AI
10분 만에 RAG 이해하기

6분
2024.11.04.인기
31.9K
소프트웨어 산업에는 하루에도 수십 개의 새로운 약어와 개념이 등장합니다. 특히나 빠르게 변하는 AI 기술 같은 경우라면 더욱 말입니다.
새로운 밀레니엄을 앞둔 1999년 출간되어 벌써 25년이 지난 빌 게이츠의 명저 “생각의 속도”에서는 “새로운 테크놀로지를 이해하기 위해서는 바로 그 이전의 기술에 대한 이해가 필요하고, 그 흐름을 한 번 놓치면 생각의 속도는 영원히 뒤처진다.”라는 구절이 나오는데요. 이 말이 요즘처럼 피부로 이해되는 시기는 없었지 않나 싶네요.

AI를 제대로 맛보게 해 준 챗GPT와 같은 LLM이 우후죽순으로 등장하더니, 지금은 또 메타의 라마(LLama)로 대표되는 SLM 혹은 sLLM이라는 게 나오고, AI를 완성시키는 AGI라는 개념도 이해해야 하는데, 또 검색-증강 생성이라며 RAG라는 말이 심심치 않게 들립니다. 거기에 개발자나 엔지니어들은 랭체인(LangChain)이란 말을 수군거리면서 본인들의 영역표시를 확실하게 하죠.
배경 개념을 알고 거기에 쉬운 스토리를 붙이면 이해에 어렵지 않습니다. 최소한 이 글을 끝까지 읽으신다면 RAG에 대한 이해는 제가 책임지겠습니다. 자, 시작합니다.
RAG(Retrieval-Augmented Generation)를 번역한 “검색 증강 생성”이란 단어를 보면 이해하기가 더 어려울 수 있으니 먼저 원어의 단어 하나하나를 쪼개서 봅니다.
1. Retrieval
R에 해당하는 “Retrieval”의 의미는 번역된 ‘검색’이라는 의미보다는 “어디선가 가져오는 것, 집어 오는 것”입니다. 즉 어딘가에 가서 요청된 무엇인가를 집어 오는 것을 이야기하죠.
2. Augmented
A에 해당하는 Augmented는 “증강되었다”란 뜻이죠. 즉 원래 것에 뭔가 덧붙이거나 보태어 더 충실하게 좋아졌다는 뜻입니다.
자, 두 단어를 이해하셨으면 이제 거의 다 끝난 겁니다.
3. Generation
거기에 이젠 G, 즉, 생성이라는 Generation을 이야기해야죠. 생성은 프롬프트라고 하는 사용자 질문/질의에 대한 응답을 텍스트로 생성하는 것을 의미합니다.
요즘 LLM은 어디에나 존재합니다. 챗GPT뿐만 아니라 구글의 제미나이(Gemini), 앤트로픽의 클로드(Claude), 네이버의 하이퍼클로바(HyperCLOVA)도 있고요. 그 LLM은 질문에 놀랍게 답을 주기도 하고 어떤 경우엔 매우 흥미롭게 틀리기도 합니다. 이 괴물같이 큰 LLM은 학습자료를 매일 삼키고 있습니다.
그런데 매일 이렇게 쉼 없이 하다간 언제 서비스를 내놓을지 모르게 됩니다. 그러다 보니, 이날까지 학습한 것으로 딱 끊어서 서비스를 만들어 내놓습니다. 그게 결국 챗GPT 3, 3.5, 4 같이 버전을 만들게 되는 것이죠.
챗GPT 4의 경우엔 2023년 4월까지의 데이터로 학습한 상태입니다. 그렇다면 그 이후에 일어난 사건이나 지식에 대해서는요? 당연히 모르지요. 문제 아니냐고요? 아주 큰 문제 맞습니다.
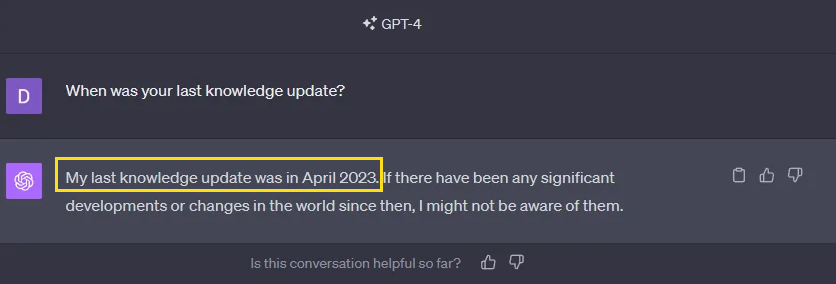
그래서 사람들은 이 LLM을 보다 정확하고 최신 상태로 유지하는 데 도움이 되는 프레임워크에 대한 아이디어를 냈습니다. 그게 바로 RAG입니다.
LLM에는 바람직하지 않은 동작이 크게 두 가지 있습니다.
이를 설명하기 위해 이야기를 하나 해 보죠. 제 아들이 어릴 때 이런 질문을 했습니다. “우리 태양계에는 몇 개의 행성이 있나요?” 어릴 때 ‘수금지화목토천해명’을 달달 외웠던 저에겐 아주 쉬운 질문이죠. “그거야 9개지.”라고 자신 있게 대답했죠. 제 지식은 약 40년 전이 마지막 업데이트였지만, 전 이 9개가 정답이라고 확신하고 있었습니다.
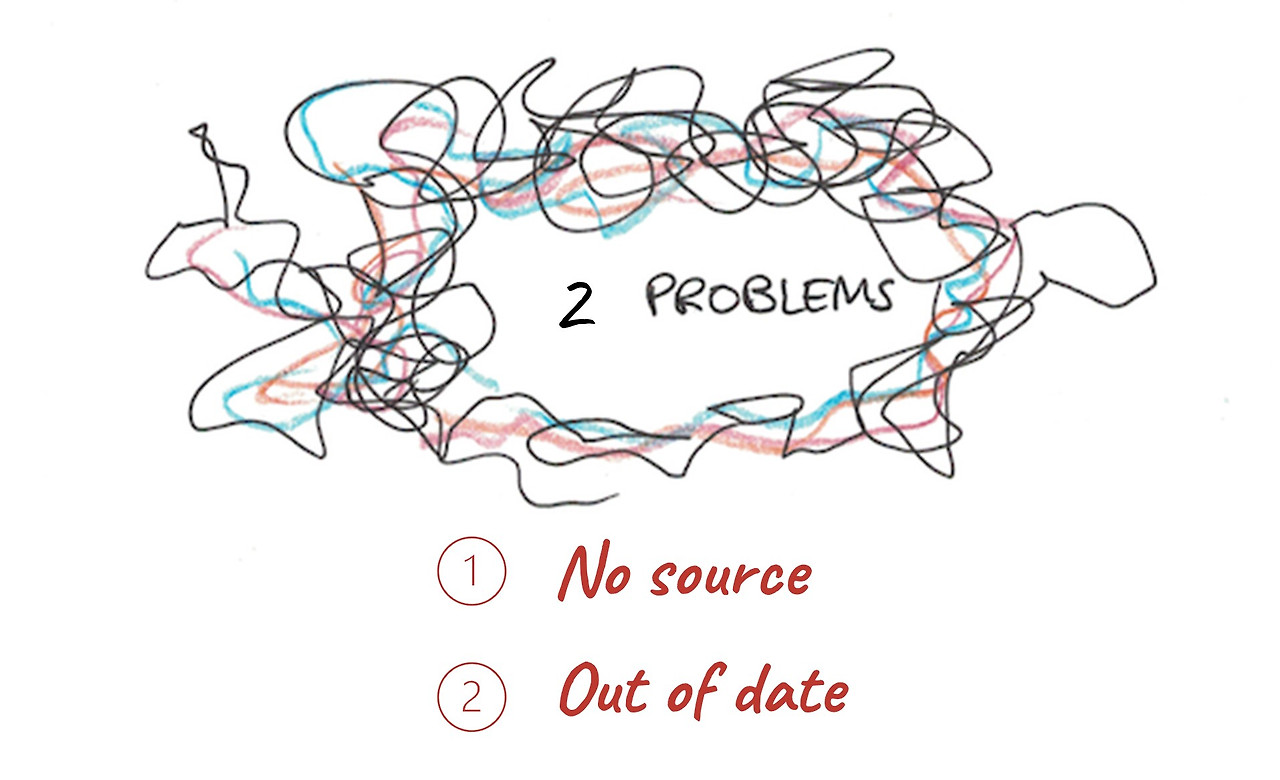
사실 제 대답에는 두 가지 크게 잘못된 점이 있습니다. 우선, 제가 말한 내용을 뒷받침할 만한 출처가 없습니다. 그래서 제가 자신 있게 “달달 외웠으니 답을 알아요!”라고 말했지만, 언제 어디서 누구에 의해 배웠는지로 돌아갈 출처가 없습니다. 답을 해줘야 하니 그냥 제 머릿속에서 떠오르는 답을 말하는 것입니다. 소위 환각(Hallucination)이라는 잘못된 대답을 할 수 있는 가능성이 높습니다.
여기에 덧붙여 더 심각한 문제가 되는 두 번째는 지난 40년 동안 이 주제를 업데이트하지 않았기 때문에, 제 답변은 시대에 뒤떨어져 있을 가능성이 있다는 것입니다.
만약 제가 대답을 하기 전에 잠깐 시간을 내서 공신력 있는 NASA와 같은 사이트에서 먼저 답을 찾아보았다면 어떻게 되었을까요? 아마도 “아, 내가 알고 있는 게 틀렸구나!”라고 바로 느꼈을 것입니다. 정답은 8개니까요. 2006년에 명왕성이 행성 기준을 못 맞추어 퇴출당하면서 태양계 행성은 8개가 되었거든요. 저는 이제 좀 더 믿을 만한 근거를 바탕으로 답을 해야겠다고 마음먹게 되었습니다. 그렇지 않으면 아빠는 거짓말쟁이가 되어 신뢰감을 못 주거든요.
이것이 LLM과 무슨 관련이 있을까요? 사실 이 두 가지 문제는 LLM을 이용할 때 종종 문제가 되는 바로 ‘그것’입니다. LLM이라면 이 질문에 어떻게 대답했을까요? LLM이라면 자신 있게 “예, 제가 학습한 바에 따르면 답은 9개입니다.”라고 말할 것입니다. 이러면 당연히 오답이 되지요. 하지만 LLM은 자신이 학습한 것을 대답한 것이기에 그것에 대해 매우 확신합니다. 자, 이 부분을 보강해야겠습니다.
이제 여기에 RAG, 즉, 검색 증강 부분을 추가하면 어떻게 될까요? 무슨 뜻이냐고요? 이제 LLM이 알고 있는 것에만 의존하는 것이 아니라 지식 콘텐츠 저장소를 추가한다는 뜻입니다. 저장소의 형태는 일반 인터넷 자료처럼 개방형일 수도 있고, 기업의 문서, 국가의 정책, 조직의 업무 프로세스처럼 폐쇄적일 수도 있고요.
하지만 중요한 것은 이제 LLM이 지 맘대로 대답하기 전에 먼저 지식 콘텐츠 저장소에 들려서 “사용자 질의와 관련된 정보를 검색해 줄 수 있나요?”라는 순서를 지시하는 일입니다. 이것이 바로 찾아오기(Retrieval), 그리고 그 대답이 풍부한 컨텐스트로 증강(Augmented)되는 것입니다. 그래서 9개가 아닌 8개라는 정답을 제공할 수 있는 것이지요.
정리하는 의미에서 흐름을 설명해 보겠습니다.
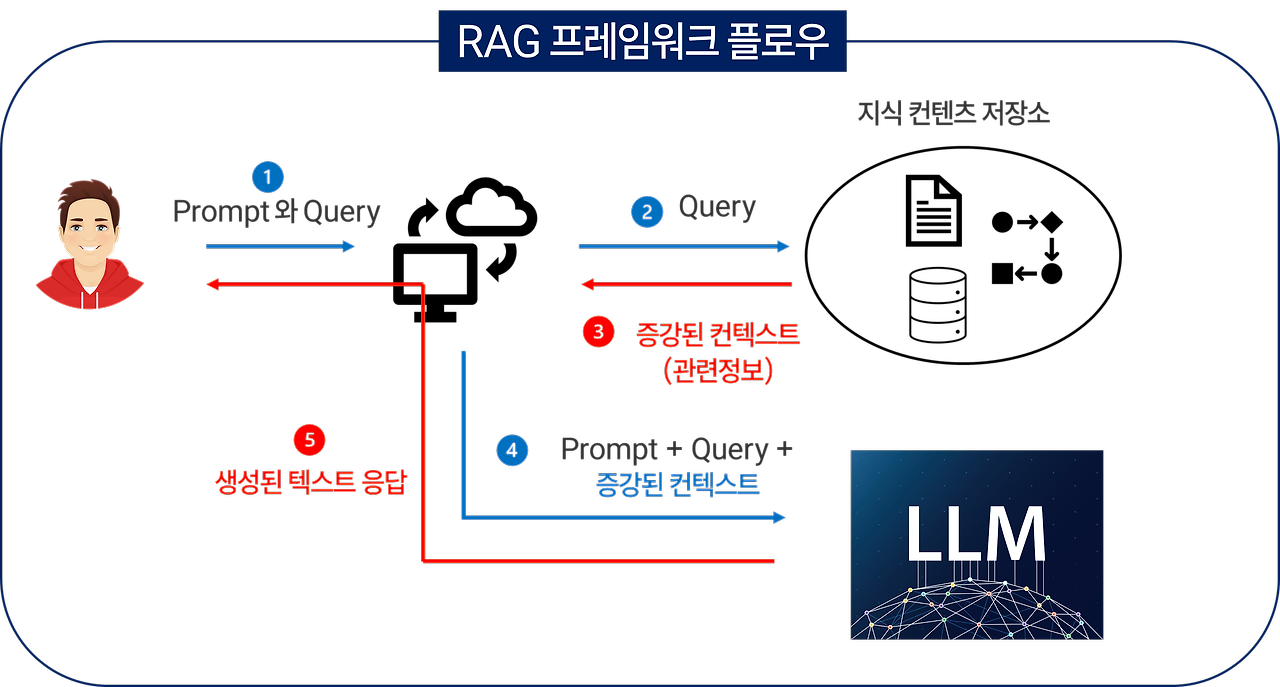
RAG 프레임워크가 없는 상황에서 사용자가 LLM에 질문을 던진다면, LLM이 직접 “아, 그래요, 답을 알아요. 여기 있습니다”라고 바로 응답을 줄 겁니다. 오답의 가능성이 높습니다.
하지만 이제 RAG 프레임워크에서는 생성 모델에 “아직 대답하지 말아요”라고 하는 명령어가 먼저 동작합니다. 이어 “먼저 관련 콘텐츠를 검색해 보세요.”, “그리고 이제 사용자의 질문과 결합해서 답변을 생성하세요.”라고 말합니다. 즉, 프롬프트는 주의하라는 지시, 검색된 콘텐츠, 그리고 사용자의 질문 세 부분으로 구성됩니다. 그리고 LLM을 통해 텍스트 응답을 만들어 냅니다.
이제 RAG가 위에서 말씀드린 두 가지 LLM 문제를 어떻게 해결하는지 이해하셨지요?
1. 먼저 정보를 업데이트하지 않아 생긴 오류부터 설명해 보죠. 이제 LLM을 다시 훈련할 필요 없이, 새로운 정보, 예를 들어 “명왕성은 더 이상 태양계 행성이 아니다” 라는 새로운 정보로 지식 콘텐츠 저장소를 보강하고 지속적으로 업데이트하기만 하면 됩니다. 그 후에는 가장 최신의 정보를 검색하기만 하면 됩니다.
2. 데이터의 출처 소스 문제는 어떻게 다룰까요? 이제 LLM은 응답을 제공하기 전에 기본 출처 데이터에 주의를 기울이도록 지시받고 있습니다. 이렇게 하면 학습한 정보에만 의존할 가능성이 줄어들기 때문에 -따로 업데이트된 지식 저장소가 있기에- 환각이나 데이터 유출 가능성이 줄어듭니다. 또한 모델이 “모르겠습니다.”라고 말할 수 있는 매우 긍정적인 행동을 하도록 할 수 있습니다. 지식 데이터 저장소를 기반으로 하였다고 해도 사용자의 질문에 신뢰할 수 있는 답변을 할 수 없는 경우는 생길 수 있습니다. 이때 모델이 사용자를 환각 시킬 수 있는 내용을 만들어내는 대신 “모르겠습니다”라고 말하는 것은 매우 중요합니다.
또 중요한 사항은 단순히 양질의 지식 콘텐츠 저장소를 준비하는 것뿐만 아니라, LLM에 최상의 고품질 정보를 제공하기 위한 리트리버(Retriever)를 개발하는 일입니다. LLM에 응답의 근거가 되는 최상의 데이터를 제공하기 위해 리트리버를 개선하고, LLM이 답변을 생성할 때 최종적으로 사용자에게 가장 풍부하고 최상의 답변을 제공할 수 있도록 생성(Generation) 부분도 개선하기 위한 노력이 필요합니다.
지금까지 RAG에 대한 개요를 짧게 설명해 드렸습니다. 여러분에게 도움이 되셨기를 바랍니다. 다음 글은 <10분 만에 랭체인(LangChain) 이해하기>로 정리해 보았습니다. RAG를 쉽게 이해하셨듯 랭체인 역시 10분 만에 이해할 수 있을 겁니다. 다음 글에서 뵐게요. 여러분들을 늘 응원합니다!
<원문>

©️요즘IT의 모든 콘텐츠는 저작권법의 보호를 받는 바, 무단 전재와 복사, 배포 등을 금합니다.