개발
Ollama에 없는 모델 내가 만들어 사용하기 (1)

8분
2024.09.06.8.2K
K8sGPT는 쿠버네티스와 대규모언어모델(이하 LLM) GPT를 결합해 만들어진 오픈소스 프로젝트입니다. 쿠버네티스 클러스터의 정보를 스캐닝하여 이슈를 발견하고, 그 이슈의 원인과 결과, 해결 방안을 알려 줍니다.
이 프로젝트는 처음에는 오픈소스 LLM과 함께 시작했지만, 이제 직접 접근하고 관리할 수 있는 AI 제공자를 구성해 활용하는 기능을 제공합니다. 따라서 데이터가 노출되는 것을 우려하거나 환경에 따라 또는 토큰을 크게 쓰고 싶은 경우, 로컬에서 LLM 환경을 만들고 이를 적용할 수 있습니다.
*참고 글: 로컬 LLM에서 K8sGPT로 쿠버네티스 AIOps 실행하기 (1부, 2부)
구성을 위해 필요한 것은 AI 모델의 실행과 해당 모델에게 요청할 API 주소, 두 가지입니다. 이때 권장하는 도구는 바로 Ollama입니다. 로컬 환경에 LLM을 손쉽게 구현하도록 도와주는 도구죠. Ollama에는 llama3.1을 비롯해 다양한 공개 모델들이 매우 빠르게 포팅되어 올라옵니다. 따라서 활용 시 특별히 신경 써야 할 부분은 없습니다.
그럼에도 공개된 LLM 또는 sLM 모델을 모두 받을 수 있는 것은 아닙니다. 이를 위해 Ollama는 필요에 따라 다른 곳에 공개된 모델을 사용할 수 있도록 create 명령을 제공합니다.
따라서 이번 기고에서는 create 명령을 사용하기 위한 절차, 그리고 준비 과정을 살펴보며 전반적인 구조에 대한 이해를 높이려고 합니다. 꼭 K8sGPT를 활용하지 않더라도 Ollama 활용법에 관심이 있는 분들에게 도움이 될 것으로 기대합니다. 작업 순서는 아래와 같습니다.
- 공개된 모델 내려받기
- 파이토치(PyTorch) 프레임워크를 사용한 모델을 GGUF 포맷으로 변환하기
- 기본 f16으로 생성된 GGUF 모델을 Q5_K_M으로 양자화
- Ollama의 create 명령을 사용해 모델 추가하기
- Ollama에 추가된 모델을 K8sGPT 분석에 사용하기
1부 글에서는 내가 활용하고자 하는 모델을 Ollama에 활용하기 좋게 변환하는 작업까지 알아볼 예정입니다.

작업을 진행하려면 아래 도구들이 설치되어 있어야 합니다. (마이너 버전은 시기에 따라 다소 달라질 수 있습니다.)
또한 다음과 같은 구조로 만든 디렉터리를 작업에 활용할 예정입니다.

가장 먼저 해야 할 일은 허깅페이스에서 어떤 LLM을 내려받을 지 결정하는 것입니다.
이번 실습에 활용할 모델은 Llama3-Chinese-8B-Instruct 모델입니다. 그에 앞서 우선 Ollama에 llama2-chinese를 올려둔 곳에서 따로 제공하는 llama3이 있는지 해당 조직 저장소로 이동해 확인해 봅니다. 저장소에 아래 이미지처럼 Llama3-Chinese-8B-Instruct이 있는 것을 확인할 수 있습니다.
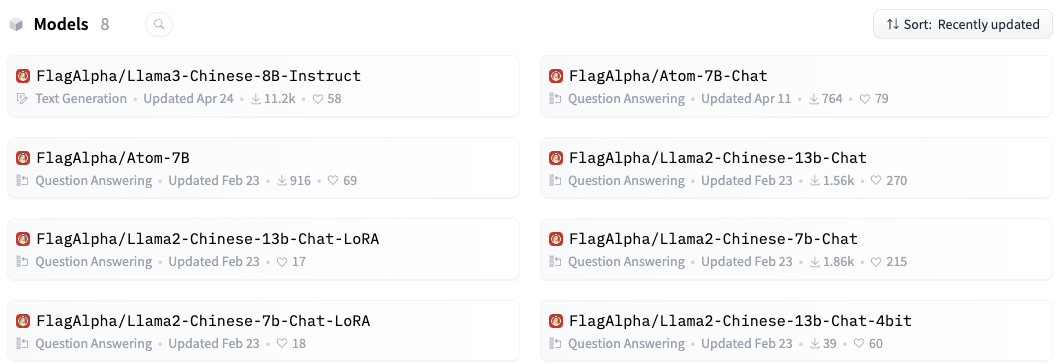
다음으로는 페이지에서 어떤 포맷으로 모델을 제공하는 지 확인해야 합니다. 모델이 세이프텐서(safetensor) 포맷으로 제공되는 것을 확인했습니다. 참고로 허깅페이스에서 제공하는 모델은 대부분 세이프텐서 형태로 제공합니다.
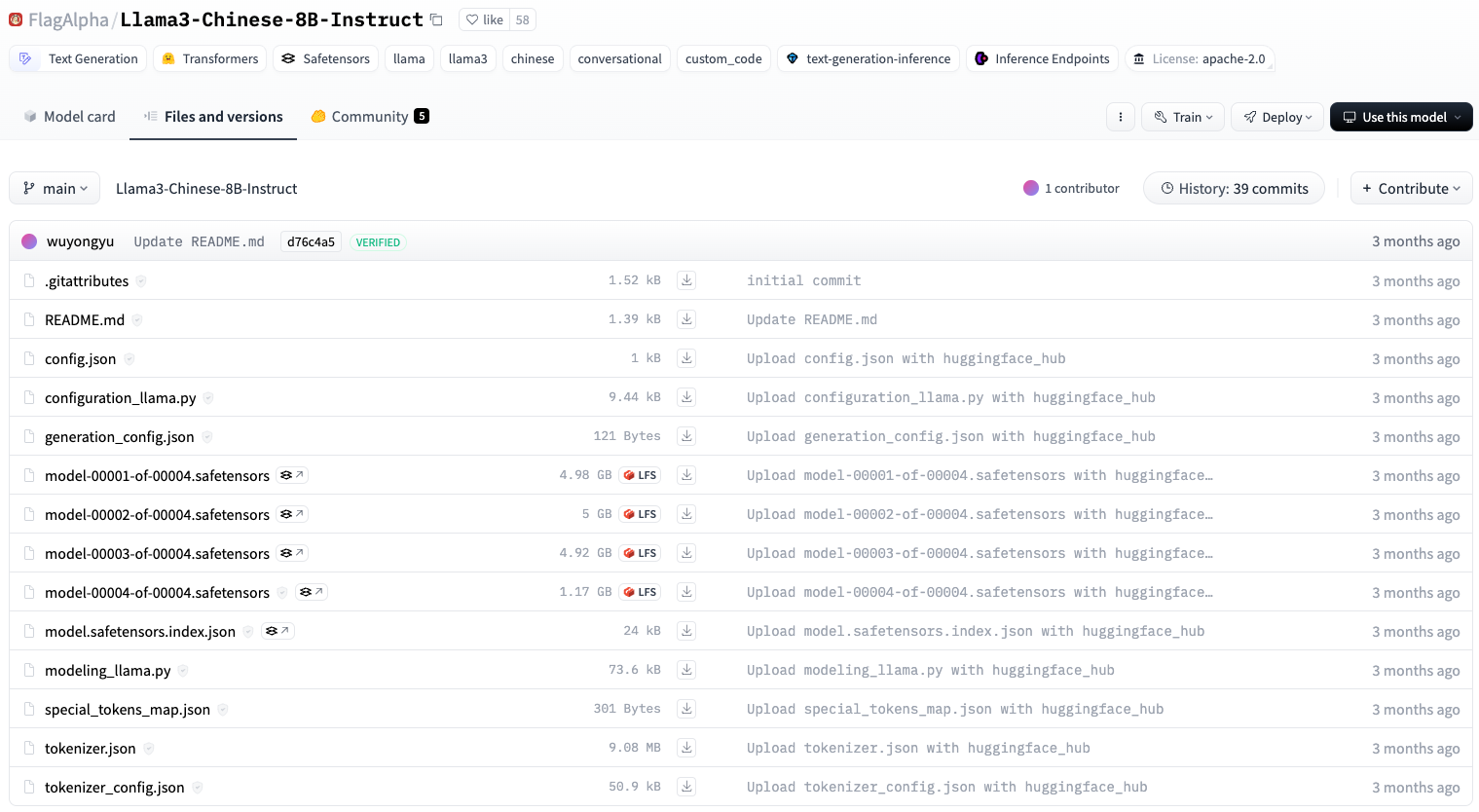
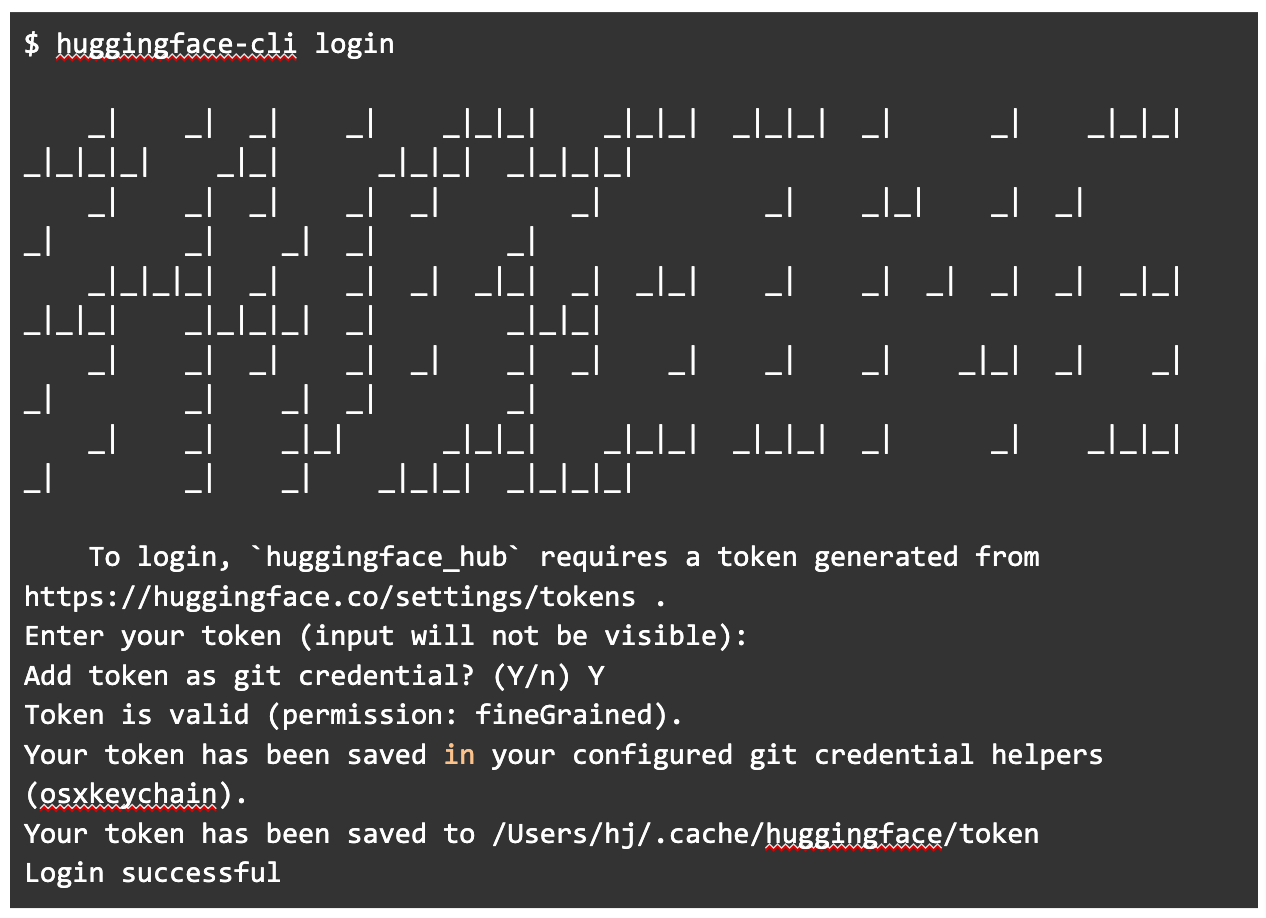
해당 모델을 내려받으려면 huggingface-cli login 명령어로 허깅페이스에 로그인을 해야 합니다. 허깅페이스 로그인 토큰을 받으려면 마찬가지 허깅페이스 공식 문서를 참고할 수 있습니다.
이제 허깅페이스에서 모델을 내려받기 위해 주소를 웹 페이지에서 복사합니다.
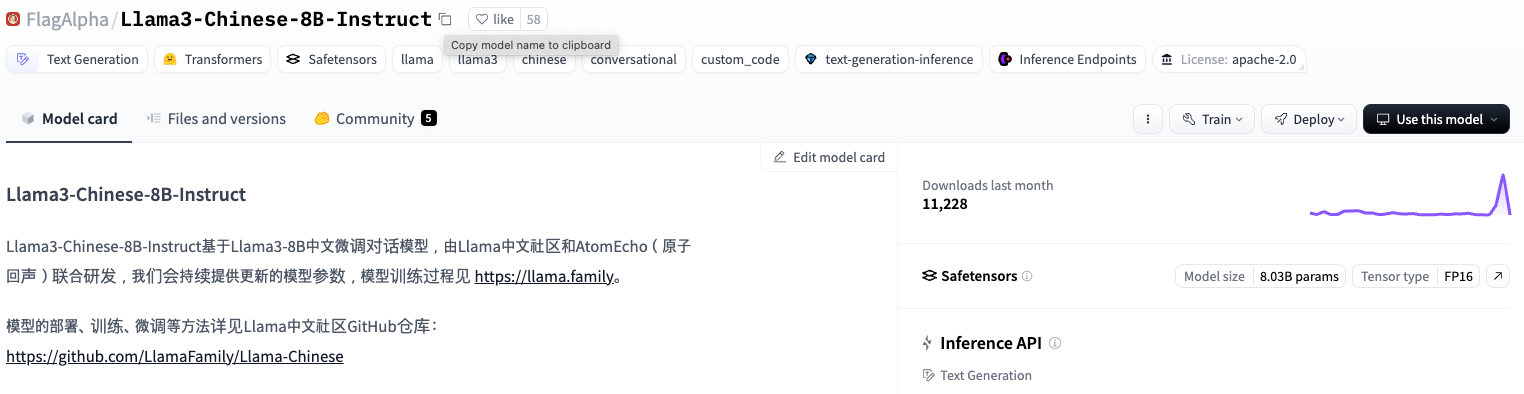
모델 다운로드에는 download 명령을 활용합니다. 내려받는 주소를 정확하게 지정해 받기 위해 --local-dir 명령어도 함께 활용했습니다.
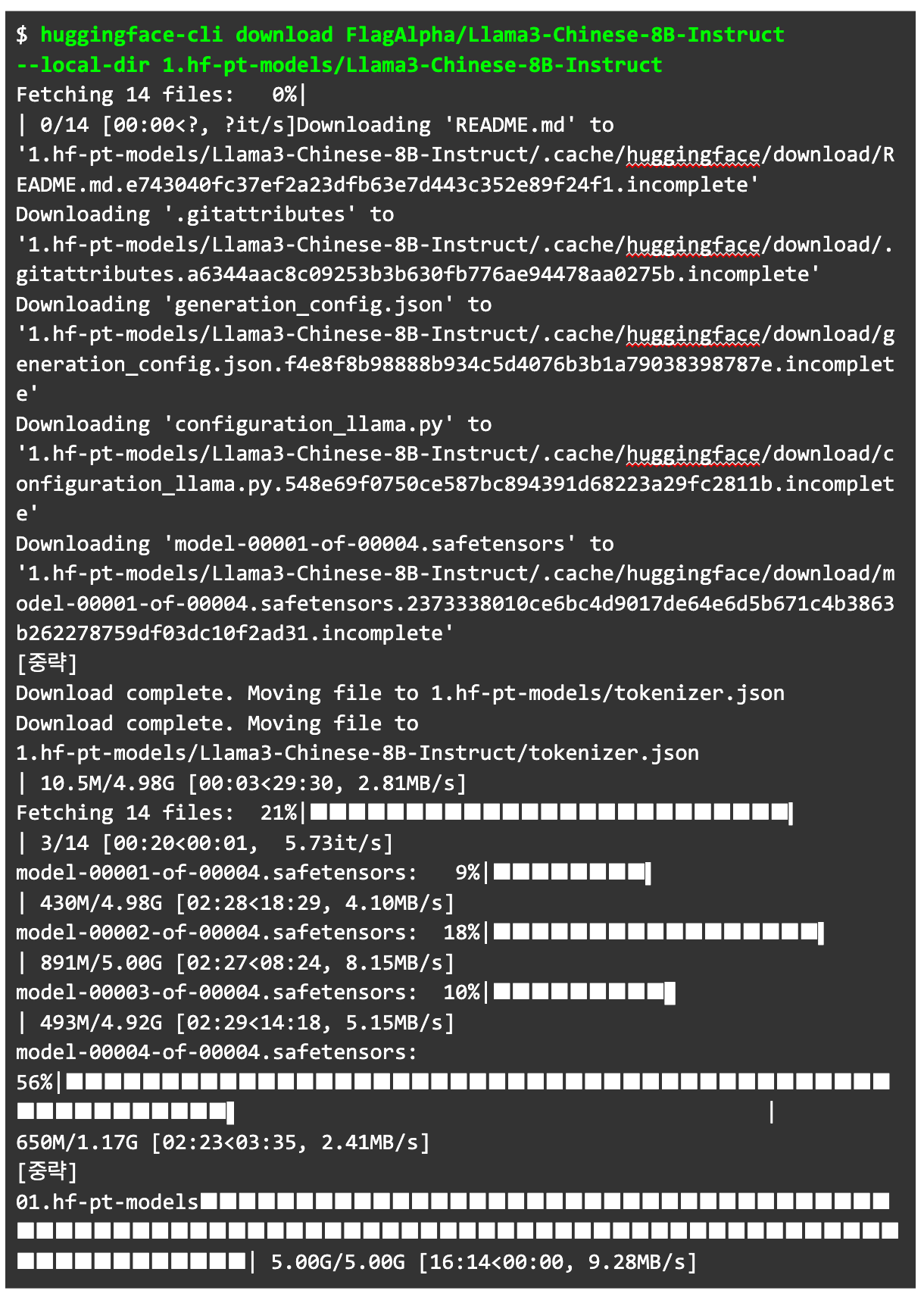
다운로드가 끝난 다음, 내려받은 모델과 관련 파일을 확인합니다.

앞서 확인했듯 허깅페이스에서 내려받은 모델은 세이프텐서(safetensors) 형식입니다. 허깅페이스에서 배포되는 모델이 주로 세이프텐서를 쓰는 주된 이유는 pt(PyTorch) 모델의 가중치에 악성코드가 포함될 수 있는 위험을 줄이기 위해서입니다. 아울러 이 형식은 효율적인 직렬화 및 압축 알고리즘으로 대용량 텐서의 크기를 줄여 줍니다.
*세이프텐서에 대한 자세한 내용은 safetensors, 세이프텐서 로드, 세이프티 센서 소개 문서를 참고해 보세요.
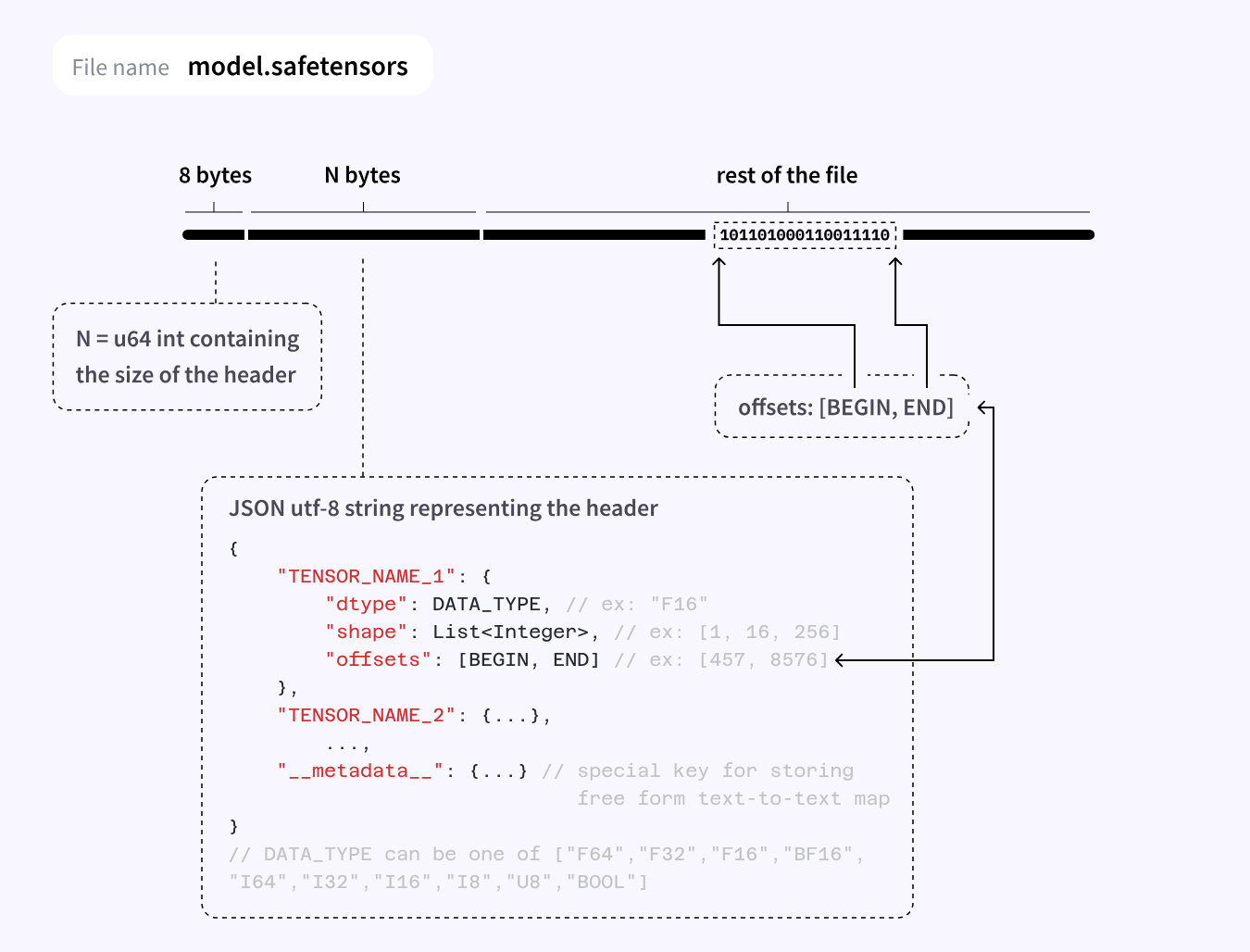
하지만 세이프텐서 형식의 모델을 Ollama에서는 사용할 수 없습니다. Ollama에서 주로 추가해서 사용하는 파일 형식은 GGUF(GPT-Generated Unified Format)입니다.
2023년 8월 공개된 GGUF는 딥러닝 모델을 단일 파일로 저장하기 위해 사용됩니다. GGUF 등장 이전에는 GGML(GPT-Generated Model Language)이라는 파일 형식을 주로 활용했습니다. 다만 GGML은 모델에 추가 정보를 넣기 어렵다는 점, 모델 간의 호환성 문제, 그리고 rope-freq-base와 같은 값을 자주 바꿔줘야 하는 문제 등이 있었습니다. GGUF는 이를 개선한 형식으로 현재 시점에서 모델 저장을 위해 널리 쓰이고 있습니다.
*GGML과 GGUF 모두 Georgi Gerganov(@ggerganov)의 주도로 만들어졌습니다. 두 가지 형식의 상세한 차이가 궁금한 분은 문서1, 문서2를 참고하세요.
GGUF 파일은 아래 이미지와 같은 세부 정보를 1개의 파일에 모두 담고 있습니다.

따라서 Ollama에서 세이프텐서 형식의 모델을 쓰려면 GGUF로 변환하는 과정이 필요합니다. 변환을 위해서는 GGUF 형식 개발을 주도한 개발자가 직접 만든 llama.cpp 프로젝트의 도움을 받는 것이 편리합니다. 특히 해당 프로젝트는 단순히 GGUF 변환 뿐만 아니라 다양한 종류의 양자화(Quantization)도 제공하고 있어 CPU와 메모리가 부족한 기기에서도 모델이 동작할 수 있게 해줍니다.
이제 본격적으로 변환 과정을 따라가 보겠습니다.
우선 가장 먼저 llama.cpp 프로젝트를 git clone 명령어로 로컬에 내려받습니다.
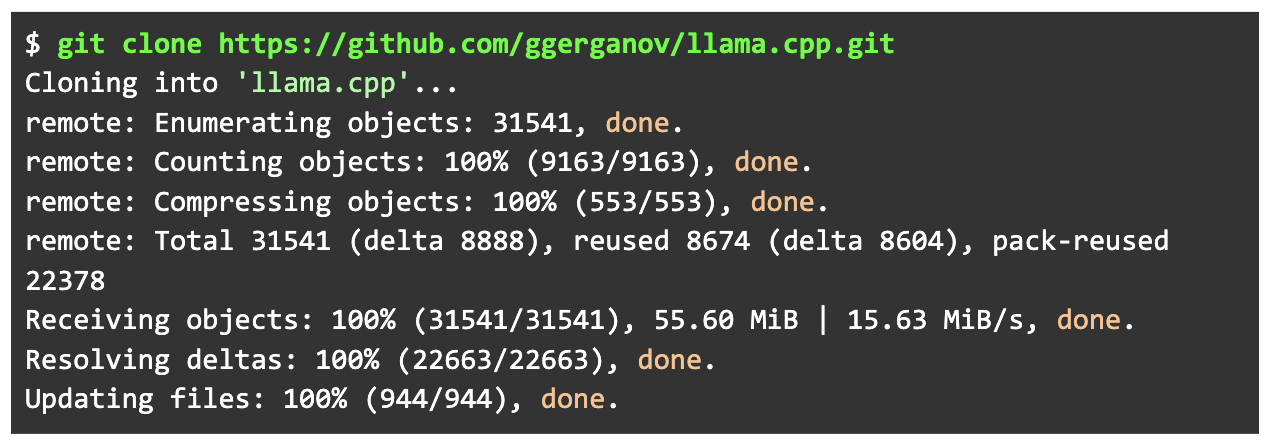
곧이어 llama.cpp 프로젝트 구동을 위한 파이썬 관련 패키지를 pip3로 설치합니다.
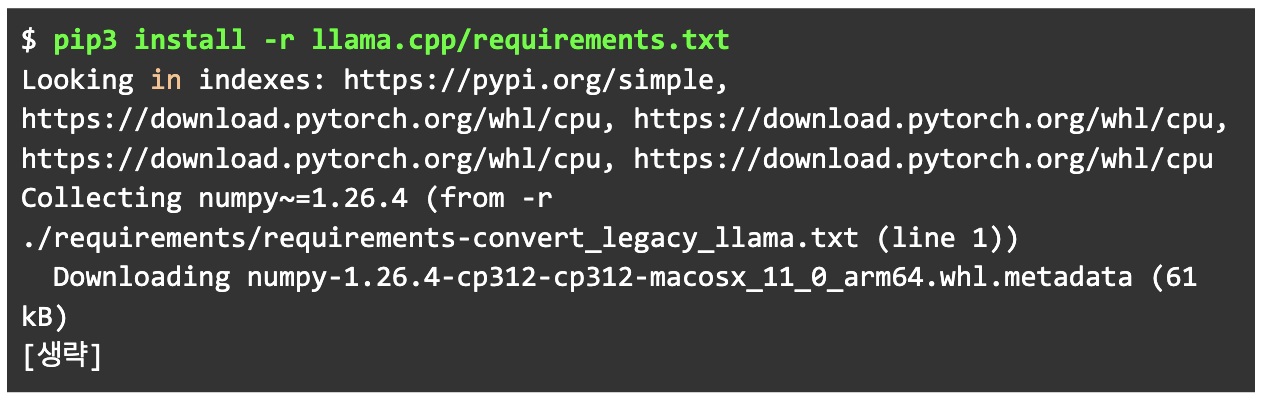
설치가 끝나면 llama.cpp에 미리 작성된 convert_hf_to_gguf.py를 이용해 f16(float16) 수준의 gguf를 생성합니다. 하단의 2.f16-modes 디렉터리는 미리 만들어져 있습니다. 단순 파일로도 변환할 수 있습니다.
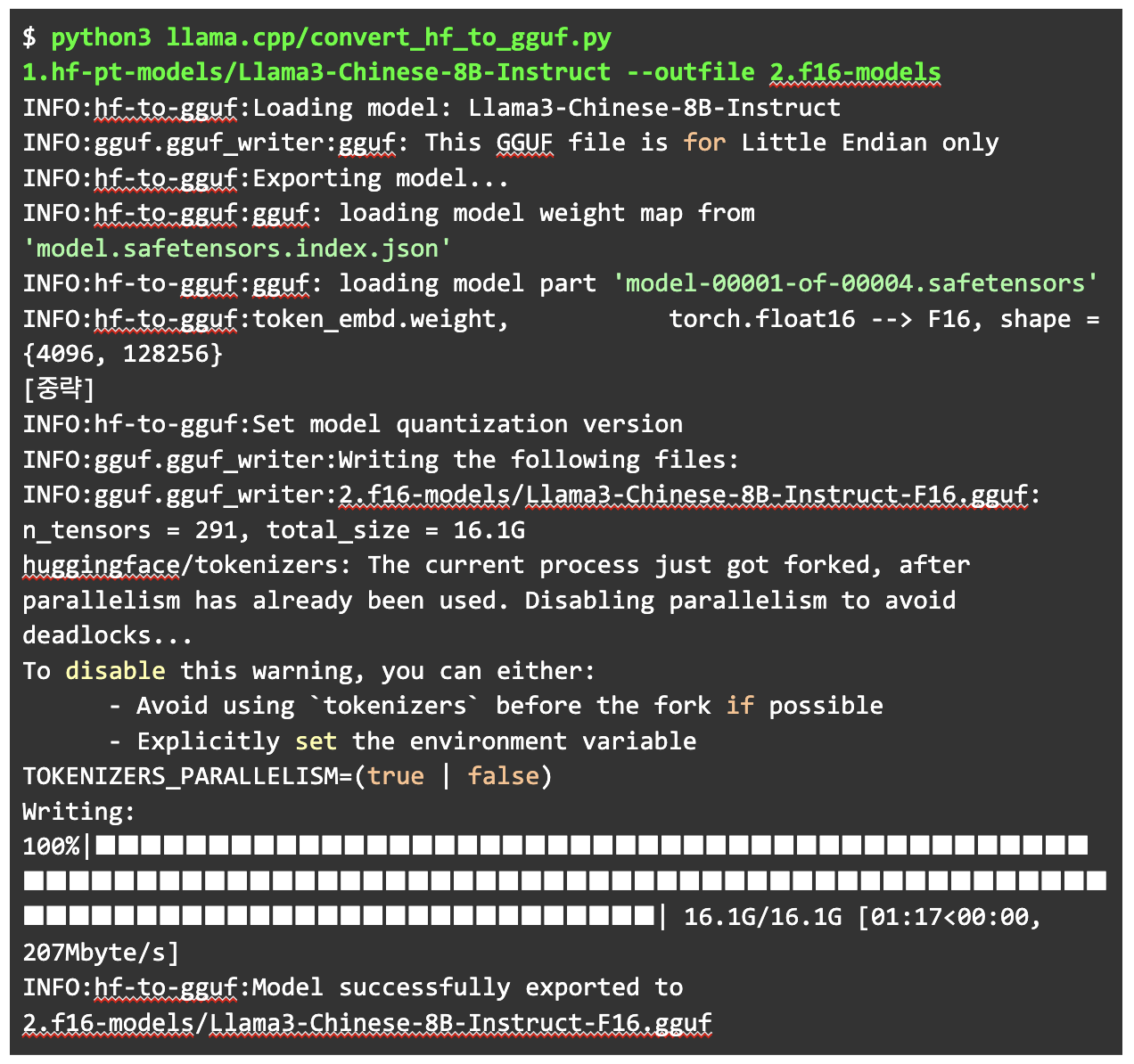
생성된 gguf 파일과 그 파일의 사이즈를 확인합니다.

문제가 없다면, 양자화(Quantization)를 진행해 보겠습니다. 다만 convert_hf_to_gguf.py 명령에서는 양자화 옵션을 f32,f16, bf16, q8_0, auto만 제공합니다. 좀 더 나은 양자화 방법이 필요해 보입니다.
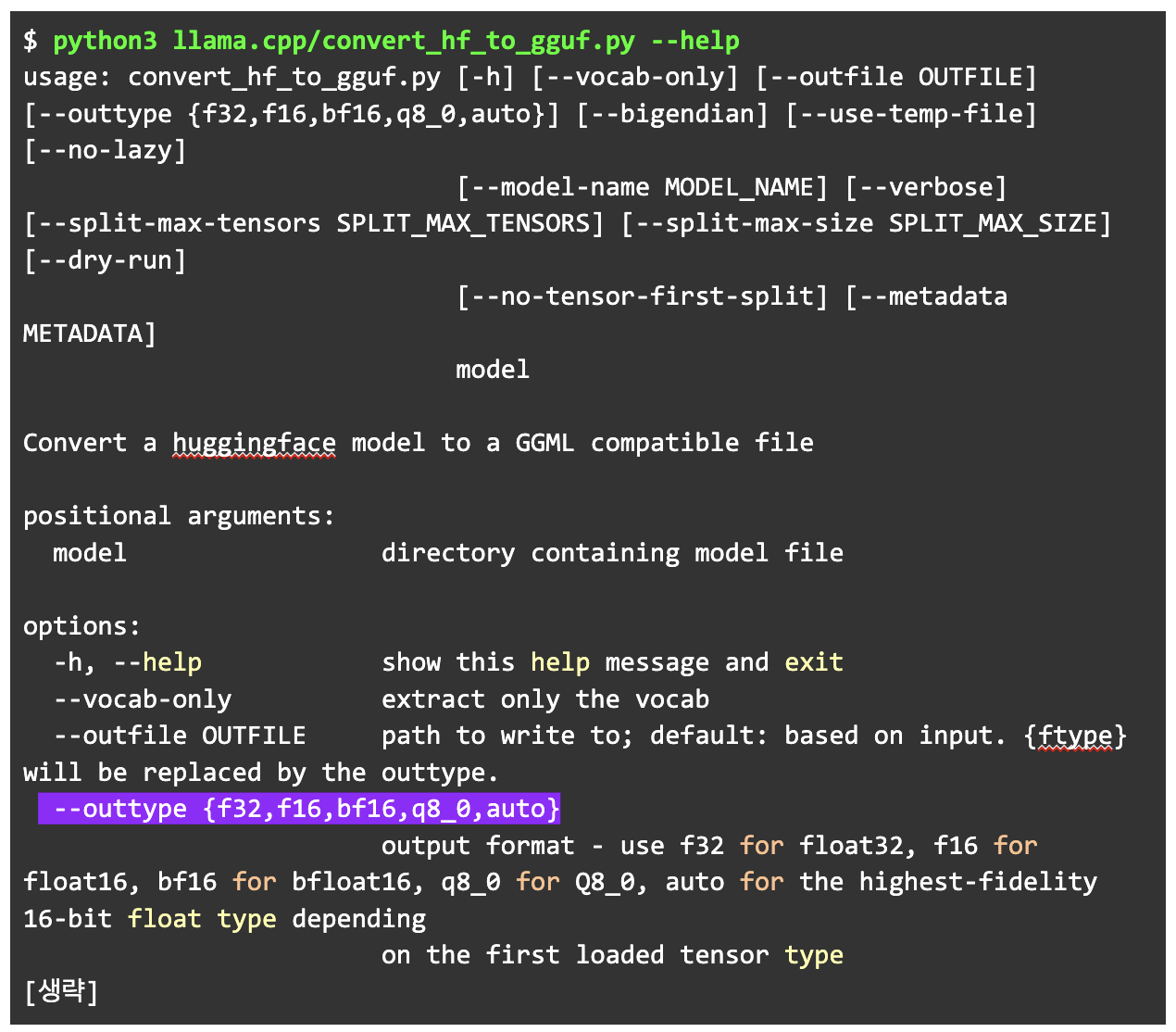
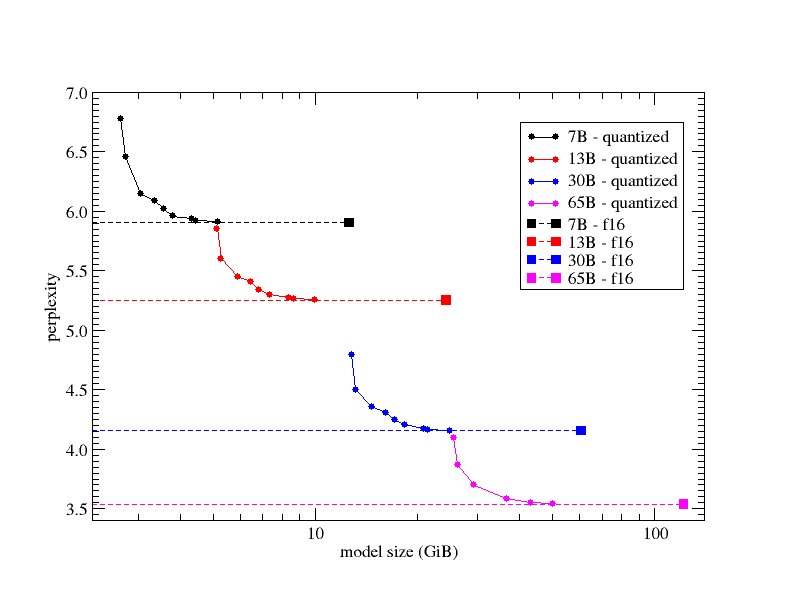
양자화(Quantization)란 모델의 성능을 일정 수준 유지하면서도 사이즈와 동작에 필요한 리소스를 효과적으로 줄이기 위해 가장 많이 쓰이는 방법 중 하나입니다. 현재 기본값인 f16은 용량이 다소 큰 편으로 허깅페이스에서 배포된 모델은 여러 종류의 양자화 모델을 함께 제공합니다.
양자화로 모델의 비트가 낮아지면 일반적으로 정확도가 내려갑니다. 하지만 그만큼 용량이 줄어 들어 모델을 동작할 때 필요한 리소스를 줄일 수 있습니다.
허깅페이스에서 배포되는 대부분 모델은 README 문서에서 레벨을 Q5라고 소개합니다. 그 외 K_M, K-L 등 표기로 레벨을 더 자세히 알려 줍니다. 여기서 K는 양자화에 K-평균 알고리즘(means clustering)을 활용했음을, 그 다음 대문자는 모델의 사이즈를 의미합니다. S(Small)와 M(Medium), 그리고 L(Large)을 사용합니다.
*양자화에 대해서는 이 문서도 함께 보면 좋습니다.
양자화 모델 중 주로 사용하는 것은 Q5_K_M입니다. 언어 모델의 주요 성능 지표인 펄플렉시티(perplexity, PPL)*이 허용 가능한 수준이며 모델의 사이즈도 적게 만든 모델이기 때문입니다.
*펄플렉시티(perplexity, PPL): 문장을 생성할 때 선택해야 하는 가짓수가 많을수록 모델은 혼란을 겪습니다. 잘 학습된 모델일수록 이러한 가짓수가 적습니다. 따라서 모델의 혼란스러움을 나타내는 수치가 낮은 것, 즉 펄플렉시티가 낮을수록 성능이 좋다고 볼 수 있습니다.
따라서 이번에도 역시 기본 제공 양자화 외에 추가로 작업해 Q5_K_M를 만들어 보겠습니다. 이를 위해 llama.cpp 디렉터리에서 make를 실행합니다. 해당 명령으로 플랫폼에 맞는 다양한 명령어가 생성되는데, 그 중 llama-quantize를 사용하겠습니다. 참고로 새로 생성되는 명령어는 llama-로 시작됩니다.
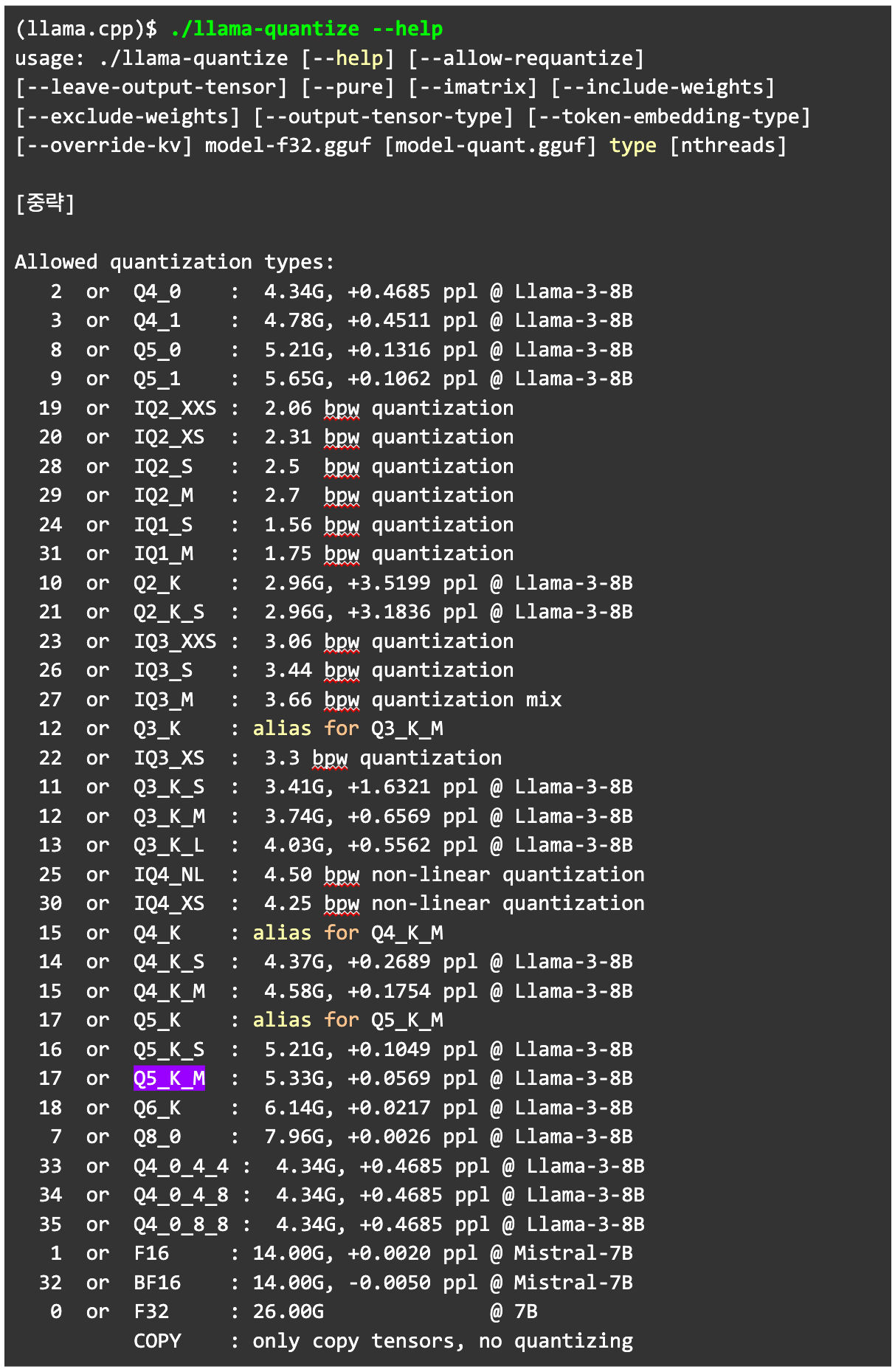
llama-quantize 명령어를 실행하기 전에 --help 명령어로 허용되는 양자화 타입을 확인합니다. Q5_K_M이 존재하는 것을 확인합니다.
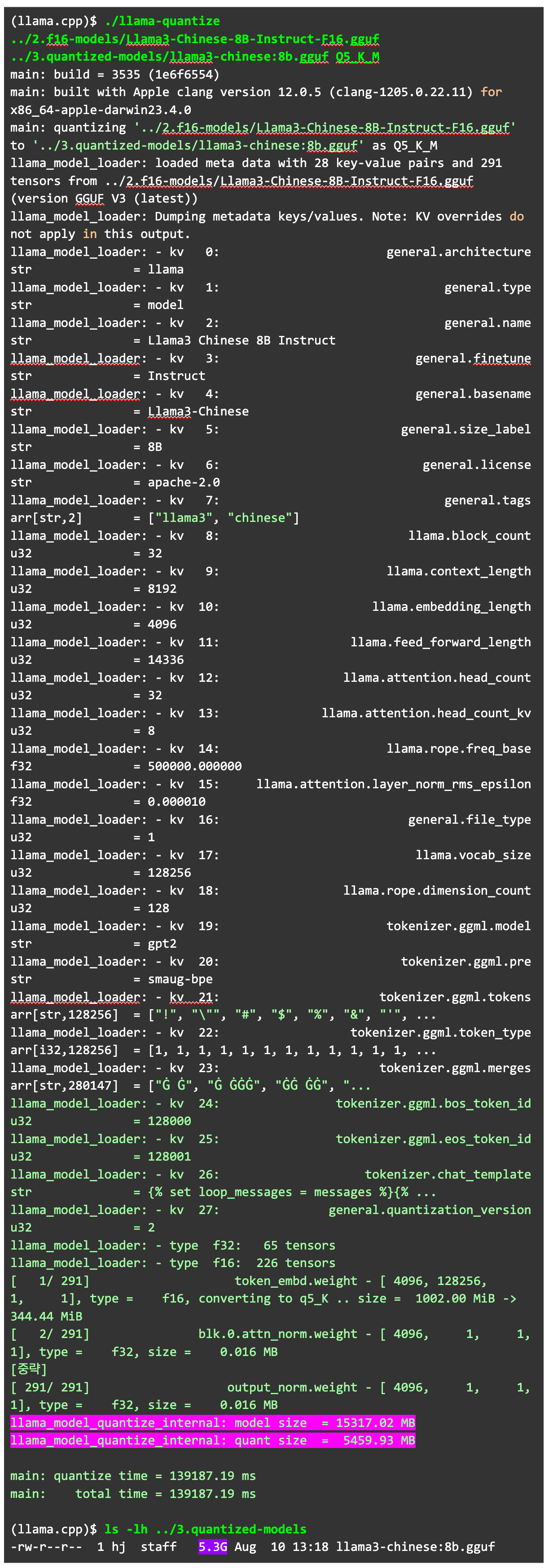
f16으로 양자화 되어 있는 gguf 파일을 Q5_K_M으로 변환했습니다. 변환 후에 줄어든 용량도 확인해 보겠습니다.
지금까지 Ollama에 없는 모델을 직접 만들어 사용하기 위한 준비를 거쳤습니다. 허깅페이스에서 대상 모델을 다운로드받고 활용에 적합한 GGUF 파일로 변환했습니다. 여기에 양자화로 모델을 활용에 적합한 사이즈로 만들기도 했습니다.
다음 글에서는 본격적으로 해당 모델을 Ollama에서 불러 사용하는 법을 다루겠습니다. K8sGPT에 이 모델을 적용하는 방법도 함께 보겠습니다.
작가
조훈(CNCF 앰버서더)
시스템/네트워크 IT 벤더의 경험 이후, 메가존 GCP 클라우드 팀에서 쿠버네티스와 연관된 모든 프로젝트에 대한 Tech Advisor 및 Container Architecture Design을 제공하고 있다. 페이스북 ‘IT 인프라 엔지니어 그룹’의 운영진을 맡고 있으며, 오픈 소스 컨트리뷰터로도 활동한다. 지식 공유를 위해 인프런/유데미에서 앤서블 및 쿠버네티스에 관한 강의를 하기도 한다. 책 <컨테이너 인프라 환경 구축을 위한 쿠버네티스/도커> 등 3권을 썼다. CNCF(Cloud Native Computing Foundation) 앰버서더로서 쿠버네티스 생태계가 더 활발하게 퍼질 수 있도록 기여하고 있다.
심근우
LG유플러스 CTO부문에서 대고객 비즈니스 시스템의 DevOps를 담당하는 UcubeDAX팀의 팀장으로 일하고 있다. 퍼블릭 클라우드와 프라이빗 클라우드에 걸친 쿠버네티스 클러스터를 안정적으로 운영하기 위해 노력하고 있으며, 특히 주니어 DevOps 엔지니어들의 육성에 큰 관심을 가지고 있다.
문성주
체커(CHEQUER) 사의 DevOps Engineer로서 쿠버네티스의 멀티 클러스터 관리 방법론과 쿠버네티스 구현체(CAPI, OCI)에 대한 명세와 컨테이너 리소스 격리 방법에 대한 연구를 병행하고 있다. 이런 연구 활동을 기반으로 쿠버네티스 볼륨 테스트 파트에 컨트리뷰션했다. 본업은 쿠버네티스 오퍼레이터와 같은 CRD(커스텀 리소스)를 개발해 현업에서 쿠버네티스를 좀 더 편리하게 사용할 수 있도록 돕는 일이다. 또한, 페이스북 그룹 ‘코딩이랑 무관합니다만'과 ‘IT 인프라 엔지니어 그룹'의 운영진을 맡고 있다.
이성민
미국 넷플릭스(Netflix) 사의 Data Platform Infrastructure 팀에서 사내 플랫폼 팀들과 데이터 사용자들을 어우르기 위한 가상화 및 도구들을 개발하는 일들을 하고 있다. 과거 컨테이너와 쿠버네티스에 큰 관심을 두고 ingress-nginx를 비롯한 오픈 소스에 참여했으며, 현재는 데이터 분야에 일하게 되면서 stateful 한 서비스들이 컨테이너화에서 겪는 어려움을 보다 근본적으로 해결하기 위한 많은 노력을 하고 있다.
©️요즘IT의 모든 콘텐츠는 저작권법의 보호를 받는 바, 무단 전재와 복사, 배포 등을 금합니다.