개발
합법적으로 ‘웹 크롤링’하는 방법 (下)

6분
2021.07.20.22.0K

앞선 합법적으로 ‘웹 크롤링’하는 방법 상편에서는 웹 크롤링이 무엇인지, 어떤 경우에 웹 크롤링 행위가 문제가 되는지에 대해 파악해 보았습니다. 하지만 웹 사이트마다 성격이 다르고, 정책이 달라 특정한 몇 개의 기준만으로 웹 크롤링의 위법 여부를 판단하기에는 무리가 있습니다. 그래서 데이터를 수집할 때 수집 대상이 되는 웹 사이트의 정책을 정확히 파악하는 것은 생각보다 중요한 사전 작업입니다. 이번 시간에는 웹 사이트 별 각기 다른 정책을 고려하면서 합법적인 웹 크롤링을 진행할 수 있는 조금 더 고도화된 방법에 대해 이야기하겠습니다.

기본적으로 모든 웹 사이트들은 자동화 프로그램에 대한 규제 여부를 명시해놓고 있습니다. 해당 내용에는 웹 크롤링을 통해 수집한 데이터의 상업적 이용, 서버 부하 등 일반적인 금지 사항이 아니라 각 웹 사이트 별 특성을 반영한 규제 여부를 알려줍니다. 예를 들어, 돈을 지불해야만 특정 페이지에 접속할 수 있는 경우 해당 페이지는 그 자체로 자동화 프로그램이 접속하는 것을 막아야 합니다. 반면, 공익적 목적을 위해 모든 자료와 데이터를 활발히 공유할 목적으로 특성 웹 사이트가 구성되어 있다면 자동화 프로그램의 접속을 굳이 막을 필요가 없습니다. 이렇듯 웹 사이트의 특성과 상황을 고려하면 너무나 많은 경우의 수를 생각할 수 있기 때문에 각 웹 사이트 별로 자동화 프로그램에 대한 규제를 명확히 표시해둡니다.
여기서 말하는 자동화 프로그램에 대한 규제는 비단 웹 크롤링에만 한정되는 이야기가 아닙니다. 꼭 웹 크롤링을 통해서 데이터 수집을 하는 것이 아니더라도, 자동화 프로그램을 이용해서 접근하는 것 자체에 대한 허용을 이야기하는 것입니다. 그래서 웹 사이트 별 자동화 프로그램에 대한 규제 내용은 웹 크롤링을 포함하여 프로그래밍을 통해 특정한 자동화 프로그램을 만들었을 때, 이 프로그램을 웹 사이트에 적용해도 되는지 아닌지에 대한 여부를 알려주는 하나의 지표 역할을 합니다.
각각의 웹 사이트 별로 자동화 프로그램에 대한 규제 내용을 확인하는 방법은 간단합니다. 각 웹 사이트는 robots.txt라는 텍스트 파일로 해당 정보를 저장하며 명시하고 있습니다. robots.txt는 브라우저 화면에서 바로 열어볼 수도 있으며 파일로 다운로드해 익숙한 메모장 프로그램을 이용하여 열어볼 수도 있습니다. robots.txt에 접근하는 방식도 매우 간단합니다. 모든 웹 사이트는 URL이라는 고유 주소를 가지고 있습니다.
흔히 알고 있는 ‘www.’으로 시작하여 ‘.com’ 혹은 ‘.co.kr’로 끝나는 형태의 문자의 조합입니다. robots.txt에 접근하기 위해서는 접근하고자 하는 웹 사이트 URL 뒤에 ‘/robots.txt’를 덧붙여 작성하고 접속을 시도해보면 됩니다. 이때, robots.txt라는 글자의 대소문자도 구분해서 인식하므로 이를 조심하여 작성해야 합니다. 웹 크롤링을 하고 싶은 웹 사이트의 URL 뒤에 robots.txt를 덧붙인 이후 접속을 시도하면 txt 파일이 자동으로 내려받아지거나 바로 robots.txt 정보가 브라우저 상에 노출되게 됩니다.

위시켓 요즘IT의 robots.txt 확인 장면
위 이미지는 위시켓의 요즘IT 웹 사이트의 robots.txt를 확인해 본 장면입니다. 해당 이미지를 보면 알 수 있듯, robots.txt는 자동화 프로그램 접속 제한 여부를 세세하게 알려줍니다. 다만 robots.txt의 내용이 우리가 무조건 지켜야 하는 법적 효력이 있는 내용은 아닙니다. 각 웹 사이트에서 자동화 프로그램은 접근을 하지 마라 혹은 접근을 해도 괜찮다는 권고안 정도의 의미를 담고 있습니다. 하지만 아무리 robots.txt에 담긴 내용에 강제성이 없다고 할지라도 이를 무시하고, 웹 크롤링을 실시하는 것은 절대 추천하지 않습니다. 웹 사이트 별로 특정 페이지마다 웹 크롤링의 접근 허용 여부를 기록해 놓은 것은 해당 서버와 데이터를 안전하게 보호하기 위한 목적이 있기 때문입니다. 혹여 추후 웹 크롤링 때문에 문제가 생긴다 할지라도 그 대부분의 경우는 robots.txt에 명시적으로 자동화 프로그램의 접근을 제한한다고 표시되어 있는 경우가 많습니다.

다만 robots.txt를 통해 명시적으로 자동화 프로그램에 대한 규제 여부를 표시해둔다고 해도 웹 크롤링을 처음 시도해보거나, 웹 사이트 구조에 대해 이해도가 떨어지는 상황이라면 이를 이해하기 힘들 수 있습니다. 그렇기 때문에 몇몇 개의 웹 사이트에서 /robots.txt를 뒤에 덧붙여 이를 해석하는 연습을 해보는 것이 좋습니다. 실제로 robots.txt에 담겨 있는 내용은 모든 웹 사이트마다 그 형식과 구조가 똑같습니다. 또한 해당 내용은 어려운 코드로 구성된 것이 아니라 직관적으로 이해하기 쉬운 몇몇 개의 단어로 이루어져 있기에 조금만 robots.txt 내용 해석을 시도하다 보면 웹 크롤링 입문자도 쉽게 자동화 프로그램 규제 여부를 파악할 수 있습니다.
아래 이미지는 포털 사이트 네이버의 robots.txt 열람 화면입니다. 이 내용의 경우 ‘User-agent: *’이라는 문구로 시작을 하고 있습니다. 네이버를 포함해 모든 robots.txt 정보는 User-agent 정보를 알려줌으로써 시작합니다. User-agent는 robots-txt에 명시한 정책들을 지켜야 하는 주체에 대해 서술하는 부분입니다. 네이버의 경우 *이라는 존재가 해당 정책들을 지켜야 한다고 말하고 있습니다. 일반적으로 프로그래밍 언어에서 *은 전체를 의미하는 경우가 많습니다. 이를 감안해 해석해보면, 예외 없이 모든 유저는 아래의 robots.txt 정책을 따를 것을 권고한다는 의미입니다. 그리고 그 뒤에는 Disallow와 Allow로 나누어 robots.txt 내용이 서술되어 있습니다. 영어 단어 그대로 Disallow는 자동화 프로그램의 접근이 허용되지 않는 부분이고 Allow는 허용되는 부분입니다. /는 모든 페이지, /$는 첫 페이지를 의미합니다. 종합해보면 네이버는 첫 접속 페이지를 제외하고 모든 페이지에서의 웹 크롤링 접근을 제한하고 있습니다. / 이라는 표시에 대해서 더욱 자세히 살펴보도록 하겠습니다.

네이버의 robots.txt 확인 장면 (https://www.naver.com/robots.txt)
네이버의 경우 매우 간단한 robots.txt 구조를 보여주고 있지만 보통은 / 표시를 통해 각 페이지 별 세부 내용을 표시해 줍니다. / 뒤에 페이지 명을 써주고 각각에 Allow 혹은 Disallow 표시를 해주는 것이 보통입니다. 우리가 인터넷 URL 주소를 입력할 때, /을 단위로 상세 페이지로 구분된다는 점을 생각하면 이해가 쉽습니다. 아래 이미지는 전 세계 최대 포털 사이트 구글의 robots.txt 적용 결과입니다. User-agent를 제외한 첫 줄을 보면 검색 페이지의 웹 크롤링 접근을 금지하고 있는 것을 알 수 있습니다. 하지만 검색 페이지 전체의 웹 크롤링을 금지하고 있지는 않습니다. 이후 세 줄에서 Allow 단어와 / 표시를 통해 about, static, howsearchworks라는 상세 페이지는 비록 검색 페이지 내에 속해있는 정보이지만 자동화 프로그램이 접근해도 괜찮다고 명시하고 있습니다.
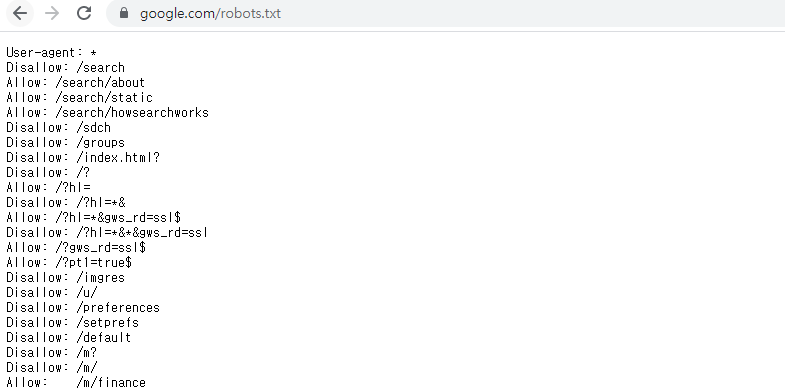
구글의 robots.txt 확인 장면 (https://www.google.com/robots.txt)
이렇듯 robots.txt를 이용한다면 같은 웹 사이트일지라도 상세 페이지 별 자동화 프로그램의 허용 여부를 쉽게 알아낼 수 있습니다. 데이터를 수집해야 하는 사람의 입장에서 작업해야 하는 것은 간단합니다. 본인이 웹 크롤링을 진행하고자 하는 웹 사이트의 URL을 알아낸 뒤 그 URL이 robots.txt의 상세 페이지 설명 중 어느 곳에 해당하는지를 파악하고, 그 앞의 단어가 Allow인지 Disallow인지만 바라보면 됩니다.

앞선 상편과 이번 편에서는 정당한 방법으로 웹 크롤링을 하는 방법에 대해 알아보았습니다. 사실 곰곰이 생각해 보면 웹 크롤링을 위해 대답을 준비해야 하는 질문은 꽤 많습니다. 내가 웹 크롤링을 통해 데이터를 수집하여 활용하려는 것이 어떤 목적인지 정확히 말할 수 있는가? 나의 웹 크롤러가 상대 서버에 부하를 주지는 않을까? 내가 웹 크롤링을 시도하려는 웹 사이트는 웹 크롤링을 제한하고 있는가?에 대해 모두 답을 하는 것은 다소 귀찮은 일이 될 수 있습니다.
하지만 이런 어려움을 감안할 만큼 웹 크롤링은 가장 좋은 데이터 공급원 중 하나로 뽑히고 있습니다. 사실상 내가 원하는 내용의 데이터를 원하는 수량만큼 무료로 수집할 수 있는 거의 유일한 수단입니다. 특히 빅데이터 분야를 이제 막 공부하기 시작하는 학생들은 더욱이 최고의 데이터 공급원으로 웹 크롤링을 이용할 수 있습니다. 그러니 법적, 윤리적 이슈를 최소화하여 활발히 데이터를 수집하고 분석하는 문화가 형성되기 바랍니다.
©️요즘IT의 모든 콘텐츠는 저작권법의 보호를 받는 바, 무단 전재와 복사, 배포 등을 금합니다.