개발
아�니 이 글자 왜 들어간 거예요? (1)

8분
2024.11.08.인기
23.7K
*FEConf2024에서 발표한 <아�니 이 글자 왜 들어간 거예요? (부제: 알아두면 가끔 쓸모 있는 한글 유니코드 완전 정복)>를 정리한 글입니다. 발표 내용을 2회로 나누어 발행합니다. 1회에서는 유니코드에 대해 알아보고, 유니코드에서의 한글에 대해 알아보겠습니다. 2회에서는 물음표 특수문자가 왜 생겨나는지, 이를 어떻게 해결하는지에 대해 알아봅니다. 본문에 삽입된 이미지의 출처는 모두 이 콘텐츠와 같은 제목의 발표 자료로, 따로 출처를 표기하지 않았습니다.
‘아�니 이 글자 왜 들어간 거예요? (부제: 알아두면 가끔 쓸모 있는 한글 유니코드 완전 정복)’
제한재 데니어 CTO
안녕하세요. 저는 ‘아�니 이 글자 왜 들어간 거예요?’라는 제목의 발표를 진행할 제한재입니다. 네이버 오피스에서 워드와 슬라이드 제품을 만들었고, 현재는 치과의사 커뮤니티를 운영하는 데니어에서 CTO로 의료인들을 위한 플랫폼을 만들고 있습니다.
이번에는 여러분들이 언젠가 한 번쯤은 만날 이 문제를 쉽게 해결하고, 기술 면접에서 발표하게 되었을 때 아주 뛰어난 답변을 할 수 있게 알찬 내용으로 구성했습니다. 잘 활용하시길 바랍니다.
이번 글에서 다루는 것들은 아래와 같습니다.
이번 발표는 아래 사진에서 시작되었습니다. 같이 한번 볼까요? 함께 일하던 매니저님이 이렇게 슬랙 메시지를 보냈습니다.

“텍스트 에디터를 통해 글을 작성하는 도중에 긴 글을 작성하면 이상한 물음표 글자가 자꾸 생겨요.”
“이 글자를 지우기 위해 글을 수정하고 다시 업로드를 하면 또 다른 곳에 나타나요. 꼭 두더지 같아요!”
이 메시지를 보낸 매니저님은 이런 현상을 보고 ‘유니코드 지옥’이라고 표현했습니다. 위 이미지의 오른쪽 아래가 실제로 매니저님이 겪은 깨진 텍스트의 모습입니다. 이제 이 물음표가 왜 등장하는지 알아보고, 이 문제를 해결하기 위한 여정을 함께 해보겠습니다.
먼저 유니코드에 대해 알아보겠습니다. 유니코드는 ISO 10646이라는 표준입니다. 다시 말해 유니코드란 전 세계에 있는 모든 문자를 표현하는 일관된 표준이자 동시에 이러한 문자들을 관리하는 기구를 말합니다. 이 유니코드 안에는 몇 가지 큰 덩어리가 나뉘어 있습니다.

첫 번째 영역은 BMP 영역이라고 합니다. 이 영역에는 기본 언어 평면이라고 부르는 텍스트 셋이 있습니다. 이 텍스트 셋에서는 U+0000~U+FFFF라는 표현을 사용합니다. 이는 유니코드를 쓸 때 많이 쓰는 표현 방법입니다. U+뒤에 나오는 16진수 숫자들이 보통 유니코드에서 말하는 숫자를 의미합니다. 숫자로만 표현하면 의미가 헷갈리기 때문에 U+를 관습적으로 붙인다고 이해하면 될 것 같습니다.
두 번째 영역인 SMP 영역은 보충 언어 평면이라고 합니다. 이 영역에는 여러분들이 사용하는 이모지나 기호들이 포함됩니다. 마지막으로 세 번째 영역은 표의 문자 평면이라고 하고 주로 한자와 같은 문자들이 여기에 포함됩니다.

위 그림은 첫 번째 영역인 기본 언어 평면입니다. 그림처럼 기본 언어 평면에는 들어있는 글자들이 정말 많습니다. 한 칸에는 256자 정도의 텍스트가 들어갈 수 있습니다. 00부터 02까지는 로마자가 들어가 있고, 로마자를 넘어 파란색의 유럽 문자 등을 지나, 34번부터는 CJK 문자도 볼 수 있습니다. CJK는 Chinese, Japanese, Korean의 약자로 세 나라에서 쓰는 한자가 포함된 칸입니다. 우리가 쓰는 문자는 동아시아 문자 영역에 들어가 있고, 빨간색으로 표시되어 있습니다. 빨간색으로 표시된 동아시아 문자는 11번, 30번, 31번에 들어가 있고, A0부터 D7에도 들어가 있습니다.
이 BMP 영역은 U+0000부터 U+FFFF까지 총 4개의 16진법 숫자가 들어갔기 때문에 2byte 표현 범위이며, 총 65,536자의 문자가 들어가 있습니다. 유니코드에서는 전 세계 대부분의 문자가 이 65,000여 개 범위에 포함된다고 설명하고 있습니다.
그럼 우리가 표현하는 한글은 정확히 어디부터 포함되어 있을까요? 앞서 말한 것처럼 동아시아 문자열에 포함되어 있는데, 그중 AC로 시작하는 부분부터 포함되어 있습니다. 아래 그림은 유니코드 안에 있는 한글 목록의 일부입니다.

‘가’부터 시작해서 ‘힣’ 까지 표현하는 ‘U+AC00’부터 ‘U+D7A3’까지 영역에 우리가 사용하는 한글이 포함되어 있습니다. 여러분들이 한글인지 판별하기 위해 쓰는 정규 표현식을 사용할 때 ‘가’부터 ‘힣'까지로 쓰는 그 영역이라고 생각하면 됩니다. 이렇게 표현한 것이 바로 유니코드에서 정의하는 한글입니다.
그럼 이 영역에 한글이 몇 글자나 들어가 있을까요? 먼저 초성 19자, 중성 21자, 종성 27자에 비어 있는 종성 1자까지 포함하고, 19 X 21 X 28을 하면 11,172자가 됩니다. 이 11,172자를 다 표현하느냐에 따라 완성된 한글인지 부분적으로 빠져있는 한글인지 판별할 수 있습니다.
그리고 여기에 포함되지 않은 한글도 있습니다. 아래 그림과 같이 ‘아래 아’를 포함한 옛한글, 초성이 없는 글자, 중성이 없는 글자 등은 유니코드에 포함되어 있지 않습니다.

한글 정렬 기준에 대해서도 알아보겠습니다. ‘가나다라마바사’부터 ‘아자차카타파하’까지, 이 정렬 순서가 정해진지는 그렇게 오래되지 않았습니다. 쌍자음이 어디에 들어갈지, 겹 모음이 어디에 들어갈지 등에 대한 논의를 바탕으로 한글을 전산화하던 1988년 문교부 고시를 통해 확정이 되었습니다. 당시 확정한 고시를 바탕으로 유니코드에도 그 순서가 반영되었습니다.
몇 가지 연구를 더 찾아보니 이 순서에 대한 제시가 몇 차례 있었고, 80년대 이전에는 쌍자음이 뒤에 있는 등의 다른 순서를 가진 사전들이 종종 있었습니다. 이처럼 다양한 논의로 정해진 순서가 KS X 1026-1이라는 표준에 기록되어 있습니다.

그럼 여기서 잠깐 북한의 한글은 어떤지 살펴볼까요? 북한에서 사용하는 정렬은 우리와 조금 다릅니다. 아래 그림처럼 쌍자음이 뒤에 오고, 모음 ‘ㅇ’도 맨 마지막에 위치해 있습니다. 따라서 북한에 있는 개발자들이 한글을 표현하고 개발에 사용할 때는 유니코드 순서와 일치하지 않는 구현을 직접 해야 합니다.
1999년에 북한이 아래 그림처럼 교정할 것을 제안했지만, 유니코드 위원회에서는 이를 받아들이지 않았습니다. 이미 88년도에 한국에서 한글에 대한 정렬을 등록했기 때문입니다.

그럼 유니코드에서 한글은 얼마나 큰 비중을 차지할까요? 앞서 설명한 BMP 영역의 66,536자 중에 11,172자, 무려 6분의 1을 차지하고 있습니다. 그래서 유니코드에서도 이렇게 많은 글자를 모두 받아줄 것인지 대한 논의도 있었다고 합니다. 그 결과, 논의를 거쳐 일부 빠진 글자도 존재했습니다.
그 때문에 유니코드 1.0 스펙에는 지금보다 적은 한글이 기록되었습니다. 1996년에 나온 유니코드 2.0 스펙이 돼서야 11,172자의 모든 한글이 기록되었습니다.
조금 다른 한글 표현이 또 있습니다. 바로 조합형 유니코드인 Hangul Jamo입니다. 이 표현은 초성, 중성, 종성을 조합해서 표시할 수 있습니다.

‘첫가끝’ 이라고도 부르는 이 표현 방법으로 제 이름의 ‘한'을 만들려면 ‘ㅎ’, ‘ㅏ’, ‘ㄴ’을 조합해 표현할 수 있습니다. 이런 조합으로 11,172자의 한글은 물론이고, 옛한글 글자도 하나의 글자로 표현할 수 있습니다. (물론 옛한글을 모두 구현하려면 이런 것을 완벽하게 지원하는 폰트를 찾아야 합니다.)
아래 그림은 조합형 텍스트의 예외 사례를 보여줍니다. ‘t’라는 변수에 ‘한재는 발표중!’이라는 값을 저장했습니다. 이 변수에 substring을 활용해 2개의 글자만 가져올 때, 우리는 ‘한재’라는 글자가 나오기를 기대할 것입니다. 그러나 실제론 ‘하’라는 글자가 표현됐습니다.

자바스크립트에서는 유니코드의 조합형 텍스트 구성 방법을 통해 초성, 중성, 종성 순으로 나란히 나열해서 표현합니다. 이 나열에서 2번째 글자까지 가져왔기 때문에 ‘하’라는 글자가 표현된 것입니다.
이런 조합형 텍스트인 첫가끝 유니코드는 우리 주변에서 종종 볼 수 있는데, 맥에서 생성한 파일을 예로 들 수 있습니다.

맥에서 작성한 한글 파일을 윈도우에서 열면 이렇게 보입니다. 그림의 파일명을 모아서 읽어보면 ‘개발자_매뉴얼’입니다. 맥 OS에서는 첫가끝 유니코드를 지원하고 저장할 때도 이 텍스트 방식으로 저장하지만, 윈도우 OS에서는 이를 지원하지 않습니다. 그래서 하나의 글자로 인식하지 못하고 하나하나 쪼개져 표현되는 것입니다.
그러면 브라우저에서는 첫가끝 유니코드를 잘 지원할까요? 다행히도 대부분의 현대 브라우저에서는 이를 잘 지원하고 있습니다. 하지만 이로 인해 생기는 문제가 있습니다. 브라우저에서는 잘 표현되던 한글이 윈도우 OS에 다운로드하여 확인하면 깨져있는 경우입니다.
첫가끝 유니코드의 특성을 보면, 그림과 같이 초성에 오는 글자와 종성에 오는 글자가 같더라도 실제로는 다른 글자로 취급합니다.

물론 우리가 흔히 사용하는 키보드에서는 초성과 종성을 분리해서 입력할 수는 없습니다. 대신 초성과 종성을 분리해서 입력할 수 있는 키보드가 있습니다. 바로 세벌식 키보드입니다. 아래 그림처럼 세벌식 키보드에서는 초성, 중성, 종성을 나눠서 입력할 수가 있습니다.
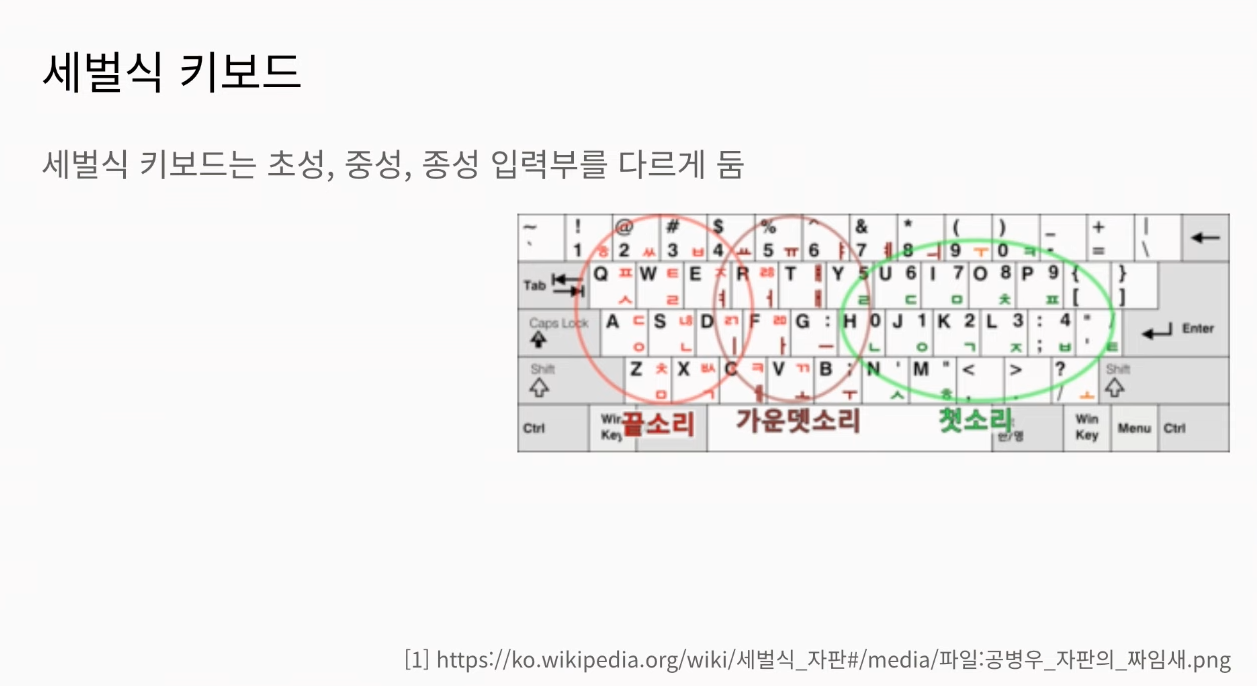
간혹 주변에서 세벌식 키보드가 좋다고 말하는 분을 볼 수 있습니다. 이런 분들은 빠른 타이핑을 위해 세벌식 키보드를 사용한다고 합니다.
우리가 흔히 쓰는 두벌식 키보드를 사용하다 보면 종종 아래와 같은 오타가 발생하곤 합니다. ‘옷이 없어요’라는 글자를 적으려 했는데, 급하게 입력하다 보니 ‘옷이 ㅇ벗어요’로 입력되는 것입니다. 두벌식 키보드는 초성과 종성에 대한 구분이 없기 때문에, 사용자가 글자를 입력하는 시간에 따라 초성인지 종성인지를 구분합니다. 그래서 이런 오타가 발생하는 것입니다.
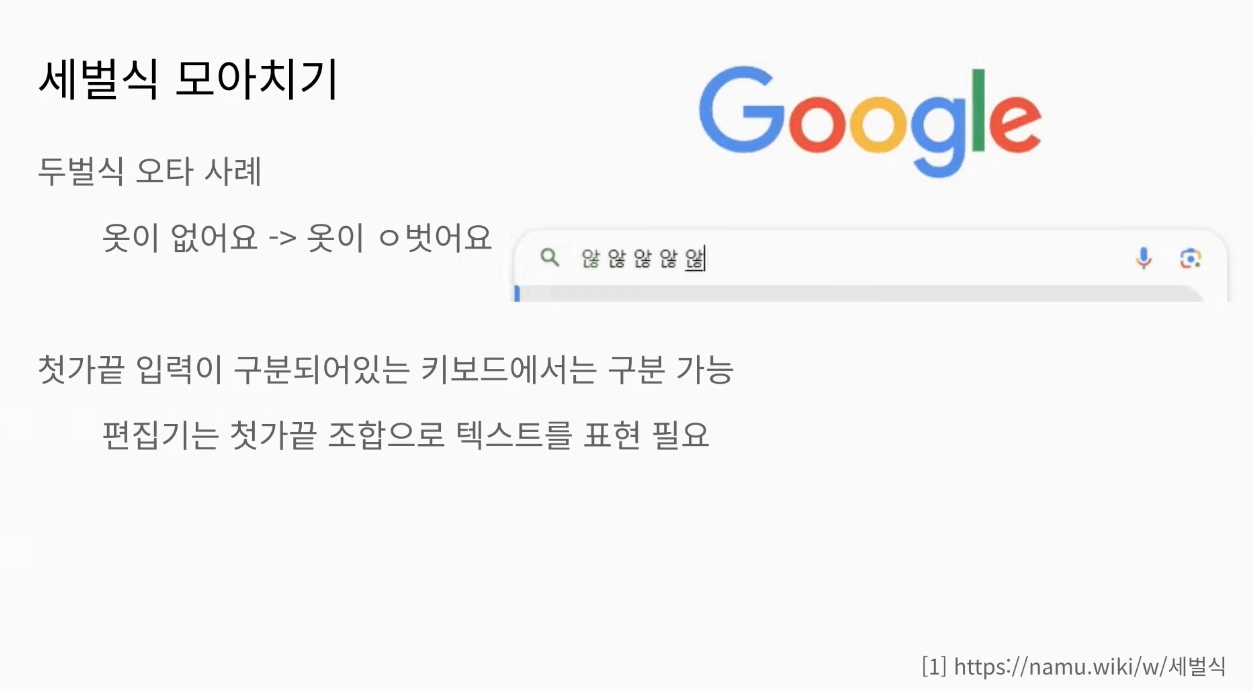
우리 눈에는 같은 글자로 보이더라도, 세벌식 키보드에서는 초성과 종성을 다른 글자로 취급합니다. 그렇기 때문에 생기는 독특한 장점이자 기법도 있습니다. 바로 세벌식 모아치기입니다. ‘않’이라는 글자를 입력할 때, 세벌식 키보드는 초성과 종성의 차이를 알고 있기 때문에 ‘ㅏ’ → ‘ㄴ’ → ‘ㅎ’ → ‘ㅇ’ 순서로 입력해도 글자를 완성할 수 있습니다. 즉, 종성을 먼저 입력하든, 끝소리를 먼저 입력하든 문제없이 글자를 표현할 수 있습니다.
물론 지금까지 설명한 첫가끝은 이해하기도 쉽지 않으며, 어떻게 결합하고 사용해야 할지는 더 어려운 게 사실입니다. 이런 어려움을 해소하기 위해 유니코드에서 소개하는 결합 방법이 있습니다. 바로 NFC(Normalization Form Canonical Composition, 정준 결합)와 NFD(Normalization Form Canonical Decomposition, 정준 분해)입니다.
정준의 사전적 뜻은 ‘바른 틀’입니다. 유니코드에서는 정준 결합과 정준 분해를 소개하며, “이 규칙을 통해 올바르게 결합하고 분해하여 사용하라”고 말합니다.

위 예제의 ‘(ㄱ)’은 정준 분해를 통해 ‘(’, ‘ㄱ’, ‘)’ 세 개의 문자로 분해할 수 있습니다. 이는 다시 반대로 정준 결합을 통해 ‘(ㄱ)’ 한 글자로 결합할 수 있습니다. 마찬가지로 ‘한’이라는 글자도 정준 결합과 정준 분해를 통해 분해와 결합이 가능합니다.
위 규칙은 자바스크립트의 String, normalize 프로토타입에 정의되어 있으니 링크를 확인하여 보시면 좋을 것 같습니다.
마지막으로 알아볼 것은 한글 호환 자모입니다. 이번 글에서 등장하는 세 번째 한글입니다.
한글 호환 자모는 우리가 흔히 쓰는 두벌식 키보드에서 사용하는 한글입니다. 첫가끝 표기와의 차이점은 초성과 종성의 차이가 없다는 점입니다. 여러분들이 두벌식 키보드를 사용하여 ‘ㄱ’을 입력하면 ‘한글 호환 자모의 313번에 있다’라고 할 수 있습니다.

지금까지 유니코드, 또 유니코드에서의 한글에 대해 알아봤습니다.
여태 알아본 내용을 바탕으로 다음 글에서는 서두에서 말한 물음표가 왜 등장하는지, 이 문제를 해결하기 위한 방법을 알아보겠습니다.
©️요즘IT의 모든 콘텐츠는 저작권법의 보호를 받는 바, 무단 전재와 복사, 배포 등을 금합니다.