개발
Spring Boot와 Redis로 캐싱 구현하기

13분
2023.11.01.21.2K
캐싱은 데이터 처리 비용을 줄이기 위해 사용되는 기법으로 비용이 많이 드는 데이터 조회 작업에서 자주 사용됩니다. 이번 글에서는 캐시를 구현하기에 앞서 사전에 알아두면 좋을 만한 캐시에 대한 개요와 캐싱을 사용하기 전에 고려해야 할 부분에 대해 알아보려고 합니다.
캐싱의 개념을 알아보고 Spring Boot와 Redis로 구현하는 캐싱에 대한 간단한 예제를 같이 설명하겠습니다.
캐싱이란 이전에 처리(검색/계산) 되었던 데이터를 효과적으로 재사용하는 기법을 의미합니다. 일반적으로는 기본 데이터 처리 방법보다 속도가 빠른 고속 데이터 계층을 두고, 동일한 요청에 대해서는 해당 계층을 통해 빠른 속도를 보장하는 기법입니다.
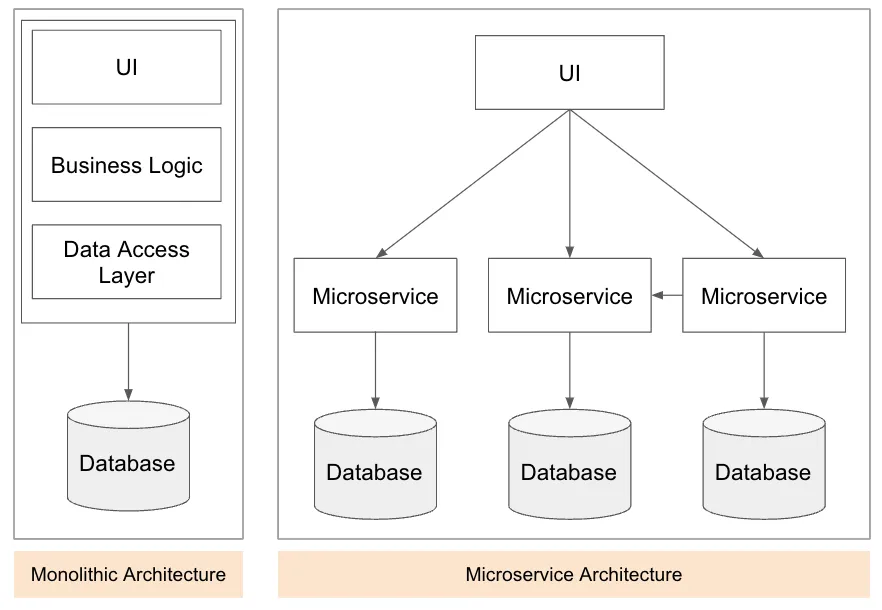
모놀리틱에서 MSA의 전환, 클라우드 환경의 전환으로 모든 단위별 기능과 데이터들이 서비스 내부에서 관리되고 제공됩니다. 서비스별 통신 방법은 협의된 방법을 통해 내/외부 통신을 하게 됩니다.
하지만 네트워크로 통신을 주고받는 과정은 비용이 드는 문제이며, 가끔은 지연이 발생하거나 유실이 발생할 수 있습니다. 내부 스토어에 접근하더라도, 원본 데이터의 양이 증가와 구조의 복잡함에 따라 속도 저하 등의 문제가 발생할 수 있습니다.
이런 경우 네트워크나 내부 스토리지를 통해 자주 가져오는 데이터를 미리 조회하여, 스토리지나 네트워크를 통해 가져오는 것보다 빠른 계층에 데이터를 임시 저장하여 데이터의 변경이 있을 때까지 그 데이터만을 사용하는 기법이라고 보시면 됩니다.
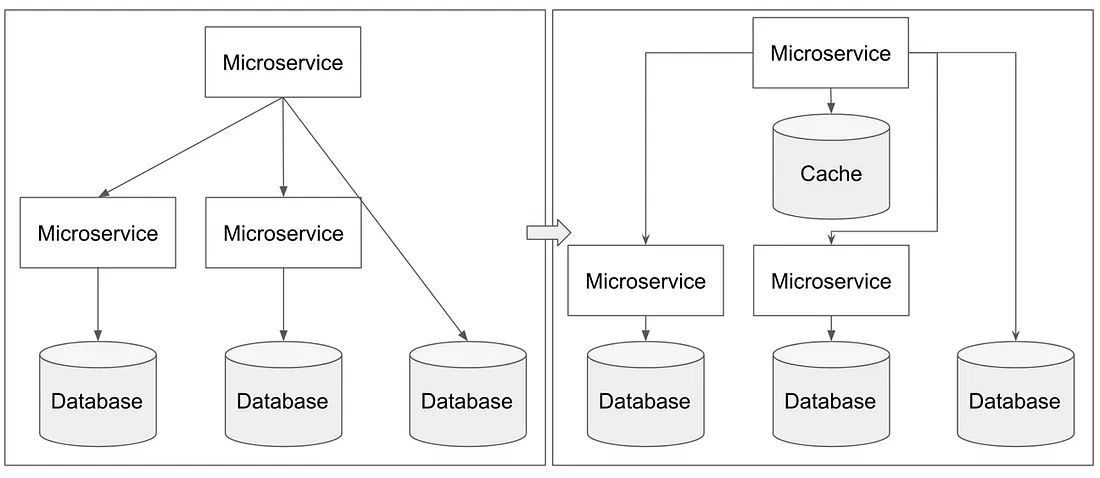
이렇게 임시 저장하여 사용하는 데이터를 통해 스토리지나 네트워크 통신 시 발생할 수 있는 지연, 유실을 줄이고 데이터 처리에 필요한 속도 저하를 낮출 수 있게 됩니다. 또한 여러 데이터를 조합해서 결과를 제공하는 경우, 미리 결과를 조합하여 캐싱 처리를 해둔다면 불필요한 엑세스를 위한 대기 시간을 줄이고 응답을 처리할 수 있게 됩니다.
자주 액세스하는 데이터를 캐싱함으로써, 애플리케이션은 느린 응답에 액세스해야 하는 횟수를 줄여 성능을 향상할 수 있습니다. 캐싱을 통해 느린 스토리지/서버 등의 액세스를 줄이므로 결국 시스템의 전반적인 성능을 향상할 수 있습니다.
이처럼 캐시를 적절하게 활용하면, 매번 반복해서 처리해야 하는 작업을 효율적으로 처리할 수 있으며 이는 시스템 성능과 안정성 향상과 연결됩니다.
CPU
HTTP
CDN Resource Caching
위의 개요에서는 캐시 조회는 내부 스토리지를 통해 가져오는 것보다 빠른 계층에서 데이터를 조회하여 처리하는 것으로 설명해 드렸습니다. 캐시 설계에 앞서 하드웨어의 캐시를 예시로 간략하게 설명하겠습니다.
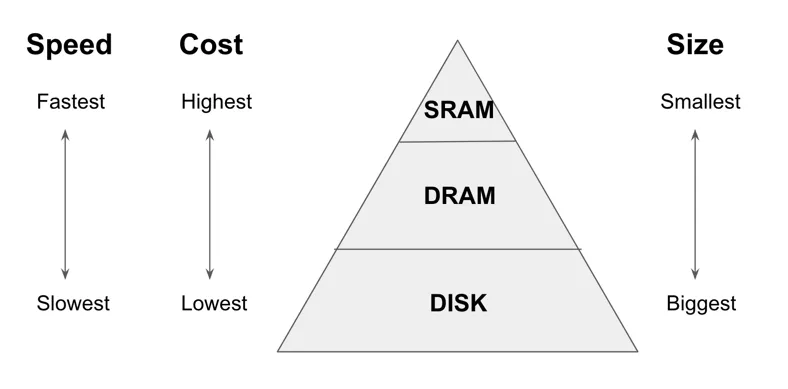
저장장치는 다음과 같은 특징을 가지고 있습니다. Disk는 Memory보다 많은 정보를 저장할 수 있지만, 상대적으로 속도가 느린 편입니다.
SRAM(Static RAM), DRAM(Dynamic RAM)은 RAM의 구조적 특징에 따라 나눠지게 되는데 같은 RAM이지만 가격/속도/용량의 차이가 있습니다. SRAM은 가장 빠르고 많은 양을 기록하기 부적절하기 때문에 Cache Memory로써 자주 사용됩니다. 요약하자면, 속도가 빠를수록 저장장치의 가격은 비싸지기 때문에 캐시를 설계할 때의 중요한 지표가 될 수 있습니다.
CPU에서도 메모리로 사용할 수 있도록 제공하는 하드웨어 캐시 Cache Memory가 존재합니다. Cache Memory는 SRAM으로 구성되어 있으며, 가장 자주 접근하는 위치의 데이터를 가지고 있는 메모리입니다. 하지만 CPU 캐시는 SRAM으로 구성되어 있어 속도는 빠르지만, 용량이 크지 않아 제한적인 데이터만을 저장하게 됩니다.
위의 경우를 요약하여 우리가 캐시를 설계할 때 고민이 필요한 부분은 다음과 같습니다.
위에서 언급한 것처럼 데이터를 디스크와 같이 비교적 속도가 느린 저장 장치에 저장하고 이를 메모리에 캐싱하는 이유가 주로 비용, 안정성 문제입니다. 이런 문제를 고려해 보자면, 결국 우리는 메인 스토리지에 있는 모든 데이터를 캐시에 저장할 수 없다는 것을 알 수 있습니다.
캐시의 취지와 상황을 고려해 보았을 때, 모든 데이터를 캐싱 처리할 수 없기 때문에 서비스 영역에서 우선순위 정의가 필요합니다. 그중 몇 가지 예시를 들어보면 다음과 같습니다.
여기서 동일한 요청이 많은 경우는 캐시 요청 기준에서의 동일한 요청을 의미합니다. 동일한 요청이 많다는 것은 애플리케이션이 캐시에 데이터 접근을 자주 한다는 의미이며, 이는 캐싱을 효과적으로 사용한다는 것을 의미합니다.
캐시의 성능을 측정하는 데 사용되는 몇 가지 용어가 있습니다. 이 용어들은 캐시의 효율성과 성능을 평가하고 측정하는 데에 도움이 됩니다.
애플리케이션은 데이터 접근을 위해 캐시에 데이터를 요청하며, 캐시에 데이터가 이미 저장되어 있는 경우 “hit”이라고 표기됩니다. 반면 캐시에 데이터가 존재하지 않아 원본 데이터를 가져와야 하는 경우에는 “miss”라고 표기됩니다.
이상적인 캐시 성능을 위해서는 높은 Hit Ratio, 낮은 Miss Ratio 가 이상적입니다. 이는 캐시가 데이터를 효율적으로 저장하고 조회하여 반복적인 요청을 빠르게 처리할 수 있다는 것을 의미합니다.
높은 Hit Ratio 경우 캐싱 처리로 인한 성능 향상을 기대할 수 있지만, Miss Ratio 가 높은 경우는 캐시와 원본 스토리지 모두 호출되므로 오히려 원본 스토리지만 호출할 때보다 불필요한 호출이 발생할 수 있습니다.
요약하자면, 캐싱을 효과적으로 활용하기 위해 Hit Ratio을 측정하여 캐시에서 데이터를 성공적으로 찾아낼 가능성을 추정할 수 있습니다. Hit Ratio는 캐시 시스템을 최적화하고 성능을 향상시키기 위한 중요한 지표가 될 수 있습니다.
캐시를 사용하더라도 관리, 비용 측면에서 데이터를 무기한 저장하지 않습니다. 예를 들어 회원 정보를 캐싱하는 API를 통해 특정 회원 정보가 캐싱되어있을 때, 해당 회원이 장기간 사용하지 않는다고 가정하면 해당 고객의 캐싱 정보를 무기한 남겨두는 것에 대한 고민이 필요합니다.
미사용 고객이 많거나, 기타 사용되지 않는 데이터들에 대한 캐싱 정보가 삭제되지 않고 쌓여있다면 Cache Data의 용량은 점점 커질 것이고 그에 따른 관리가 필요하기 때문입니다. 그래서 Key 별로 만료 일자를 지정하여 특정 기간 내에만 데이터를 저장하며 기간이 지나면 삭제되어 다시 캐싱을 처리하는 방법을 사용해야 합니다.
Redis의 경우 이런 만료 시간을 처리하기 위해 Key별 TTL(Time-To-Live)을 설정할 수 있습니다.
> set username::1 'daehoon' EX 60 #1
> TTL username::1 #2
(integer) 55
> set username::2 'dahun' #3
> TTL username::2 #4
(integer) -1
사용하는 캐시 구조와 Key가 사용되는 서비스를 고려하여 적절한 TTL을 설정하고 관리하는 것이 중요합니다.
캐시 및 서비스 상황에 따라 다르겠지만 캐시 사용을 위해 기본적으로 관리되어야 하는 항목 중 몇 가지만 설명하겠습니다.
KEY
VALUE
EXPIRE
다른 서비스에서 캐싱되어 사용하는 데이터 중 변경 사항이 있는 경우, 이를 캐싱하여 사용하고 있는 부분에 동기화(전파) 될 방법에 대해 같이 고민되어야 합니다. 또한 데이터 싱크에 민감하지 않은 서비스는 싱크가 안 맞아도 상관없지만, 데이터 싱크에 대한 신뢰도가 중요한 서비스는 캐싱 처리에 대한 고민이 필요합니다. (금융, 예매 등)
위에서 자주 설명했던 조회 빈도나 비용과 더불어, 높은 Cache Hit Ratio와 관리 측면에서 전략에 따라 다를 수 있겠지만 변경이 많지 않은 데이터가 캐싱하기에 쉬운 데이터라고 볼 수 있습니다.
> MEMORY USAGE username::2
(integer) 72
Spring Boot 2.6.7 + Redis를 통해 캐싱에 대해 간단히 구현해 보도록 하겠습니다.
dependencies {
implementation 'org.springframework.boot:spring-boot-starter-web'
implementation 'org.springframework.boot:spring-boot-starter-data-jpa'
implementation 'org.springframework.boot:spring-boot-starter-data-redis'
}
Redis Dependency 추가
@Configuration
@EnableCaching
@EnableRedisRepositories
@RequiredArgsConstructor
public class RedisConfiguration {
private final ObjectMapper objectMapper;
private final RedisProperties redisProperties;
private final SentinelProperties redisSentinelProperties; // 1
@Bean
public RedisConnectionFactory redisConnectionFactory(RedisSentinelConfiguration redisSentinelConfiguration, LettuceClientConfiguration lettuceClientConfiguration) {
return new LettuceConnectionFactory(redisSentinelConfiguration, lettuceClientConfiguration);
}
@Bean
public RedisSentinelConfiguration redisSentinelConfiguration() {
return new RedisSentinelConfiguration(redisSentinelProperties.getMaster(), redisSentinelProperties.getNodes());
}
@Bean
public LettuceClientConfiguration lettuceClientConfiguration() {
return LettuceClientConfiguration.builder()
.readFrom(ReadFrom.REPLICA_PREFERRED) // 2
.commandTimeout(Duration.ofSeconds(redisProperties.getTimeout()))
.build();
}
@Bean
public CacheManager cacheManager(RedisConnectionFactory cf) {
RedisCacheConfiguration productConfig = RedisCacheConfiguration.defaultCacheConfig()
.prefixCacheNameWith(RedisProperties.ENVIRONMENT + "_") // prefix
.serializeKeysWith(RedisSerializationContext.SerializationPair.fromSerializer(new StringRedisSerializer()))
.serializeValuesWith(RedisSerializationContext.SerializationPair.fromSerializer(new Jackson2JsonRedisSerializer<>(Product.class)));
RedisCacheConfiguration userConfig = RedisCacheConfiguration.defaultCacheConfig()
.prefixCacheNameWith(RedisProperties.ENVIRONMENT + "_") // prefix
.serializeKeysWith(RedisSerializationContext.SerializationPair.fromSerializer(new StringRedisSerializer()))
.serializeValuesWith(RedisSerializationContext.SerializationPair.fromSerializer(new Jackson2JsonRedisSerializer<>(User.class)));
return RedisCacheManager.RedisCacheManagerBuilder
.fromConnectionFactory(cf)
.withCacheConfiguration("Product", productConfig) // 3
.withCacheConfiguration("User", userConfig)
.build();
}
@Bean
public RedisTemplate<?, ?> redisTemplate(RedisConnectionFactory redisConnectionFactory) {
RedisTemplate<String, Object> redisTemplate = new RedisTemplate<>();
redisTemplate.setConnectionFactory(redisConnectionFactory);
redisTemplate.setKeySerializer(new StringRedisSerializer());
redisTemplate.setValueSerializer(new GenericJackson2JsonRedisSerializer(objectMapper));
return redisTemplate; // 4
}
}
RedisTemplate은 Redis 자료구조별 적절한 메서드를 통한 상세 제어가 가능합니다.
@Service
@RequiredArgsConstructor
public class ExampleService {
private final RedisTemplate<String, String> redisTemplate;
public void example() {
redisTemplate.opsForValue().set("key1", "Data", 10, TimeUnit.DAYS); // String 자료구조에 'key1'을 key로하는 데이터 set
redisTemplate.opsForValue().get("key1");
redisTemplate.opsForHash().get("key1", "hashKey2"); // Hash 자료구조 데이터 조회
}
}
이외에도 opsForList(), opsForSet(), opsForZSet()등의 Redis의 자료구조별 접근 기능을 제공합니다.
JPA Data Repository 형태로 Redis CRUD 기능을 지원합니다.
@Getter
@RedisHash // 1
public class ProductCache {
@Id // 2
Long productId;
@TimeToLive // 3
Long ttl;
UserProduct product;
}
import org.springframework.data.repository.CrudRepository;
public interface ProductRepository extends CrudRepository<ProductCache, Long> { // 4
}
@Service
@RequiredArgsConstructor
public class ExampleService {
private final ProductRepository productRepository;
public void example() { // 5
productRepository.save(product);
productRepository.findAll();
productRepository.findById(productId);
productRepository.delete(product);
}
}
@Cacheable(value ="User", key="#userId", unless = "#result == null", cacheManager= "cacheManager") // 1
public Optional<User> findByUserId(long userId) {
return userRepository.findById(userId);
}
@Transactional
@CacheEvict(value="User", key="#userVo.userId", cacheManager= "cacheManager") // 2
public void updateUser(UserVo userVo) {
User user = ....;
user.update(userVo);
}
@Transactional
@CachePut(value="User", key="#result.userId", cacheManager= "cacheManager") // 3
public User updateUser(UserVo userVo) {
User user = ....;
user.update(userVo);
return user;
}
절대적인 성능 차이 확인을 위한 비교는 아니며, 캐싱 전후의 성능 차이 확인을 위해 간단히 비교를 진행했습니다.
위의 성능 비교는 둘의 용도는 다르고 시스템 구성/데이터등 영향을 받는 요소가 많은 부분입니다. 시스템에 맞춰 구현시 상세한 성능 테스트가 필요한 부분입니다. 레디스를 예를 들었지만, 이외에도 많은 캐시 솔루션이 있으며 상황에 맞는 캐시 솔루션을 판단하여 사용해야 합니다.
이번 글에서는 캐싱에 대한 개요와 간단한 구현에 대해서 알아보았습니다. 개발을 하며 가볍게 사용해 왔던 캐싱에 관해 정리할 수 있는 기회가 됐던 것 같습니다. 이후 아티클을 통해 레디스의 구조, 전략 등에 대해 설명드리도록 하겠습니다.
<원문>
©️요즘IT의 모든 콘텐츠는 저작권법의 보호를 받는 바, 무단 전재와 복사, 배포 등을 금합니다.