기획
p값? 신뢰구간? AB 테스트를 완성하는 통계 분석, 기본 개념 잡기

9분
2021.09.09.13.3K
* 시리즈로 구성된 글입니다. 이번 글에서는 AB 테스트 결과를 분석하는 빈도주의 통계적 가설 검정에 대해 다룹니다. 다음 편에서는 베이지안 통계 방식에 입각한 가설 검정을 살펴봅니다.
이전에 연재한 AB 테스트 가이드에서 실행한 AB 테스트의 결과 분석은 실험의 결실을 거두는 일종의 수확이라고 비유한 적 있습니다. AB 테스트의 모든 과정이 결과를 위해 존재하고, 그렇게 도출된 결과는 인사이트화 되어 제품과 조직의 성장, 그리고 또 다른 AB 테스트에 기여하는 사이클에 있어서 필수적인 부분이기 때문입니다. 한 번이라도 AB 테스트를 돌려본다면 결과 분석이 생각보다 어려운 일임을 깨닫게 됩니다. 뻔히 눈에 보이는 결과, 수치인데 매번 해석하기가 난감합니다.
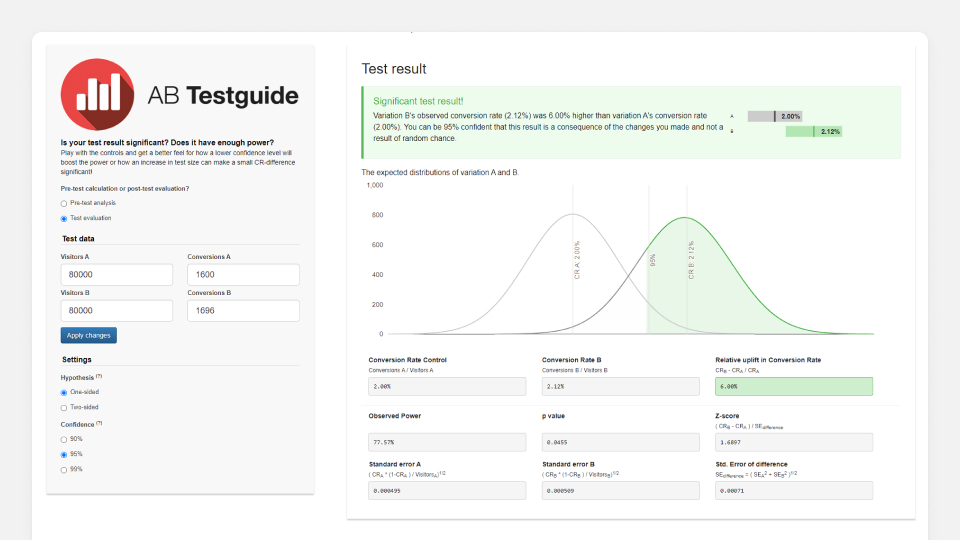
위와 같이 AB 테스트 결과의 통계적 유의성을 알려주는 계산기를 몇 번 소개한 적이 있습니다. 이런 복잡한 계산기가 필요한 이유는 ‘이 AB 테스트 결과를 믿을 것인가’를 결정하기 위해서입니다. 원본 A의 전환율이 10건 중 2건으로 20%, 대안 B의 전환율이 10건 중 6건으로 60%가 나왔다면, 대안 B가 3배의 성과를 거뒀으니 실험을 종료하고 대안 B로 고정하자고 이야기할 수 있을까요? 10건 중 6건은 우연일 수 있으니 데이터를 좀 더 모아야 한다는 의견은 충분히 상식적입니다. 그렇다면 데이터를 얼마나 더 모아야 할까요? 1천? 1만? 그 이유는 무엇인가요? 여기서부터 AB 테스트 결과 분석이 어려워집니다. 구글링을 통해 p값, 신뢰구간, 통계적 유의성에 대한 정보를 알게 됩니다. 이해는 안 되지만 아무튼 계산기도 발견합니다. 반신반의하면서도 계산기를 사용해 결과를 분석합니다.
이런 태도가 실무에서는 별다른 문제가 되지 않을 수도 있습니다. 결국 AB 테스트는 제품과 조직을 위한 도구일 뿐입니다. 보닛 아래서 무슨 일이 일어나는지 정확히 설명할 수는 없어도 자동차를 모는 데 문제는 없습니다. 그러나 그 신뢰는 자동차가 지난 몇 세기 동안 굴러다녔다는 사실에서 비롯되었습니다. AB 테스트는 사정이 다릅니다. 좋다고는 하는데 내 제품과 조직에 맞을지는 알 수 없습니다. AB 테스트는 이유 있는 제품을 만듭니다. 어떤 테스트에 대한 결론을 내리면서 그 이유를 설명할 수 없다면 난센스일 것입니다. 이번 글을 통해 풀어내고자 하는 내용이 바로 그것입니다. 이 시리즈를 통해 어떤 AB 테스트 결과 분석 계산기든 이해할 수 있게 될 것입니다.
좀 멀리 돌아가는 것처럼 보이기도 하지만, AB 테스트의 원리가 뭘까요? 원본과 대안에 각각 10,000명의 고객을 투입하여 2배의 전환율 개선을 이끌어낸 테스트가 있었다고 가정합시다. 이 테스트 결과가 의미하는 바는 제품을 대안으로 개선하면 제품의 전환율이 2배가 된다는 것입니다. 그런데 이게 말이 되나요? 실험에 참여한 고객 10,000명이 2배의 전환율을 보였다고 어떻게 앞으로 제품의 전환율이 2배가 된다고 말할 수 있나요?

위 사실을 증명하는 게 통계학입니다. 미국 성인 1,000명을 조사해 600명이 매일 1잔 이상 커피를 마신다는 조사 결과는 ‘미국 성인 60%가 하루 한 잔 이상 커피를 마신다’라는 결론을 내릴 수 있지만, ‘한국 학생 60%가 하루 한 잔 이상 커피를 마신다’라는 결론은 내릴 수 없습니다. 이는 ‘미국 성인 1,000명’이 ‘미국 성인 전체’를 대표할 만한 유사성이 있다고 판단했기 때문입니다. AB 테스트에서도 마찬가지로, ‘실험에 참여한 고객’이 ‘앞으로 제품을 사용할 고객 전체’를 대표[1]합니다. 통계학에서는 전자를 표본(Sample), 후자를 모집단(Population)이라고 합니다.
이상적인 표본은 모집단을 완벽하게 반영합니다. 그러나 현실은 다릅니다. 미국 성인 60%가 하루 한 잔 이상 커피를 마시지만, 10명짜리 표본을 추출했더니 우연히 전부 카페인에 약해 한잔의 커피도 마시지 않을 수 있습니다. 반대로 다른 표본에서는 전부 커피 애호가일 수도 있습니다. 첫 번째 표본은 0%, 두 번째 표본은 100%가 하루 한 잔 이상 커피를 마십니다. 모집단의 비율과 큰 차이를 보입니다. 그런데 두 표본을 합치면 50%로, 그 전보다 모집단과의 차이가 훨씬 줄어들게 됩니다. 이처럼 표본이 규모를 키우면 점점 모집단을 더 잘 반영하게 됩니다. 다시 말해, 충분히 큰 표본은 어느 정도 모집단을 대표할 수 있습니다.
충분히 큰 표본이 어느 정도 모집단을 대표하는 성질을 이용하면 표본을 가지고 모집단에 대한 어떤 가설이 맞는지 아닌지 추론할 수 있습니다. 이를 통계적 가설 검정(Statistical Hypothesis Testing)[2]라고 합니다. 통계적 가설 검정은 다음 3단계로 진행[3]됩니다.

예시와 함께 그 뜻을 살펴보도록 하겠습니다. 상품 구매 페이지에서 AB 테스트를 하나 진행합니다. 원본 A는 배송비가 별도 표기되고, 대안 B는 배송비가 상품가에 포함되어 배송비는 별도로 표기되지 않습니다. 각 안에 참가한 고객 수는 1,000명이고, 원본 A는 300명이 구매하여 구매율은 30%, 대안 B는 350명이 구매하여 구매율이 35%로 집계되었습니다.
결론부터 이야기하자면 위 예시에서 원본 A와 대안 B 사이 유의미한 차이가 없다고 가정했을 때 대안 B의 구매율 35%가 관측될 확률이 매우 희박하기 때문에, 원본 A와 대안 B는 통계적으로 유의미한 차이를 가지고 있습니다. 왜 그런지 용어 개념부터 하나씩 살펴보죠.

알아내고자 하는 가설을 확인하기 위해 기각되는 용도로 세워지는 가설[4]입니다. 따라서 귀무가설은 항상 알아내고자 하는 가설에 반대편에 있는, 가설 제시 이전의 현상태를 반영합니다. 잘 알려진 비유로 무죄 추정의 원칙과 비슷합니다. 피고인은 결정적 증거로 유죄가 확정되기 전까지 항상 무죄입니다. 언급한 예시에서 귀무가설은 ‘대안 B(별도 배송지 미표시)가 적용돼도 구매율은 30%이다.’ 즉, 대안 B가 효과가 없다고 세울 수 있습니다.
귀무가설에 맞서는 가설로 알아내고자 하는 가설과 방향이 같습니다. 예시에서 대립가설은 ‘대안 B가 적용되면 구매율이 30%가 아니다.’ 즉, 대안 B가 효과가 있는 겁니다. 이때 ‘구매율이 30%가 아니다.’는 ‘구매율이 30%보다 낮다.’ 그리고 ‘구매율이 30%보다 크다.’의 합성입니다. 이를 제1형 대립가설이라고 합니다. 더 낮은 통계치를 알아보려는 경우를 제2형, 더 큰 통계치를 알아보려는 경우는 제3형이라고 합니다.
과정 2를 따라 귀무가설을 참으로 가정합니다. 즉, 대안 B가 적용돼도 구매율은 똑같이 30%입니다. 이 상황에서 실험 결과처럼 구매율이 35%인 경우와 그보다 극단적인 경우가 발생할 확률을 구합니다. 이 상황을 이해하기 쉽도록 표본 분포를 그려볼 수 있습니다. 1,000명이 참가한 실험에 구매율이 30%인 상황은 독립된 1,000번의 시행에서 각 시행의 확률이 30%인 이산 확률 분포, 곧 이항 분포로 나타낼 수 있습니다.
쉽게 생각해보면 1,000명이 실험에 참여해 300명이 구매한 상황이 실험마다 나올 수는 없을 겁니다. 실험을 반복할 때마다 구매 고객 수는 290, 310, 심하면 그보다 더 극단적인 값이 나오면서 구매율도 29%, 31%, 더 크고 작은 구매율이 집계될 것입니다. 다만 이러한 반복 실험 결과의 평균 구매율은 30%로 분포도는 30%에서 멀어질수록 줄어드는 형상일 것입니다.
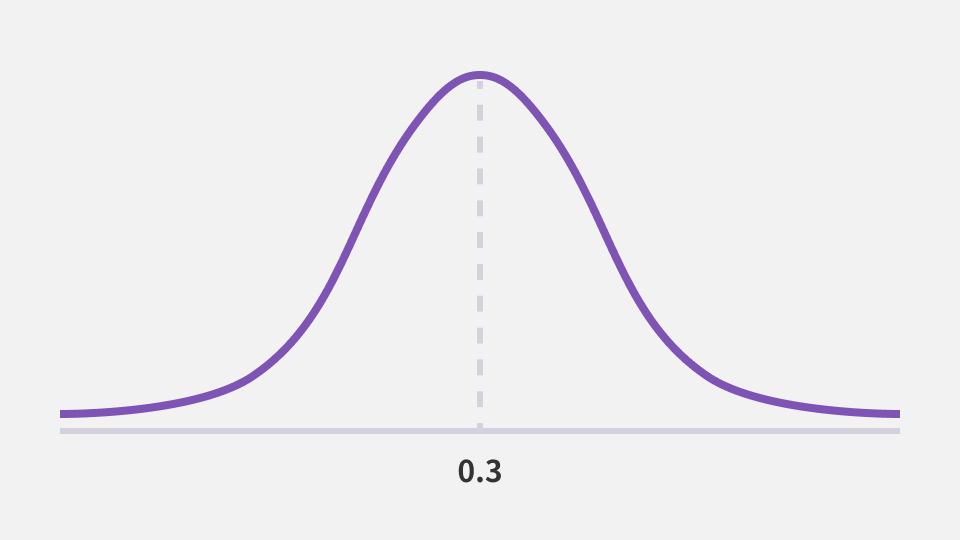
시행 확률이 30%에 가까워질수록 예상 가능한 시행 횟수가 늘어나고 멀어질수록 예상 가능한 시행 횟수가 줄어듭니다. 이제 이 표본 분포에서 구매율이 35%이거나 그보다 더 극단적인 경우의 확률을 찾아야 합니다. 이 과정은 2단계로 나눠집니다.
2-1. 30%에서 35%까지 얼마만큼의 표준오차가 있는지(Z 점수) 계산
2-2. 과정 2-1의 계산을 이용, 35%와 같거나 그보다 극단적인 결과가 관측될 확률 계산
몇 가지 새로운 용어가 보입니다. 이를 설명하면서 계속하겠습니다.
앞서 설명했듯 같은 실험을 반복하더라도 매번 30%의 구매율이 나오지는 않으며 반복 실험 결과의 평균이 30%일뿐입니다. 어떤 실험에서 28%의 구매율이 나왔다면, 평균과의 편차가 -2%라고 말할 수 있습니다. 표준오차는 어떤 실험에서 나온 구매율과 평균 사이의 편차를 전부 모았을 때 이들의 평균입니다. 즉, 평균적인 편차가 어느 정도인가를 알려주는 값입니다. 표준오차를 계산하는 식은 다음과 같습니다.
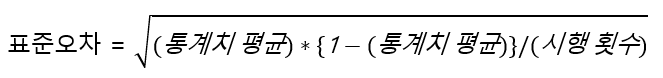
예시의 원본 A의 표준 오차를 계산하면
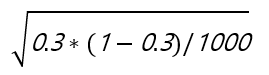
이므로 0.0145(소수점 다섯째 자리에서 반올림) 정도가 됩니다. 같은 식으로 대안 B의 표준오차는 0.0151입니다. 위의 과정 1에서 필요한 표준 오차는 두 표본의 평균 차이의 표준오차입니다. 두 표본의 평균 차이의 분산은 각 평균 분산을 합한 값이므로,
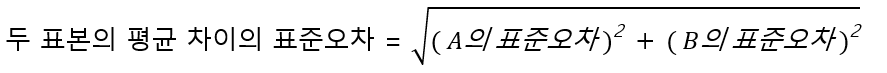
원본 A와 대안 B 평균 시행 확률 차이의 표준오차는 0.0209입니다.
Z 점수는 정규분포에서 특정 통계치가 표본의 평균에서 얼마의 표준편차만큼 떨어져 있는지 나타낸 값[5]입니다.

과정 1을 위 식에 그대로 대입합니다. 표준편차 대신 원본 A와 대안 B 평균 차이의 표준오차를 사용합니다.
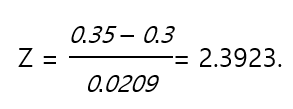
다시 말해 대안 B의 평균 35%는 원본 A의 평균 30%에서 두 평균 차이의 표준오차의 2.3923배 떨어져 있습니다.
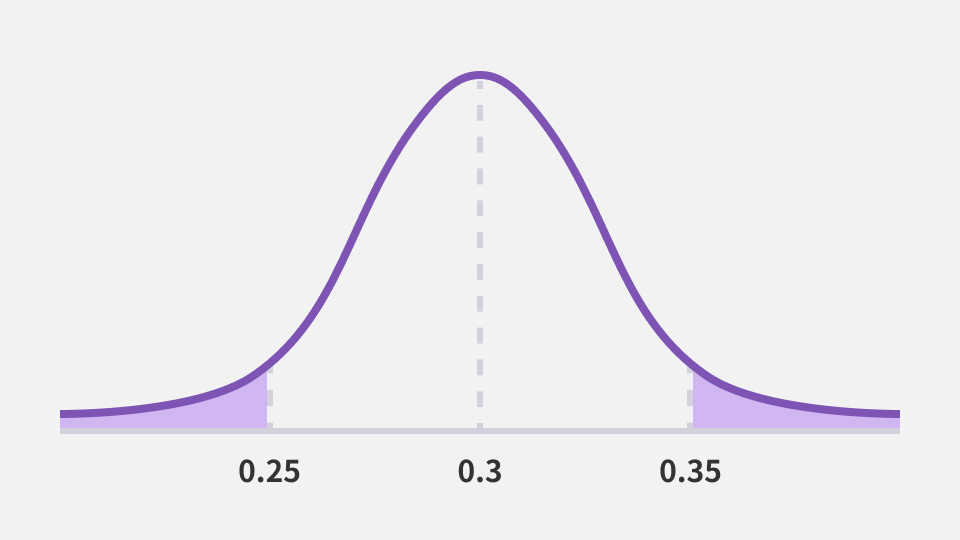
이로써 귀무가설이 참일 때 35%와 같거나 그보다 극단적인 결과가 관측될 영역을 특정했습니다. 이 영역의 넓이가 곧 해당 결과가 관측될 확률입니다. 대략적인 값을 Z Table, 표준정규분포표[6]에서 확인할 수 있습니다.
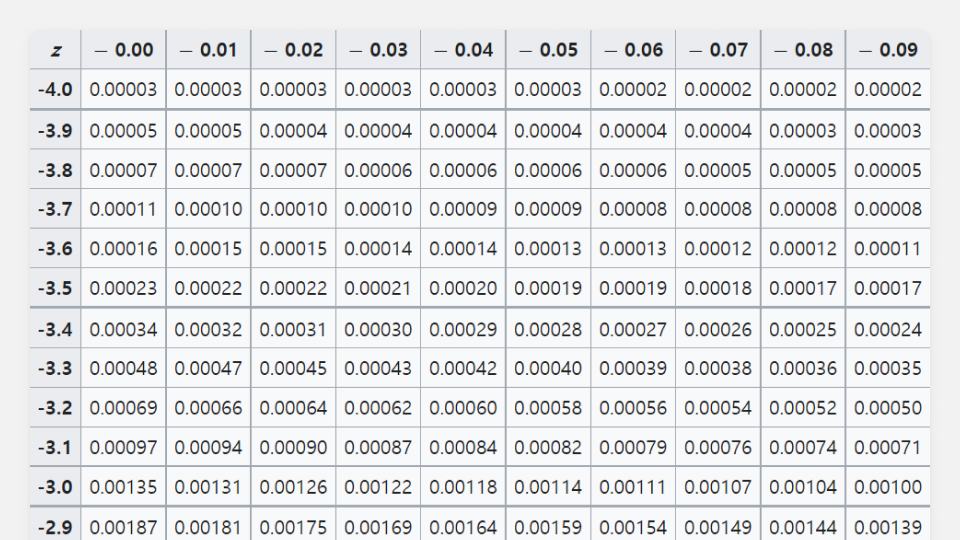
Z = 2.39에서 누적 분포 함숫값은 0.99158이므로 귀무가설이 참일 때 35%와 같거나 그보다 극단적인 결과가 관측될 확률은 0.00842, 즉 0.842%입니다. 이 확률이 바로 p값(Probability Value)입니다.
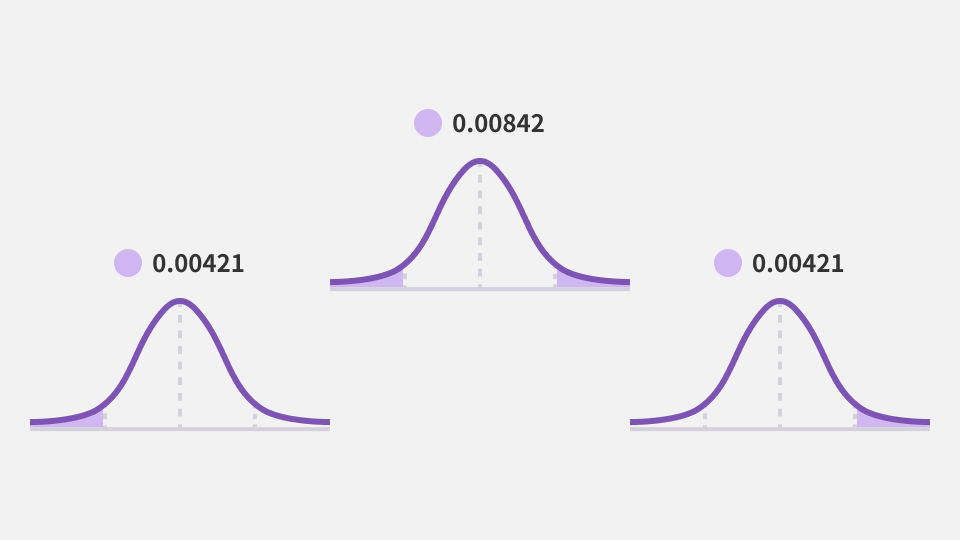
0.842%의 p값은 제1형 대립가설을 검정하는 양측 검정(Two-sided Test)입니다. 평균 시행 확률이 30%인 표본에서 최소 35%만큼 극단적인 결과가 관측될 확률로, 30%에서 음의 방향으로 35%만큼 극단적인 25% 이하의 값이 나타날 확률도 포함합니다. 실제로 업무에 활용한다고 생각했을 때 전환율이 저하됐을 경우의 확률까지 포함해서 검정할 필요성은 없을 듯합니다. 그러므로 대립가설을 제3형 가설, ‘대안 B가 적용되면 구매율이 30%보다 크다.’로 수정합니다. 이렇게 수정된 대립가설을 검정하는 것을 단측 검정(One-sided Test) 중 우측 검정(Upper Tailed Test)이라고 합니다.[7] 이때 p값은 양측 검정 때의 절반, 0.421%가 됩니다.
이제 이 확률, p값이 귀무가설을 기각할 만큼 낮은 건지 아닌지 기준을 잡아 알아보아야 합니다. 이 기준이 유의 수준입니다.
유의 수준은 특정 통계치가 특정 범위 안에 있는 비율입니다. 유의 수준보다 p값이 낮다면 귀무가설을 참으로 가정했을 때 극단적 통계치가 관측될 확률이 충분히 낮다고 판단하여, 귀무가설을 기각하고 대립가설을 채택합니다. 유의 수준의 값은 관습적으로 1%, 10%, 특히 5%가 자주 사용되나 의료계에서는 0.1% 수준으로 검정 기준의 허들을 더 높여야 한다는 주장도 제기된 바[8] 있습니다. 그러나 이는 정도의 차이이므로 AB 테스트를 진행하는 조직 구성원끼리 합의를 통해 결정하면 될 일입니다. 35% 구매율이 우연히 관측될 확률이 0.421%라는데, 깐깐하게 보는 것도 좋지만 비즈니스의 필요에 따라 유연하게 채택할 필요가 있습니다.
유사한 지표로 신뢰구간이 있습니다. 단순히 1에서 유의 수준 값을 빼면 됩니다. 유의 수준이 5% 일 때 신뢰구간은 95%입니다. 만약 누군가 이러한 과정을 통해 ‘이 실험의 결과는 95% 신뢰구간에서 유효하다.’고 한다면, 실험 결과가 95%만큼 믿을 만하다는 뜻이 아니라 결과가 유효하지 않았다면 해당 실험 결과가 나올 확률이 5% 이하라는 뜻입니다. 그만큼 실험 결과가 유효하지 않을 가능성이 희박하다는 것입니다.
이상의 과정처럼 통계적 가설을 검정하는 접근법을 빈도주의 통계(Frequentist Statistics) 방식이라고 말합니다. 이는 알려지지 않은 모집단의 통계치를 추정하기 위해 여러 표본의 값을 비교·분석하는 방식입니다.
여기까지 이해하고 계산기를 켠다면 달리 보이는 부분이 많을 겁니다. AB 테스트 결과 통계적 가설 검정 과정을 다시 한번 짚어보겠습니다.
AB 테스트는 ‘앞으로 제품을 사용할 고객’이라는 모집단을 대표하는 표본인 ‘실험 참여 고객’을 통해 전환율을 개선합니다. 빈도주의 통계적 가설 검정은 귀무가설, 대립가설, 유의 수준을 설정해 귀무가설이 참인 상황에서, 표본에서 관측된 통계치와 같거나 더 극단적인 값이 관측될 확률인 p값을 계산합니다. 이 확률이 유의 수준 이하라면 귀무가설 기각하고 대립가설을 채택합니다.
이제 AB 테스트 결과 분석 계산기에 나타난 여러 수치가 무얼 뜻하는지 알게 되었습니다.
그런데 최근에는 빈도주의 통계로 접근한 계산기가 아니라 다른 방식으로 결과를 분석하는 계산기도 종종 보입니다. 베이지안 통계(Bayesian Statistics) 방식의 계산기가 그것입니다. 베이지안 통계는 빈도주의적 통계의 라이벌이라고 할 수 있는 접근법입니다.
다음 편에서는 베이지안 통계 방식의 AB 테스트 결과 분석과, 빈도주의 통계가 갖는 한계를 베이지안 통계 방식이 어떻게 해결하는지 알아보겠습니다.
[1] Jacob McMillen, 2016 - A/B Testing Statistics: An Intuitive Guide For Non-Mathematicians
[2] Wikipedia - Statistical hypothesis testing
[3] Khan Academy, 2010 - Hypothesis testing and p-values | Inferential statistics | Probability and Statistics
[4] Wikipedia - Null Hypothesis
[5] David Kindness(Investopedia), 2021 - Z-Score
[6] Wikipedia - Standard normal table
[7] Khan Academy, 2010 - One-tailed and two-tailed tests | Inferential statistics | Probability and Statistics
[8] Andrew N. Philips, George Davey Smith, 1993 - The design of prospective epidemiological studies: More subjects or better measurements?
©️요즘IT의 모든 콘텐츠는 저작권법의 보호를 받는 바, 무단 전재와 복사, 배포 등을 금합니다.