기획
신뢰할 수 있는 A/B 테스트 만들기: ③ A/A 테스트와 무작위화

7분
2024.05.24.4.8K
앞서 A/A 테스트의 목적과 필요성, 실험 전 편향에 대해 다루었습니다. 이번에는 이러한 실험 전 편향을 A/A 테스트로 어떻게 극복할 수 있는지, 구체적으로 이야기해 보려고 합니다. 이른바 ‘무작위화(randomization’의 마법이라고도 표현할 수 있는데요.
여기서 무작위화란, 실험군과 대조군에 고객들을 무작위로 할당하는 것을 말합니다. 이번 글의 예시를 통해 무작위화가 갖는 강력한 힘을 느낄 수 있을 텐데요. 고객이 어떤 시스템을 경험할지 온전히 통제할 수 있는 온라인 실험의 가치는 곧 무작위 할당의 마법과도 직결되기 때문입니다. 이번 글에선 무작위화를 비롯해 A/A 테스트를 수행하는 3가지 방법에 대해서도 함께 살펴보겠습니다.
A/A 테스트가 실험 전 편향을 극복하는 로직은 이전 글에서 힌트를 드렸듯이 생각보다 간단합니다. 무작위화의 마법을 활용하는 것인데요. 이 무작위화를 활용해 실험 전 편향이 존재하지 않는 적절한 실험군, 대조군 구성을 찾아줄 수 있습니다. 자세한 설명을 위해 그림을 하나 가져와 봤습니다.
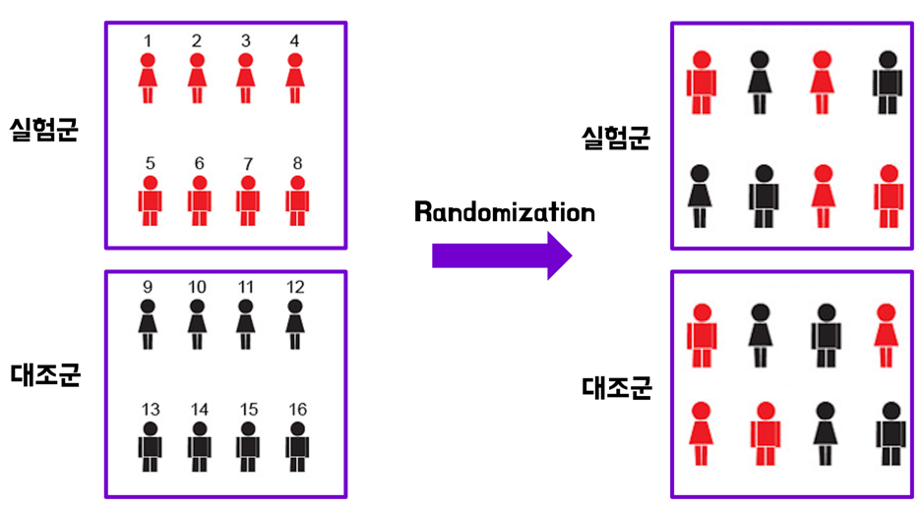
그림 1의 빨간색 사용자들을 방금 막 A/B 실험이 끝난 사람들이라고 해보겠습니다. 편의상 2번의 실험을 진행하는 상황이며, 순서효과는 없다고 가정할게요. 이들은 방금 막 실험을 마쳤기에 해당 실험군, 대조군 구성 그대로 다음 실험을 진행할 경우 ‘잔류효과’로 인한 실험 전 편향이 존재하여, 다음 실험에서 나타난 처리효과(실험 피처의 효과)를 순수한 인과적 효과로 보긴 어려울 것입니다.
다만 온라인 실험에서 이를 극복하는 방법은 생각보다 간단합니다. 실험을 진행할 때마다 그림 1처럼 고객들을 각 군에 무작위 재할당하여, 실험군과 대조군을 다시 구성하는 것이죠. 이러한 재구성은 해시 알고리즘(hash algorithm)을 이용해 진행됩니다. 2021년 Spotify에서 제시한 그림을 보시죠.

그림의 가운데 박스로 나타나 있는 해시 함수에 랜덤 솔트(random salt) 문자열에 고객의 ID를 붙여 입력값으로 넣어주면, 각 고객이 갖는 ID가 무작위로 바뀌어서 나오게 됩니다. 위 그림에는 고객 ID가 복잡하게 나오고, 우측에는 버킷(bucket)이라는 생소한 개념도 있는데요. 이해를 돕기 위해 예시를 들어볼게요.
우리에게 1만 명의 고객이 있고, 순서대로 각 고객은 1~10,000번의 고객 ID를 갖는다고 해보죠. 이때 이 고객 ID와 랜덤 솔트 문자열 “abc”를 함께 붙여(예를 들어 1번 고객은 “1abc”), 해시 함수를 태워줬다고 해보겠습니다.
1만 명의 고객 중 해시 함수를 타기 전, 고객 ID로 1번을 갖는 A라는 사람이 있습니다. 이 고객의 ID에 랜덤 솔트 문자열 “abc”를 붙여 “1abc”를 해시 함수에 태워줬더니, 고객 ID는 1001번으로 새롭게 부여되었다고 할게요. 즉, 1번이었던 고객 ID가 1001번이 된 거죠.
여기서 그림 2 우측에 등장하는 ‘버킷’이란 개념의 추가 설명이 필요합니다. 버킷은 고객 수가 너무 많으니 운영 편의상 그룹화를 한 것으로 이해하면 됩니다. 버킷을 10개 사용한다고 해보면, 1~1000번은 버킷 1번, 1001~2000번은 버킷 2번, 9001~10000번은 버킷 10번이 되는 겁니다. 즉, 한 버킷당 전체 고객 중 10% 트래픽을 들고 있는 것이라 할 수 있죠. 여기서 중요한 점은 고객 A는 해시 함수를 타기 전 1번 버킷이었으나, 해시 함수를 탄 후에는 1001번이라는 고객ID를 부여받았기 때문에 2번 버킷에 속하게 된다는 것입니다.
이게 곧 고객들을 대조군과 실험군에 무작위로 할당하는 개념으로 이어지는데요. 실제 실험을 진행한다고 가정하고 예를 들어보겠습니다. 20% 트래픽에 대해 실험군과 대조군을 균등 분할하여 실험한다고 해보죠.
우리는 고객들을 10개의 버킷을 나누어 놓았으니 간편하게 1번 버킷은 대조군으로, 2번 버킷을 실험군으로 사용하는 걸로 의사소통하면 됩니다. 이제 앞선 예제를 가져와서 생각해 보면 답이 나옵니다. 고객 A는 해시 함수를 타기 전에는 대조군에 배치되었으나, 해시 함수를 탄 후에는 실험군에 배치되죠. 본 예시에서는 고객 A만을 이야기했지만, 이러한 로직에 의해 해시 함수를 사용한 뒤에는 대조군과 실험군 각각에 속하는 고객의 구성이 달라지는 겁니다.
여기서 추가로 ‘랜덤 솔트 문자열’의 정체에 대해서도 알아보면, 고객 ID에 랜덤 솔트 문자열을 붙이는 이유는 근본적으로는 재현성을 위해서인데요. 랜덤 솔트 문자열을 무작위화 기계를 사용할때 필요한 토큰과 비슷한 개념으로 생각하면 됩니다. 예를 들어, 앞선 예제에서 1번 고객에 “abc”라는 토큰을 넣어 기계를 돌리면, 몇 번을 돌리든 해당 고객은 1001번이라는 ID를 부여받게 됩니다. 즉, 다시 말하면 토큰(랜덤 솔트 문자열)을 어떤 것을 넣느냐에 따라, 대조군과 실험군에 속하는 고객 구성이 달라지는 것이죠.
즉, 이 동전을 바꿔가면서 그림 2의 우측과 같이, 실험 전 편향이 존재하는 고객들을 양측에 균형 있게 다시 배치해 보자는 겁니다. 이를 바탕으로 우리는 실험 전 시기에는 관심 지표에 차이가 없는 실험군과 대조군 구성을 찾을 수 있을 것입니다. 이때 찾아진 실험군과 대조군 구성을 두고, 앞서 적절한 실험군, 대조군 구성이라고 표현한 것입니다.
앞서 설명한 일련의 과정들을 한마디로 표현하면 다음과 같습니다.
변형군 간 관심 지표 기준 최대한 편향 없이 균형 있게 구성해 주는 랜덤 솔트 문자열을 찾자!
참고로 변형군은 실험에 참여하는 모든 군을 이르는 말입니다. 이 일련의 과정은 A/A 테스트를 수행하는 방법으로 이어집니다.
먼저 위 일련의 과정을 바탕에 둔 2개의 A/A 테스트 방법부터 소개하겠습니다.
위 두 방식은 이미 적재되어 있는 과거 데이터를 활용해, 가상의 A/A 테스트로 적절한 변형군 구성을 찾아주는데요. 실무에서도 요긴하게 쓰는 방법이라고 할 수 있습니다.
마지막으로 소개할 A/A 테스트는 앞선 설명한 방법과는 달리, 과거 데이터를 활용하진 않습니다. 이른바 온라인 A/A 테스트라는 것인데요. 단, 온라인 A/A 테스트를 수행하더라도 한 번 정도는 후향적 A/A 테스트 분석을 수행하여 한 번 섞어주는 것이 좋습니다. 방금 실험이 끝난 실험군들이 각 군에 몰려있다면 순서효과나 잔류효과가 존재할 것이라, 섞어주지 않고 기존 그대로의 구성을 들고 가면 대조군과의 편향이 크기 때문이죠.
온라인 A/A 테스트는 말 그대로 실제 A/B 실험을 하듯이 실험을 할당하여, 실험군이든 대조군이든 같은 시스템을 경험하도록 만들어 관심 지표의 움직임을 관찰하는 것을 말합니다. 실제로 A/A 테스트를 온라인에 켜서 약 1~2주간 변형군 간 관심 지표에 차이가 없는지 관찰하고, 차이가 없이 수렴한다면 그때 A/B 테스트를 켜주는 것이죠.
이 방법의 단점은 실제로 실험을 관찰해야 해서 A/B 실험의 시작이 지연될 수 있다는 것입니다. 실제로 마이크로소프트의 검색서비스 Bing 팀의 경우 4번 중 1번은 실험을 재시작해야 했다고 합니다. 이러한 불편함에도, 온라인 A/A 테스트가 꼭 필요한 상황이 있습니다. 바로 실험 전에 실험군과 대조군을 할당해 두기 어려운 경우인데요.
눈치채셨을 수도 있지만 앞서 과거 데이터를 활용한 A/A 테스트의 경우, 사전에 이미 각 고객들이 대조군과 실험군 어느 쪽에 할당할지 결정해도 문제가 없는 실험에서만 사용할 수 있습니다. 그렇지 않으면 과거 데이터에 기반한 관심 지표를 계산할 수 없기 때문이죠. 사전에 고객들이 어느 군에 포함될지 미리 설정해선 안되는 때가 생기는 이유는 변형군의 설계 비율이 관측 비율과 일치하지 않으면, 심각한 문제를 초래하기 때문입니다.
실험을 진행할 때는 변형군의 설계 비율을 결정합니다. 특별한 상황이 아니라면 각 군은 균등한 비율로 설정되는데요. 만약 고객들의 방문 빈도가 적은 페이지에서 실험을 진행할 때는 이렇게 사전에 설계한 변형군 비율이 실제 관측상에서는 깨질 수 있다는 겁니다. 즉, 실험군과 대조군에 고객을 사전에 할당하여 A/B 테스트를 진행하면, 우리가 설계한 비율과 실제 관측되는 실험군과 대조군 비율이 다를 수 있다는 이야기죠.
방문 빈도가 적은 페이지에 고객이 실제로 진입하기 전 미리 변형군을 할당을 해버렸으니, 두 군 중 우연히 실험군에 속하는 고객들만 유독 해당 페이지에 많이 방문했다고 하면, 설계 비율과 관측 비율은 달라질 수밖에 없습니다.
이는 별 것 아닌 것처럼 보이겠지만 이 비율이 깨지는 것은 실험에서 심각한 문제를 초래합니다(Fabijan et al., 2019). 이 비율이 깨지는 것을 두고 ‘SRM(sample ratio mismatch)’이 발생했다고 이야기하며, 실험에서 측정하고 있는 모든 지표를 신뢰할 수 없게 됩니다. 이러한 이유에서 때로는 온라인 A/A 테스트의 활용이 필요한 경우가 생깁니다.
지금까지 A/A 테스트가 실험 전 편향을 극복할 수 있는 로직과 구체적 수행 방법에 대해 살펴봤는데요. 이러한 A/A 테스트 외에도 실험 전 편향을 줄이고, 실험 민감도를 올리는 그 밖의 방법들도 있습니다. 2013년 마이크로소프트에서 제안한 CUPED(Deng et al., 2013)와 넷플릭스에서 제안한 층화 추출(stratified sampling, Xie & Aurisset, 2016)이 바로 그것입니다. (두 방법론 모두 고도화된 통계적 방법론이라, A/B 테스트 전반에 관한 소개가 모두 끝난 뒤에 다시 다뤄보겠습니다.)
이전 글에서도 말했지만, A/B 테스트의 본질적 가치는 우리가 제품에 준 변화로 발생한 순수한 인과적 효과만을 측정할 수 있다는 것입니다. 이러한 본질적 가치를 갖기에, 여러 빅테크 기업에서도 온라인 실험에 진심일 수밖에 없는 것이죠. 계속해서 A/B 테스트 앞에 굳이 ‘신뢰할 수 있는(Trustworthy)’이라는 단어를 붙이는 배경 또한 이러한 본질적 가치에 있습니다.
A/A 테스트도 결국 본질적 가치를 지키기 위해 필요한 방법론 중 하나로 보면 됩니다. 상황과 인프라가 허락된다면, 가능한 많은 A/A 테스트를 수행해 보세요. 실험 전 편향을 해결할 뿐만이 아니라, 여러분이 놓친 함정을 발견하는 데 큰 힌트가 되어줄 겁니다.
©️요즘IT의 모든 콘텐츠는 저작권법의 보호를 받는 바, 무단 전재와 복사, 배포 등을 금합니다.