개발
시작하는 개발자를 위한 JS 구조 분해 활용법 3가지

7분
2024.09.09.인기
9.5K
IT 지식이 무엇보다 중요해진 요즘, 여러분은 어떻게 공부하고 있나요? 가장 먼저 눈길이 가는 건 다양한 IT 강의 영상일 겁니다. 강의를 제공하는 교육 기업들과 함께, 요즘IT에서 ‘IT 강의 시리즈’를 준비했습니다. 엄선한 교육 영상을 텍스트로 읽고 필요한 정보를 빠르게 가져가세요.
이번 강의는 ‘Web 개발자 부트캠프 2024: JavaScript의 최신 기능들’입니다. 개발자이자 부트캠프 강사로 활동하며 전 세계 175만 명 이상 수강생을 배출한 콜트 스틸(Colt Steele) 님이 강의를 맡았습니다. 시작하는 개발자를 위해 코드 작성에 도움이 되는 JavaScript 기능을 소개합니다. 영어로 진행한 강의의 번역본을 기초로 글을 구성했고, 전체 영상은 유데미에서 확인할 수 있습니다.
안녕하세요, 가르치는 일을 진심으로 사랑하는 개발자 콜트 스틸입니다. 이번에 배울 것은 구조 분해입니다. 이 구문으로는 값을 해체하고 꺼내고 선정할 수 있습니다. 배열과 객체에 적용할 수 있죠. 이들을 해체해 별개 변수 형태로 만들 수도 있고요.
편하게 코드를 쓰고 관리하는 데 큰 도움을 줄 겁니다. 시작해 볼까요?
배열부터 시작합시다. 예시를 볼게요.
아래 배열에는 점수가 순위대로 쓰여 있습니다. 이 점수를 핀볼 게임의 점수라고 해봅시다.

이 가운데 1위와 2위의 점수를 따로 꺼내서 보상을 주고, 나머지는 별개 변수로 분리하고 싶습니다. 어떻게 하면 좋을까요?

위와 같이 score[0]를 입력해 1위 점수를 우선 선정하고 그 아래에는 score[1]을 입력해 2위 점수를 선정했습니다. 그럭저럭 괜찮은 방법이지만, 이보다 더 간편한 방법이 있습니다.
분해를 이용하는 거죠. 이를 활용해 만든 더 짧은 구문은 아래 형식을 활용합니다.

이 배열 대괄호 안에 첫 번째 값을 gold, 두 번째 값은 silver라고 부르도록 하겠습니다.

이제 콘솔에서 gold, silver를 입력하면 어떤 값이 나올까요?
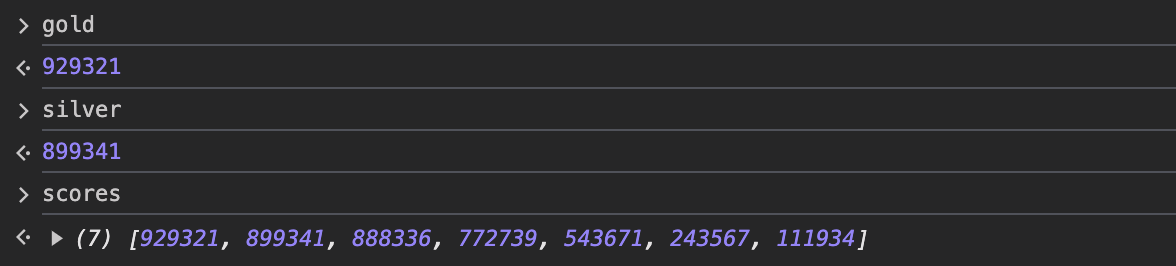
scores의 첫 요소가 gold에, 두 번째 요소는 silver라는 변수에 저장되었습니다.
이 작업은 배열의 값에 영향을 주지 않습니다. 기존 값을 지우며 새로 꺼내는 게 아니니까요. 개별 변수에 점수를 복사해 쓰는 것일 뿐입니다. 그래서 계속 덧붙일 수 있습니다. 곧 bronze를 추가하면 세 번째 점수가 bronze가 될 겁니다. 이 세 가지 값의 순서대로 세 개의 변수를 만들었습니다.

잠시 다른 예시도 살펴볼게요. 이번에는 달리기 선수들의 기록입니다.
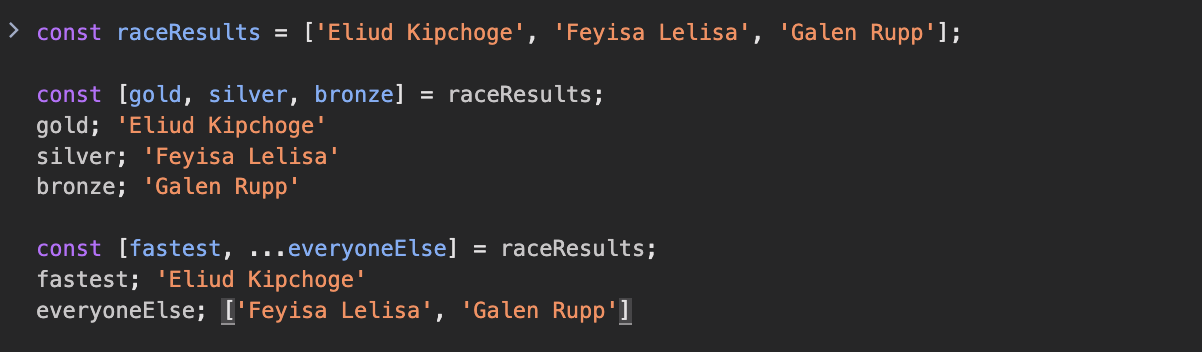
여기도 gold, silver, bronze 순으로 경주 결과를 나타냈습니다. 이처럼 배열을 구조 분해할 때는 대괄호를 잊지 말아야 합니다. 이 대괄호는 배열에서 분해한 것을 어떻게 지칭할지 정합니다.
다시 핀볼 게임 예시로 돌아가 봅시다. 이 예시에서는 점수 값이 많았습니다. 무려 일곱 가지 값 중에 세 개를 꺼내 단독 변수로 만들었습니다. 이제 그 외 점수들을 나머지 모두(everyoneElse)라는 변수에 저장해 볼게요. 앞서 전개 구문에서 배운 나머지 연산자(...)를 이용합니다.

콘솔에서 나머지 모두(everyoneElse)를 입력한 결과를 볼까요? gold, silver, bronze에 해당하지 않는 점수들이 나옵니다. 총 네 개의 요소가 나오는데, 모두 순서를 기반으로 합니다.

배열의 구조 분해 역시 자주 쓰이는 구문이지만, 더 흔히 쓰이는 게 있습니다. 바로 객체 구조 분해입니다.
객체 구조 분해는 순서를 따르지 않기 때문에 배열 구조 분해보다 실용적입니다. 사용자 정보를 가진 객체 user를 예로 보겠습니다.

몇 가지 특성에 접근하거나 선정해야 하는 상황입니다. 첫 번째 방법입니다. 직접 특성을 부르는 구문을 입력하는 겁니다. firstName, lastName, email 값을 부르도록 직접 입력했습니다. 물론 값은 원하는 대로 잘 나옵니다.
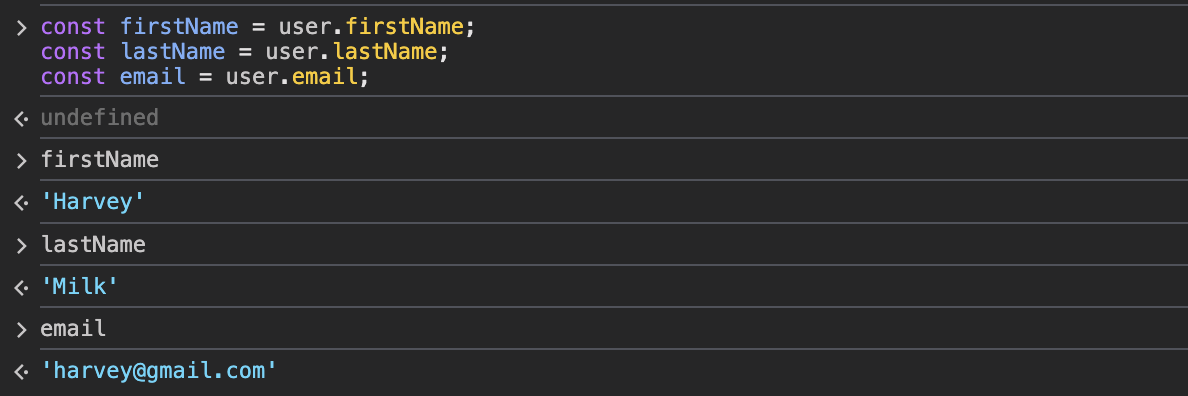
하지만 선정하고 싶은 특성이 있을 때마다 일일이 코드를 작성하려면 매우 귀찮겠죠.
이럴 때 구조 분해 구문을 이용할 수 있습니다. let이나 const 뒤에 중괄호를 입력합니다. 그 중괄호 안에는 개별 특성을 넣어 줄 겁니다.

배열과는 달리 여기서 순서는 상관없습니다. 대신 특성의 이름이 중요하죠. email 값을 원한다고 해봅시다. 그럼 중괄호 안에 email을 입력합니다. email이 이름인 특성을 부른 겁니다. 또한 그와 함께 특성값을 가진 email이라는 변수를 만든 것이죠.

확인해 봅시다. 콘솔에서 email을 입력하면 실제 메일 주소가 나옵니다.

중괄호 안에 다른 특성도 넣어보겠습니다. firstName, lastName, city, bio를 넣었습니다. 그러면 총 다섯 개의 변수가 만들어진 겁니다.

이제 콘솔에서 변수를 호출하면 각 특성값을 꺼낼 수 있습니다.

사실 엄밀하게 말하면 꺼낸 건 아닙니다. 값은 그대로 있으니까요. 대신 변수로 지정해 주었다고 하는 게 맞을 것 같아요. 객체 자체를 바꾼 건 아닙니다. 객체의 값을 기반으로 한 다섯 개의 새 변수를 만든 거죠. 이 기능은 여러모로 도움이 될 겁니다.
종종 변수로 활용하기 어려운 이름을 가진 값이나 특성이 있는데요. 객체 분해를 활용하면 값을 객체에서 꺼낼 뿐 아니라 새 이름도 지을 수 있습니다. 변수의 이름이 특성의 이름과 꼭 같을 필요는 없는 거죠.
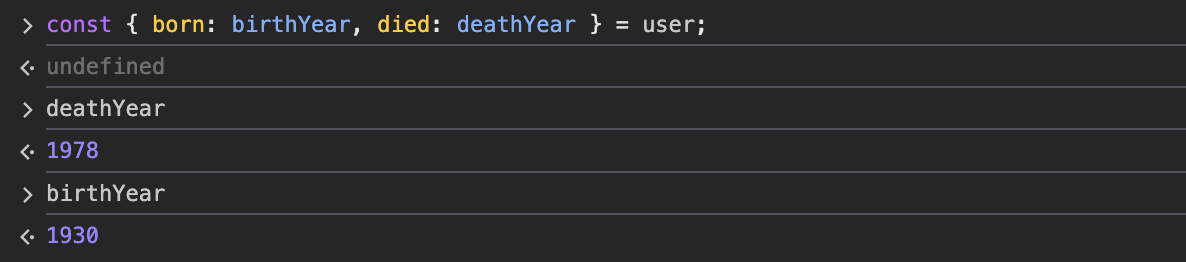
예시의 born과 died 특성을 좀 더 엄밀하게 출생 연도(birthYear)와 사망 연도(deathYear)라고 하겠습니다.
일단 출생연도부터 시작합시다. 중괄호를 만들고 born을 입력하면 그대로 born이라는 변수가 만들어질 겁니다. 새 이름을 짓기 위해 콜론을 넣고 birthYear를 입력하겠습니다. 이제 변수의 이름은 born이 아닌 birthYear가 됩니다.

user의 born 특성값이 birthYear 변수에 쓰이는 겁니다. 콘솔에서 born을 입력하면 아무것도 없지만, birthYear를 입력하면 값이 나오죠.

died에도 같은 방법을 써서 deathYear라고 이름을 지을게요. 곧 birthYear와 deathYear 값을 확인할 수 있습니다.
마지막으로 디폴트 값 추가를 배워 보겠습니다. 또 다른 사용자, user2가 있다고 칩시다.
이 사용자의 정보에는 특성이 많지 않습니다. 특히 died 특성이 없는데요, 아직 살아 있는 사람이기 때문입니다. 유명한 사람이 아니기 때문에 bio도 없습니다.

자, 이번에는 user2라 객체를 구조 분해해 보도록 합시다. 중괄호 안에 선정할 특성을 입력하겠습니다. 무슨 특성을 볼까요? city와 state를 입력할게요. 그리고 died도 추가하겠습니다. 실제로 객체에는 없는 정보지만, 어떤 값이 나오는지 확인하기 위해 넣어 보겠습니다.

콘솔에서 died를 입력해 볼까요?

undefined가 나왔습니다. undefined가 오류는 아닙니다. 그저 객체에서 해당 데이터를 못 찾았기 때문입니다.
이럴 때는 디폴트 값을 주어 해결할 수 있습니다. 디폴트 값은 = 을 입력해 설정합니다. 여기서는 died 값이 없으면 N/A가 뜨도록 설정했습니다.

반면 첫 번째 사용자(user)인 Harvey Milk의 경우, 디폴트 값을 N/A로 주더라도 결과에 N/A가 뜨지는 않습니다. 객체의 특성값인 1978이 뜨죠. died 값이 있으니까요.

마지막입니다. 이번 구조 분해는 함수의 매개 변수에 적용됩니다.
함수를 정의할 때 괄호 안에 매개 변수를 작성하면 전달하는 값의 구조를 분해할 수 있습니다. 이는 객체에 주로 쓰이는 방법입니다.
예시를 보면서 더 자세히 알아보겠습니다. 우선 간단한 것부터 하죠. 앞서 본 사용자(user) 객체를 전달하는 함수를 만들겠습니다. 함수의 이름은 firstName이라고 지었습니다. 사용자 객체의 정보를 받아 값을 출력할 겁니다. 반환문으로 firstName과 lastName을 출력해 보겠습니다. 아래와 같은 형태죠.

사용자(user)의 fullName을 출력하면 값이 나올 겁니다.

이와 같은 결과를 구조 분해를 이용해 만들 수 있습니다.
위의 코드에 몇 가지를 추가하겠습니다. 중간에 const 문을 넣고 return 부분에서 user를 지우겠습니다. 큰 차이는 없죠?

처음 작성한 코드가 더 짧지만 매개 변수를 자주 쓸 때는 이 방식이 더 낫습니다.
좀 더 줄여서 코드를 작성할 수도 있습니다. born, died, bio 등 다른 특성 정보는 출력하지 않고 이름 정보만 필요하다면 말이죠. 아예 매개 변수에서 구조 분해를 할 수 있습니다. 다시 fullName이라는 함수를 생성합니다. 그다음 값을 가져오는 매개 변수 자리에서 곧바로 구조 분해를 하는 거죠. return은 위의 함수에서 그대로 가져오겠습니다.

코드가 훨씬 짧아진 데다 user라는 이름은 아예 작성하지 않아도 됩니다. 이 방법으로도 똑같은 값, Harvey Milk가 나옵니다.

이러한 구조 분해는 배열 메서드에서도 자주 쓰입니다. 예시로 영화 정보를 가져왔습니다.
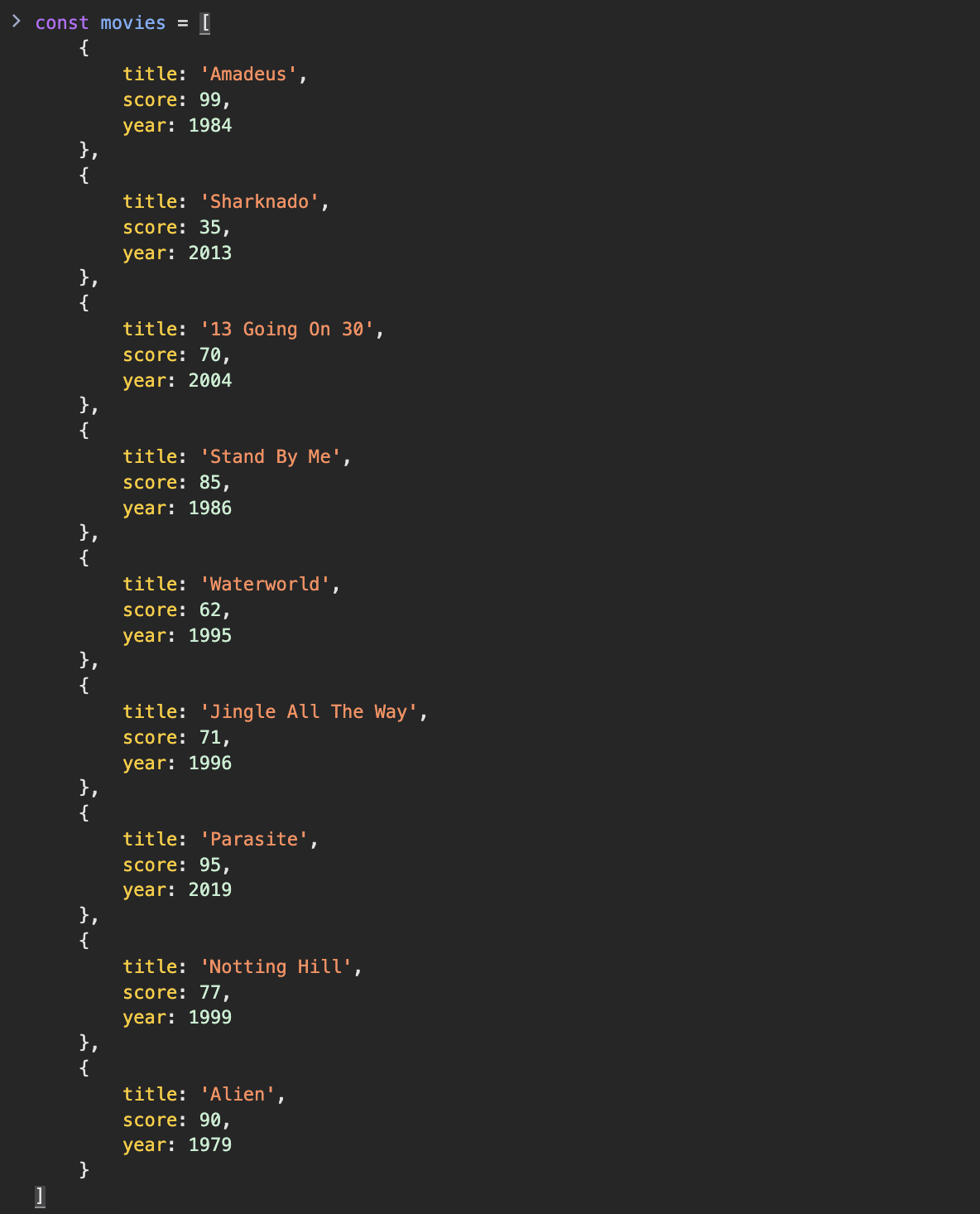
평점으로 영화를 분류한다고 칩시다. 이 작업에는 filter 메서드를 이용하겠습니다. score 특성이 90점 이상인 영화를 분류합시다. 높은 평점의 영화들은 무엇일까요?
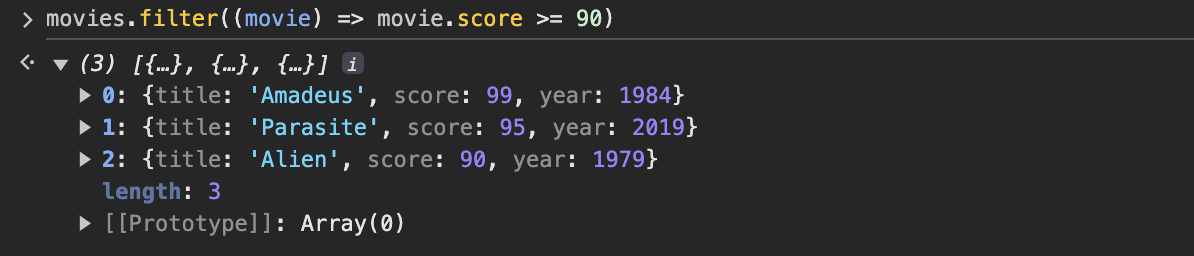
Amadeus, Parasite, Alien이 나오네요.
이때 매개 변수 자리에 구조 분해를 이용해도 됩니다. movie라는 객체 이름을 빼도 된다는 뜻이죠. 그저 중괄호 안에 score를 넣으면 됩니다. 앞서 작성한 코드보다 훨씬 짧죠.

다만 여전히 같은 한 줄이어서 차이가 크게 느껴지지 않을 수 있습니다. 더 긴 코드가 필요한 때를 보겠습니다. title, score, year 특성을 한 번에 구조 분해해 봅시다.
여기에는 map을 이용할게요. movies.map을 입력하고 return 값으로는 영화 제목과 개봉 연도, 평점이 나오도록 문자열 템플릿 구문을 작성했습니다.

결과는 어떨까요?
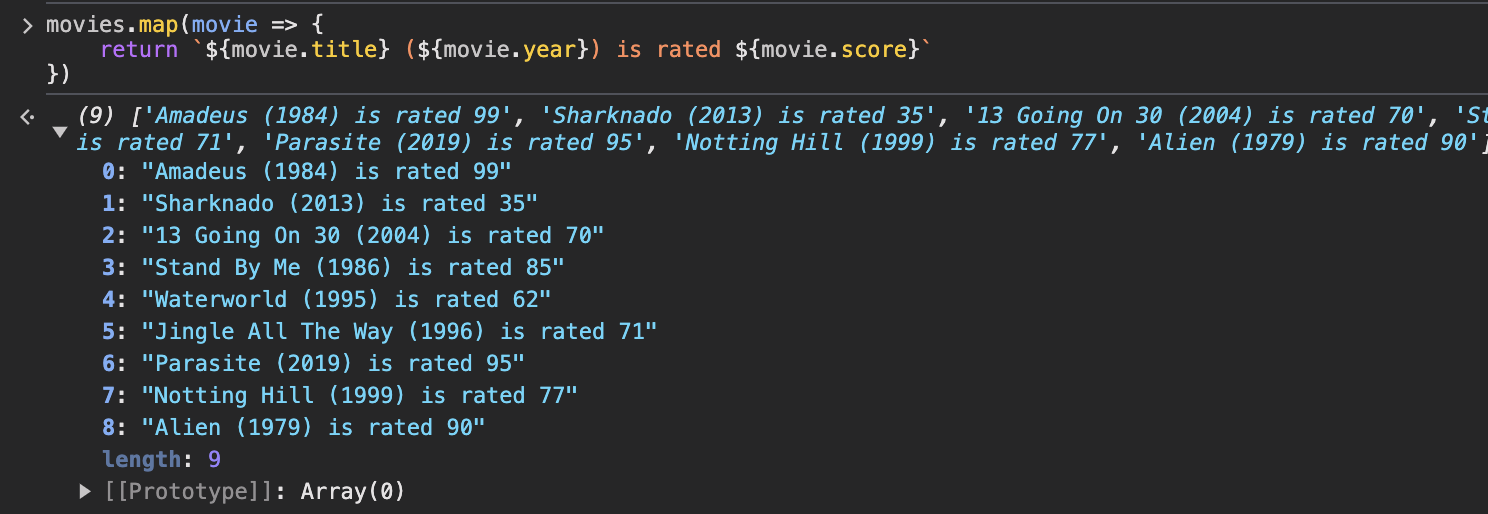
1984년에 개봉한 Amadeus는 99점, 2013년에 개봉한 Sharknado는 35점입니다. 원하는 대로 잘 나왔네요.
구조 분해를 이용해 이 코드를 더 짧게 만들어 봅시다. 다시 한번 구조 분해를 위해 중괄호를 입력하고 title, score, year 특성의 이름을 넣겠습니다. 객체 이름인 movies는 지웁니다.

이 코드로 앞서와 같은 결과를 얻을 수 있을 겁니다. 코드의 길이가 짧아지고 구성이 간소해졌으니 더 나은 작성법입니다.
지금까지 구조 분해를 살펴봤습니다.
구조 분해는 말 그대로 배열과 객체를 분해하는 데 도움을 줍니다. 배열의 요소나 객체의 특성값을 끌어내 활용할 수 있죠. 함수의 매개 변수에도 똑같이 적용할 수 있습니다.
이로써 훨씬 효율적으로 코드를 작성할 수 있습니다. 그저 괄호를 활용하는 것만으로요.
원본 강의 보러 가기 https://url.kr/37pfmk
©️요즘IT의 모든 콘텐츠는 저작권법의 보호를 받는 바, 무단 전재와 복사, 배포 등을 금합니다.