개발
Ollama에 없는 모델 내가 만들어 사용하기 (2)

7분
2024.09.06.8.2K
K8sGPT는 쿠버네티스와 대규모언어모델(이하 LLM)을 결합해 만들어진 오픈소스 프로젝트입니다. 쿠버네티스 클러스터의 정보를 스캐닝하여 이슈를 발견하고, 그 이슈의 원인과 결과, 해결 방안을 알려 줍니다.
이 프로젝트는 처음에는 오픈소스 LLM과 함께 시작했지만, 이제 직접 접근하고 관리할 수 있는 AI 제공자를 구성해 활용하는 기능을 제공합니다. 따라서 데이터가 노출되는 것을 우려하거나 환경에 따라 또는 토큰을 크게 쓰고 싶은 경우, 로컬에서 LLM 환경을 만들고 이를 적용할 수 있습니다.
*참고 글: 로컬 LLM에서 K8sGPT로 쿠버네티스 AIOps 실행하기 (1부, 2부)
구성을 위해 필요한 것은 AI 모델의 실행과 해당 모델에게 요청할 API 주소, 두 가지입니다. 이때 권장하는 도구는 바로 Ollama입니다. 이번 기고에서는 Ollama의 create 명령을 사용해 내가 필요한 모델을 활용하는 방법을 알아보겠습니다. 꼭 K8sGPT를 활용하지 않더라도 Ollama 활용법에 관심이 있는 분들에게 도움이 될 것으로 기대합니다. 작업 순서는 아래와 같습니다.
- 공개된 모델 내려받기
- 파이토치(PyTorch) 프레임워크를 사용한 모델을 GGUF 포맷으로 변환하기
- 기본 f16으로 생성된 GGUF 모델을 Q5_K_M으로 양자화
- Ollama의 create 명령을 사용해 모델 추가하기
- Ollama에 추가된 모델을 K8sGPT 분석에 사용하기
앞서 1부 글에서는 모델을 내려받아 Ollama에 활용하기 좋게 변환하는 3단계까지 작업을 진행했습니다. 이번 2부 글에서는 본격적으로 Ollama create 명령을 활용해 모델을 추가하는 것부터 시작합니다.

Ollama에서는 GGUF를 간단하게 불러 곧바로 사용할 수 있습니다. 하지만 더 잘 활용하고 싶은 이들을 위해 모델 파라미터를 변경하고 어느 정도 프롬프트 엔지니어링을 할 수 있는 옵션도 제공됩니다. 이번에는 이 옵션을 함께 활용해 보겠습니다.
우선 양자화된 GGUF 파일을 작업할 디렉터리를 만들어 옮깁니다. 해당 디렉터리의 이름은 현재 모델을 제공한 조직의 이름으로 했습니다.

작업할 디렉터리로 이동해 모델파일(modelfile)을 추가합니다. 모델파일은 Ollama에 모델을 추가하며 변경할 수 있는 다양한 설정을 제공합니다.

Ollama에서는 모델파일이라는 형식으로 모델을 추가합니다. 이때 세부 설정이나 프롬프트 엔지니어링에 가까운 항목을 추가할 수 있습니다.
공식 홈페이지에서 설명하는 핵심 구문은 다음과 같습니다.
FROM에는 GGUF 형식 모델 등 추가하고자 하는 모델의 경로와 이름을 넣습니다.
PARAMETER에서는 모델의 세부 설정을 할 수 있습니다.
이 구문에서는 그 외에도 다양한 파라미터를 제공합니다.
SYSTEM에서는 시스템의 역할을 부여해 모델의 답변을 어느 정도 유도할 수 있습니다. 예를 들면 다음과 같은 형태로도 넣을 수 있습니다.
SYSTEM """You are an assistant designed for question-answering tasks. Use the provided pieces of retrieved context to answer the questions accurately. Ensure that your answers are directly relevant to the questions and cite your sources when possible. Keep your responses concise and within three sentences."""
그 외 TEMPLATE은 Ollama에서 지정한 프롬프트를 위한 템플릿으로, 이는 각 모델마다 다를 수 있습니다. 따라서 모델 제공자의 지시를 따르거나 문법을 충분히 이해하고 고쳐야 합니다. 이에 대한 문법은 이 문서에서 제공하고 있습니다.
다시 실습으로 돌아가, 우리의 모델파일을 만들어 보겠습니다. 모델파일을 만드는 다양한 방법이 있지만, 무에서 유를 창조하는 것보다 조금 더 쉬운 방법으로 진행하겠습니다. 우선 현재 모델의 기준인 llama3:8b를 내려받습니다.
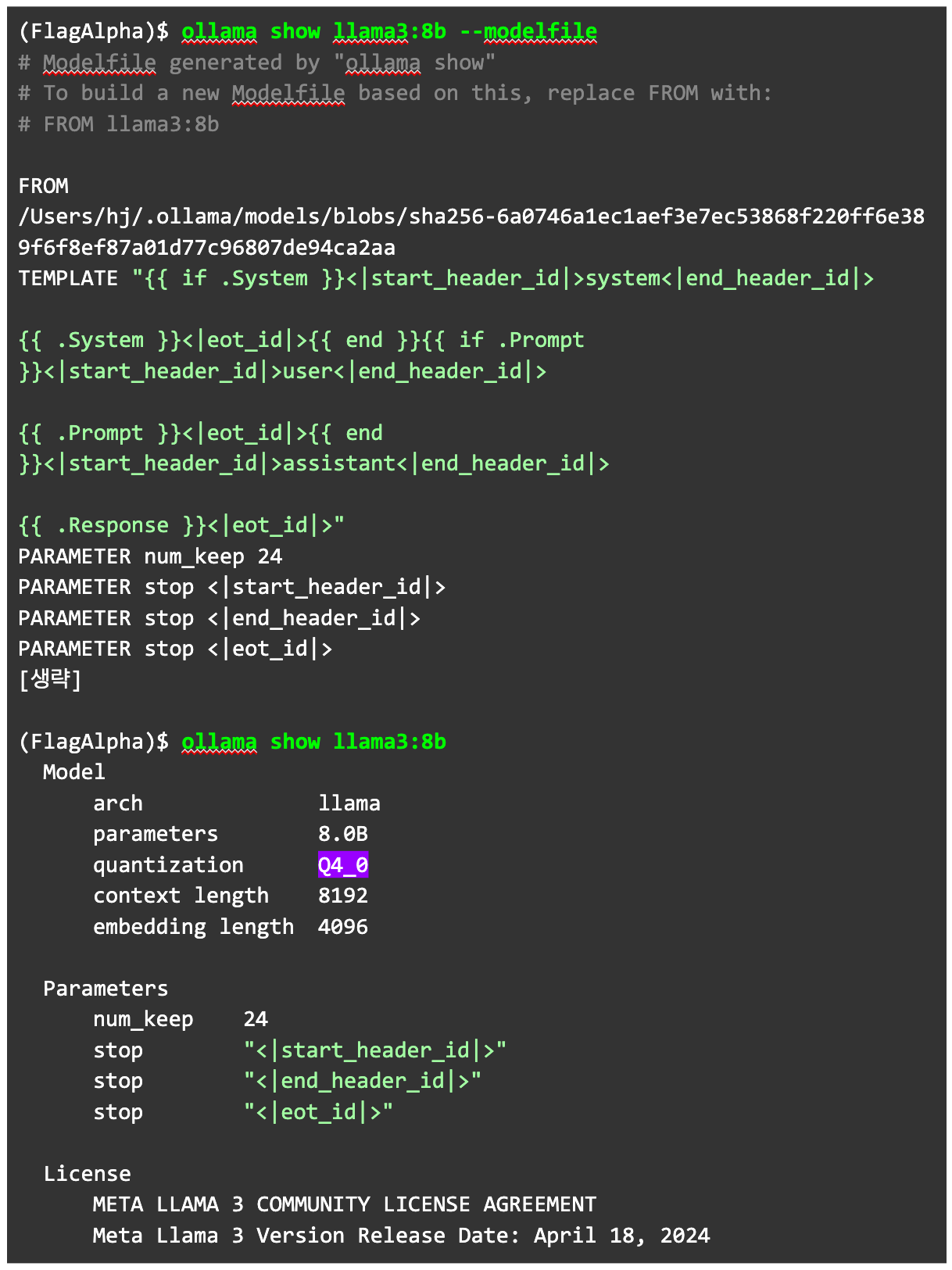
해당 모델에서 사용하고 있는 모델파일을 ollama show <모델> --modelfile 명령으로 추출합니다. 참고로 --modelfile을 넣지 않으면 양자화 정보 등을 확인할 수 있습니다.
기본 모델파일에서 확인된 정보를 바탕으로 만든 모델파일은 아래와 같습니다.
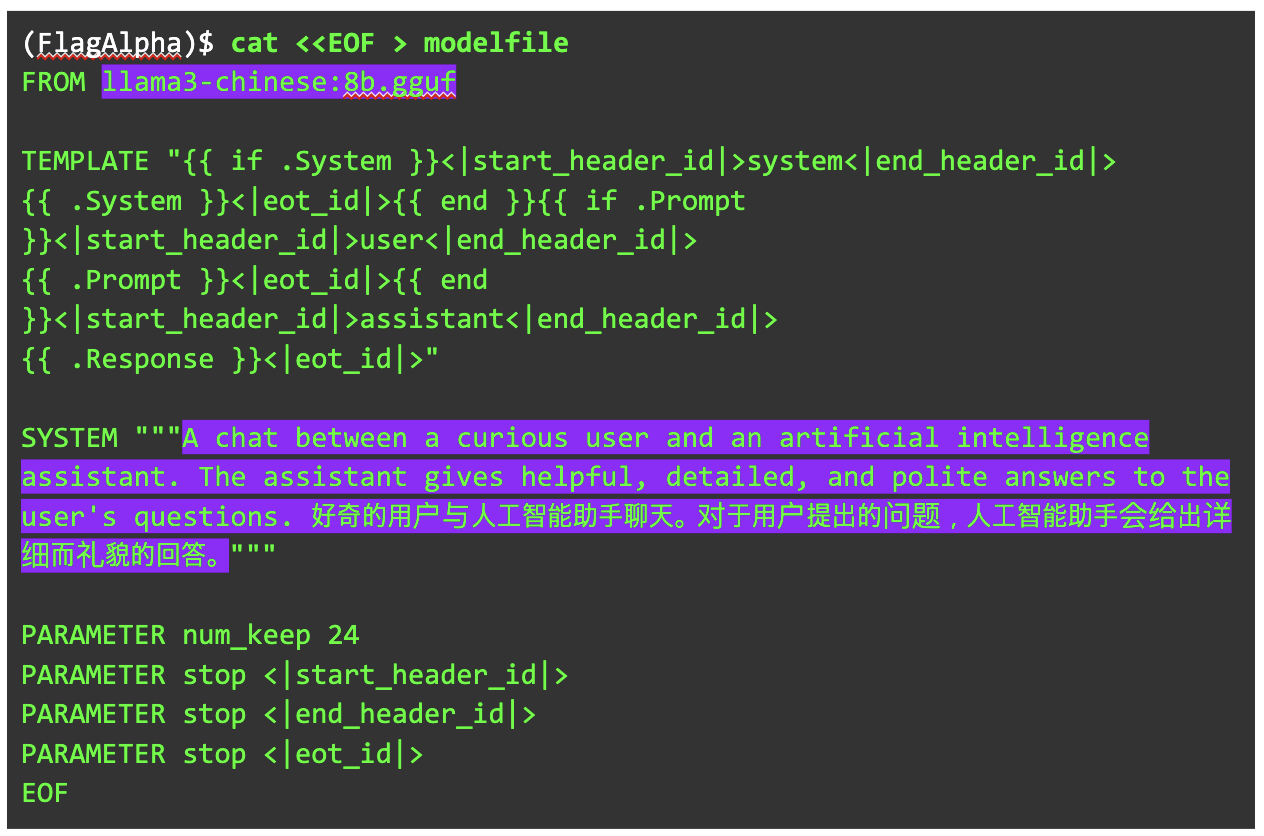
FROM 부분을 변경하고 SYSTEM에 영어와 중국어로 시스템 메시지를 넣었습니다. 여기서 중국어를 추가하지 않으면 중국어에 대한 답변이 나오지 않거나 영어로 답변할 가능성이 높습니다.
이제 세부 설정까지 모두 조정했으니 모델을 추가할 차례입니다. ollama create 명령을 사용해 GGUF로 생성한 모델을 추가합니다. 세부 설정은 새로 만든 모델파일에서 가지고 오도록 -f 옵션을 사용합니다.
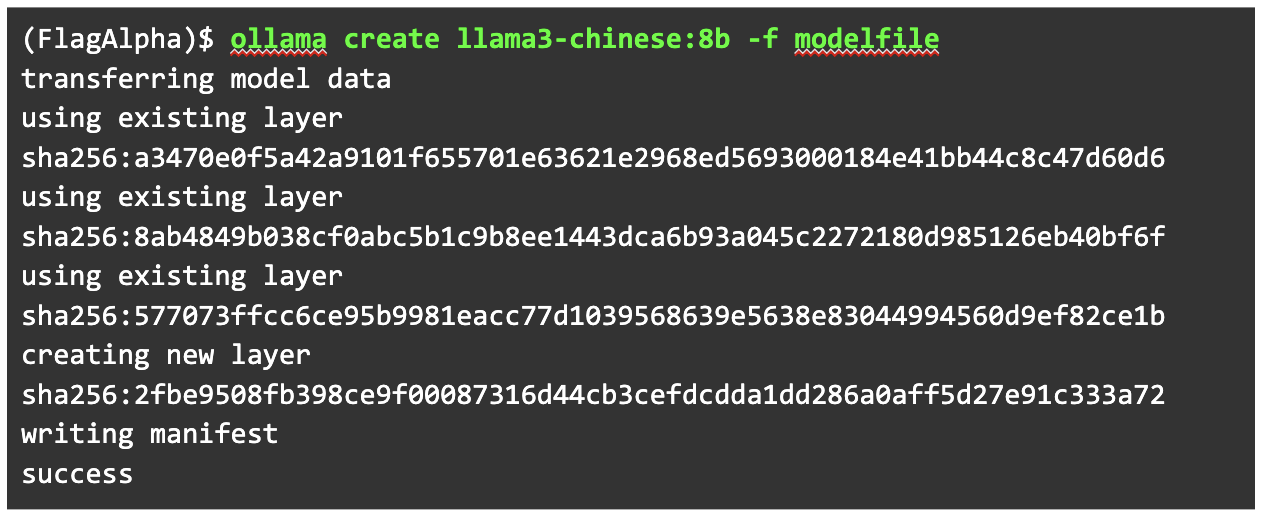
Ollama에 추가된 모델을 확인해 보겠습니다. 우리가 추가한 모델이 제대로 올라와 있습니다.
해당 모델을 활용해 K8sGPT에 질문해 봅시다. 간략한 활용을 위해 직접 만든 run_ollama_n_k8sgpt.sh 명령으로 질문을 시작했습니다. K8sGPT에서 로컬 AI 모델을 활용하는 localai 기능은 앞서 작성한 글을 참고할 수 있습니다. (run_ollama_n_k8sgpt.sh에 대해서는 요청이 많으면 추후에 설명을 고려해 보겠습니다. 간단히 말하면, K8sGPT의 localai 기능을 반복해 사용하기 번거로워 스크립트로 처리했다고 볼 수 있습니다.)
*참고 글: 로컬 LLM에서 K8sGPT로 쿠버네티스 AIOps 실행하기 (1부, 2부)
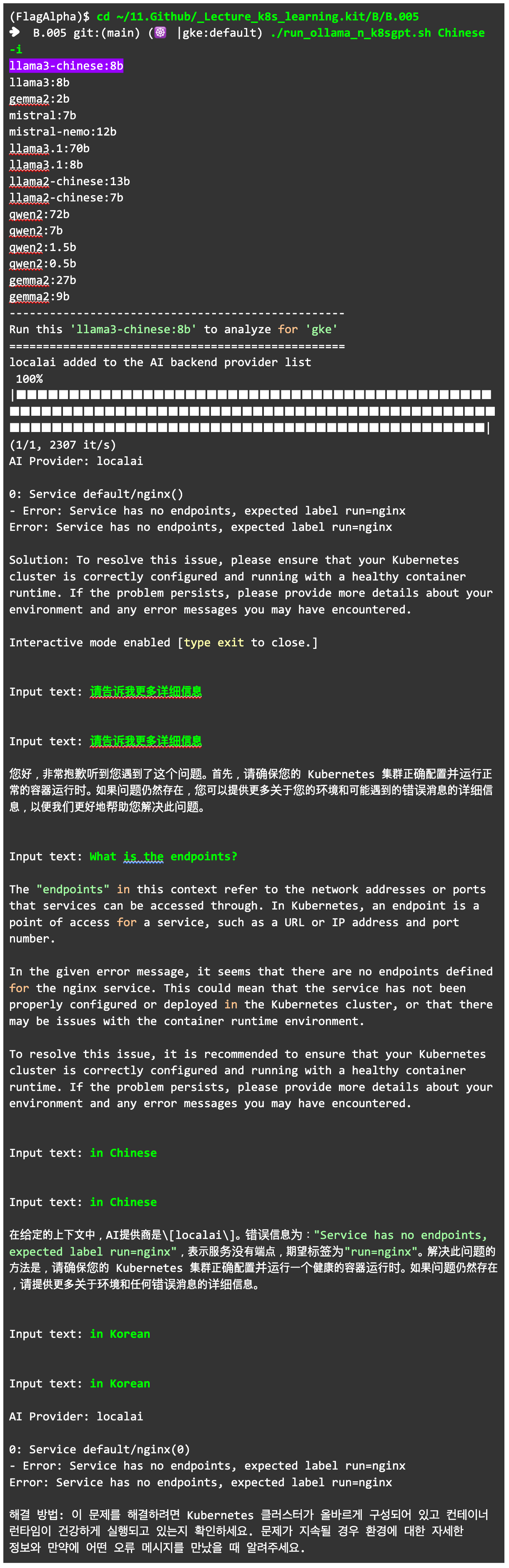
원하는 대로 작동하는 것을 확인했습니다.
지금까지 Ollama에 존재하지 않는 모델을 추가해 K8sGPT에서 사용하는 방법을 확인해 보았습니다.
결괏값에서 나타나듯 사실 대부분의 모델은 파운데이션 모델(대표적인 공개 모델은 llama, gemma, mistral 등)을 그대로 사용하는 것보다 좋은 결과(낮은 펄플렉시티 값)를 만들기 어렵습니다. 그럼에도 최근 K8sGPT처럼 특정 목적을 가진 sLM이 요구되는 만큼, 모델을 직접 붙여 활용해야 하는 시점이 곧 올 것으로 보입니다. 따라서 이와 연관된 기술들을 살펴보고 준비할 필요가 있습니다.
이번 글에서 소개한 내용을 바탕으로 KubeCon China 2024에서 발표하기도 했습니다. 더 자세한 내용이 궁금한 분은 발표 영상을 살펴볼 수 있습니다.
작가
조훈(CNCF 앰버서더)
시스템/네트워크 IT 벤더의 경험 이후, 메가존 GCP 클라우드 팀에서 쿠버네티스와 연관된 모든 프로젝트에 대한 Tech Advisor 및 Container Architecture Design을 제공하고 있다. 페이스북 ‘IT 인프라 엔지니어 그룹’의 운영진을 맡고 있으며, 오픈 소스 컨트리뷰터로도 활동한다. 지식 공유를 위해 인프런/유데미에서 앤서블 및 쿠버네티스에 관한 강의를 하기도 한다. 책 <컨테이너 인프라 환경 구축을 위한 쿠버네티스/도커> 등 3권을 썼다. CNCF(Cloud Native Computing Foundation) 앰버서더로서 쿠버네티스 생태계가 더 활발하게 퍼질 수 있도록 기여하고 있다.
심근우
LG유플러스 CTO부문에서 대고객 비즈니스 시스템의 DevOps를 담당하는 UcubeDAX팀의 팀장으로 일하고 있다. 퍼블릭 클라우드와 프라이빗 클라우드에 걸친 쿠버네티스 클러스터를 안정적으로 운영하기 위해 노력하고 있으며, 특히 주니어 DevOps 엔지니어들의 육성에 큰 관심을 가지고 있다.
문성주
체커(CHEQUER) 사의 DevOps Engineer로서 쿠버네티스의 멀티 클러스터 관리 방법론과 쿠버네티스 구현체(CAPI, OCI)에 대한 명세와 컨테이너 리소스 격리 방법에 대한 연구를 병행하고 있다. 이런 연구 활동을 기반으로 쿠버네티스 볼륨 테스트 파트에 컨트리뷰션했다. 본업은 쿠버네티스 오퍼레이터와 같은 CRD(커스텀 리소스)를 개발해 현업에서 쿠버네티스를 좀 더 편리하게 사용할 수 있도록 돕는 일이다. 또한, 페이스북 그룹 ‘코딩이랑 무관합니다만'과 ‘IT 인프라 엔지니어 그룹'의 운영진을 맡고 있다.
이성민
미국 넷플릭스(Netflix) 사의 Data Platform Infrastructure 팀에서 사내 플랫폼 팀들과 데이터 사용자들을 어우르기 위한 가상화 및 도구들을 개발하는 일들을 하고 있다. 과거 컨테이너와 쿠버네티스에 큰 관심을 두고 ingress-nginx를 비롯한 오픈 소스에 참여했으며, 현재는 데이터 분야에 일하게 되면서 stateful 한 서비스들이 컨테이너화에서 겪는 어려움을 보다 근본적으로 해결하기 위한 많은 노력을 하고 있다.
©️요즘IT의 모든 콘텐츠는 저작권법의 보호를 받는 바, 무단 전재와 복사, 배포 등을 금합니다.