AI
AI 전성시대, CPU 아닌 GPU가 주목받는 이유

12분
2023.10.31.29.4K
소프트웨어 개발뿐 아니라 사회 전반적으로 AI가 큰 화두입니다. 초거대언어모델(LLM, Large Language Model)인 ChatGPT를 전 세계 사람들이 사용하는 시대가 도래했습니다. 이러한 기술의 발전이 놀라우면서도 한편으론 두렵기도 한데요. 이번 글에서는 AI 기술 발전과 함께 언급되는 GPU(Graphical Processing Unit)*의 개념, CPU와의 차이점을 통해 AI에서 GPU가 왜 필요한지 알아보고자 합니다.
아마도 어렴풋이 AI를 하기 위해선 GPU가 필요하다고 알고 있거나, 많은 데이터를 처리하기 위해서라고 알고 계신 분들도 있을 겁니다. 보통 우리가 사용하는 CPU로는 안 되냐는 의문도 들고, GPU 서버 1대에 몇 억 원씩 하는 장비가 왜 필요한지 모르는 의사결정권자도 있을 수 있습니다. 지금부터 왜 CPU가 아닌 GPU가 AI에 최적화된 장비인지 살펴보겠습니다.
*GPU(Graphical Processing Unit)는 그래픽을 처리하는 보조 장치를 말합니다. AI 모델 개발에 사용되는 GPU는 그래픽 기능을 제외하고, 연산 기능에 초점을 맞춘 GPGPU(General Purpose Graphical Processing Unit)입니다. 하지만 대부분은 GPGPU도 GPU로 통칭하는 경우가 많이 본 글에서도 모두 GPU로 통일하도록 하겠습니다. 이번 글에서 나오는 대부분의 GPU는 GPGPU를 의미합니다.
본격적으로 GPU 이야기를 시작하기 전, AI 역사에서 3번의 전성기와 2번의 침체기(AI Winter)에 대해 먼저 알아보겠습니다.
AI 시대를 나누는 기준은 각기 다른데요. 이번 글에서는 유럽 평의회(COE, Council of Europe) 홈페이지에서 정리한 ‘History of Artificial Intelligence’ 내용을 살펴봤습니다. 유럽 평의회에서는 AI 시대를 크게 세 번으로 나눕니다.
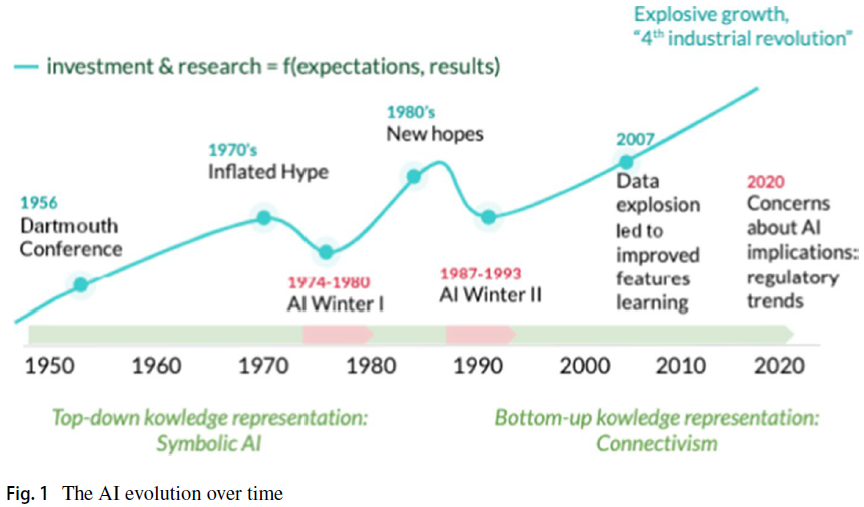
첫 번째는 AI의 태동기인 1940년대부터 1960년대까지입니다. 최초의 AI 작업은 Warren McCulloch와 Walter Pitts가 1943년도에 뉴런을 컴퓨터로 모델링한 것입니다. 그리고 MIT의 McCarthy가 1956년 ‘AI’라는 단어를 정의했습니다. 학술적으로 많은 연구가 있었지만, 당시 컴퓨팅의 열악한 환경 때문에 AI의 시대가 활짝 열리지는 않았습니다. 그렇게 한동안 첫 번째 AI 겨울이 찾아왔습니다.
두 번째 AI 전성기는 1980년대부터 1990년대까지입니다. 이 시기는 마이크로프로세스의 발달로 빠른 정보처리가 가능하게 되었습니다. 개인용 컴퓨터(PC)가 보급되면서 대규모 컴퓨터에 접근하기 위해서 어렵게 권한을 획득해야 할 필요성이 없어졌을 뿐 아니라, PC로도 많은 업무 처리할 수 있게 되었죠. 이때 등장한 AI의 기술은 전문가 시스템입니다. 전문가 시스템은 특정 영역의 지식이나 정보처리 체계를 내재한 소프트웨어, 하드웨어를 통해 빠르게 업무나 정보를 처리하는 시스템입니다.
지금의 AI와는 형태나 처리 방법에서 차이가 있지만, 사람이 아닌 컴퓨터를 통해 전문 지식 체계를 사용하는 것이 인공지능임을 생각한다면 왜 인공지능이란 말을 사용했는지 수긍되실 겁니다. 이 시기의 인공지능은 규칙 기반(Rule-based) 시스템으로, 특정 영역의 지식에 대한 처리 규칙을 컴퓨터가 빠르게 처리하는 방식이었습니다. 그리고 1997년 IBM의 딥블루가 체스 세계 챔피언을 이기는 AI 진영의 쾌거도 있었습니다. 하지만 규칙 기반이라는 한계, 여전히 많은 데이터를 처리하지 못하는 컴퓨팅의 한계로 다시 겨울을 맞이하게 되었습니다.
그리고 2010년대 알파고(AhphaGo)라는 인공지능 바둑 프로그램과 2023년 현재 ChatGPT 등으로 세 번째 AI 전성기가 열리게 됩니다. 뉴런의 깊은 층에서 희석되던 값을 유지할 수 있는 기법의 등장과 대규모 데이터를 빠르게 처리할 수 있는 장치의 등장이 세 번째 전성기를 이끌게 된 것이죠.
현재 딥러닝 기술의 눈부신 발전은 그레디언트 소실*(Gradient Vanishing)에 대한 이론적인 해결과 이로 인해 깊어진 신경망을 처리할 수 있는 컴퓨팅의 발전의 합작품이라고 할 수 있습니다.
*그레디언트 소실(Gradient Vanishing)은 뉴런의 깊은 층으로 전달되던 값이 희석되는 현상을 말합니다.
이 중에서 오늘은 컴퓨팅에 관해 이야기 해보려 합니다. 이쯤에서 한 가지 궁금증이 생길 수 있습니다. 우리가 사용하고 있는 AI 모델, 특히 딥러닝 모델의 신경망은 얼마나 많은 계산이 필요할까요? 즉, 컴퓨터가 얼마나 열심히 일을 해야 하는지입니다. 신경망은 깊이와 파라미터(Parameter) 개수도 중요하지만, 네트워크마다 구성이 다르기 때문에 계산량 자체를 비교하는 것이 가장 직관적일 것 같습니다. 아래 그림은 모델 학습을 위한 계산량을 비교해 놓은 것입니다.
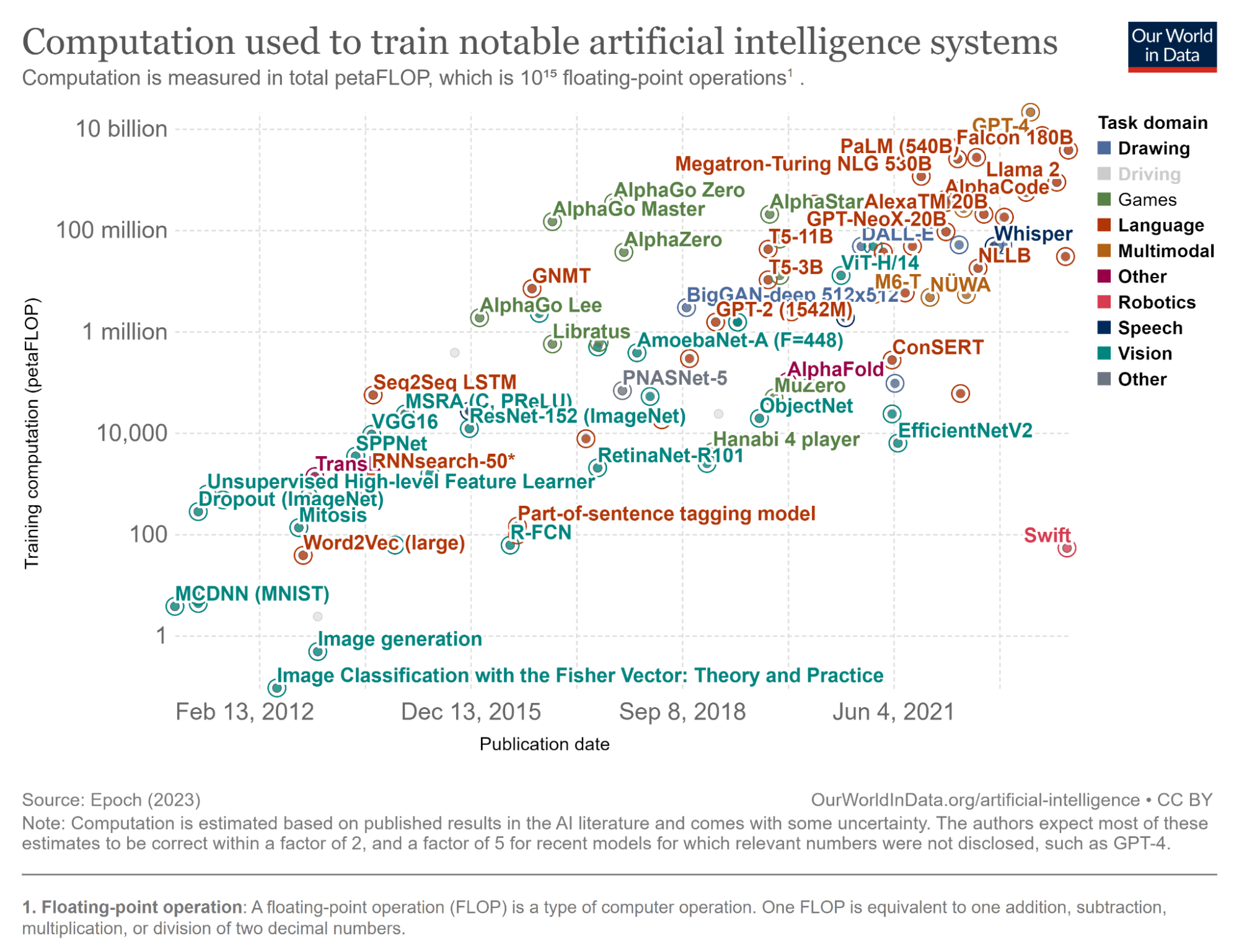
최근 모델들과 비교하기 위해서 2012년 초부터 살펴봤습니다. Y축은 로그 스케일입니다. 눈금 하나가 100배 차이를 나타내며, 언어 모델의 계산 필요량이 확실히 많은 것을 확인할 수 있습니다. Y축 단위의 FLOP은 부동소수점 연산입니다. GPT-4, Falcon 180B, PaLM(540B)과 같은 모델을 학습하기 위해서는 10 billion petaFLOP이 필요합니다. 10 billion petaFLOP이라고 하면 1010 x 1015 = 1025번의 부동 소수점 연산이 필요하다는 이야기입니다. 숫자가 너무 커서 잘 와닿지 않는데, CPU를 사용했을 때 소요될 수 있는 시간을 계산해 보겠습니다.
우선 인텔에서 공개한 자료에서 CPU의 FLOPs를 확인할 수 있습니다. FLOPs는 초당 처리 가능한 부동 소수점 연산 능력입니다. 해당 자료에서 가장 높은 FLOPs를 가진 CPU가 Intel® CoreTM i9-12900KF이며, 약 819.2 GFLOPs로 819.2 * 109입니다.
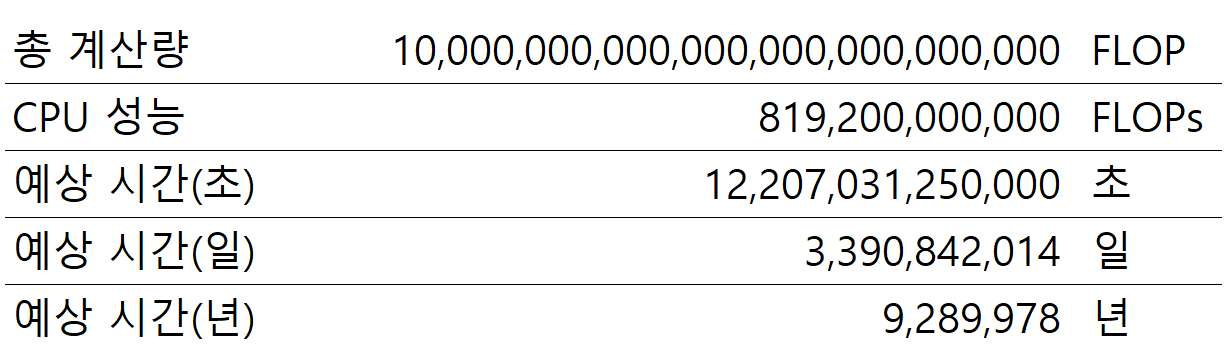
계산된 수행 시간은 여러 다른 변수가 있어 정확하지 않을 수 있지만, 대략의 스케일을 짐작할 수 있게 계산해 봤습니다. CPU 한 개, 즉 컴퓨터 한 대로 GPT-4를 학습하려면 대략 9백만 년이 걸립니다. 다시 말씀드리지만 단순히 스케일을 비교하기 위한 계산입니다. 상업적인 목적을 위해서는 모델 학습에 컴퓨터 한 대만 사용하진 않겠지만, 이해하기 쉽게 단순하게 계산해 보면 어마어마한 시간이 필요하다는 것을 알 수 있습니다.
최신 AI 모델이 아닌 2017년에 개발된 알파고 제로로 계산하더라도, 약 9백만 년 정도의 시간이 걸립니다. 믿기지 않는 오랜 시간을 짧게 바꾸는 방법은 무엇이 있을까요? 첫 번째 방법은 CPU의 성능을 9백만 배로 빠르게 만들면 됩니다. 두 번째 방법은 CPU 9백만 개를 한 번에 사용할 수 있게 하면 됩니다. 말이 안 되는 소리 같지만 실제로 이 방법으로 문제를 해결했는데요. GPU가 활발히 사용되기 전에는 CPU가 10~20개 정도 들어가는 서버 수백 대를 연결해서 사용했습니다.
이러한 방식을 슈퍼컴퓨터라고 하고, 전문 용어로는 HPC(High Performance Computer)라고 부릅니다. HPC를 제대로 활용하기 위해서는 매우 많은 기술적인 노력이 필요합니다. 그래서 여러 개의 서버나 CPU를 사용하는 것보다는 CPU가 빨라지는 게 훨씬 수월합니다. 그 수월한 방법이 바로 GPU를 사용하는 것입니다.
23년 현재 가장 최신 서버용 GPU인 Nvidia H100의 연상 능력은 얼마일까요? H100의 공식 데이터 시트의 FLOPs를 확인해 보면 NVLink bridge를 사용하는 H100의 FP16 연산 FLOPs는 무려 3,958teraFLOPs입니다. 앞서 계산한 예상 시간을 H100으로 다시 계산해 보면 다음과 같습니다.
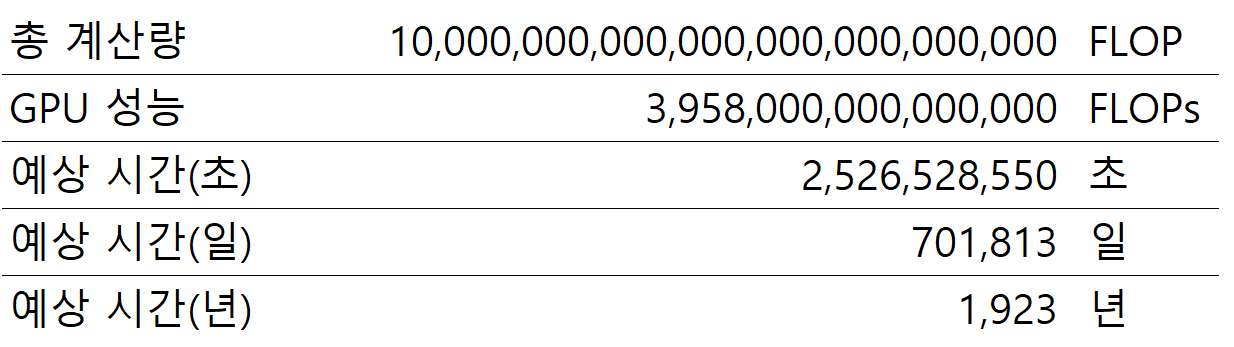
GPU를 사용하면 약 2천 년 정도면 현재 가장 커다란 모델을 학습할 수 있습니다. 실제 서버에 사용되는 GPU 숫자를 사용하여 한 번 더 계산해 보죠. 우리가 사용하는 GPU 서버는 8개의 GPU를 동시에 사용합니다. 그렇다면 GPU 성능을 GPU 서버 성능으로 바꾸면 어떨까요?
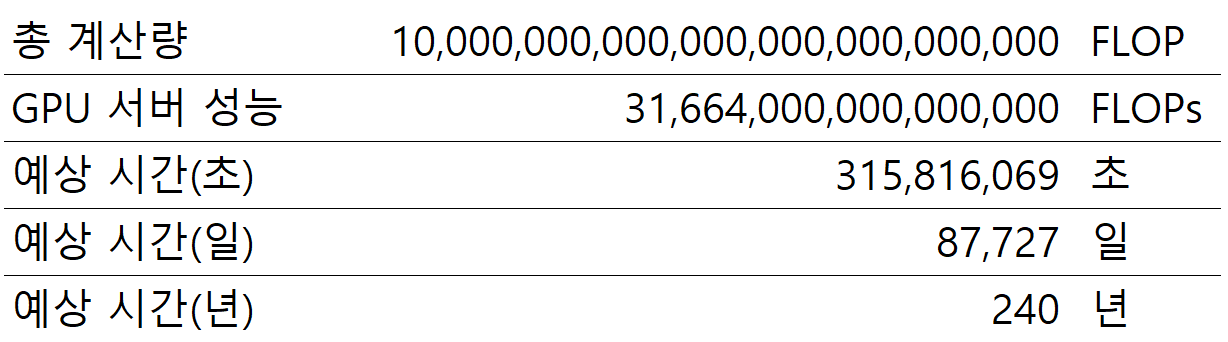
240년 만에 모델을 학습할 수 있게 되었습니다. CPU도 여러 개를 사용하면 예상 시간이 줄어들겠지만, 9백만 시간을 줄이는 것은 쉬운 일이 아닙니다. 자 이제 240년 만에 모델 학습이 가능해졌습니다. 그러면 우리가 240대의 서버를 사용하면 1년 만에 학습이 가능하다는 이야기가 됩니다. 그리고 그 12배인 2,880대의 GPU 서버를 사용하면 단 1개월 만에 최대 계산량이 필요한 모델을 학습할 수 있는 것입니다.
GPU 서버가 너무 많아서 현실적이지 못하다고 생각하시나요? 그렇지 않습니다. Nvidia의 슈퍼팟(SuperPOD)은 수십, 수백 대의 GPU 서버로 구성된 GPU 서버 클러스터 제품입니다. 물론 비용은 매우 비싸겠죠.
다시 한번 말씀드리지만 위 계산법은 개념적으로 알기 쉽게 계산한 어림치입니다. 이외에도 데이터를 저장하고 가져오는 스토리지, 서버 간 네트워크 성능 등 수없이 많은 기술이 필요합니다. 그러나 AI 개발에 GPU가 필수적인 장비라는 것은 틀림없는 사실입니다.
이러한 계산 능력의 차이는 CPU 제조사가 GPU 제조사보다 기술력이 떨어져서 일까요? 기술력에 대한 비교는 각자의 사정과 추구하는 바가 다르기 때문에 직접적인 비교가 어렵겠지만, CPU든 GPU든 제조사 기술력 차이가 FLOPs의 차이만큼은 아닐 거라 생각합니다.
그렇다면 왜 GPU의 계산 성능은 CPU보다 좋을까요, GPU가 더 좋으면 컴퓨터의 CPU를 모두 GPU로 교체하면 더 좋지 않을까요? 왜 이런 차이가 발생하는지를 살펴보기 위해 CPU와 GPU의 차이점을 알아보겠습니다.
CPU와 GPU의 가장 큰 차이점은 CPU는 단독으로 동작한다는 점입니다. 컴퓨터가 CPU만으로 동작하지는 않지만, CPU가 없다면 모든 장치가 동작하지 않습니다. GPU의 경우 반드시 CPU가 있는 컴퓨터 본체에 부착되어서만 동작합니다. 컴퓨터의 모든 연산을 담당하는 중앙처리장치가 CPU입니다. GPU는 컴퓨터 본체에 부착되어 연산을 수행합니다. 그래서 GPU와 같은 장치를 보조 연산 장치라는 의미에서 영어로 Co-processor 또는 Hardware accelerator라고 합니다.
이렇게 이해하면 쉽습니다. 기본적인 흐름과 컨트롤은 CPU에서 관장하고, GPU는 대규모 계산 수행하는 구조가 일반적인 AI 학습의 전형이라고 보면 됩니다. 바꾸어 말하면 CPU와 GPU가 추구하는 목적이 다릅니다. 목적이 다르기 때문에 내부 구조(아키텍처)가 다릅니다. 잠시 CPU 아키텍처(인텔 아키텍처)와 GPU 아키텍처를 비교해 본 후, 개념적인 정리를 다시 해볼게요. 개념을 먼저 정리하면 처음에는 이해가 쉽지만, 계속해서 발전하는 각각의 아키텍처를 이해하기 어렵습니다.
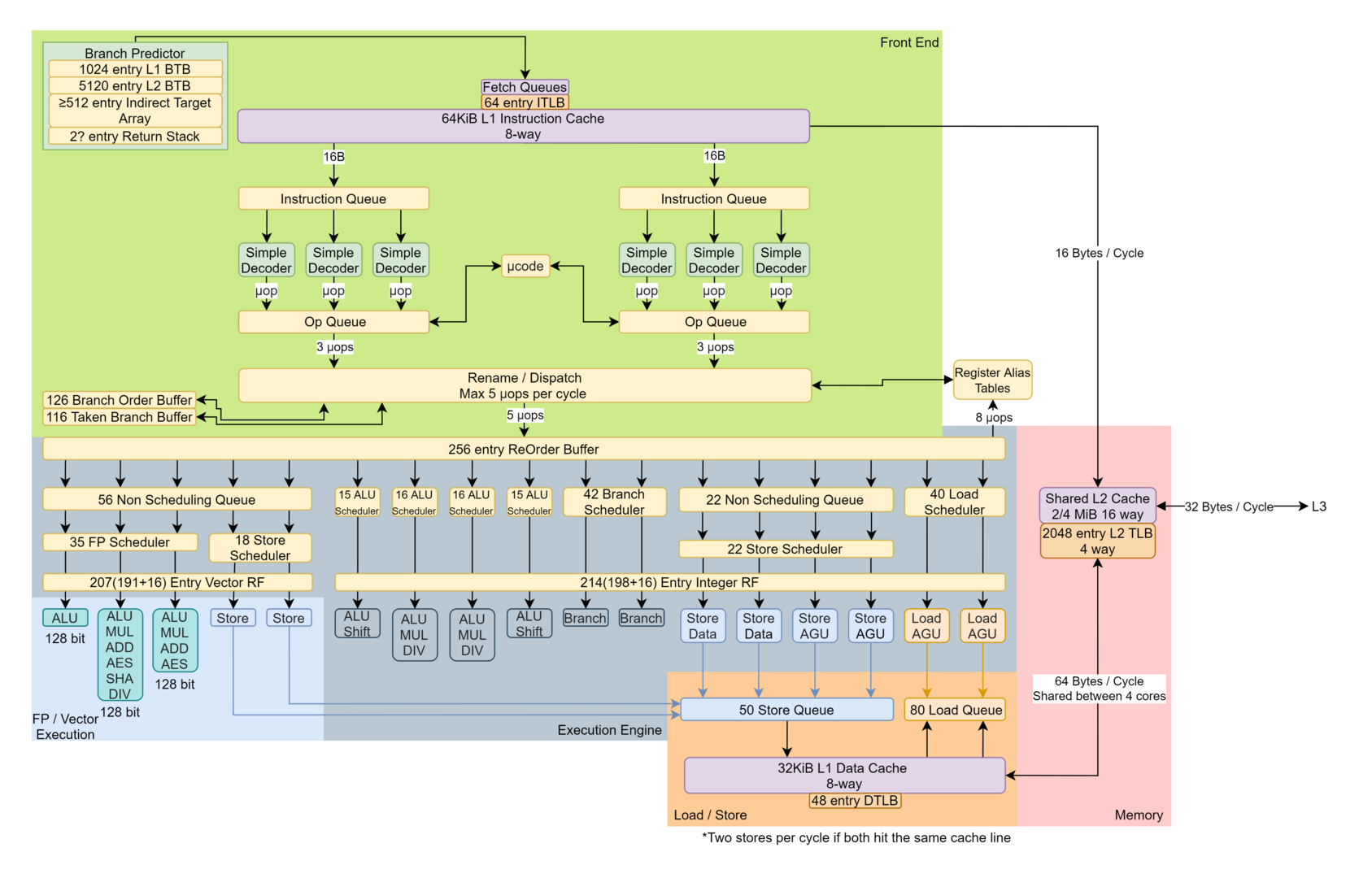
인텔의 Gracemont CPU Core입니다. CPU의 코어는 컴퓨터 메인보드에 있는 CPU 전체가 아닙니다. 우리가 생각하는 네모난 CPU는 연산 처리를 위한 CPU 코어 여러 개와 그래픽, CPU 캐시 메모리 등을 칩에 포함하고 있습니다. Branch Predictor는 프로그램의 동작이 어떤 분기로 진행해야 할지를 판단하고, Instruction Cashe, Simple Dispatcher는 분기별로 실행해야 할 명령어를 연산을 직접 수행해야 할 ALU 등으로 보내주는 역할을 합니다. 이런 코어가 4개 있으면 4코어 CPU, 8개 있으면 8코어 CPU라고 합니다.
ALU는 산술 논리 장치(Arithmetic and Logical Unit)의 약자로 사칙연산을 비롯한 XOR, NOT과 같은 논리 연산을 수행하는 장치입니다. 구조도를 다시 한번 보면 명령어를 처리할 시기와 처리할 명령어를 해석하는 Branch Predictor, Dispatcher는 Front End인 녹색 박스에, ALU는 Execution Engine인 옅은 남색 박스에 위치해 있습니다. ALU가 코어 안에 꽤 많아 보입니다. 이런 코어가 4개 있으면 4코어 CPU, 8개 있으면 8코어 CPU라고 합니다.
이번에는 GPU 아키텍처를 살펴보겠습니다. GPU에서 인텔 CPU의 코어에 해당되는 모듈이 SM(Streaming Multiprocessor)입니다.
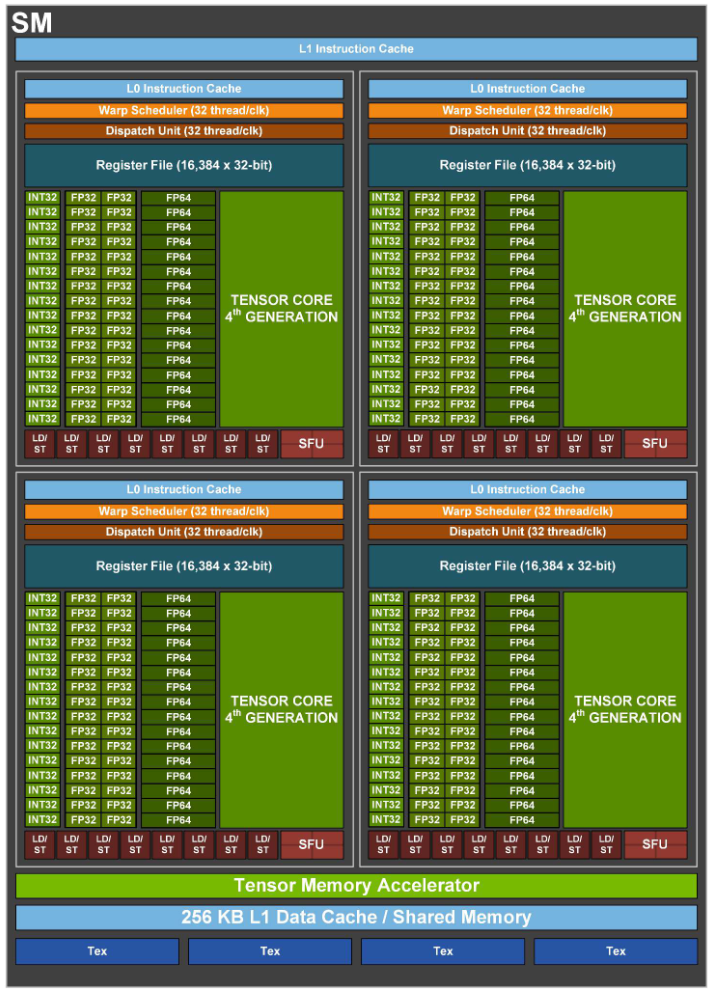
CPU와 구조가 많이 다릅니다. SM은 4개의 묶음으로 되어 있습니다. 각 묶음은 명령어를 처리하는 Warp Scheduler와 Dispatch Unit이 있습니다. 각 묶음에는 여러 종류의 ALU가 존재하는데 데이터의 종류에 따라 INT32, FP32, FP64, Tensor core, LD/ST, SFU로 구별됩니다. 묶음의 대부분을 차지하는 이 단어들이 모두 ALU를 나타냅니다. 두드러지는 특징은 CPU 코어에 비해 ALU가 많다는 것입니다. 그리고 컨트롤 유닛이라고 하는 Dispatcher, Predictor가 상대적으로 적습니다. 수많은 ALU가 동일한 명령어로 대량의 데이터를 처리하기 때문입니다 컨트롤 유닛이 매우 적은 것입니다.
다량의 데이터를 동일한 연산 방식으로 처리하는 방식을 SIMD(Single Instruction, Multiple Data)라고 합니다. 엔비디아의 GPU는 명령어를 여러 스레드에서 대량의 데이터를 처리하는 방식 ‘SIMT(Single Instruction, Multiple Thred)’를 사용합니다. 데이터에 초점이 있는 것이 아니라 연산에 더 집중한 것이죠. 스레드는 SM내의 묶음 속 Wrap라는 단위로 실행됩니다.
그런데 CPU와 비교해서 ALU가 조금 많은 것 같지만, 앞에서 비교한 숫자만큼의 차이는 아닌 것 같습니다. 앞서 계산한 엄청난 차이의 비밀은 SM이 얼마나 많은가에 있습니다. 그림으로 확인했던 CPU 코어가 우리가 사용하는 PC에는 8개 정도, 서버용 CPU에는 24~64개 정도가 사용됩니다. 그럼 GPU는 어떨까요? H100에 SM이 어떻게 배치되어 있는지 볼까요?
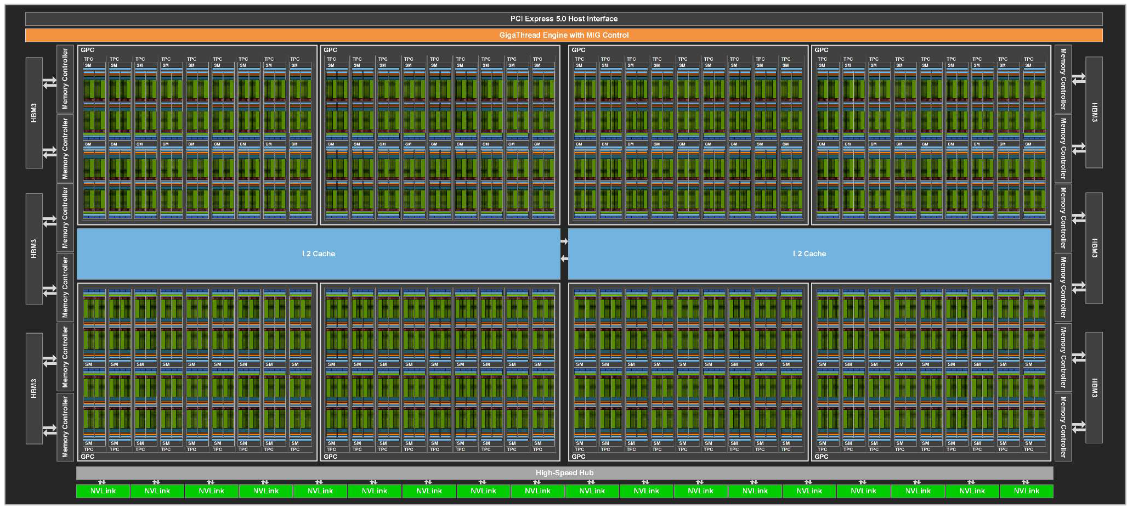
H100의 경우 SM이 144개 들어가 있습니다. 위 그림의 작은 사각형이 앞에서 본 SM입니다. 그리고 H100 8개를 하나의 서버에서 사용합니다. H100 8개가 사용된 서버에는 ALU의 숫자가 어마어마하겠죠. ALU의 개수는 앞에서 계산할 때 사용된 FLOPs를 높이는 주요 장치이기 때문에, ALU의 규모가 계산 성능을 좌우하게 됩니다.
CPU와 GPU를 비유적으로 표현해 볼까요? 회사에 유능한 직원 두 그룹이 있다고 가정해 봅니다. 한 그룹의 직원들은 다양한 업무를 잘 처리하는 직원들로 구성되어 있습니다. 이 직원들은 의사결정도 스스로 척척 알아서 하고 필요한 자원들을 잘 찾아냅니다. 다양한 업무를 잘 처리 하다 보니 연봉도 높습니다. 이 그룹을 C그룹이라고 할게요.
반면 다른 그룹의 직원들은 단일 업무 처리 속도가 엄청나게 빠릅니다. 주어진 업무에 대해서는 빠르고 확실하게 마무리할 수 있습니다. 그러나 주어진 업무에 대해서만 빠르게 처리하므로 연봉이 높은 편은 아닙니다. 두 번째 그룹은 예상하신 것처럼 G그룹입니다.

여러분이 회사에서 함께 프로젝트를 한다면 어떤 그룹과 일하고 싶으신가요? 아마도 프로젝트의 성격에 따라 달라질 것입니다. 과정이 복잡하거나 회사에서 경험해 보지 못한 일이라면 C그룹이 더 적합할 것입니다. 반대로 단순하지만 해야 할 일이 많고 이미 처리하는 방법을 잘 알고 있다면, G그룹과 함께하면 좋을 겁니다. 때에 따라서는 C, G그룹이 함께 하면서 구성원의 비율이 조정될 수도 있고요. 요점은 두 그룹의 좋고 나쁨을 가리는 것이 아니라, 프로젝트 성격에 따라 선택해야 한다는 것입니다.
예상하신 것처럼 C그룹은 CPU를 G그룹은 GPU를 비유한 것입니다. CPU는 프로그램이 실행되면서 내부에서 다양한 경로의 분기로 조정이 되거나, 일정 조건에서 실행이 변경되는 등의 복잡한 로직을 가진 프로그램에 적합합니다. 이 경우에도 하위 루틴에서 많은 계산이 필요하기 때문에 CPU 내부에도 SIMD가 구현되어 있습니다.
반면 GPU는 실행해야 할 계산이 정해진 상태에서 계산을 반복하는 것에 최적화 되어 있습니다. 우리가 사용하는 소프트웨어의 구조나 방식에 따라서 GPU가 CPU보다 더 느린 경우도 있을 수 있습니다. 특히 CPU가 컴퓨터 연산의 중심이기 때문에, 주변 장치와 데이터 교환이 많은 경우 보조 연산장치인 GPU를 사용할 때 추가적인 손해가 발생합니다. 이 부분은 기회가 된다면 따로 소개해 보겠습니다. 앞서 비유한 것처럼 CPU, GPU의 사용 선택 또는 어떤 기능을 CPU에서 돌리고, 어떤 기능을 GPU에서 동작하게 할지는 선택에 달려 있습니다. 소프트웨어에서는 선악(善惡)이 아닌 선택(選擇)만 있을 뿐이죠.
결국 선택이 중요한데 왜 AI에서는 GPU가 더 선택받고 있을까요? 앞서 CPU와 GPU의 차이에 관해 이야기했습니다. 따라서 GPU가 주목받는다는 것은 GPU에 더 적합한 과제가 많다는 뜻이죠. CPU도 분명 좋은 컴퓨팅 자원이지만, GPU에 적합한 소프트웨어가 더 많이 사용되고 있다는 것입니다.
특히 AI에서의 GPU 활용도가 매우 높은데요. 예시를 위해 딥러닝 모델을 활용한 AI 학습에 자주 사용되는 뉴럴 네트워크를 살펴보겠습니다.
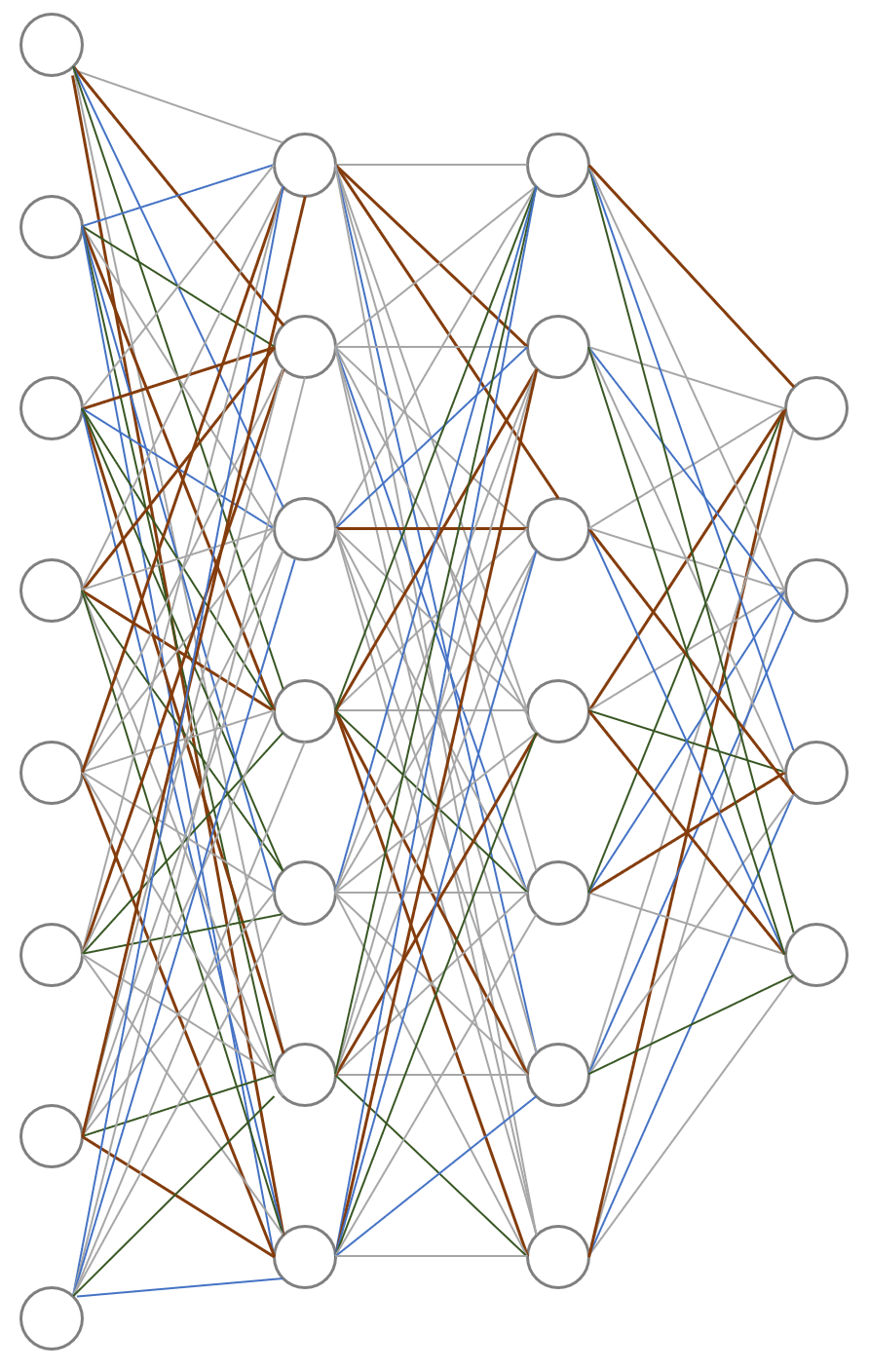
총 4개의 레이어로 구성되어 있는 간단한 뉴럴 네트워크 입니다. 첫 번째 레이어의 노드들이 두 번째 레이어의 입력으로 사용되면서 ax + b의 연산이 수행됩니다. 레이어를 내려가면서 연산을 진행하고, 오류를 측정한 후에 레이어를 타고 올 가면서 백프로퍼게이션을 수행합니다.
이때는 미분 연산이 진행됩니다. 그리고 이 과정을 수없이 반복합니다. 앞에서 말한 네트워크를 타고 내려가고 반대로 올라오면서 하는 연산들은 대부분 선형 방정식으로 계산합니다. 선형 방정식은 선형대수학을 기반으로 한 연산이고, 복잡한 행렬과 벡터들의 내적, 외적 연산입니다. 내적, 외적은 행렬과 벡터의 곱과 나누기 등의 연산입니다. 이런 연산을 텐서(Tensor) 곱, 텐서 연산이라고 합니다. 우리가 많이 사용하는 TensorFlow가 텐서 연산들의 흐름을 라이브러리화 했기 때문에 붙은 이름입니다.
설명이 조금 복잡하지만, 실제 연산은 사칙 연산을 기반으로 수행됩니다. 복잡한 딥러닝 연산을 조금 과장해서 말하면 엄청나게 많은 더하기, 빼기, 곱하기, 나누기의 반복입니다. 레이어가 고정되어 있고, 정해진 순서에 따라서 연산이 변경되기 때문에 분기도 복잡하지 않습니다. 다만 엄청나게 많은 사칙연산이 끊임없이 이루어집니다.
앞에서 어떤 연산 장치가 엄청나게 많은 ALU를 가지고 있었는지 기억나시나요? 복잡한 분기 없이 정해진 순서에 맞춰서 계산만 엄청나게 잘하는 장치가 바로 GPU입니다. 이러한 이유로 CPU가 아닌 GPU가 딥러닝의 주요 연산장치로 사용되는 것입니다.
GPU가 딥러닝에 주요 연산 장치로 사용되고, 관련된 라이브러리도 많아지면서 엔비디아는 GPU의 연산 성능을 높이는데 단순히 ALU를 더 많이 병렬로 붙이는 것외에도, 텐서 연산을 ALU 연산의 조합이 아닌 하드웨어적으로 연산할 수 있는 Tensor Core를 만들어 별도로 추가했습니다. 다음 그림은 A100과 H100의 텐서코어 개념화 그림입니다.
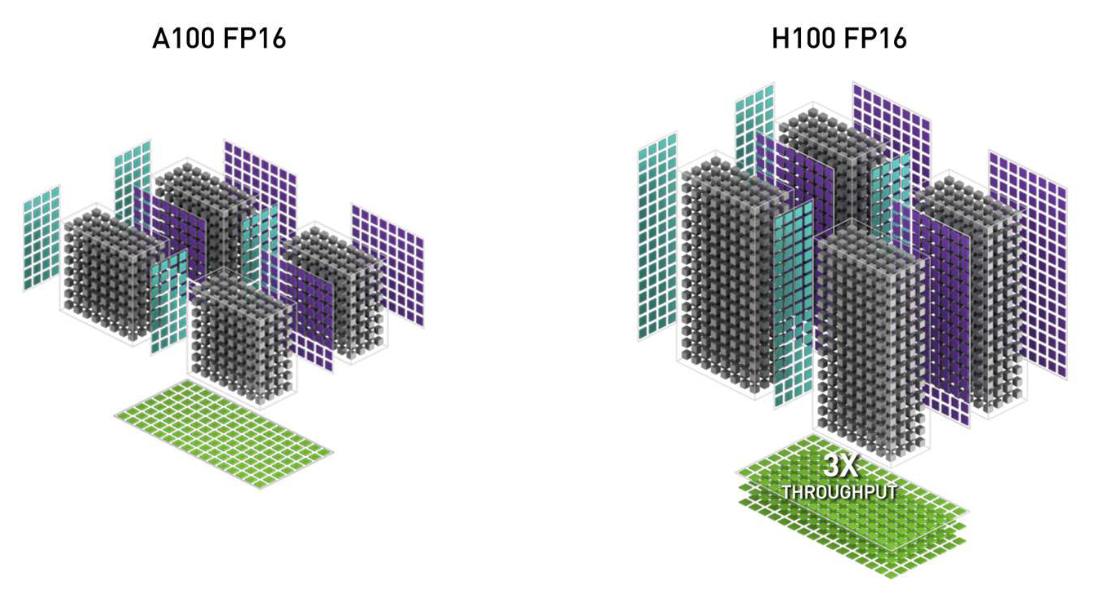
그리고 A100에서부터는 GPT-3로 주목받기 시작한 초거대언어모델(LLM)의 기본 뉴럴 네트워크 아키텍처 구조인 트랜스포머를 내부에 구현하여, 빠르게 동작할 수 있도록 했습니다. 이외에도 수도 없이 많은 기술이 GPU에서 내부 구현되어, AI 발전 속도를 눈부시게 향상시키고 있습니다.
지금까지 살펴본 GPU 개념과 마지막으로 설명한 딥러닝 구조, 연산 특징으로 인해 GPU는 AI의 핵심 하드웨어가 될 수 있었습니다. 금광 앞 청바지 장사가 가능했던 이유와 같죠.
지금까지 살펴본 내용들은 서버 1대에서, 특히 GPU 카드 1개에서 일어나는 일이었습니다. 하지만 앞서 개발 기간을 계산할 때 GPU 수백 개를 사용한다고 했는데요. 단순히 GPU를 수백 개 연결한다고 연산이 빨라지지는 않습니다. 이 과정에도 수많은 기술적인 발전이 있는데, 다음 글에서 한번 다뤄볼까 합니다. 그럼 이번 글을 통해 AI에 왜 GPU가 필요한지, 그 이유에 대한 청사진을 머릿속에 그려볼 수 있길 바라며 글을 마칩니다.
©️요즘IT의 모든 콘텐츠는 저작권법의 보호를 받는 바, 무단 전재와 복사, 배포 등을 금합니다.