개발
QA팀이 테스트 자동화 지표로 ‘신뢰성’ 회복한 방법

5분
2024.10.30.6.2K
국내 유명 IT 기업은 한국을 넘어 세계를 무대로 할 정도로 뛰어난 기술과 아이디어를 자랑합니다. 이들은 기업 블로그를 통해 이러한 정보를 공개하고 있습니다. 요즘IT는 각 기업의 특색 있고 유익한 콘텐츠를 소개하는 시리즈를 준비했습니다. 이들은 어떻게 사고하고, 어떤 방식으로 일하는 걸까요?
이번 글에서는 패션 플랫폼 29CM의 QA팀에서 ‘테스트 자동화 지표’를 활용해 신뢰성을 확보한 경험에 대해 소개합니다.
안녕하세요, 29CM에서 QA팀을 맡고 있는 박현준입니다. 지난 7월 제3회 QA Korea Conference에서 정다정 님이 “자동화의 신뢰성(정확도)을 높이기 위해 한 액션”이라는 주제로 강연을 해주셨는데요. 그 내용에 추가적인 내용으로, 액션을 원활히 할 수 있도록 사전에 어떤 준비가 되어있었는지 이야기해 보려고 합니다.
이미 많은 QA 조직에서 시행하고 있는 것처럼 29CM QA팀도 앱 테스트 자동화와 API 테스트 자동화가 실행되고 있습니다. API 테스트 자동화의 경우 API 자체의 수정이 그리 빈번하지 않은데요. 테스트 결과가 Fail일 경우 API 문제보다는 네트워크 퍼포먼스에 의해 오류가 발생할 수 있어서, 테스트 스크립트를 수정해야 하는 상황까지 가지 않을 때가 많습니다. 그래서 테스트 자체의 신뢰성이 떨어져 잘못된 테스트 결과를 받는 경우는 거의 존재하지 않았죠.
신뢰성에 문제가 발생할 수 있는 부분은 바로 앱 테스트 자동화입니다. 앱의 경우 UI, UX의 변동이 빈번히 일어납니다. 신규 개발 기능이 추가되거나, 기존 기능이 업데이트되는 등 변동과 함께, A/B 테스트로 인한 UI 차이도 계정마다 발생할 수 있습니다. 이로 인해 테스트 자동화 수행 시 테스트 결과가 Fail인 경우가 자주 발생하게 되었고, 결과적으로 테스트 자동화 수행 결과의 신뢰성이 떨어지게 된 것이죠.
이처럼 신뢰성 하락 문제는 테스트 자동화 사용 여부에 대한 근간이 흔들릴 수 있는 문제였기 때문에, 팀에서는 중요한 우선과제로 잡고 2분기 OKR로 설정하여 집중적인 신뢰성 확보 작업을 진행했습니다. 그러기 위해서는 지표가 필요한데, 어느 부분이 얼마큼 개선되었고 실제로 개선이 된 것인지 판단할 수 있는 데이터를 수집해야 했습니다.
이에 QA팀에서는 Postgresql과 Grafana를 활용하여, 데이터를 시각화하고 지표를 추적하기로 했습니다. 이 과정에서 지표로 삼을 데이터를 선정하고 테이블 구조를 설정했습니다.
등을 필수 지표로 선정하여 기록합니다.
선택 지표로는 Fail이 컨트롤 영역 밖의 원인일 경우 해당 결과를 참조하지 않도록 별도로 기록하거나, 실제 Bug가 발견되어 Fail이 발생한 경우를 기록할 수 있도록 했습니다.


이렇게 지표를 설정한 후에는 데이터가 쌓이기를 기다리며 자동화를 계속 수행했습니다. 현재는 모바일팀에서 배포용 빌드가 나오면 자동으로 트리거되어, QA팀 테스트 자동화가 수행됩니다.
29CM는 주 1회 배포를 진행하며, 그때마다 3~6개 정도의 빌드가 나와 테스트를 수행하게 됩니다. 최근에는 프론트엔드 배포 시에도 트리거가 적용되어 자동화가 수행되고 있으며, 일주일 기준으로는 약 40회 정도 수행되고 있습니다. 데이터를 지표로 삼을 만큼 충분한 데이터가 모이게 되는 것이죠.
또한 테스트는 E2E 시나리오로 약 30여 개 정도가 수행되고 있습니다. 30개의 시나리오가 수행되면 테스트 결과와 관련된 정보를 DB에 적재하고, Grafana 대시보드에서 조회하기 위한 쿼리를 설정합니다.

그다음 수행 갯수와 Fail률을 체크하기 위한 Visualization을 생성합니다. 이를 통해 현재 Fail률을 실시간으로 체크할 수 있게 됩니다. 물론 실시간으로 Fail률을 보는 것도 중요하지만, DB화하는 것의 가장 중요한 목표 중 하나가 바로 추이를 확인하는 것입니다. 그래서 일주일간의 데이터와 한 달간의 데이터를 볼 수 있도록 Visualization을 생성해 둡니다. 이를 통해 우리의 Fail률은 감소하고 있는지, 증가하고 있는지 정확히 측정할 수 있게 됩니다.
우선 QA팀에서는 2Q(4월~6월)에 Fail률을 2% 미만으로 낮춘다는 계획을 잡고, Fail 매니징을 시작했습니다. Fail 발생 시 빠르게 대응하여 코드를 수정하고, 단순히 상황을 해결하기 위한 방식이 아니라 더 근본적인 원인을 찾아서 해결점을 찾는 시간을 가졌습니다.
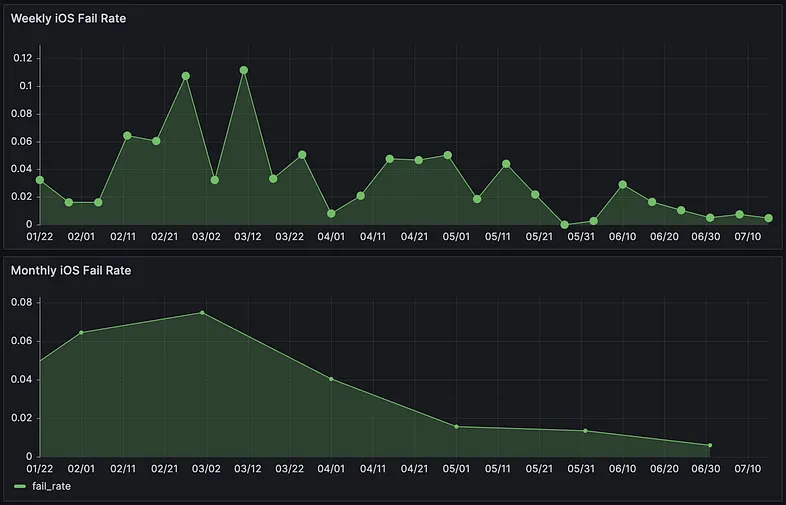
위 그래프를 보면 1Q(1월~3월)에는 Fail률이 8% 가까이 치솟은 모습을 볼 수 있습니다. 주간으로 보자면 12% 가까이 치솟을 때도 있었습니다. 하지만 팀 목표로 설정한 뒤인 2Q(4월~6월)에는 Fail률이 눈에 띄게 감소하는 모습을 확인할 수 있었습니다.
물론 근본적인 원인을 찾는 과정은 그리 순탄하지 않았습니다. 대기 시간을 1초 늘리거나, 플로우를 줄이면 해결할 수도 있었죠. 하지만 여기서 타협하지 않고, element를 못 찾으면 다른 xpath 쿼리를 사용하여 한 번 더 대상 element를 찾을 수 있도록 했습니다. 또한 언제 출력될지 몰라 Fail이 발생했던 팝업은 출력되는 페이지를 확인하여, 해당 페이지에 진입 시 빠르게 해당 팝업 여부만 체크했습니다. 시간이 늘어나더라도 안전성 있게 수행되는 것을 목표로 한 것이죠.
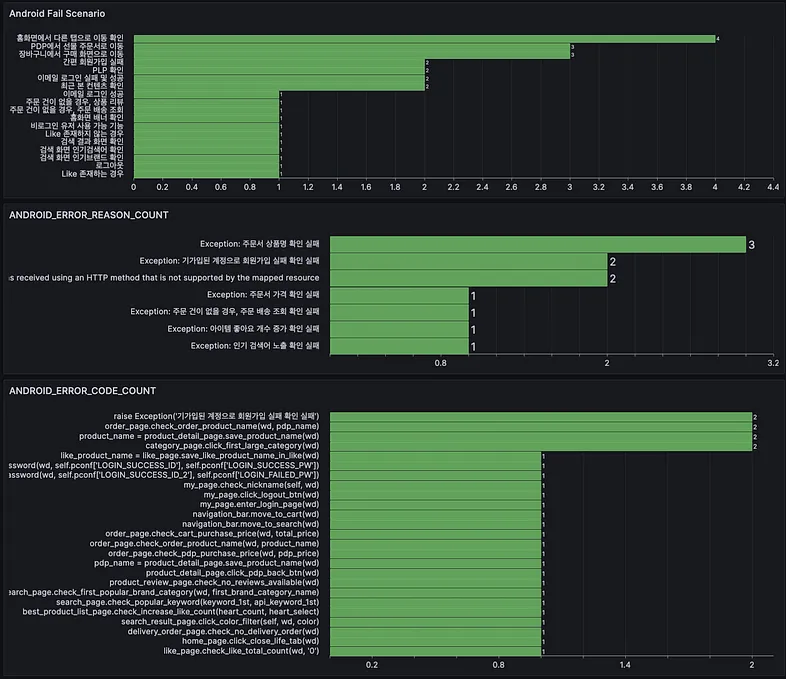
만약 Fail률이 증가하고 있다면 어떤 문제가 있는지 분석이 필요합니다. 가장 높은 빈도수의 시나리오와 에러 코드, 에러 원인을 수집하여 파악할 수 있게 하고, 어떠한 코드에서 자주 문제가 발생하는지 추적합니다.
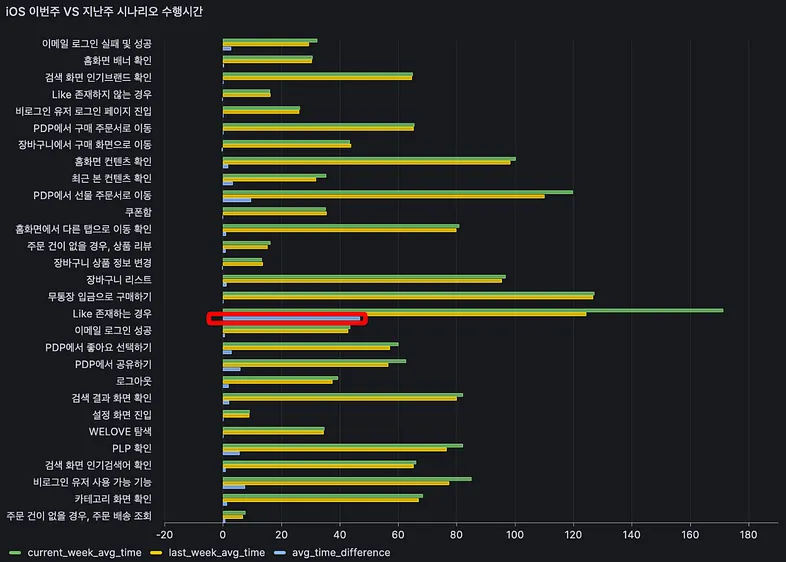
그다음 성능적인 부분도 체크합니다. 각 시나리오별 수행시간을 지속적으로 체크하여. 지난주와 대비하여 수행시간이 길어진 시나리오를 파악하고 원인을 찾습니다. 가장 영향을 많이 받는 부분은 웹뷰였습니다. 네이티브 화면은 시간 차이가 거의 존재하지 않는 데 비해, 웹뷰는 퍼포먼스의 차이가 자주 발생하는 편입니다.
따라서 퍼포먼스에 의한 시간 차이는 변동이 생길 수 있음을 인지하더라도, 큰 폭의 차이가 발생할 경우 시나리오를 수행하면서 어느 부분에 병목이 발생하는지 체크합니다.
처음에 Fail률은 눈에 보이지 않아 잡히지 않을 것처럼 보였습니다. 그러나 하나씩 그 모습을 드러낼 수 있게 DB화했고, 그것을 지표 삼아 Fail률을 잡는 데 성공했습니다. 이것은 저희에게 의미 있는 도전이었습니다. 저 또한 항상 QA는 어떻게 성과를 측정해야 하는지에 대한 물음이 있었는데, 이렇게 정량적으로 측정할 수도 있다는 점을 알게 됐습니다. 이러한 경험을 교훈 삼아, 앞으로도 QA 활동을 정량화 할 수 있는 방안이 있을지 좀 더 고민해 봐야겠습니다.
<원문>
29CM QA팀은 어떻게 테스트 자동화 지표를 활용하여 신뢰성을 확보할 수 있었을까?
©️요즘IT의 모든 콘텐츠는 저작권법의 보호를 받는 바, 무단 전재와 복사, 배포 등을 금합니다.