개발
MySQL 콜레이션은 어떻게 동작할까?

8분
2024.08.28.8.8K
IT 지식이 무엇보다 중요해진 요즘, 여러분은 어떻게 공부하고 있나요? 가장 먼저 눈길이 가는 건 다양한 IT 강의 영상일 겁니다. 강의를 제공하는 교육 기업들과 함께, 요즘IT에서 ‘IT 강의 시리즈’를 준비했습니다. 엄선한 교육 영상을 TEXT로 읽고 필요한 정보를 빠르게 가져가세요.
이번 강의는 ‘Real MySQL’입니다. 당근마켓 인프라실 DB팀에서 DBA로 근무하는 이성욱, 백은빈 님이 강의를 맡았습니다. MySQL 8.0 버전을 중심으로 실무에 바로 적용할 수 있는 MySQL 활용법을 다루고 있죠. 전체 영상은 인프런에서 확인할 수 있습니다.

이번 글에서는 MySQL의 콜레이션에 대해 살펴보려고 합니다. 전반적인 개요와 함께 MySQL 8.0에 새롭게 추가된 콜레이션들을 위주로 어떻게 동작하는지, 동작 방식과 주의해야 할 사항을 총 2편에 걸쳐 알아보겠습니다.
먼저 콜레이션은 무엇인지 간단하게 살펴보겠습니다. 콜레이션은 문자를 비교하거나 정렬할 때 사용되는 규칙을 말합니다. 이 규칙은 문자가 어떻게 서로 비교되는지, 어떤 순서로 나열되어야 하는지를 정의합니다.

예를 들어, 알파벳 대문자 A와 소문자 a가 같은지, 또는 어느 것이 먼저 오는지를 결정하는 데 사용됩니다. 또한 콜레이션은 문자 집합, 즉 캐릭터 셋(Character Set)에 종속적인데요. 문자 집합이란, 각 문자에 할당된 고유한 코드값의 집합을 의미합니다.
예를 들어, 대문자 A는 U+0041, 소문자 a는 U+0061과 같이 정의됩니다. 이 코드값을 통해 컴퓨터가 문자를 인식하고 처리할 수 있습니다.
콜레이션은 문자들을 비교하는 과정에서 이러한 코드값 등을 기반으로 작동하기 때문에 문자 집합에 종속적입니다. 그리고 MySQL에서는 문자열 타입을 가지는 모든 컬럼은 자신만의 독립적인 문자 집합과 콜레이션을 가질 수 있습니다.
만약 사용자가 MySQL 서버나 DB 내 오브젝트에 별도로 콜레이션을 설정하지 않으면, MySQL은 서버에 설정된 문자 집합의 디폴트 콜레이션을 사용합니다. 또한 데이터베이스 내에 생성되는 오브젝트에도 해당 내용이 적용됩니다.

다음은 콜레이션 종류입니다. MySQL에서 지원하는 콜레이션 목록을 확인하고 싶은 경우, SHOW COLLATION 명령을 사용하면 됩니다.
SHOW COLLATION 명령을 실행하면, 위 그림과 같이 콜레이션 목록이 보이는데요. 콜레이션 이름과 함께 각 콜레이션이 속해있는 문자 집합, 그리고 콜레이션이 문자 집합의 기본 콜레이션인지, 후행 공백에 대해 패딩 처리를 하는지 등과 같은 부가적인 속성 정보들을 확인할 수 있습니다.
콜레이션을 살펴보면 이름에 어떤 규칙이 있어 보이면서도 낯설고 복잡하게 느껴지는 부분들이 있는데요. 사실 콜레이션의 이름에는 콜레이션의 성질과 특성에 대한 다양한 정보가 담겨 있습니다. 따라서 네이밍 컨벤션을 이해하는 것도 많은 도움이 됩니다.

지금부터는 MySQL에서 사용되는 콜레이션의 네이밍 컨벤션에 대해 알아보도록 하겠습니다. MySQL에서 콜레이션 이름은 크게 네 부분으로 구성되어 있으며, 각각은 콜레이션의 중요한 특징을 나타냅니다.
우선 첫 번째 부분부터 살펴보면, 콜레이션 이름의 시작 부분으로 해당 콜레이션이 속한 문자 집합을 나타냅니다. 예시로 나와 있는 것처럼 utf8mb4, utf8mb3, latin1, euckr 등이 있습니다. 여기서 utf8mb3는 기존 utf8 문자 집합을 의미한다고 보시면 됩니다.

다음으로 두 번째 부분인 언어 종속입니다. 언어 종속 부분은 문자 집합 부분과 달리, 글자가 회색으로 표시되어 있는데요. 이는 선택적인 속성으로 생략될 수 있음을 의미합니다.
즉, 콜레이션이 언어 종속 특성을 가진다면 이름에도 해당 내용이 표시되고, 그렇지 않은 경우에는 이름에도 표시되지 않습니다. 언어 종속은 특정 언어에 대해 해당 언어에서 정의한 정렬 순서를 바탕으로 정렬 및 비교를 수행함을 의미합니다. 언어 종속 부분에 표시되는 값은 locale code 또는 language 값이 표시되는데요. 표시된 언어에 대해서는 그 언어에서 정의한 정렬 순서가 사용됩니다.

세 번째는 UCA 버전인데요. 언어 종속과 마찬가지로 선택적으로 표시되는 값입니다. UCA는 ‘Unicode Collation Algorithm’의 약자로 유니코드 기반의 문자 집합에 속한 콜레이션에서 사용하는 ‘문자열 비교 표준 알고리즘’을 의미합니다.
그래서 이 UCA를 기반으로 동작하는 콜레이션에서는 해당 콜레이션이 사용하는 UCA 버전 정보가 이름에 표시됩니다. 예시로 나와 있는 콜레이션들을 살펴보면, 전부 유니코드 기반 문자 집합에 속해 있는 콜레이션으로, 콜레이션별로 UCA 버전이 표시되는 형태가 조금 다른 것을 확인할 수 있습니다.
그리고 이름에 ‘general’이라는 단어가 포함된 콜레이션도 있는데요. 이는 UCA 기반은 아니고, MySQL에서 비교, 성능 향상 등을 위해 자체적으로 커스텀한 규칙이 적용된 콜레이션이라고 보면 됩니다.
마지막 부분은 민감도라고 표시해 보았는데요. 콜레이션에서 문자열 비교 시 악센트 구분이나, 대소문자 구분을 하는지 또는 바이너리 값 기반 비교를 수행하는지와 같이 문자열 비교 민감도에 대한 특성이 명시되는 부분입니다.
위 자료에 보이는 값들이 민감도에 표시될 수 있는 값인데요. _ai와 _as는 악센트 구분 여부를 나타내고, _ci와 _cs는 대소문자 구분 여부를, _ks는 일본어에서 히라가나와 가타카나 문자 구분 여부를 나타냅니다.
_bin는 Binary의 줄임말로, 문자열에 대해 Binary 값으로 비교하고 정렬하는 것을 의미합니다.
지금까지 MySQL에 어떤 콜레이션들이 있는지, 그리고 콜레이션 네이밍 컨벤션에 대해 알아보았는데요. 이제는 실제 콜레이션이 어떻게 동작하는지, 많이 사용하는 유니코드 기반 문자 집합에 속하는 콜레이션 위주로, 해당 내용을 살펴보겠습니다.
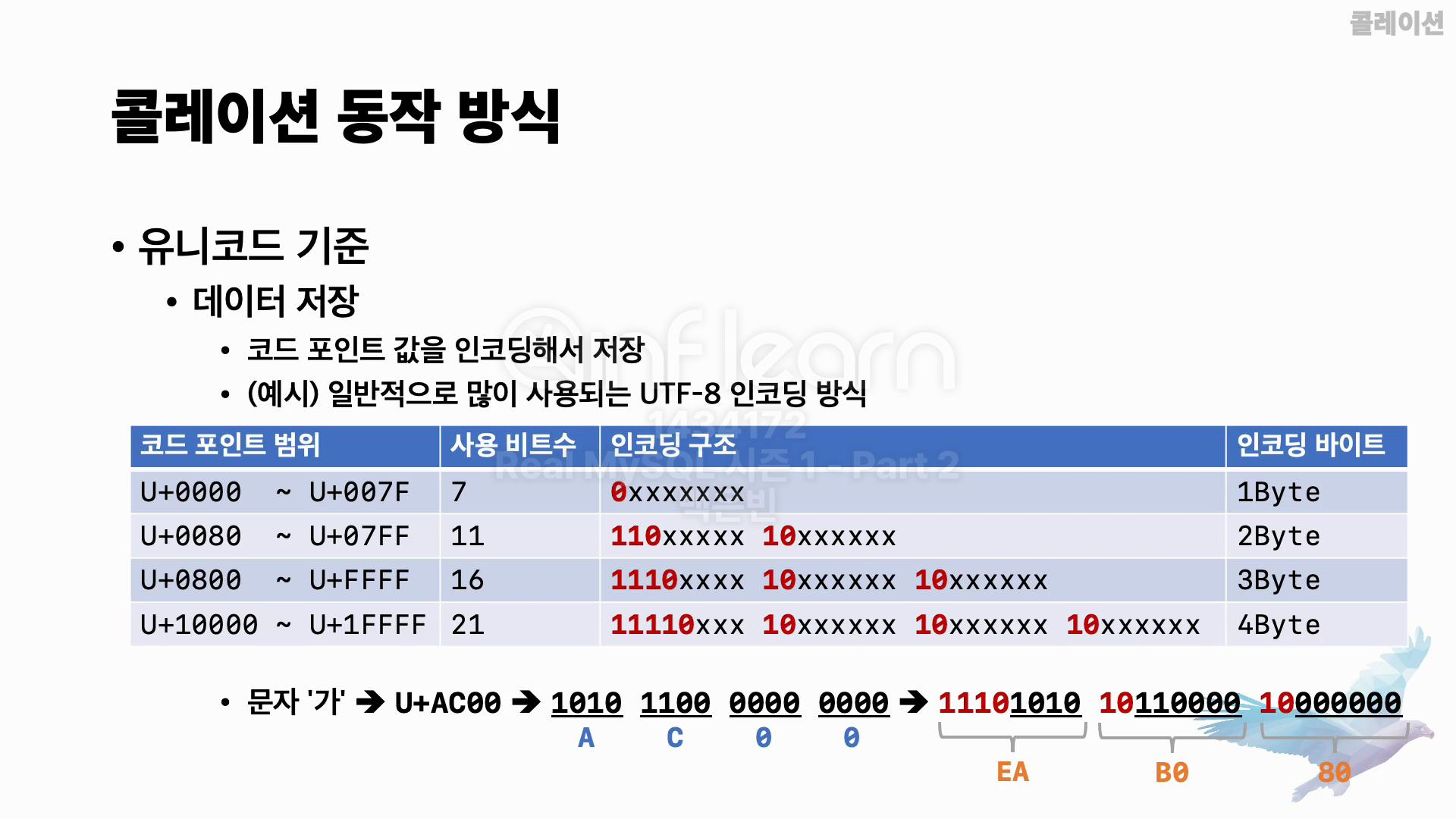
우선 기본 개념을 익히기 위해 문자열 데이터가 어떻게 저장되는지부터 간단하게 살펴볼게요. 유니코드 기반 문자 집합에서는 문자 데이터를 저장할 때, 그 문자에 해당하는 유니코드 코드 포인트 값을 인코딩해서 저장합니다.
이 인코딩 방식에 따라 UTF-8, UTF-16 등으로 문자 집합이 구분됩니다. 일반적으로 많이 사용되는 문자 집합은 utf8mb4로 문자열 데이터 저장 시, UTF-8 인코딩 방식이 적용됩니다. UTF-8 인코딩 방식은 가변 길이 인코딩 방식으로, 코드 포인트 범위에 따라 문자가 1에서 4바이트로 인코딩됩니다. 그림에 나와 있는 표가 UTF-8 인코딩 방식을 대략적으로 보여주고 있는데요.
코드 포인트 범위별로 이 코드 포인트를 표현하는 데 사용되는 비트 수가 다르고, 이를 기반으로 UTF-8 인코딩은 지정된 인코딩 구조에 맞춰, 가변 길이의 바이트 시퀀스로 변환하여 저장합니다.
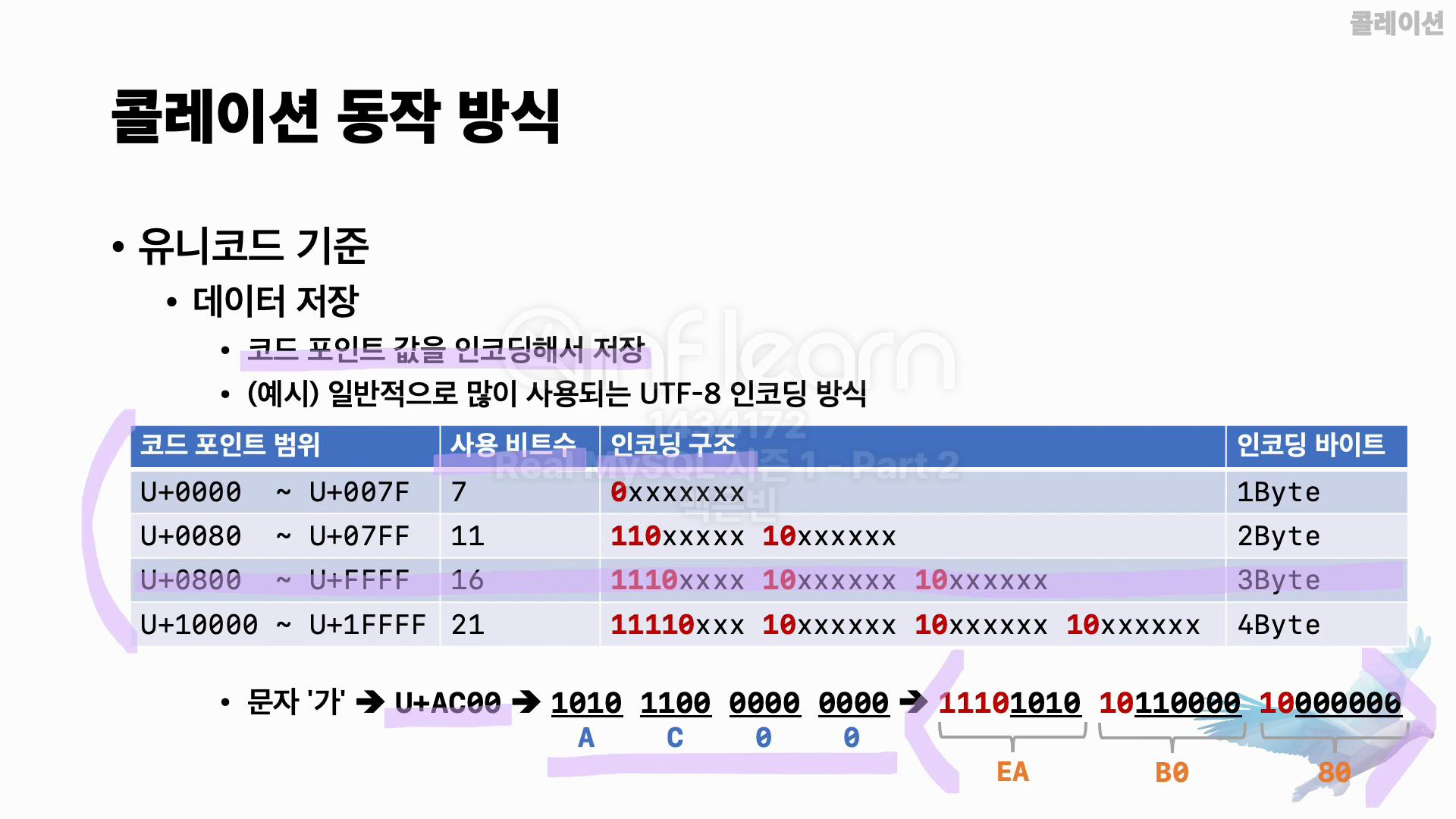
좀 더 이해하기 쉽도록 문자 ‘가’를 인코딩하는 예시를 살펴볼게요. 문자 ‘가’의 유니코드 코드 포인트는 AC00으로 UTF-8 인코딩에서 3바이트가 필요한 범위에 속합니다.
AC00을 비트로 표현하면 그림 하단에 나와 있는 값으로 표현이 됩니다. 이를 3바이트 인코딩 구조에 맞춰 값을 배치하면, 그림 하단 오른쪽에 나와 있는 것과 같은 3바이트 시퀀스 값이 완성됩니다. 이 3바이트 시퀀스는 16진수로 EAB080으로 표현할 수 있습니다. 따라서 문자 ‘가’는 UTF-8 인코딩으로 EAB080으로 표현되고, 저장된다고 볼 수 있습니다.
이처럼 문자 집합과 코드 포인트, 인코딩에 대해 기본 개념을 살펴봤습니다. 이러한 개념들은 DB에서 문자 데이터를 어떻게 처리하는지 이해할 수 있는 중요한 부분이니, 간단하게라도 알아두는 것이 좋습니다.

이제 본격적으로 문자 데이터 간의 비교는 어떻게 수행되는지 알아보겠습니다. 일반적으로 문자열을 비교할 때 각 문자열에 대해 먼저 가중치 값을 계산한 후, 비교하게 되는데요. 유니코드 기반 문자 집합에 속하는 콜레이션에서는 ‘DUCET’라는 데이터 시트에 정의된 가중치 값을 사용해서 비교합니다.
DUCET는 ‘Default Unicode Collation Element Table’의 약자로, 유니코드 문자별로 가중치 값이 정의되어 있는 데이터 시트입니다. DUCET에서 문자별 가중치 값은 Primary, Secondary, Tertiary와 같이 단계적으로 구성되어 있습니다.
예시로 한글 문자 ‘기역(ㄱ)’에 대한 DUCET 가중치 값을 살펴보면, 제일 첫 번째 3131 값은 문자 기역의 유니코드 코드 포인트 값을 나타냅니다. 그 뒤로 대괄호 안에 들어있는 3개의 16진수 값이 가중치 값에 해당합니다.
1단계 가중치 값에 해당하는 Primary Weight는 기본이 되는 문자를 비교할 때 사용되고, 2단계 가중치 값인 Secondary Weight는 악센트를 구분할 때, 3단계 가중치 값인 Tertiary Weight는 대소문자 구분 시 주로 사용됩니다.
그래서 콜레이션에 따라 사용되는 가중치 값도 달라지는데요. 콜레이션이 ai_ci인 경우, 즉 악센트와 대소문자를 구분하지 않는 경우에는 1단계 가중치 값까지 사용합니다. as_ci의 경우, 악센트는 구분하고 대소문자는 구분하지 않는 경우로, 2단계 가중치 값까지 사용합니다. 마지막으로 as_cs처럼 악센트와 대소문자를 모두 구분할 때는 3단계 가중치 값까지 사용합니다. 이 부분은 뒤에서 구체적인 예시를 통해, 가중치 값이 어떻게 사용되는지 다시 살펴보겠습니다.
그리고 한글 음절의 경우, 분해해서 개별 문자에 대한 가중치 값을 조합한 후 비교합니다. 문자열에 대해 계산된 가중치 값을 직접 확인해 볼 수도 있는데요. MySQL에서 제공하는 Built-in 함수인 WEIGHT_STRING() 함수를 사용하면, 문자열의 가중치 값을 바이너리 형태로 확인할 수 있습니다.

이번엔 실제 DUCET 데이터를 기반으로, 콜레이션별로 문자의 가중치 값이 어떻게 계산되는지 예시를 통해 확인해 보겠습니다. 위 그림에 나와 있는 예시는 문자 ‘기역(ㄱ)’에 대한 가중치 값을 확인하는 것으로, 첫 번째 박스에 나와 있는 값은 앞에서 본 것과 같이 문자 기역에 대한 DUCET의 가중치 데이터입니다. 이 데이터와 함께 실제 MySQL에서 계산된 값을 비교해 보겠습니다.
MySQL에서는 WEIGHT_STRING 함수와 HEX 함수를 사용해, 문자 기역에 대한 가중치 값을 16진수 값으로 확인할 수 있습니다.
첫 번째로 문자 기역에 대해 콜레이션을 utf8mb4_0900_ai_ci로 설정한 후, 가중치 값을 확인해 보면 3BF5 값이 나온 것을 확인할 수 있는데요. 이는 가중치 데이터에서 1단계, 즉 프라이머리 단계에 해당하는 값과 동일한 것을 알 수 있습니다.
그 다음으로 utf8mb4_0900_as_cs 콜레이션으로 지정 후, 다시 값을 확인해 봤습니다. 이때 가중치 데이터의 세 가지 값에 대해, 각각의 값을 0바이트로 연결해 조합한 값을 최종적인 가중치 값으로 사용하는 것을 알 수 있습니다.

다음으로 문자 ㄱ, ㄴ, ㄷ에 대해 utf8mb4_0900_ai_ci 콜레이션에서의 정렬 순서 및 가중치 값을 확인해 보겠습니다.
위 그림의 왼쪽과 같이 해당 값들을 저장할 테이블을 하나 만들고, 값을 저장한 후 오른쪽과 같이 정렬 순서와 가중치 값을 확인해 보면, 가중치 값 순서대로 데이터가 정렬되어 반환된 것을 알 수 있습니다.
어떤 콜레이션을 사용하는지에 따라서 문자를 비교한 결과나 정렬한 결과가 달라질 수 있는데요. 따라서 필요한 경우에는 이처럼 WEIGHT_STRING 함수를 사용해, 실제 계산된 가중치 값을 직접 확인하는 것도 좋은 방법입니다.

다음으로 콜레이션 설정입니다. MySQL에서 콜레이션 설정은 글로벌 수준에서부터 데이터베이스, 테이블, 그리고 개별 컬럼 단위까지 세밀하게 지정이 가능합니다.
우선 글로벌한 콜레이션 설정은 MySQL 서버 전체에 적용되고, 데이터베이스나 테이블 등 하위 오브젝트들은 그 값을 상속받습니다. 사용자가 MySQL 서버에 특별히 콜레이션을 지정하지 않은 경우, MySQL 서버에 설정된 문자 집합에 대한 기본 콜레이션 값이 서버의 글로벌 설정으로 자동 지정됩니다.
만약 문자 집합에 대해 특별히 값을 설정하지 않았다면, 기본적으로 utf8mb4 문자 집합으로 설정되고, 콜레이션도 utf8mb4 문자 집합의 기본 콜레이션인 utf8mb4_0900_ai_ci 콜레이션으로 설정됩니다.
각 문자 집합별 기본 콜레이션을 확인하고 싶다면, 앞서 살펴봤던 SHOW COLLATION 명령에서 디폴트 컬럼 값이 Yes인 콜레이션을 확인하거나, 그림에서처럼 information_schema 데이터베이스의 CHARACTER_SETS 테이블을 조회해 확인할 수 있습니다.
MySQL 서버에서 특정 문자 집합이나 콜레이션을 직접 지정해서 글로벌하게 적용하고 싶다면, character_set_server와 collation_server 설정 변수에 값을 지정하면 됩니다.

앞서 콜레이션은 좀 더 세밀한 단위로도 설정할 수 있다고 말했는데요. 글로벌하게 설정된 콜레이션 값과는 별개로 데이터베이스, 테이블, 컬럼별로 독립적으로 콜레이션을 지정할 수 있습니다.
위 예시와 같이 각 오브젝트들을 생성할 때, ‘COLLATE’라는 키워드와 함께 사용하고자 하는 콜레이션 명을 지정할 수 있습니다. 또한 ALTER 명령을 사용해 동일한 형태로 이미 설정되어 있는 콜레이션을 변경할 수도 있습니다.
다음 편에서는 이러한 콜레이션을 사용할 때 주의해야 할 점에 대해 살펴보겠습니다.
원본 강의 보러가기 https://u.inf.run/4fss3D5
©️요즘IT의 모든 콘텐츠는 저작권법의 보호를 받는 바, 무단 전재와 복사, 배포 등을 금합니다.