기획
신뢰할 수 있는 A/B 테스트 만들기: ① 실험 전 단계

7분
2024.04.25.6.5K
신뢰할 수 있는 실험(trustworthy experimentation)을 수행하기 위해서는 어떤 요소들을 고려해야 할까요? 보통 사전에 정한 실험 기간 동안 데이터를 수집한 후, 해당 데이터를 기반으로 통계적 가설검정을 통해 우리의 가설이 옳은지 확인하는 것이 실험의 일련의 과정이라고 할 수 있는데요. 여기서 “통계적 가설 검정에 관한 원칙과 가정만 잘 지키면, 실험 결과를 신뢰할 수 있지 않을까?”라고 생각할 수 있는데, 안타깝게도 실상은 그렇지 않습니다. 신뢰도 높은 실험 결과를 제공하기 위해서는 가설 검정을 수행하는 실험 후 분석 단계뿐만 아니라, 실험의 전 과정에서 여러 요소를 신경 써야 합니다.
이번 글에서는 A/B 실험의 라이프사이클을 정의한 뒤, 각 실험의 단계에서는 어떤 것들을 고려해야 하는지에 살펴보고, 실험 전 단계(Pre-Experiment stage)에 대해 자세히 알아보겠습니다.
실험의 라이프 사이클은 간단하게 실험 전, 중, 후로 나눠서 바라볼 수 있습니다.
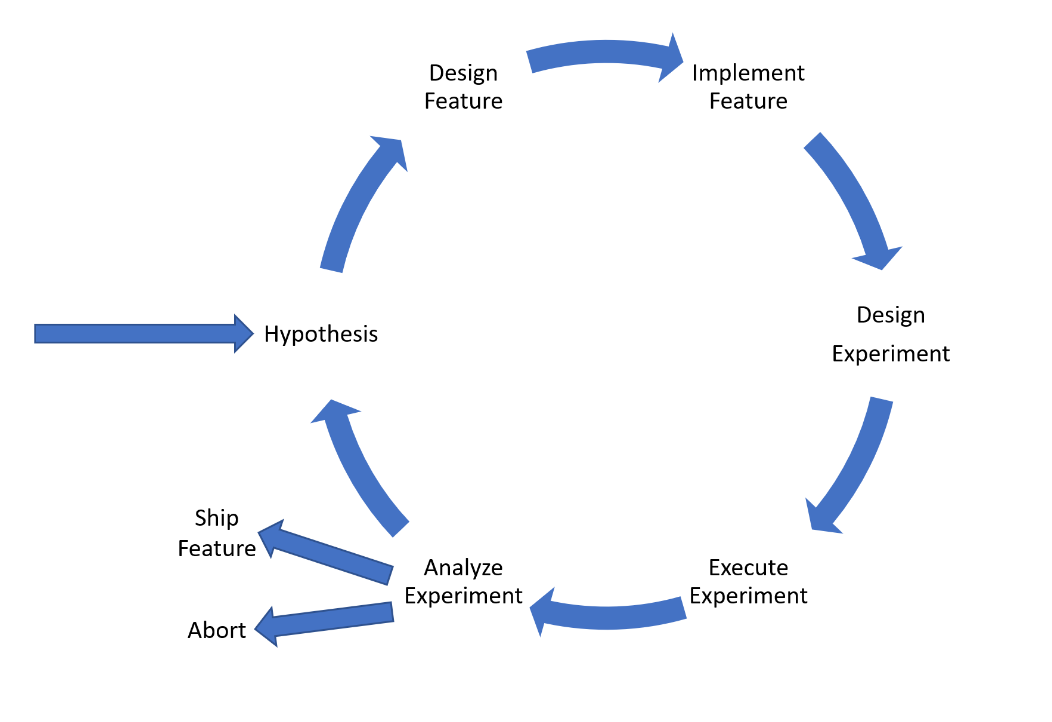
그림 1은 2018년 ICSA에서 마이크로소프트에서 제시한 실험의 라이프사이클입니다. 그림 속 각 요소들을 실험 전, 중, 후 단계로 나누어 다음과 같이 정리할 수 있습니다.
이제 본 글에서 다루기로 한 실험 전 단계의 각 요소를 살펴볼게요.
실험 전 단계에서 먼저 고려할 것은 가설 설정입니다. 실험의 첫 단추인 만큼 가장 중요한 요소라고 해도 과언이 아닌데요. 이때 본인이 쌓아온 도메인 지식, 과거 분석 사례 등을 활용하여, 가설의 초안을 잡고 이를 구체화해 나가는 과정이 필요합니다.
최종 가설을 설계하고 난 뒤에는 다음의 3가지에 답을 할 수 있어야 합니다.
위 3가지 질문에 답할 수 있다면, 실험 전 단계의 각 요소인 가설 설정, 실험 피처 디자인 및 구현까진 끝난다고 볼 수 있습니다. 마지막 질문의 답을 통해 성공 지표 설계도 할 수 있고요. 또한 이렇게 구체화된 가설을 바탕으로 실험의 성공 지표를 설계하는 것은 실험 설계 단계에서 매우 중요한 검정력 분석과 A/A 테스트와도 깊은 연관이 있습니다. 따라서 실험의 성공 지표를 명확히 하는 것은 꼭 필요한 과정이죠.
이 정도 설명만으로는 가설 설정이 어려울 수 있으니, 구체화한 가설이 갖추면 좋은 4가지 요소를 바탕으로 한 템플릿을 살펴볼게요.
“OO에 OO을 더하면/변경하면, OO을 시작하는 사용자에 대한 OO이 저하한다.”
위와 같이 가설을 구체화하는 노력이 필요하며, 이렇게 구체적인 가설을 설정하는 것이 성공적인 A/B 실험을 실행하는 중요한 첫걸음입니다.
실험을 설계할 때는 기본적으로 4가지 요소를 고려해야 합니다.
하나씩 간략하게 설명해 보겠습니다. 먼저 무작위 추출 단위는 일반적으로 사용자(고객)라고 할 수 있습니다. 특별한 상황이 아닌 이상, 우리는 사용자들을 중심으로 무작위화(randomized)하여 대조군과 실험군 각각에 사용자들을 배치합니다. 이에 따라 지표의 측정 또한 사용자 단위로 이루어지죠. 앞선 가설 설정에서 제시한 지표와 같이 사용자당 OO이 일반적인 실험 지표가 되는 것입니다.
물론 A/B 테스트에서 흔히 사용되는 지표 중 하나인 CTR과 같이 다른 단위의 지표가 필요한 경우도 있습니다. CTR의 경우 페이지뷰(page view) 단위로 볼 수 있는데요. 단, 이 경우 CTR 지표의 분산 계산에 델타 방법(delta method)를 적용해 주어야 통계적 가설 검정에 필요한 지표의 분산 추정에 편향(bias)을 피할 수 있습니다.
델타 방법은 CTR과 같은 두 지표 간의 비율 지표(ratio metrics)의 분산을 정확하게 추정하는 데에 굉장히 중요한 역할을 하는 방법론인데, 이 부분에는 통계학적인 개념이 많이 들어가기 때문에 추후에 별도의 글로 다루도록 하겠습니다.
다음으로 타겟팅인데요. 말 그대로 어떤 사용자들을 대상으로 실험을 진행할 것인가입니다. 앞서 이야기한 분석 대상의 정의와는 다른 얘기로, 그 전에 근본적인 실험 타겟 자체를 어떻게 설정할 것인가에 대한 부분으로 이해하면 됩니다.
지역(글로벌 서비스의 경우 국가), 플랫폼(iOS, Android 등), 장치 유형(태블릿, PC, 모바일), 앱 버전 등이 타겟팅의 기준이 될 수 있습니다. 특정 실험 피처의 경우, 일정 버전 이상의 앱 버전이 요구될 수 있으며, 지역 특성에 따라 고객 경험을 위해 제품 피처를 세부적으로 조정해야 하는 경우도 있죠. 따라서 이러한 타겟팅 기준에 대해서도 고민이 필요합니다.
마지막으로 트래픽과 실험 기간입니다. 이 둘은 서로 연관되는 부분이 많아서 묶어서 이야기해 보려 합니다. 그 이유는 온라인 실험의 경우, 실험에 참가하는 고객 수(표본 크기)가 트래픽과 실험 기간에 의해 결정되기 때문인데요. 트래픽이 100%에 가까울수록, 실험 기간이 길수록 더 많은 고객을 실험에 참가시킬 수 있습니다. 그리고 실험에 더 많은 고객을 참가시킬수록(표본 크기를 키울수록) 통계적으로 더욱 정밀한 실험 효과를 감지할 수 있죠.
이 부분은 통계적 검정력, 검정력 분석과 관련되는 내용이며,이 부분에 관한 자세한 설명 또한 다음에 별도의 글로 풀어볼 예정입니다. 이번엔 전반적인 개념만 간단하게 소개하겠습니다.
실험을 통해 프로덕트가 성장하고 성숙해질수록, 더욱 정밀한 실험 효과를 감지하는 것이 중요해 집니다. 정밀한 실험 효과를 감지하는 것의 필요성은 시험 점수로 이야기해 볼 수 있는데요.
60점에서 90점으로 가는 것은 비교적 쉽지만, 90점에서 100점을 향해 가는 것은 상대적으로 더욱 어렵습니다. 즉, 이에 따라 우리 프로덕트가 90점쯤 왔을 때는 점진적으로 조금씩 개선해 나가는 것이 필요하죠. 만약 1점씩 증가시키더라도 이를 통계적으로 유의하다고 감지할 수 있는 실험을 설계할 수 있어야 합니다.
1점을 증가시키고 이를 통계적으로 유의한 차이가 있는 결과라고 판단했을 때, 이 결과가 신뢰할 만하고 재현이 가능한가?에 대한 답이 되는 분석이 검정력 분석입니다. 그래서 저는 검정력 분석이 갖는 본질적 의미를 다음과 같이 정의합니다.
“충분한 표본을 확보하여 검정력과 유의수준을 균형 있게 통제함으로써, 실험 결과가 우연히 발생한 것이 아닌 신뢰할 수 있는 재현성 있는 결과임을 보장해주는 분석”
여기서 ‘균형 있게 통제하는 것’의 기준으로 삼는 산업 표준(industrial standard)은 검정력 80%, 유의수준 5%에 해당합니다. 위 의미를 곱씹어 보면, 실험 설계 단계에서 굉장히 중요할 수밖에 없는 부분이라는 것을 알 수 있습니다. 여기서 앞서 말한 산업 표준을 지키기 위해 충분한 표본을 확보한다는 것이 포인트인데요. 온라인 실험에서 표본을 얼만큼 확보할 수 있는지는 실험 기간과 트래픽을 어떻게 설정할 것이냐로 이어집니다.
그래서 실험 설계 단계에서 검정력 분석을 활용하여, 주어진 상황에 맞게 실험 기간과 트래픽을 설정하는 것은 굉장히 중요합니다. 여기서 주어진 상황의 예시로, 실험 피처가 프로덕트에 대규모 변경을 가져오는 경우를 들 수 있는데요. 이러한 대규모 변경은 위험이 크기 때문에 적은 트래픽으로 실험을 시작하는 것이 좋습니다.
즉, 이때는 트래픽이 고정되어 있으므로 검정력 분석 결과에 따라, 감지하려는 실험 효과(MDE, minimum detectable effect)를 고려하여 기간을 결정하는 것이 필요합니다. 앞서 시험 점수로 비유하며, 1점의 개선으로 중요한 상황이 온다고 했는데, 이때 1점이 곧 MDE라고 할 수 있죠.
이렇게 트래픽과 실험 기간은 서로 연관 있게 설정되며, 이 부분은 실험 전 단계에서 필요한 검정력 분석과도 이어집니다. 최대한 쉽게 풀어보려고 했는데, 혹시 이해가 어려운 부분이 있다면 댓글로 남겨주시면 답변드리겠습니다. 또한 검정력과 검정력 분석에 대한 이해는 실험에서 굉장히 중요한 부분이라, 앞서 이야기했듯 더 자세한 설명은 별도의 글로 다뤄보겠습니다.

오늘은 신뢰할 수 있는 실험을 만들기 위해 A/B 실험을 라이프사이클 관점에서 정의해보고, 각 단계에서 어떤 요소를 고려해야 하는지 실험 전 단계에서 살펴보았습니다. 앞서 실험 전 단계를 구성하는 요소에서 한 가지 더 중요한 요소가 있는데요. 바로 A/A 테스트입니다.
A/A 테스트는 A/B 테스트와 달리, 말 그대로 실험군과 대조군이 같은 피처를 경험하는 테스트입니다. 왜 굳이 이런 형태의 실험을 해야 하냐고 할 수 있지만, A/A 테스트는 실험 전에 존재하는 편향(pre-experiment bias)을 잡아주고, 실험 플랫폼(실험을 대규모로 실행하는데 필요한 플랫폼)의 신뢰도를 검증할 수 있게 해서, 온라인 통제 실험에서 중요한 역할을 합니다.
그래서 실험 전 단계에서 실험 설계 이후, A/A 테스트 과정이 필요하죠. 다음 글에서는 실험 중 단계, 실험 후 단계를 구성하는 요소를 살펴보기 전에 먼저 A/A 테스트에 대해 자세히 다뤄보겠습니다. 마지막으로 A/A 테스트 과정을 반영한 실험 전 단계를 간략히 정리하며 글을 마칩니다.
©️요즘IT의 모든 콘텐츠는 저작권법의 보호를 받는 바, 무단 전재와 복사, 배포 등을 금합니다.