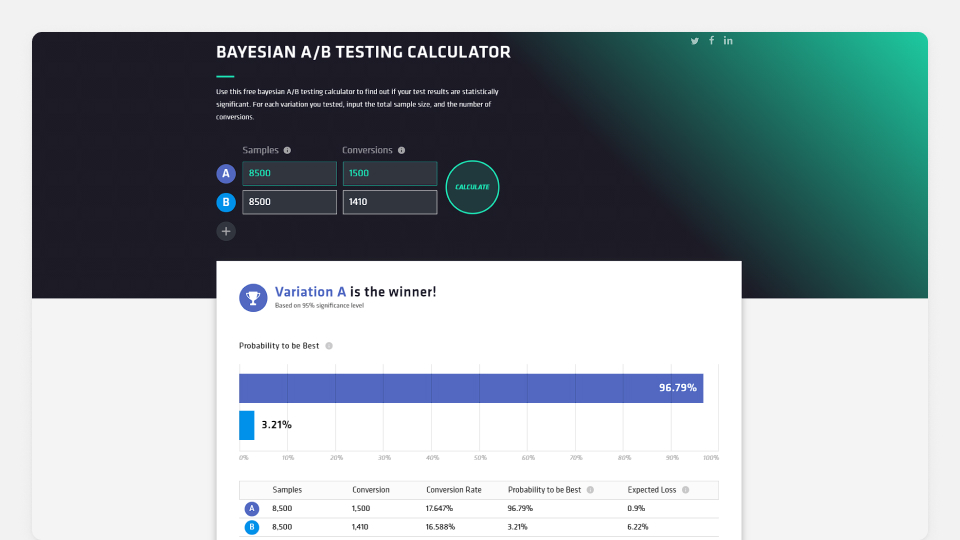
일반적인 형태의 베이지안 통계 AB 테스트 결과 분석 계산기입니다. 특정 대안이 원본을 포함한 다른 안보다 나을 확률, 해당 대안을 채택했을 때 예상 전환율 손실률이 계산됩니다. 베이지안 통계의 특성상 이 두 값은 단어 그대로 받아들이면 되지만, 어떻게 이 값이 나왔는지 알려면 베이지안 통계를 AB 테스트 결과 분석에 적용하는 과정을 이해해야 합니다. 이 과정은 크게 봤을 때 다음 3단계로 이뤄집니다.
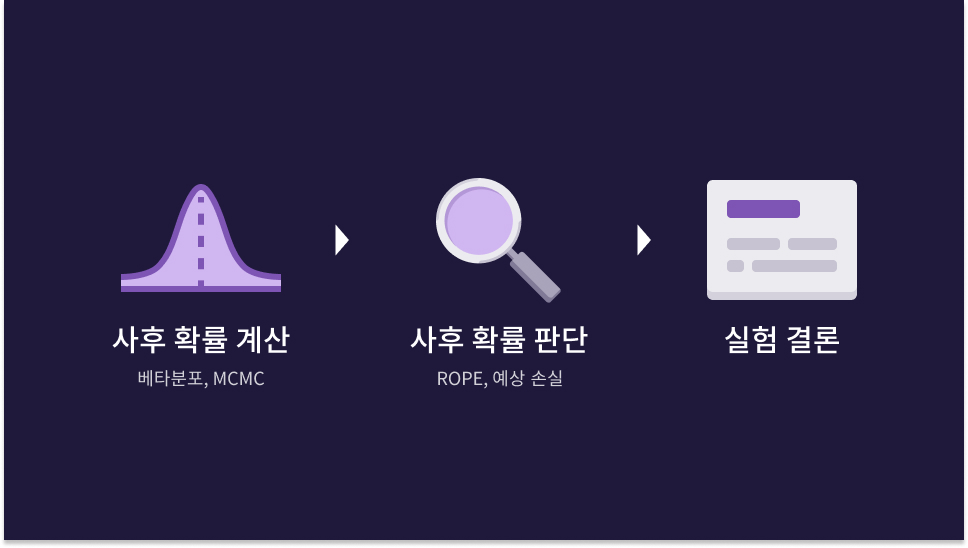
AB 테스트 결과 분석을 목적으로 베이지안 통계를 적용하려는 입문자에게 헷갈릴 만한 일은, 사후 확률을 계산하고 판단하는 방식이 여러 가지라는 것[8]입니다. AB 테스트 결과에서 사후 확률을 계산하는 방법은 대표적으로
이 있습니다. 이렇게 계산된 사후 확률이 특정 기준에 해당되면 실험을 종료하거나 계속하는 의사결정을 내려야 합니다. 여기에도 크게 2가지 방식이 사용됩니다.
베타 분포는 특정 간격으로 제한된 랜덤 변수를 모델링하는데 사용되는, 구간 [0, 1] 사이의 연속 확률 분포의 집합[9]입니다. 베타 분포는 랜덤화 된 백분율이나 비율을 나타내기에 적합한 모형입니다. AB 테스트 전환율은 이항 분포 형태를 가졌기 때문에 베타 분포를 켤레 사전 분포(Conjugate Prior Distribution)로 활용하기에 알맞습니다. 켤레 사전 분포란 신발의 두 짝처럼 사전 분포와 사후 분포가 같은 분포족에 속할 때 사전 분포 쪽을 뜻합니다.
베타 분포는 식으로 B(α,β)로 표현합니다. α는 전환 수, β는 비전환 수를 넣습니다. 50명이 참가해서 5명이 전환해 전환율이 10%인 경우를 베타 분포로 나타내면 아래와 같습니다.
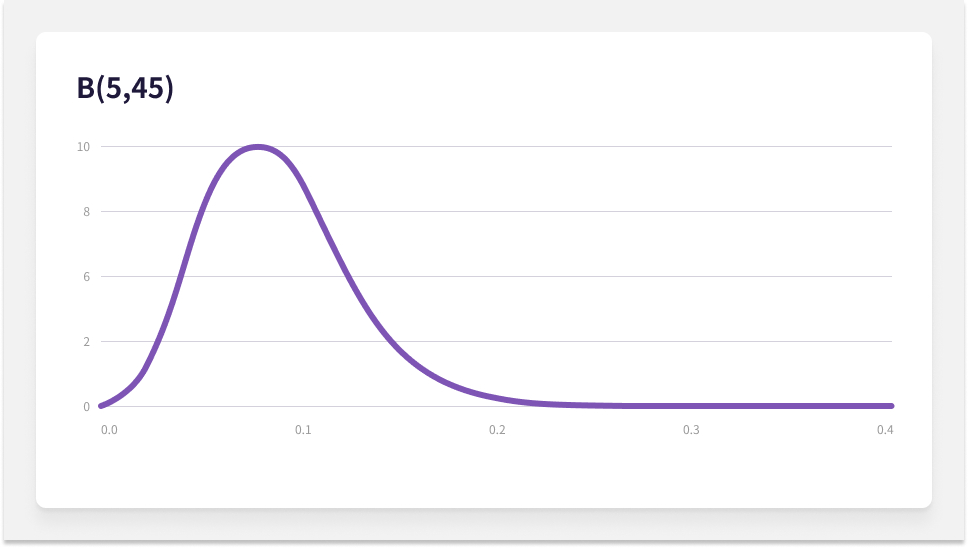
다음은 전환율이 10%으로 같지만 실험 참여자가 많은 경우를 살펴보겠습니다.
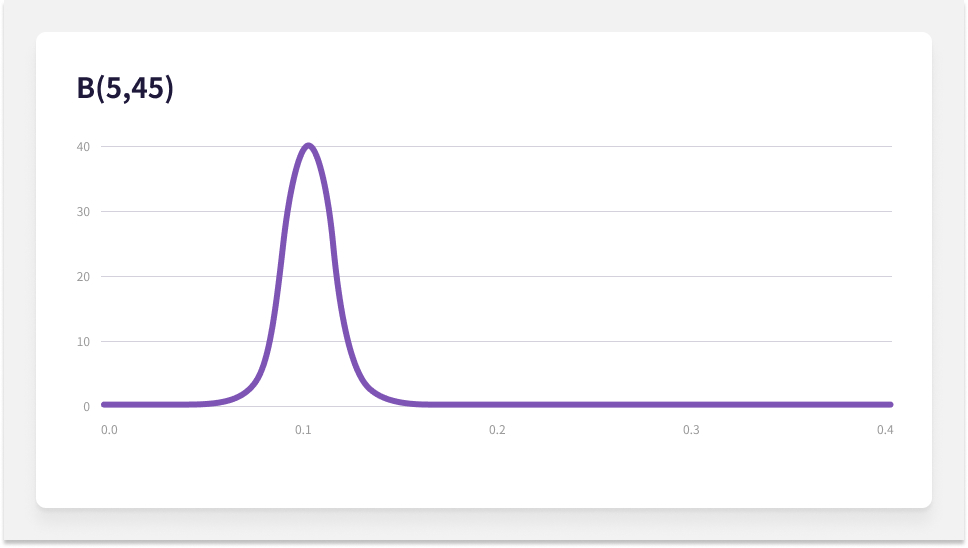
실험 참여자가 많아질수록 그래프는 좁고 뾰족해집니다. 더 작은 전환율 범위에서 밀도 있는 모습입니다. 더 확실한 전환율을 보여주고 있습니다.[10] 전자를 사전 확률, 후자를 사후 확률이라고 볼 수 있습니다. 예시처럼 정보가 있다면 참고해서 적합한 사전 확률(Informative Prior)을 계산할 수 있겠지만, B(1,1)의 무정보적 분포(Uninformative Prior)[11]로 시작하는 것도 방법입니다.
AB 테스트는 여러 안에서 사후 확률이 계산될 것입니다. 결합 사후 분포(Joint Posterior Distribution)는 단순히 각 안의 사후 확률을 곱하는 것으로 완성됩니다. 이제 AB 테스트를 대표하는 사후 확률이 생겼습니다. 이제 정해놓은 기준에 맞춰 의사결정하면 됩니다.
MCMC는 임의의 랜덤한 표본에서 시작, 이전 표본을 참고하여 다음 표본을 표집 하는 알고리즘[12]입니다. 저번 편에서도 설명했지만 AB 테스트는 ‘앞으로 제품을 사용할 고객’이라는 모집단을 대표하는 표본인 ‘실험 참여 고객’을 통해 전환율을 개선합니다. 이를 위해서는 표본과 모집단이 최대한 닮아야 합니다. 카메라 구매 예정 고객을 대상으로 카메라별 설명 영상을 제공하는 실험을 진행해놓고, PC 구매 예정 고객에게 영향이 미칠 것을 원한다면 뜬금없겠죠. 모집단을 닮은 표본을 만드는 건 어려운 일입니다. 빠르게 표집 하려고 크기를 줄이면 정확도가 낮아지고, 정확하게 표집 하려고 크기를 늘리면 표집 속도가 느립니다.
MCMC는 이름 그대로 마르코프 연쇄와 몬테카를로 방법, 2가지를 활용해서 이 문제를 해결합니다. MCMC는 이전 표본에서 다음 표본으로 이동할 때 조건부 확률분포가 주어졌다는 원리를 이용해 나타나는 패턴을 활용, 표본의 크기와 상관없이 모집단과 유사한 확률 분포를 만들어 냅니다.MCMC는 Python, R 등 여러 프로그래밍 언어에서 라이브러리로 제공되고 있습니다.
ROPE를 활용한 의사결정 방법은 인디애나 대학의 심리학 및 뇌 과학 교수 존 크루슈케(John K. Kruschke)는 논문 <t-검정을 대체하는 베이지안 추정(Bayesian Estimation Supersedes the t Test; 일명 BEST)>[13]에서 제시된 개념을 기반으로 합니다. BEST 논문의 방식은 대립가설이 채택에 실패해도 귀무가설을 채택할 수 없는 빈도주의 방식과는 다르게, 귀무가설에 대응되는 값을 채택할 수 있어 이를 이용해 AB 테스트의 결과를 분석합니다.
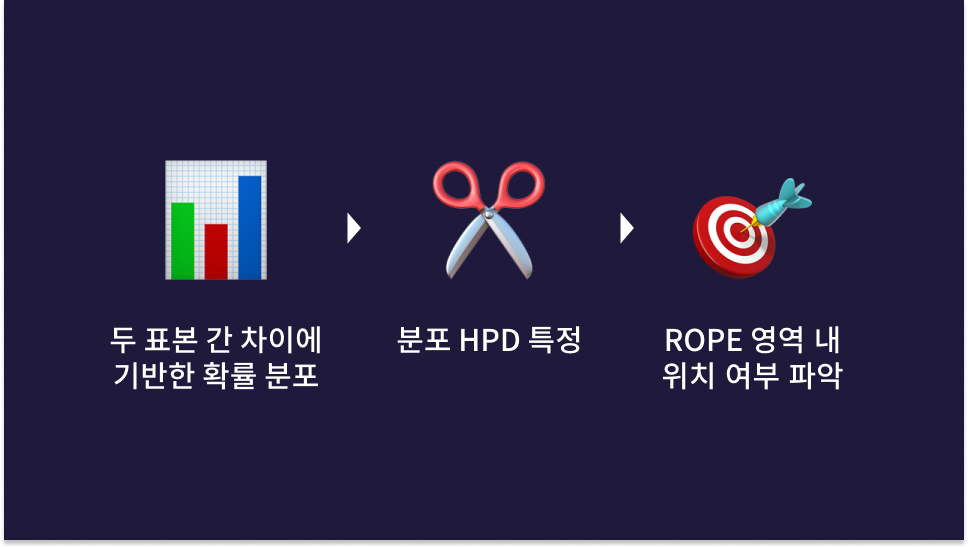
BEST 논문의 방식은 두 표본 간 차이에 대한 추정 값을 모아 확률 분포를 만든 후, 특정 HPD (Highest Posterior Density) 구간을 기준으로 해당 분포의 평균, 즉 가장 믿을 만한 두 표본의 차이에 대한 추정 값이 특정 영역(ROPE)에 위치하는가, 그렇지 않은가에 따라 AB 테스트 결과의 통계적 유의성을 판단하는 순서로 진행됩니다. 여기서 추정 값에는 효과 크기(Effect Size)가 흔히 사용됩니다. 효과 크기는 비교하는 표본 간 차이 혹은 관계가 어느 정도인지, 즉 연관도가 얼마나 되는가를 나타내는 지표[14]입니다. 효과 크기를 계산하는 방법은 다양하지만 지금처럼 독립된 두 변수를 비교하는 경우에는 두 표본의 평균 차이를 표준편차로 나누어 도출합니다.
여기서 HPD는 바로 위에서 언급한 확률 분포에서 가장 밀도 높은 영역을 발라내는 목적을 가지고 선을 그어 해당 영역의 면적을 구한 것[15]입니다. 마치 빈도주의의 p값으로 정한 신뢰구간처럼, HPD로 분포에서 필요한 부분만을 판단에 활용합니다.
ROPE은 빈도주의 통계로 치면 귀무가설, 실제 AB 테스트라면 실험 결과에서 도출된 차이가 통계적으로는 무의미하다는 사실을 대표하는 값(이하 Null 값)이 분포상에서 양과 음의 방향으로 생성하는 일정한 구간입니다. 따라서 두 표본 간 차이에 대한 분포의 평균이 ROPE 내에 위치한다면 해당 AB 테스트 결과의 차이는 무의미한 것으로 판단할 수 있습니다. 많은 경우 ±0.1의 ROPE가 사용됩니다.
AB 테스트 하나를 진행했다고 가정합시다. 서로 다른 3가지 시나리오에 따라 원본 A와 대안 B 간 효과 크기의 확률 분포를 만들었습니다. HPD에 포함된 영역과, 효과 크기 = 0(원본 A와 대안 B 사이에 유의미한 차이가 없는 경우를 나타내는 값)과 해당 지점 좌우로 뻗친 ROPE를 표시하겠습니다.
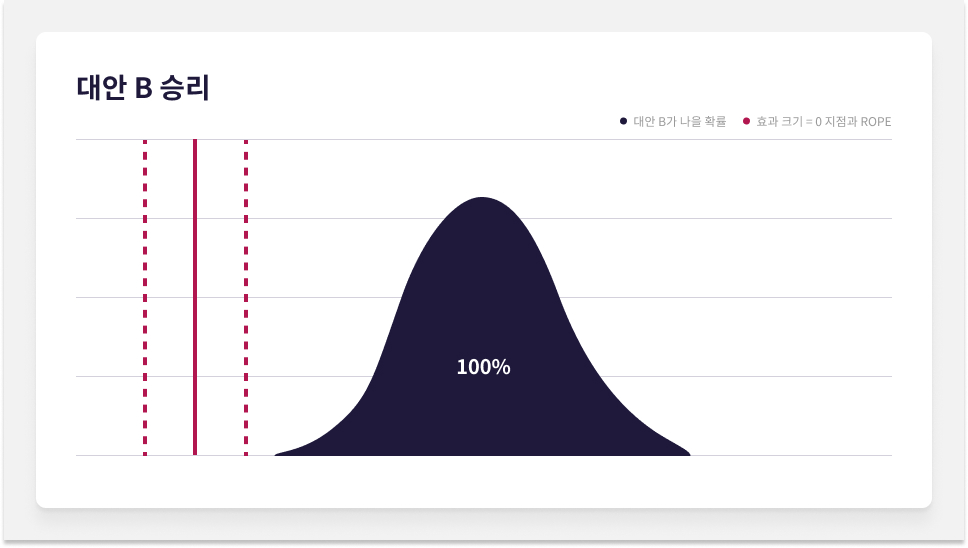
시나리오 A에서는 HPD 구간에 분포의 포함된 영역이 ROPE에서 완전히 벗어나 있으며, ROPE를 기준으로 양의 방향에 위치해 있습니다. 원본 A에 대한 대안 B의 효과 크기를 구한 경우, 즉 대안 B의 평균에서 원본 A의 평균을 빼서 계산한 분포라면 시나리오 A는 대안 B의 완전한 승리를 나타냅니다. 효과 크기가 0인 지점을 분포의 전 영역이 우측에 위치해 있으므로 대안 B가 원본 A보다 나을 확률은 100%입니다.
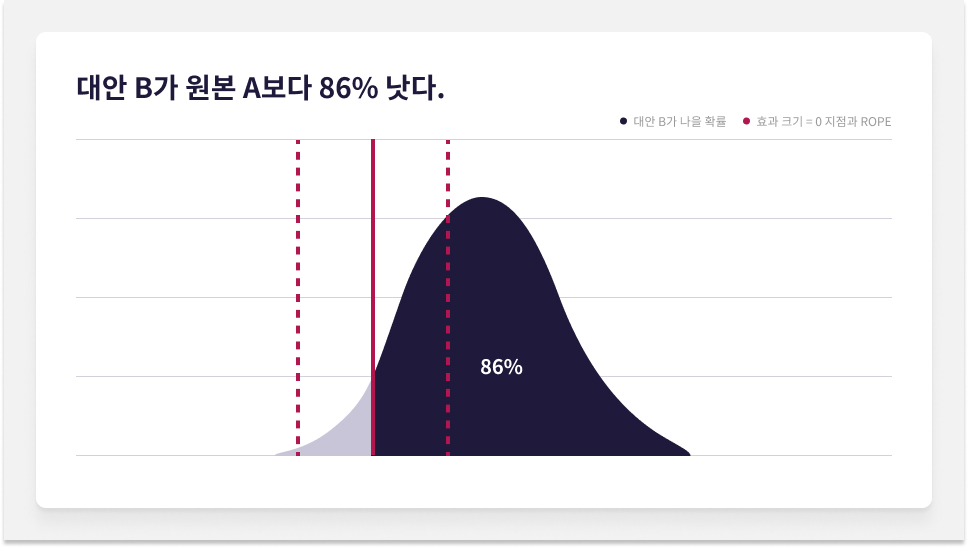
시나리오 B에서는 HPD 구간에 포함된 분포의 영역이 ROPE 안에도, 밖에도 있습니다. 결과의 통계적 유의성은 아직 확실하지 않습니다. 그러나 효과 크기가 0인 지점을 기준으로 봤을 때 분포는 양의 방향에 더 많은 영역을 차지하고 있습니다. 대안 B는 해당 영역의 면적만큼 원본 A보다 낫습니다.
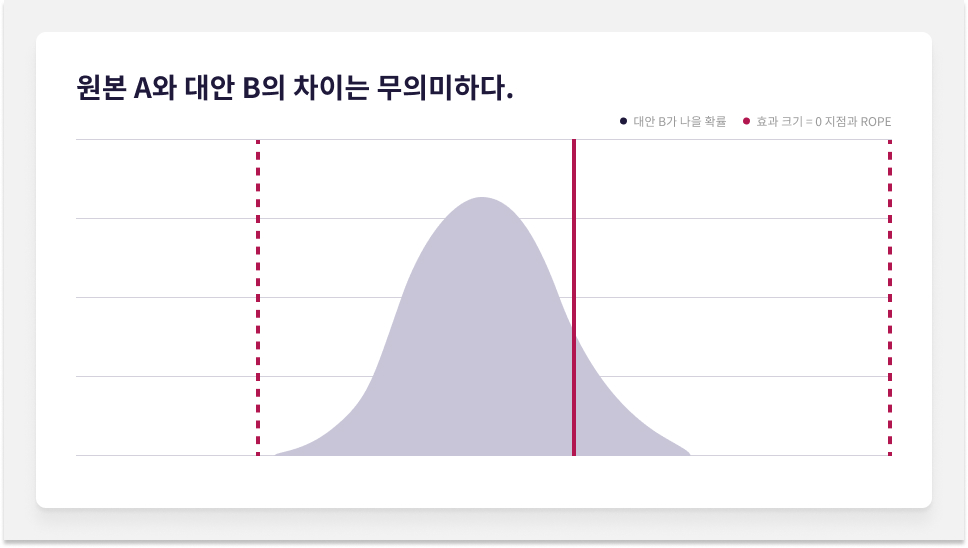
시나리오 C에서는 HPD 구간에 포함된 분포의 영역이 ROPE 안에만 있습니다. 원본 A와 대안 B 사이의 차이는 무의미합니다. 실험을 종료합니다.
ROPE 방식이 통계적 유의성에 따라 결과를 판단하는 방식이었다면, 예상 손실 측정 방식은 원본 A나 대안 B 중 하나를 승리 안으로 판단하고 실험을 종료했을 때 발생하는 손실로 실험 결과를 판단합니다. 예상 손실이 매우 작아 비즈니스에 영향을 미치지 않을 정도일 때 실험을 종료하고 더 나은 전환율을 보인 안을 채택합니다. 이 방식은 AB 테스트 플랫폼 VWO의 결과 분석 툴을 만들기도 한 데이터 과학자 크리스 스투키오(Chris Stucchio)에 의해 고안[16]되었습니다.
우선 두 안의 전환율 차이를 구합니다. 이 값은 0 이상입니다. 식으로 보여드리겠습니다.

이제 다음 함수로 두 안의 결합 사후 분포의 예상 손실을 구할 수 있습니다. (x에는 예상 손실을 구하고자 하는 안, A 혹은 B를 넣을 수 있습니다.)
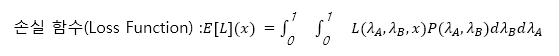
이제 원본 A와 대안 B에 채택했을 때의 예상 손실을 매길 수 있습니다. 해당 값이 임계값 이하라면 설사 손실이 나도 비즈니스에 영향이 없을 것으로 보고 실험을 종료합니다. 때문에 임계값은 충분히 낮은 수치로 정해져야 합니다.
빈도주의 통계적 가설 검정은 AB 테스트 결과 분석으로 활용하는데 2가지 한계가 있습니다.
베이지안 확률론은 확률을 해당 사건이 일어날 믿음의 정도로 봅니다. 베이지안 통계는 사전 확률에서 데이터를 받아들여 사후 확률을 계산합니다. ‘특정 기준에 만족하므로 대안의 결과는 유의미’가 아니라 ‘대안의 결과가 원본보다 나을 확률은 몇 퍼센트’, 그리고 ‘대안을 선택했을 때 예상 손실은 몇 퍼센트’처럼 제품을 운영하는 데 도움이 되는 인사이트를 얻을 수 있습니다.
AB 테스트 결과가 베이지안 통계적으로 분석되는 과정은 다음 3단계로 이뤄집니다.
AB 테스트 결과 분석에 빈도주의와 베이지안 무엇이 더 나은지에 대해서는 논란[17]이 많습니다. 시리즈를 읽으면서 두 방식을 모두 알았으니, 같은 실험에서 비교해보는 것도 좋은 방법입니다.
[1] Evan Miller, 2020 - How Not To Run an A/B Test
[2] Shubhi Ahluwalia(VWO), 2021 - Type I and Type II Errors in A/B Testing and How to Avoid Them
[3] Chris Stucchio, 2021 - VWO SmartStats: Testing for Truth Versus Maximizing Revenue
[4] 위키백과 - 베이즈 확률론
[5] Optimize Resource Hub - General methodology
[6] VWO - SmartStats For Smarter Business Decisions
[7] shurain(Personal Perspective), 2018 - Properties of Probability
[8] Marginalia, 2017 - Bayesian A/B Testing: a step-by-step guide
[9] Wikipedia - Beta distribution
[10] Ian(Locutus of Blog), 2011 - Proportionate A/B testing
[11] 위키백과 - 사전 확률
[12] 삼성소프트웨어멤버십, 2019 - Markov Chain Monte Carlo 샘플링의 마법
[13] J. Kruschke, 2013 - Bayesian estimation supersedes the t test.
[14] 남상건, 2015 - 효과크기의 이해(Understanding Effect Sizes)
[15] D. Hitchcock - Lecture notes available for the course STAT J535(Introduction to Bayesian Data Analysis, South Carolina University)
[16] Chris Stucchio, 2015 - Bayesian A/B Testing at VWO
[17] Alex Birkett(CXL), 2020 - Bayesian vs. Frequentist A/B Testing: What’s the Difference?
©️요즘IT의 모든 콘텐츠는 저작권법의 보호를 받는 바, 무단 전재와 복사, 배포 등을 금합니다.