개발
MySQL에서 SQL 문장 가독성 향상시키는 법

8분
2024.09.11.인기
13.3K
IT 지식이 무엇보다 중요해진 요즘, 여러분은 어떻게 공부하고 있나요? 가장 먼저 눈길이 가는 건 다양한 IT 강의 영상일 겁니다. 강의를 제공하는 교육 기업들과 함께, 요즘IT에서 ‘IT 강의 시리즈’를 준비했습니다. 엄선한 교육 영상을 TEXT로 읽고 필요한 정보를 빠르게 가져가세요.
이번 강의는 ‘Real MySQL’입니다. 당근마켓 인프라실 DB팀에서 DBA로 근무하는 이성욱, 백은빈 님이 강의를 맡았습니다. MySQL 8.0 버전을 중심으로 실무에 바로 적용할 수 있는 MySQL 활용법을 다루고 있죠. 전체 영상은 인프런에서 확인할 수 있습니다.
Real MySQL 시리즈
① CHAR vs. VARCHAR, 언제 어떻게 써야 할까?
② VARCHAR vs. TEXT, 뭐가 다를까?⑤ MySQL에서 SQL 문장 가독성 향상시키는 법

이번 글에서는 MySQL에서 SQL 쿼리문을 사용할 때 가독성을 향상시키기 위한 몇 가지 방안을 살펴보려고 합니다. 여기서 ‘가독성’은 단순히 쿼리가 눈에 보기 좋은 형태로 작성된 것을 의미하는 것이 아니라, 어떤 의도로 사용하려는 건지 알기 쉽게 작성되어 있다는 의미로 봐주시면 됩니다. 가독성은 특히 업무 시 커뮤니케이션 측면에서 중요한 부분인데요. 가독성을 높이는 방법을 미리 숙지하고 있으면, 많은 도움이 될 것으로 예상합니다.

먼저 가독성의 중요성부터 살펴보겠습니다. 쿼리를 작성할 때 가독성을 고려하는 것은 왜 중요할까요? 먼저 가독성이 높으면 쿼리의 작성 의도를 보다 쉽게 파악할 수 있습니다. 이는 다른 사람들이 쿼리를 이해하는 데 드는 시간이 단축된다는 것을 의미합니다.
이로 인해 커뮤니케이션 비용이 줄고, 업무 진행 속도가 빨라질 수 있죠. 생산성 또한 증대될 수 있고요. 또한 가독성 높은 쿼리는 나중에 문제가 발생해도, 빠른 디버깅과 수정을 가능하게 하고 실수를 감소시킵니다. 즉, 문제가 발생할 확률을 줄여주고, 만약 문제가 발생했다 하더라도 수정에 소모되는 시간을 단축시켜줍니다. 남은 시간을 다른 일에 더 투자할 수 있죠. 또한 이와 같은 장점 덕분에, 장기적으로는 해당 쿼리를 사용하는 시스템의 유지 보수 비용도 줄어든다고 볼 수 있습니다.
이처럼 가독성은 단순히 보기 좋게 쿼리를 작성하는 것을 넘어, 효과적인 커뮤니케이션, 향상된 업무 효율, 그리고 낮은 유지보수 비용으로 이어지는 중요한 요소가 됩니다. 따라서 SQL 쿼리를 작성할 때는 항상 가독성을 고려해야 합니다. 이제 가독성을 높이는 구체적인 방안에 대해 살펴보겠습니다.

첫 번째로 DISTINCT를 함수처럼 사용하는 형태는 지양하는 것이 좋습니다. DISTINCT는 함수가 아님에도 불구하고, 괄호와 함께 사용하는 경우가 종종 있는데요. 괄호와 함께 사용한다 하더라도 그렇지 않은 경우와 결과가 동일합니다. 그래서 괄호를 사용하는 경우, 실제 쿼리와는 다른 의도로 보일 수 있는데요. 추가로 더 필요한 부분이 있는 건지, 의도가 불분명한 부분이 있어 괄호가 없는 형태로 사용하는 것을 권고합니다.
위 예시 쿼리들을 보면, 왼쪽과 같이 괄호를 넣어서 사용하는 형태와 오른쪽 쿼리는 결과가 동일합니다. 또한 MySQL에서는 왼쪽처럼 쿼리를 실행하더라도, 자동으로 오른쪽과 같은 형태로 변경해서 쿼리를 실행합니다. 그래서 오른쪽 예시와 같이 괄호를 사용하지 않는 것이 올바른 형태로, 사용 의도를 명확히 할 수 있어 쿼리의 가독성도 높아집니다.

두 번째 방법은 LEFT JOIN을 사용하는 방법을 준수하고 필요한 경우에만 사용하는 것입니다. LEFT JOIN 사용 시 LEFT JOIN의 JOIN 대상 테이블, 즉 LEFT JOIN 오른쪽에 있는 드리븐 테이블에 대한 조건을 WHERE 절에 명시한 경우에는 INNER JOIN을 사용한 것과 동일한 결과가 출력될 수 있습니다.
그래서 실제로 의도한 게 LEFT JOIN을 사용하는 거라면, 드리븐 테이블에 대한 조건은 WHERE 절이 아닌 ON 절에 명시해 사용해야 합니다. 그런데 만약 원래 의도한 게 INNER JOIN을 사용하는 거였다면, WHERE 절에 조건을 명시해도 상관없습니다. 다만 이 경우에는 LEFT JOIN 키워드가 아닌 INNER JOIN으로 명확하게 변경해 사용하는 것이 좋습니다.
그리고 LEFT JOIN은 필요한 경우에만 사용하는 것이 좋습니다. 예를 들어, LEFT JOIN하는 두 테이블이 서로 1:1 관계일 때, 쿼리에서 LEFT JOIN하면서 조인 왼쪽에 위치한 드라이빙 테이블에 속해 있는 컬럼들만 조회하거나 또는 COUNT를 사용하는 경우에는 굳이 LEFT JOIN을 수행할 필요가 없으므로, 제거해서 사용하는 것이 가독성뿐만 아니라 성능적인 측면에서도 좋습니다.

방금 말한 내용에 대해 간단하게 예제를 살펴보겠습니다. 예를 들어, DB에 유저 정보가 저장되는 user 테이블과 유저들의 속성값을 저장하는 user_attribute 테이블이 있다고 가정해 볼게요.
user 테이블에는 id가 PK 컬럼으로 되어 있고, user_attribute 테이블에는 user_id와 name, 이 두 개의 조합으로 프라이머리 키가 구성되어 있다고 가정했을 때, 유저 테이블의 유저 목록을 전체 다 조회해야 하는데, 만약 주소 정보를 입력한 유저가 있다면 그 정보는 함께 출력되도록 쿼리를 작성한다고 해볼게요.
우선 왼쪽에 나와 있는 쿼리들 중에 첫 번째 쿼리부터 살펴보면, user와 user_attribute 테이블을 LEFT JOIN을 사용해서 조인하고, 실제 가져올 속성인 주소값에 해당하는 조건을 WHERE 절에 사용한 것을 알 수 있습니다.
이렇게 실행하게 되면 실제 user와 user_attribute 테이블을 조인한 결과에서, user_attribute 테이블의 name 컬럼의 값이 “address”인 데이터들만 필터링한 후 결과를 반환하기 때문에 실제 바로 밑에 나와 있는 INNER JOIN 쿼리와 동일한 결과를 얻게 됩니다.
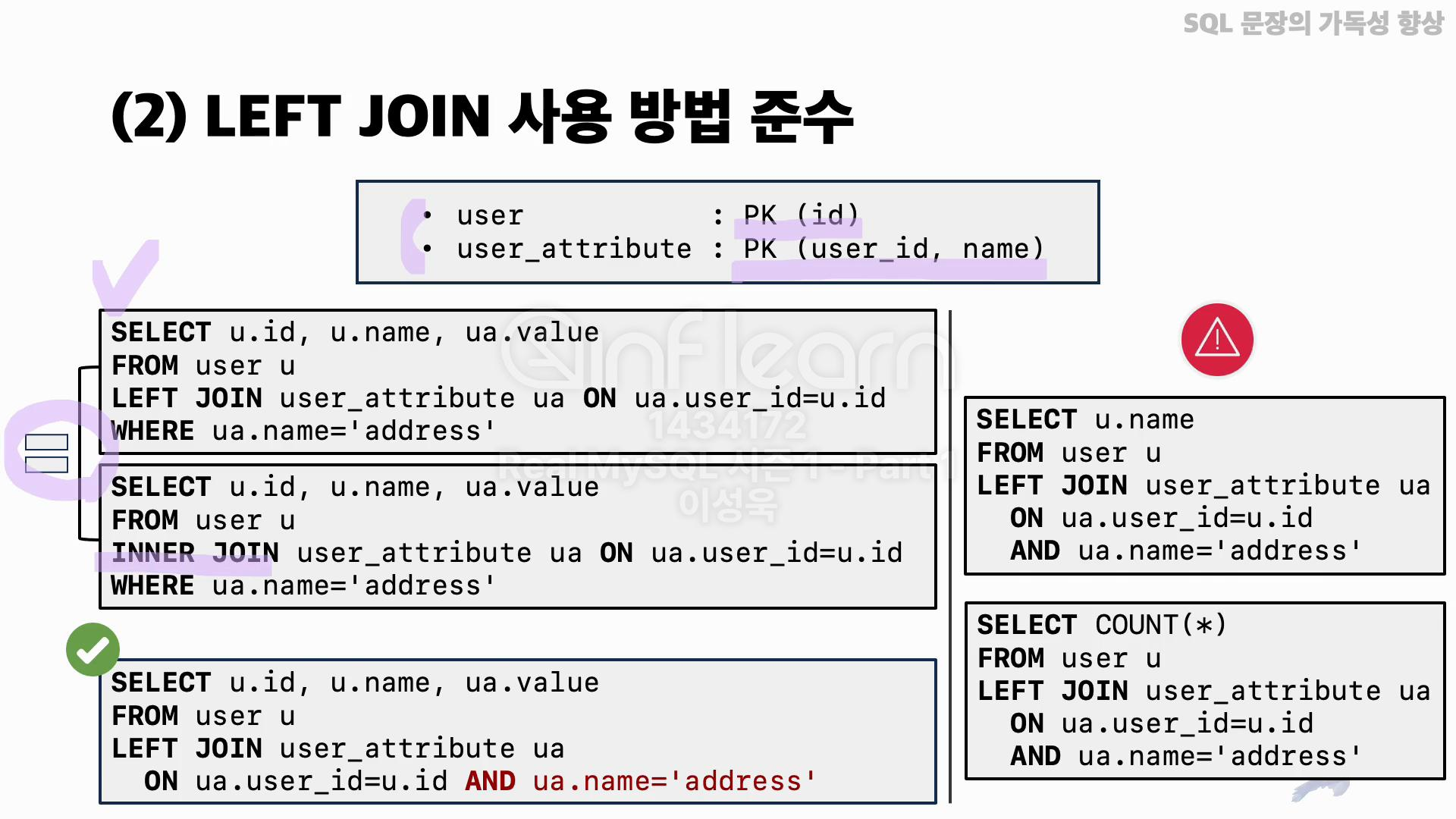
이렇게 되면 원래 의도와 다른 결과를 얻게 되고, 또 LEFT JOIN을 제대로 사용한 게 아닙니다. 그래서 LEFT JOIN을 사용하는 경우, 그림의 제일 밑에 나와 있는 쿼리처럼 ON 절에 속성 이름 조건을 명시해 올바르게 사용하는 것이 좋습니다.
그리고 그림에서 오른쪽에 있는 쿼리들을 보면 동일한 조건이지만, SELECT 절에는 드라이빙 테이블인 user 테이블에 있는 컬럼만 명시되고, 또 COUNT 함수를 사용한 쿼리가 있는 것을 알 수 있는데요. 이 경우에는 실제 user 테이블과 user_attribute 테이블을 LEFT JOIN한 결과가 user 테이블만 조회한 경우와 동일하기 때문에, 굳이 LEFT JOIN이 필요하지 않습니다. 그래서 불필요한 부분이라고 할 수 있죠.
그래서 LEFT JOIN이 이와 같은 형태로 사용되는 경우에는 쿼리에서 LEFT JOIN을 제거하는 것이 쿼리 성능에 더 도움이 됩니다. 이 부분도 참고해서 쿼리를 작성하면 좋을 것 같습니다.

그리고 세 번째로는 ORDER BY 절 없이 LIMIT 문법을 사용하는 형태는 지양하는 것이 좋습니다. 쿼리에서 ORDER BY 절 없이 LIMIT이 사용되는 경우가 종종 있는데요. 특히 쿼리에서 결과로 반환되는 데이터가 여러 건인 경우에는 반환되는 데이터를 예측할 수 없습니다. 또한 어떤 의도로 이렇게 사용된 건지 의도를 파악하기 어려워지죠.
그래서 LIMIT 절이 불필요한 부분이거나, 혹은 의도하지 않게 추가된 부분이라면 명확하게 제거해 주는 것이 좋습니다. 만약 페이지네이션 처리를 위해 LIMIT을 사용했다면, 정렬 기준이 반드시 포함되는 게 맞기 때문에 ORDER BY 절을 명시해서 사용해야 합니다.

다음으로 그룹핑을 할 땐 FULL GROUP BY 형태로 쿼리를 사용하는 것이 좋습니다. FULL GROUP BY 형태란 GROUP BY 절을 사용한 쿼리에서 SELECT 절에, GROUP BY 절에 명시된 컬럼이나 집계 함수를 사용한 컬럼만 명시하는 것을 말합니다. SELECT ~ GROUP BY 쿼리에서 GROUP BY 절에 명시되지 않은 컬럼을, 집계 함수 없이 SELECT 절에 명시해 사용하는 경우를 종종 볼 수 있는데요.
바로 위 예시에서 왼쪽에 있는 쿼리와 같은 형태로 사용된 경우를 의미합니다. 이 경우 해당 컬럼은 그룹핑 기준 컬럼이 아니다 보니, 집계함수를 사용하지 않은 경우 의도치 않은 값이 결과로 반환될 수 있습니다.
또한 어떤 이유로 이렇게 쿼리를 작성하게 된 건지, 의도를 명확하게 알 수 없는데요. 데이터의 정확성을 보장하고, 의도에 맞게 예측 가능한 결과가 반환될 수 있도록 오른쪽 쿼리와 같이 적절한 집계함수를 사용하는 것이 좋습니다.
또한 불필요한 컬럼이라면, 쿼리에서 제거하거나 만약 어떤 값이 반환되어도 크게 상관없는 경우라면, ANY_VALUE()라는 함수를 사용해 보세요. 단순히 컬럼만 명시하는 것보다는 가독성 측면에서 훨씬 더 나은 선택일 것입니다.

그리고 MySQL에서는 SQL 모드 설정(sql_mode)을 통해 FULL GROUP BY 형태로만 쿼리가 수행되도록 강제할 수 있는데요. FULL GROUP BY 모드는 SQL 모드 설정에 기본으로 포함되어 있습니다. 따라서 SQL 모드 설정을 직접 변경하는 경우가 아니라면, 기본적으로 FULL GROUP BY 형태로만 쿼리를 사용할 수밖에 없을 것으로 예상합니다.
그렇지만 SQL 모드 설정에 FULL GROUP BY 모드가 지정되지 않은 환경이라면, 그림의 왼쪽과 같이 FULL GROUP BY 형태가 아닌 쿼리도 정상적으로 실행됩니다. 따라서 쿼리 작성 시 이와 같은 부분을 고려해, 가독성이 높은 FULL GROUP BY 형태로 작성하는 것이 좋습니다.

다음으로 쿼리의 WHERE절에서 AND와 OR 조건을 함께 사용하는 경우를 살펴볼게요. 표준 SQL에서 AND 연산자는 OR 연산자보다 우선순위가 높습니다. 그래서 괄호가 없는 경우에는 AND 연산자를 우선해서 처리하게 됩니다.
그림에서 3개의 예시가 나와 있는데요. 왼쪽부터 살펴보겠습니다.
우선 첫 번째로 “SELECT 1 OR 0 AND 0”으로 쿼리를 실행하면, 결과로 1이 반환된 것을 알 수 있습니다. 즉, 뒤에 있는 AND 절이 먼저 처리된 후 그다음에 OR 연산이 수행되어 1이 출력된 것입니다. 두 번째 쿼리를 보면 AND 절이 괄호로 묶여있고, 첫 번째 쿼리와 동일한 결과가 나온 것을 알 수 있습니다.
세 번째는 OR 부분을 괄호로 묶어서 실행했는데, 이 경우에는 결과가 0으로 출력됩니다. 따라서 제일 처음 말한 것처럼 AND 연산자가 OR 연산자보다 우선순위가 높기 때문에, 괄호가 없는 첫 번째 경우와 AND 절을 괄호로 묶은 두 번째 경우에서 동일한 결과가 반환된 것을 알 수 있습니다.
물론 연산자 우선순위를 명확하게 알고 있어서, 괄호를 사용하지 않고 원하는 결과가 나오도록 쿼리를 사용할 수도 있습니다. 하지만 괄호를 사용하지 않는 경우, 특히 쿼리의 조건이 다양하게 추가될수록 한눈에 쿼리의 작성 의도를 파악하기 어렵습니다. 이때 실수가 발생할 확률도 높아져 예상하지 못한 결과가 반환될 수 있으므로, 어떤 조건들을 어떤 조합으로 사용하려고 하는지 명확하게 알 수 있도록 괄호를 꼭 사용하는 것이 좋습니다.

마지막으로 COUNT 쿼리에 대한 내용입니다. 데이터 건수를 조회하는 데는 다양한 방법들이 있는데요. 주로 사용되는 건 COUNT 함수입니다. COUNT 함수를 사용하는 경우에도, 그림에 있는 예시처럼 다양한 형태들이 있고, 또 SUM 함수를 사용할 수도 있습니다.
이처럼 형태는 다를 수 있지만, 결과적으로는 모두 동일한 데이터 건수를 반환하게 됩니다. 그렇기 때문에 의도를 좀 더 명확히 알 수 있는 형태로 사용하는 것이 좋은데요. 데이터 건수를 세기 위한 것이므로, SUM과 같은 함수보다는 COUNT 함수를 사용하는 것이 좋습니다. 또한 COUNT 함수를 사용하는 경우, 인자로 특정 컬럼이나 1과 같은 상수값을 주기보다는 (*, Asterisk)를 사용하는 것이 좋습니다.
(*)는 모든 컬럼 값을 대표하며, 이는 특정 컬럼 값을 고려하지 않고 단지 행의 수만 센다는 것을 명확하게 보여줍니다. 따라서 쿼리의 목적을 분명히 하고 쿼리를 읽는 이가 손쉽게 이해할 수 있도록 COUNT(*)를 사용하는 것이 좋습니다.
지금까지 쿼리의 가독성을 높이는 여러 방법에 대해 살펴보았는데요. 가독성 좋은 쿼리는 더 나은 이해와 빠른 문제 해결, 그리고 원활한 협업과 소통을 가능하게 해줍니다. 이번 글에서 설명한 내용을 숙지하여, 가독성 높은 쿼리를 작성할 수 있길 바랍니다.
원본 강의 보러가기 https://u.inf.run/4fss3D5
©️요즘IT의 모든 콘텐츠는 저작권법의 보호를 받는 바, 무단 전재와 복사, 배포 등을 금합니다.