기획
신뢰할 수 있는 A/B 테스트 만들기: ② A/A 테스트와 실험 전 편향

6분
2024.05.24.3.9K
A/B 테스트 시리즈 보러 가기
고객 중심 프로덕트 개선에 ‘A/B 테스트’ 왜 필수일까?
신뢰할 수 있는 A/B 테스트 만들기: ① 실험 전 단계
앞서 1편을 통해 신뢰할 수 있는 A/B 테스트를 만들기 위해 실험 전 단계에서 고려해야 할 사항을 알아보았습니다. 가설 설정 및 성공 지표 설정, 그리고 실험 설계가 실험 전 단계의 큰 두 개의 축을 이룬다고 할 수 있는데요. 지난번 글을 마치며 이야기했듯, 더욱 성공적인 실험을 진행하기 위해 하나의 관문을 더 거칠 필요가 있습니다. 바로 A/A 테스트입니다.
A/A 테스트는 대조군과 실험군 모두에게 정확히 같은 시스템을 경험하게 만드는 실험을 말합니다. 굳이 두 변형군(variants, 실험에 참여하는 모든 그룹인 대조군과 실험군을 통칭함)에게 같은 시스템을 경험하게 해서 얻을 수 있는 점은 무엇일까요? A/A 테스트는 문자 그대로 보면 참 의미 없는 도구인 것처럼 느껴집니다. 그러나 A/A 테스트를 수행하지 않았더라면, 우리는 A/B 테스트에 내재된 여러 함정(pitfalls)을 지금까지도 모른 채 살아가고 있었을지도 모릅니다. 그래서 A/A 테스트에 대해 2개의 글로 살펴보고자 합니다. 이번 글에서는 먼저 A/A 테스트의 목적과 필요성, 실험 전 편향(pre-experiment bias) 대해 파헤쳐보겠습니다.
A/A 테스트의 목적은 크게 2가지로 정리할 수 있습니다.
먼저 A/A 테스트는 실험 전에 존재하는 편향을 잡아주기 위한 용도로 쓰일 수 있습니다. 두 번째 목적에서는 ‘실험 플랫폼(experimentation platform)’이라는 다소 생소한 용어가 등장하는데요. 여기서 실험 플랫폼이란 실험을 쉽고 빠르게 설계, 실행, 분석할 수 있도록 도와주는 도구입니다.
실험을 얼마나 빠르게 수행할 수 있는지는 곧 우리가 가진 가설을 얼마나 빨리 검증해 볼 수 있는지를 나타냅니다. 이는 곧 제품의 성장 가능성과 직결되고요. 그래서 A/B 테스트를 통해 실제 데이터를 기반으로, 가설을 검증하길 원하는 기업에서는 실험 플랫폼이라는 도구가 내부적으로 꼭 필요합니다. 이러한 실험 플랫폼의 신뢰도를 검증하는데 A/A 테스트는 중요한 역할을 합니다. (실험 플랫폼에 관한 이야기는 추후 별도로 다뤄보겠습니다.)
실험군과 대조군 각각에 다른 시스템을 경험하도록 하는 A/B 실험이 잘 구현되었음에도, 실험 전 편향은 발생할 수 있습니다. 이러한 실험 전 편향의 원인으로는 크게 3가지가 있습니다.
잔류효과, 순서효과의 설명을 보면 그럴듯합니다. 실험이 종료된 직후, 실험군에서 좋았거나 혹은 나빴던 사용자 경험이 실험이 종료된다고 하더라도 여전히 남아있을 수 있죠. 이것이 곧 잔류효과고요.
또한 실험 1 또는 실험 2에서의 경험이 어땠는지에 따라, 실험 3에서의 반응은 당연히 달라질 수 있습니다. 실험 2에 비해 1의 실험군에 속한 사용자들이 유독 좋은 경험을 했다면, 실험 3에서 더욱 호의적으로 반응할 수도 있고요. 이것이 순서효과입니다.
마지막으로 무작위 불균형이 나오는데요. 무작위 불균형은 무작위 할당을 해주더라도 우연히 대조군과 실험군 간의 차이가 발생하는 상황을 말합니다. A/B 테스트가 갖는 본질적 가치가 ‘우리가 제품에 준 변화로 발생한 인과적 효과만을 측정할 수 있다’는 점인데, 이를 이론적으로 가능케 하는 것이 곧 실험군과 대조군으로의 무작위 할당이라고 할 수 있습니다. 그러나 무작위 할당을 한다고 해도, 실험군과 대조군에 다양한 고객이 골고루 배치되지 않는 경우가 발생할 수 있습니다. 이것이 실험에서 관심 지표에 관한 불균형을 초래하고요.
예를 들어, 실험 A의 관심 지표가 사용자당 매출이라고 해봅시다. 우연히도 실험군에 우리 프로덕트에 돈을 많이 쓰는 사용자들이 많이 포함되었다고 해보죠. 이 경우 실험을 진행하여 실험군에서 대조군 대비 더 많은 사용자당 매출을 낸다고 한들, 이것이 우리가 준 변화로 나타난 것이 맞는지 확신하기 어려울 것입니다. 애초에 실험군에는 대조군 대비 돈을 더 많이 쓰는 고객들이 많이 배치되어 있기 때문이죠.
마이크로소프트에선 온라인 실험 연구진이 A/A 테스트를 통해 잔류효과를 검증해 낸 사례가 있습니다. Kohavi et al., 2012에 등장한 사례인데, 아래 그림을 통해 살펴볼게요.
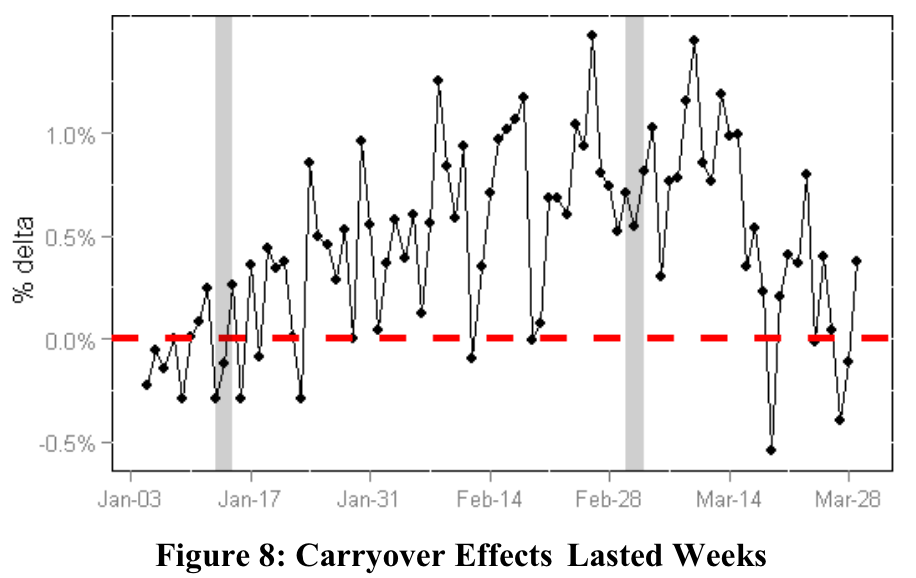
위 그림의 X축은 날짜, Y축은 ‘Delta %’라고 하여, A/B 테스트에서 대조군 대비 실험군에서 관심 지표의 변화율이 얼마나 되는지를 나타냅니다. 그림에 수직으로 뻗어있는 회색 쉐이딩 영역을 기준으로 실험은 3가지 스테이지로 나뉩니다. 먼저 첫 번째 스테이지에서는 약 일주일간 A/A 테스트를 진행해 주었습니다. 즉, 이 단계에서는 실험군과 대조군에 같은 시스템을 제공하며, 이에 따라 우리가 의도한 대로 두 그룹 간의 관심 지표의 Delta %는 0 근처에서 움직이고 있는 것을 확인할 수 있죠.
실험 전 편향이 존재하지 않는 것을 확인했으니, A/A 테스트를 종료하고 두 번째 스테이지에서 A/B 테스트를 약 5주간 수행해 줍니다. 실험이 경과됨에 따라 보다 많은 사용자들이 방문하고 실험군의 새로운 피처(feature)를 경험하며, Delta %가 커지는 자연스러운 그림으로 보이죠. 우리가 세운 가설로 디자인한 실험군의 새로운 피처가 고객들에게 좋은 경험을 선사하고 있는 것으로 보입니다.
문제는 그 다음입니다. 그들은 잔류효과 검증을 위해 A/B 테스트 종료 후, 세 번째 스테이지에서 곧바로 A/A 테스트를 다시 켜주었습니다. 같은 시스템을 경험하고 있음에도, 두 그룹 간의 Delta %는 3주쯤이 지나서야 0 근처로 안정화가 되는 것을 관측했죠.
즉, 실험에서 발생한 효과가 약 3주간 지속되는 잔류효과를 실제 데이터를 기반으로 검증해냈다고 할 수 있습니다. 만약 A/A 테스트가 없었다면 마이크로소프트 연구진 또한 잔류효과라는 함정을 모른 채, 지나가게 됐을 겁니다.
지금까지 A/A 테스트의 목적과 실험 전 편향, 그리고 마이크로소프트에서 실험 전 편향을 A/A 테스트를 통해 검증해 낸 실제 사례를 살펴봤습니다. A/A 테스트를 통해 우리는 실험 피처의 순수한 인과적 효과를 오염시키는 실험 전 편향을 잡아줄 수 있는데요. 이러한 실험적 편향을 잡아주는 것은 제품에 준 변화의 ‘순수한 인과적 효과’를 측정하기 위해 사용되는 A/B 테스트의 본질적 가치를 지키는 데 매우 중요하게 작용합니다.
앞서 마이크로소프트의 잔류효과 검증 사례를 이야기한 뒤, 그래서 이러한 실험 전 편향을 어떻게 극복할 것인지에 대해 따로 살펴보지 않았는데요. 이어지는 A/A 테스트 두 번째 글에서 A/A 테스트로 이를 어떻게 극복할 수 있는지 알아보려고 합니다. 미리 힌트를 드리자면, A/B 테스트가 갖는 본질적 가치인 ‘순수한 인과적 효과’를 발라내는 중추적 역할을 하는 ‘무작위화(randomization)’의 마법을 다룰 예정입니다.
©️요즘IT의 모든 콘텐츠는 저작권법의 보호를 받는 바, 무단 전재와 복사, 배포 등을 금합니다.