개발
Git Internal API를 활용한 .git 탐험

9분
2023.10.30.4.1K
국내 유명 IT 기업은 한국을 넘어 세계를 무대로 할 정도로 뛰어난 기술과 아이디어를 자랑합니다. 이들은 기업 블로그를 통해 이러한 정보를 공개하고 있습니다. 요즘IT는 각 기업의 특색 있고 유익한 콘텐츠를 소개하는 시리즈를 준비했습니다. 이들은 어떻게 사고하고, 어떤 방식으로 일하는 걸까요?
이번 글은 국내 화장품 시장의 정보 비대칭 문제를 해결하고 있는 뷰티 앱 ‘화해’에서 Git Internal API를 활용한 방법에 대해 소개합니다.

git은 요즘 개발자분들의 필수 교양이 되어 가고 있습니다. git은 추상화가 잘 되어 있어, 제공되는 API만으로 손쉽게 버전 관리가 가능하기 때문에 이러한 인기를 얻은 게 아닌가 싶습니다. 이번 글에서는 git의 내부 동작을 일부 만들어가며 이해해 보고자 합니다. 대부분의 경우에는 이러한 깊이 없이도 유용하지만, 내부 동작을 이해하게 되면 여러 가지 최적화나 도구를 만드는 데 도움이 됩니다.
실제로 저희는 동작 원리를 공부하면서 git을 활용할 수 있는 도구들을 만드는 데 영감을 많이 얻었습니다. 이를 통해 모노레포 내에서 git clone시에 기존에 비해 최대 80% 용량을 감량하는 최적화 도구 등을 만들기도 했습니다.
git scm을 읽으면 Porcelain와 Plumbing이라는 용어가 자주 등장합니다. 직역하자면 변기와 배관이라는 뜻입니다. Porcelain(변기)는 git add, git commit 같이 편의를 제공하는 User Interface입니다. 반대로 Plumbing(배관)은 git의 내부에서 동작하는 Backend System을 의미합니다. Git을 사용하는 데에 있어서는 Porcelain를 아는 것만으로 충분하지만, 복잡한 활용을 위해서는 Plumbing을 이해할 필요가 있습니다.
자, 그럼 우리 함께 배관공이 되어봅시다.

git의 기초 구성 중에 반드시 필요한 요소는 HEAD, objects와 refs입니다. objects는 파일 시스템을 추상화한 객체입니다. 이는 blob, tree로 구성되어 있습니다. blob은 파일의 내용을 가지는 오브젝트이며 반면 tree는 디렉토리의 내용을 가지는 오브젝트입니다. refs는 이름에서 알 수 있듯 포인터입니다. refs는 key-value로 이루어져 있습니다. key에는 기억하기 쉬운 별칭을 value는 objects 참조 값이 포함됩니다.
HEAD는 refs내에 존재하는 수많은 포인터 중 현재 활성화된 포인터에 대한 정보를 기록하는 파일입니다. 이를 그림으로 표현하면 다음과 같습니다.

다만 git에서 정해놓은 프로토콜이 있어서 이를 참조해서 구성해 봅시다.
mkdir mario
cd mario
mkdir .git
mkdir -p .git/objects
mkdir -p .git/refs/heads
echo ref: refs/heads/example > .git/HEAD 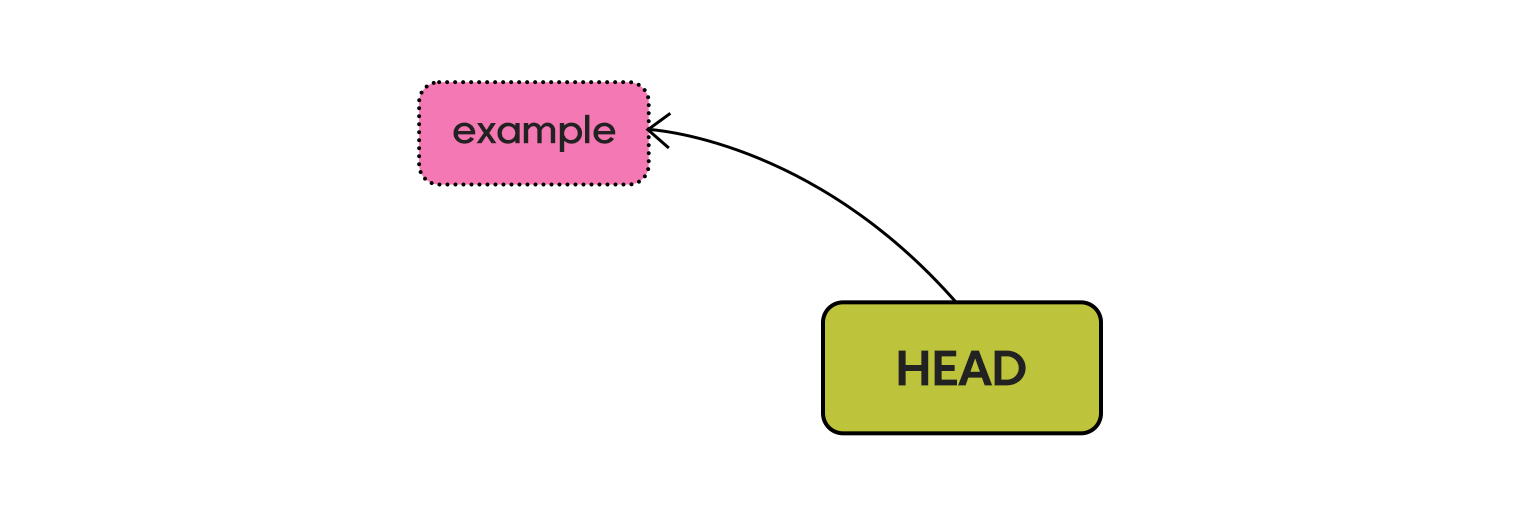
Blob
Blob은 Binary Large Object의 약어입니다. 이게 정확하게 무엇인지 설명하기보단 그냥 만들어보겠습니다.
var content = "console.log('Hello Mario')" // 파일의 내용
var header = `blob ${content.length}\0` // 파일의 메타 데이터
var store = header + content
var crypto = require('crypto')
var shasum = crypto.createHash('sha1')
shasum.update(store) // 내용과 메타데이터를 sha1 해싱
var hash = shasum.digest("hex")
var util = require('util');
var deflate = util.promisify(zlib.deflate);
위 코드를 요약하자면 다음과 같습니다.
sha1 해싱 처리를 하고 이를 저장할 경로로 사용한다.deflate 알고리즘을 이용해서 압축하여 저장한다.
이에 대한 결과는 다음과 같습니다.
.git
├── HEAD
├── objects
│ └── 8b
│ └── 8d0064cdef7af5e2aadb3cdcd7b7606bb3fd68
└── refs
└── heads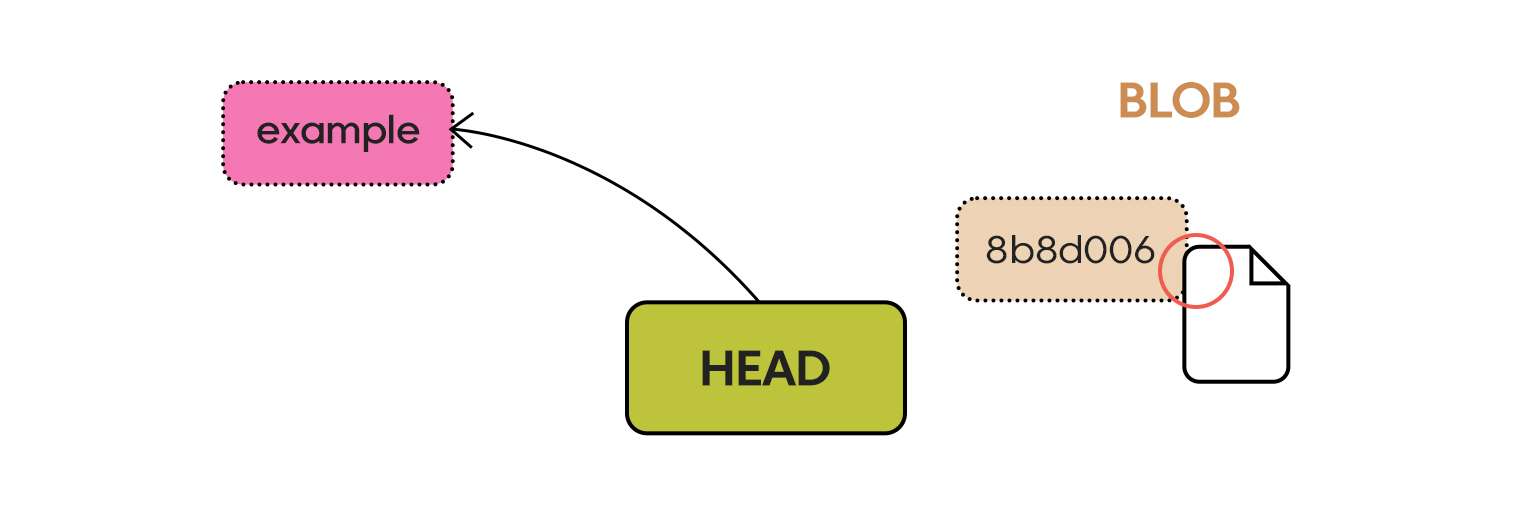
아래의 명령어를 이용하면 파일의 내용과 타입을 확인할 수 있습니다.
git cat-file -p 8b8d0064cdef7af5e2aadb3cdcd7b7606bb3fd68 # console.log('Hello Mario')
git cat-file -t 8b8d0064cdef7af5e2aadb3cdcd7b7606bb3fd68 # blob
Tree
tree는 blob과 달리 디렉토리 객체입니다. 디렉토리가 굳이 필수인 이유는 HEAD를 충족하기 위해서는 refs값이 반드시 필요합니다. 그리고 tree만이 refs의 값으로 사용할 수 있기 때문에 이를 충족하기 위해서는 반드시 필요합니다. 참고로 우리가 기본적으로 git init을 하게 됐을 때는 cwd가 tree로써 자동으로 생성됩니다.
설명이 길었는데, 어쨌든 생성해 보겠습니다. blob과 마찬가지로 직접 hash를 생성해 줘도 되지만 blob과 크게 동작방식이 다르지 않아서 git에서 제공하는 write-tree 명령어로 생성하겠습니다.
git write-tree
git cat-file -t $(hash) ## tree
결과는 다음과 같습니다. 주목할 점은 blob과 마찬가지로 파일로 objects에 관리된다는 점입니다.
.git
├── HEAD
├── index
├── objects
│ ├── 4b
│ │ └── 825dc642cb6eb9a060e54bf8d69288fbee4904 ## new
│ └── 8b
│ └── 8d0064cdef7af5e2aadb3cdcd7b7606bb3fd68
└── refs
└── heads
이제 git status를 사용해 봅시다.
git status
## No commits yet
## Untracked files:
status의 결과로는 Untracked 하는 것이 없고, No commits라고 하지만 제대로 동작하는 것처럼 보입니다.
자 이제, 이미 만든 blob을 tracking 해봅시다. tracking 하기 위해서는 stage 혹은 index라고 불리는 공간으로 파일을 등록하면 됩니다. 물론 git add를 하는 것이 일반적이지만 우리는 working directory 내에 아무런 폴더가 없습니다. 대신 blob에 있는 값을 활용해서 직접 stage로 업로드할 수 있습니다.
git update-index --add --cacheinfo 100644 8b8d0064cdef7af5e2aadb3cdcd7b7606bb3fd68 hello.js
결과는 다음과 같습니다.
No commits yet
Changes to be committed:
(use "git rm --cached <file>..." to unstage)
new file: hello.js
Changes not staged for commit:
(use "git add/rm <file>..." to update what will be committed)
(use "git restore <file>..." to discard changes in working directory)
deleted: hello.js
stage에 제대로 hello.js가 올라간 것을 확인할 수 있습니다. 그런데 deleted는 왜 존재할까요? stage에는 이미 업로드되어 있으나 working directory에는 없기 때문에, “삭제 작업을 진행한 파일” 로 인식하게 됩니다. 쉽게 생각하면 hello.js가 있는 commit이 있었는데, working directory 내에서 삭제 한 상황입니다.
자 이제 hello.js를 부활시켜 봅시다. 가장 간단하게 git reset을 이용할 수 있겠지만, 이전 커밋이 하나도 없으므로 이를 이용하기에는 어렵습니다. 대신 git add를 초기화하는 git restore 명령어를 이용할 수 있습니다.
git restore hello.js
이 결과는 다음과 같습니다.
./
├── .DS_Store
├── .git
│ ├── .DS_Store
│ ├── HEAD
│ ├── index
│ ├── objects
│ │ ├── 4b
│ │ │ └── 825dc642cb6eb9a060e54bf8d69288fbee4904
│ │ └── 8b
│ │ └── 8d0064cdef7af5e2aadb3cdcd7b7606bb3fd68
│ └── refs
│ ├── .DS_Store
│ └── heads
└── hello.js # <- new!!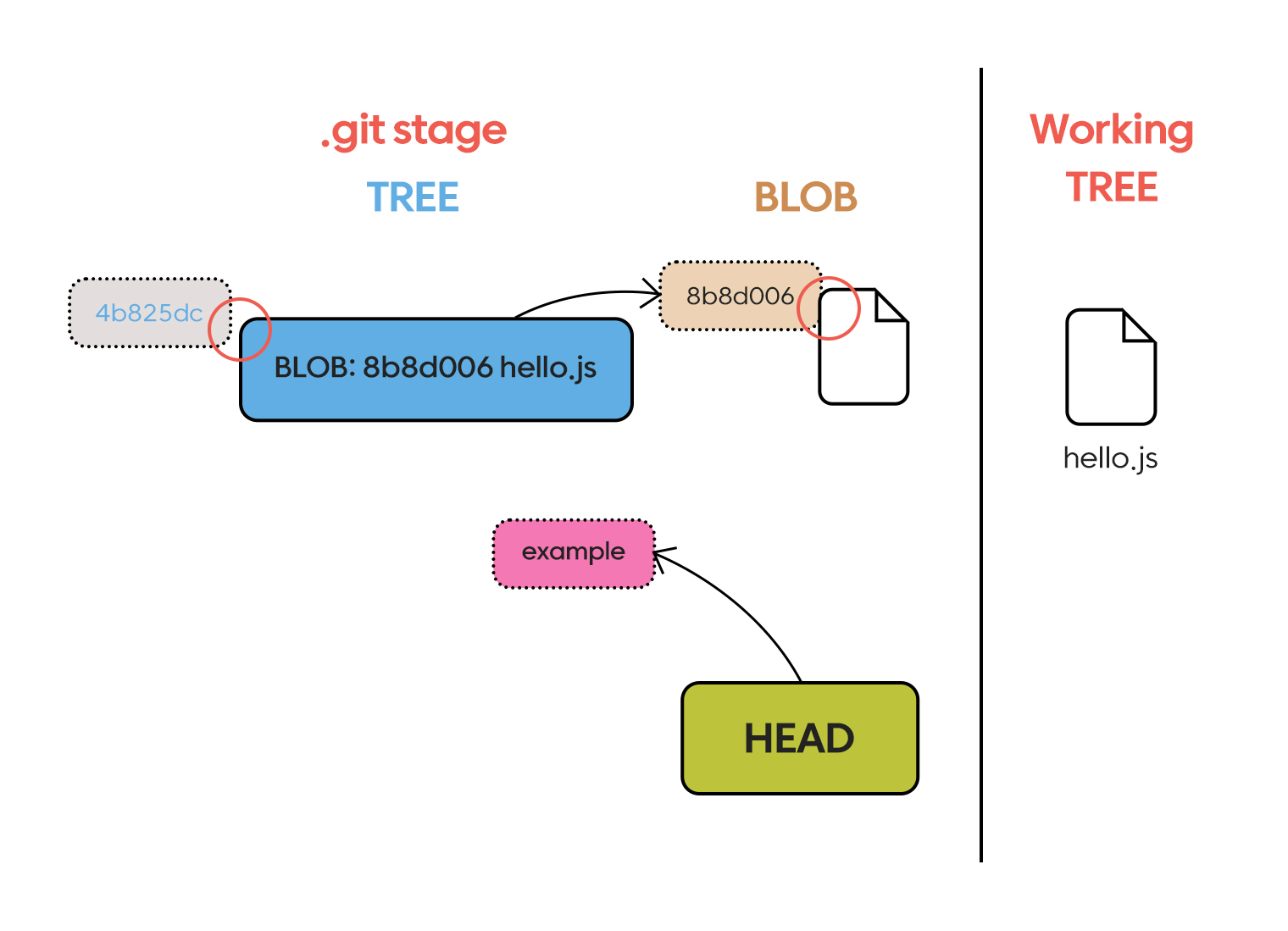
이제 working tree에 파일이 생성된 것을 확인할 수 있습니다.
Commit
그럼에도 여전히 git log에는 아무런 commit이 쌓이지 않았습니다. 당연하게도 git add를 통해 stage에 blob과 tree가 올라간 상황일 뿐입니다.
commit은 working tree의 스냅샷이라고 볼 수 있습니다. 때문에 tree의 참조 값을 넘겨주는 것으로 생성할 수 있습니다.
git commit-tree $(working-tree) -m "hello commit"
git cat-file -t $(commit)
git cat-file -p $(commit)
결과는 다음과 같습니다.
.git
├── HEAD
├── index
├── objects
│ ├── 15
│ │ └── 4edf456a1f24d3a65a35fa0b0272bf679ee9e7 ## commit-tree
│ ├── 4b
│ │ └── 825dc642cb6eb9a060e54bf8d69288fbee4904
│ └── 8b
│ └── 8d0064cdef7af5e2aadb3cdcd7b7606bb3fd68
└── refs
└── heads
자 이제 git log 명령어를 요청해 봅시다.
git log
# fatal: your current branch 'example' does not have any commits yet
결과는 다음과 같이 example 브랜치가 가진 commits 결과가 없다고 나옵니다. 현재 상황을 도식화하면 아래와 같습니다.
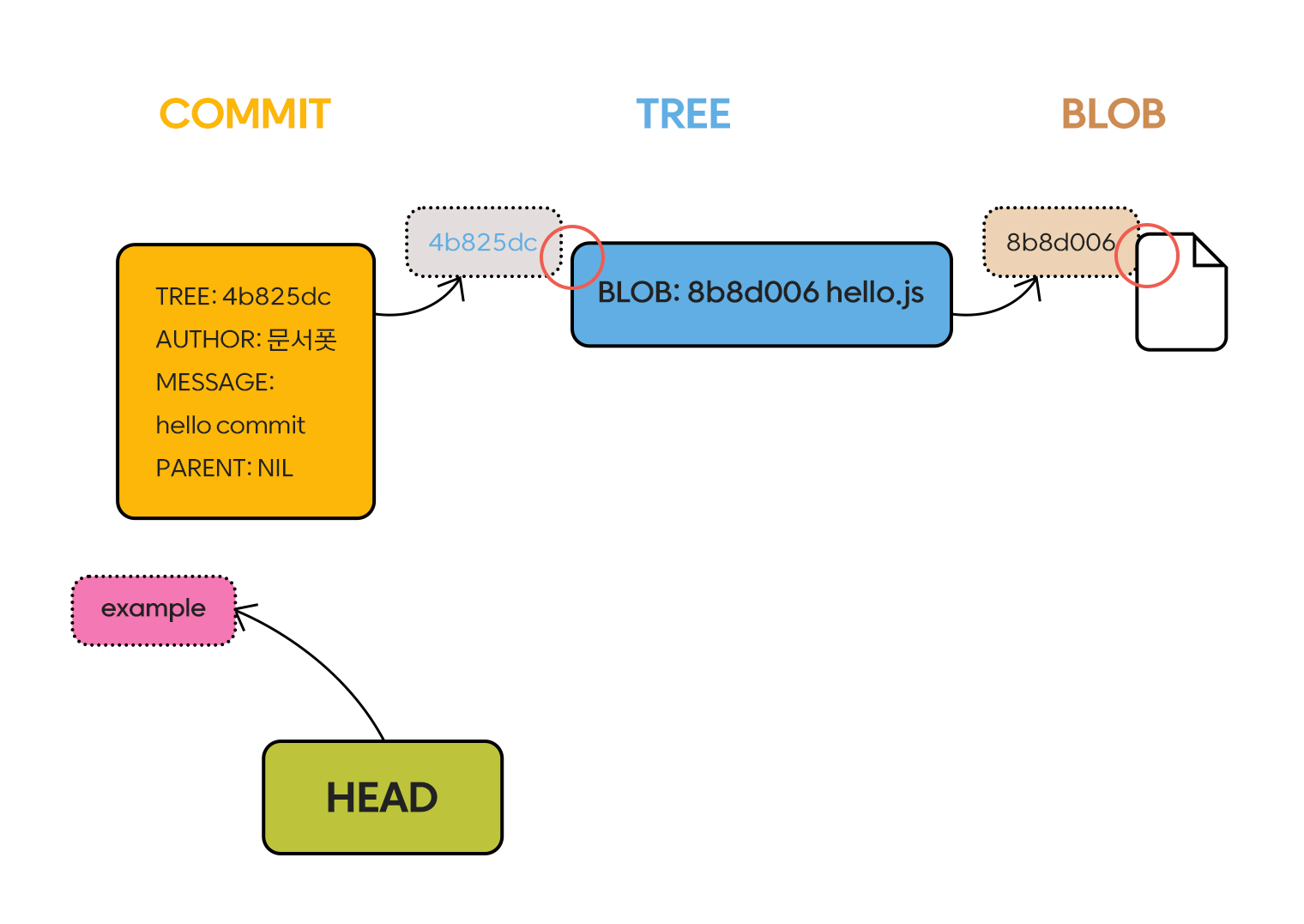
Branch
이전에 말했던 refs가 바로 Branch입니다.
refs의 구조에 따라 key-value를 세팅해 봅시다. key는 branch명인 example을, value에는 해당 브랜치가 참조할 commit-tree를 작성해 주도록 합니다.
echo [방금 생성한 commit-tree의 hash] > .git/refs/heads/example > .git/refs/heads/example
결과는 다음과 같습니다.
.git
├── HEAD
├── index
├── objects
│ ├── 15
│ │ └── 4edf456a1f24d3a65a35fa0b0272bf679ee9e7
│ ├── 4b
│ │ └── 825dc642cb6eb9a060e54bf8d69288fbee4904
│ └── 8b
│ └── 8d0064cdef7af5e2aadb3cdcd7b7606bb3fd68
└── refs
└── heads
└── example
git log
commit 154edf456a1f24d3a65a35fa0b0272bf679ee9e7 (HEAD -> example)
Author: MoonSupport <jiwon3346@naver.com>
Date: Thu Nov 24 23:09:10 2022 +0900
hello commit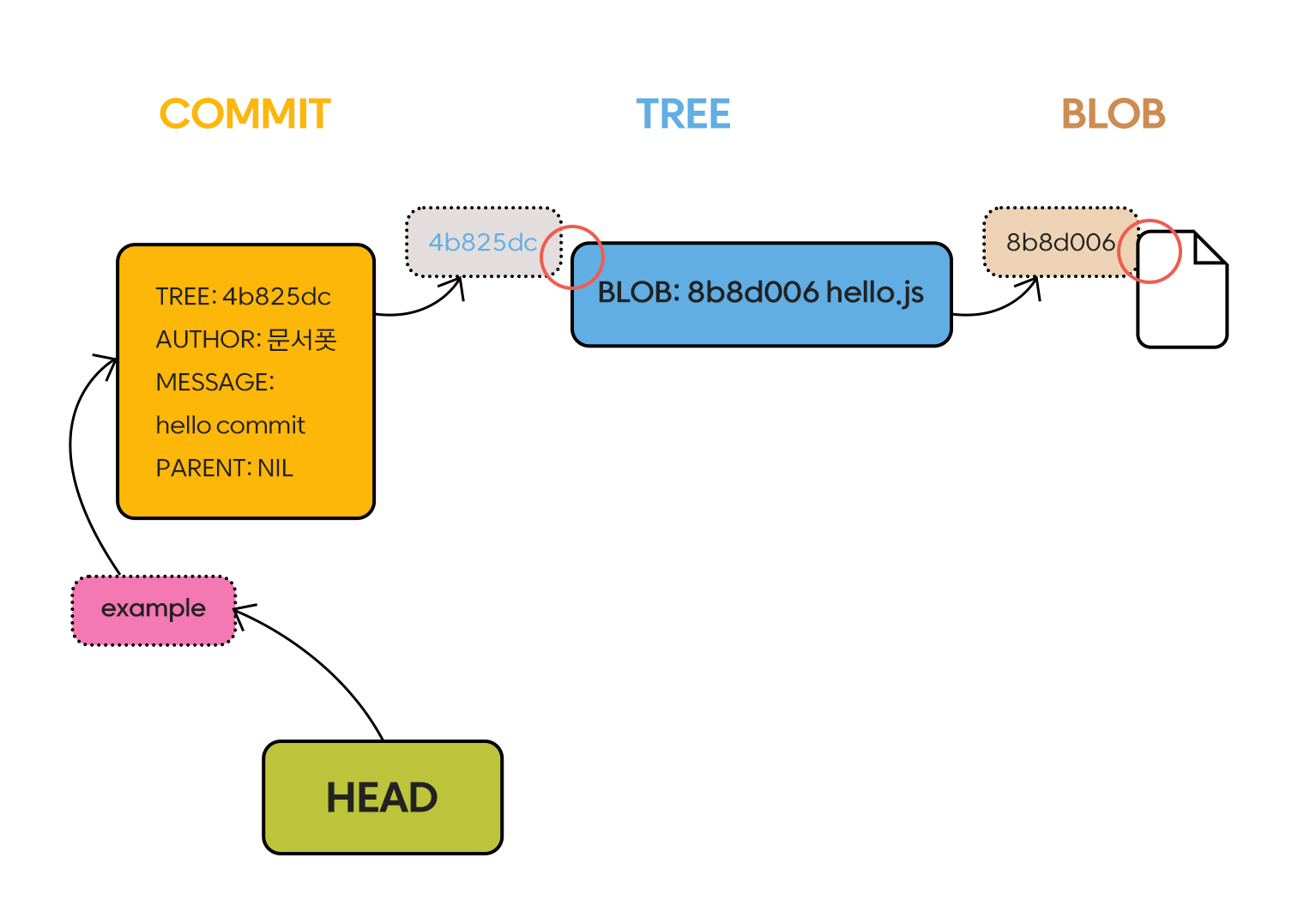
참조와 가비지 커밋
이론을 공부했으니 이제 조금 더 살아있는 예제를 만들어 보겠습니다.
echo "인덱스임니다" > index.js
mkdir apps
echo "메컵" > apps/makeup.js
echo "팩이용" > apps/package.json
git init
git add .
git commit -m "first commit"
이를 다이어그램으로 그리면 다음과 같습니다.
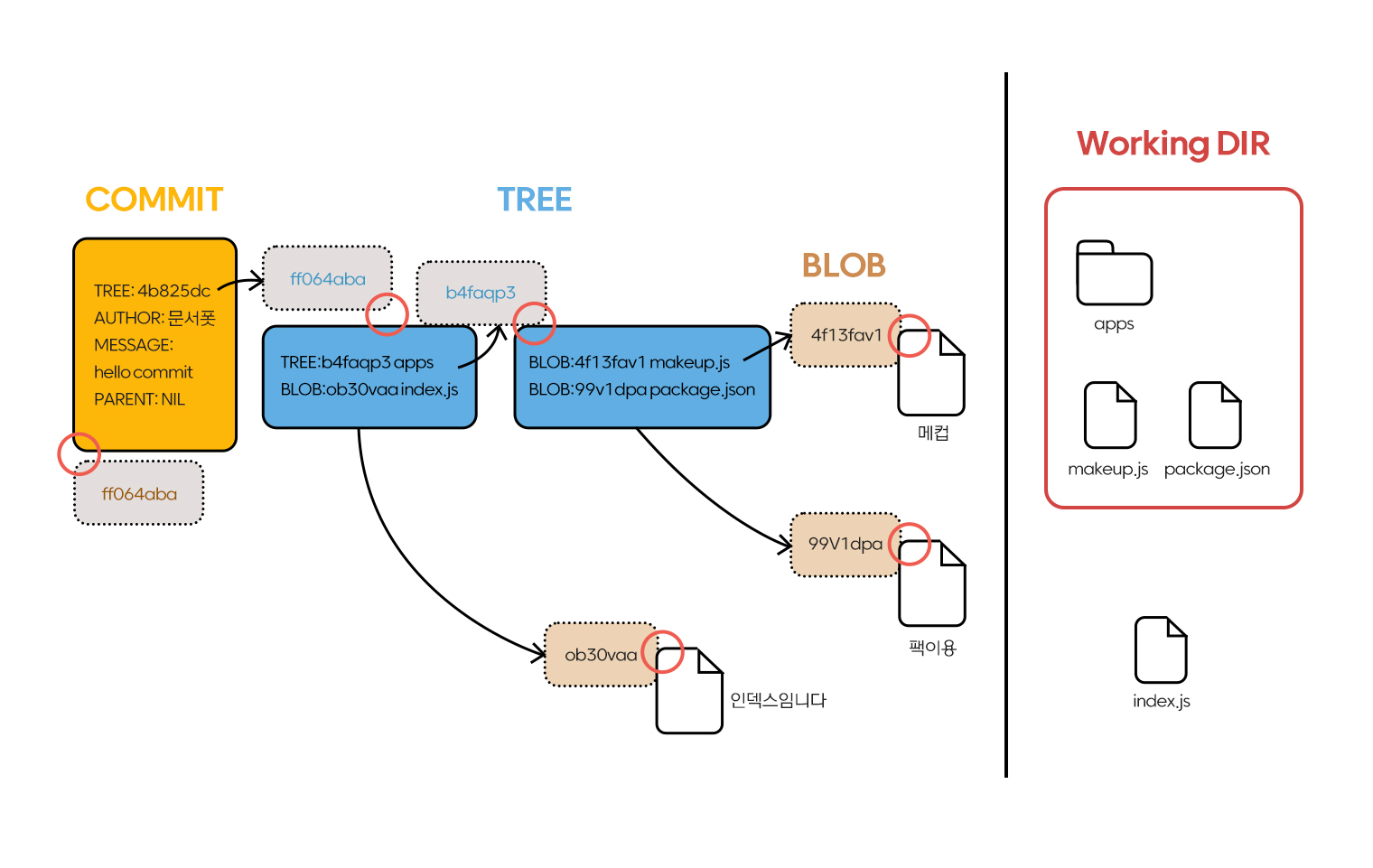
여기서 package.json의 내용을 수정하고 커밋해보겠습니다.
echo "패키지요" > apps/package.json
git add apps/package.json
git commit -m "second commit"
이 결과는 다음과 같습니다.
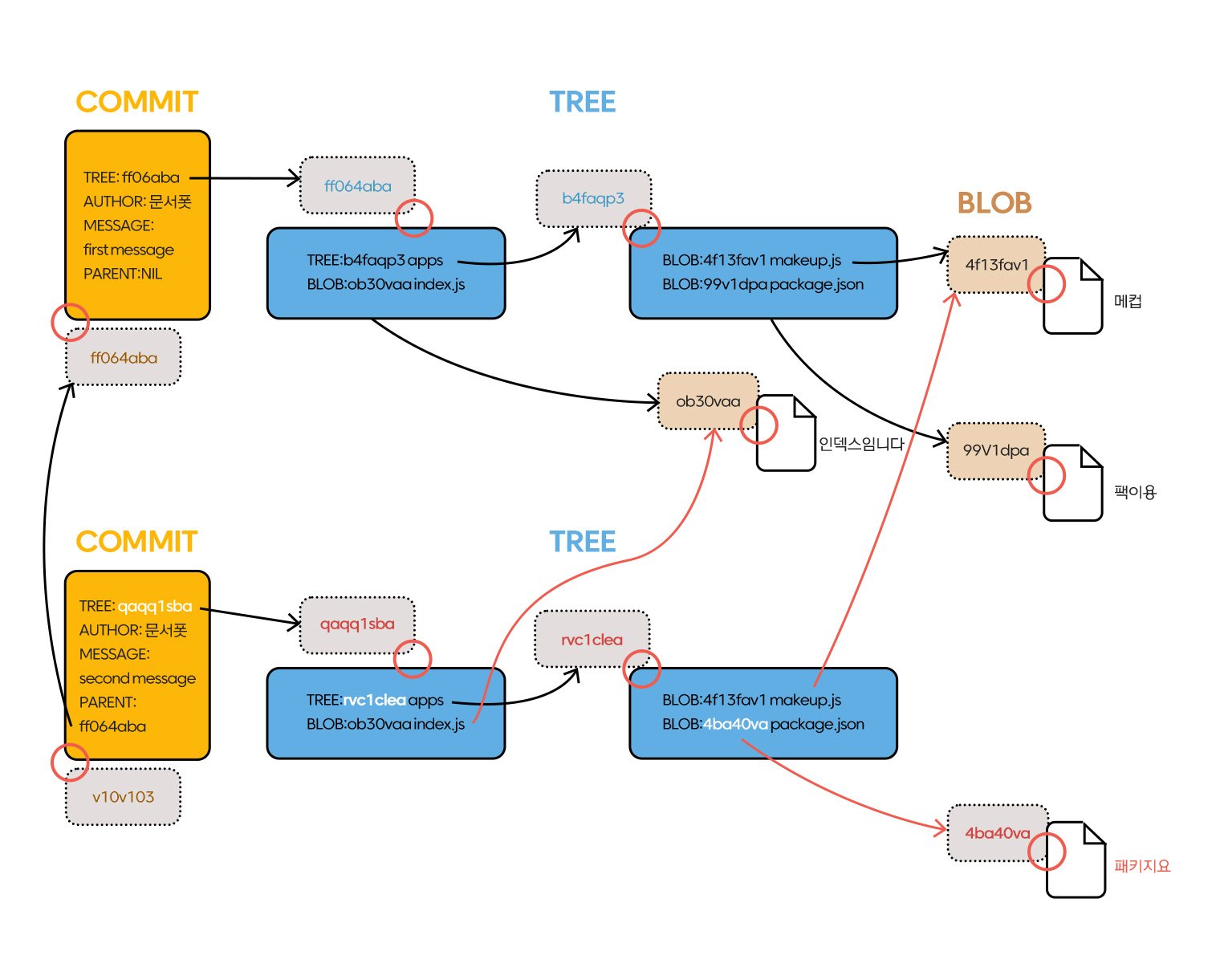
여기서 주의해야 할 점은 두 번째 commit 입장에서 "팩이용"은 더 이상 쓰지 않는 Blob이라는 점입니다.
다음으로는 새로운 브랜치를 만들고 파일을 제거해 보겠습니다.
git checkout -b "deploy"
rm -rf apps
git add apps
git commit -m "third commit"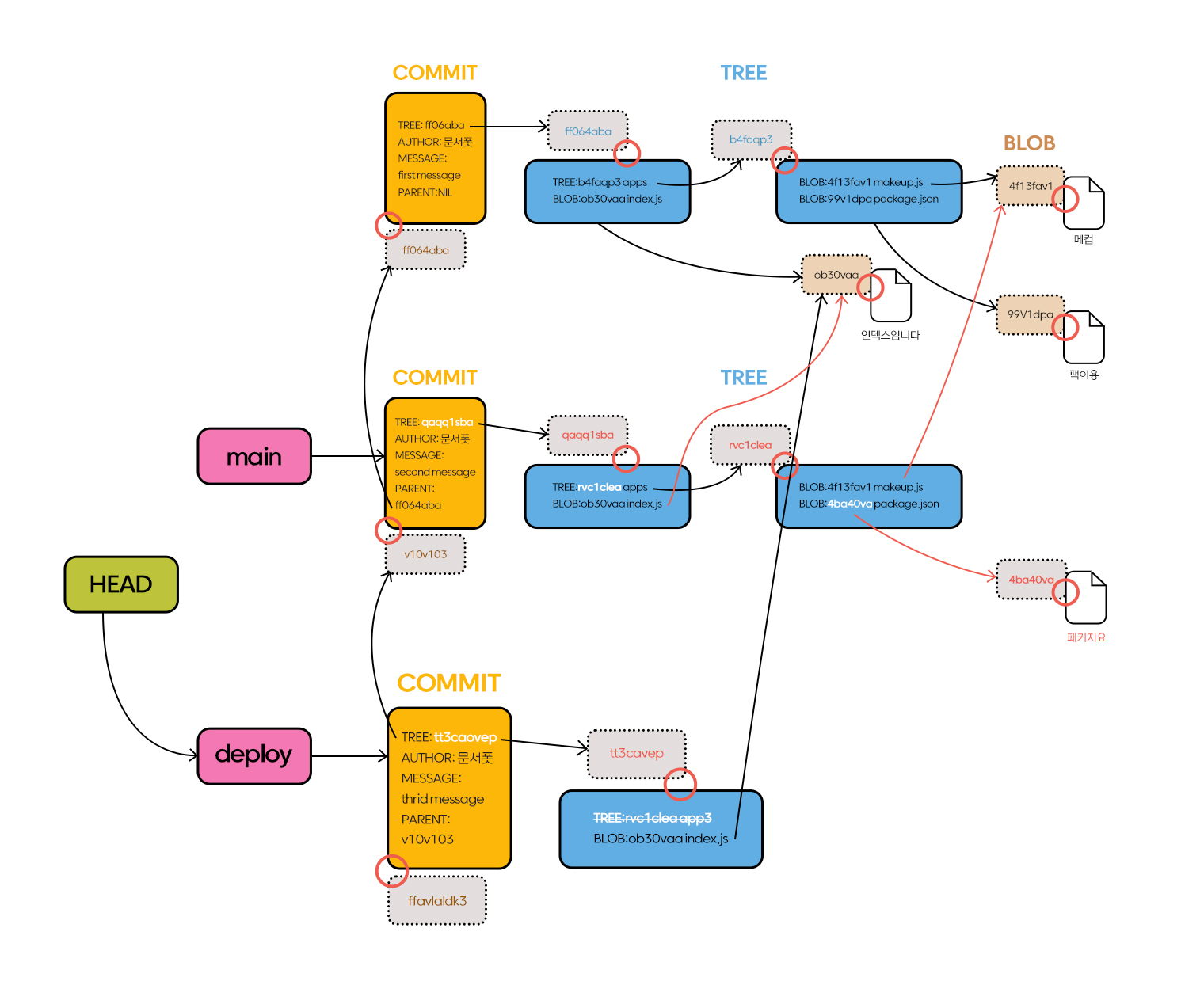
이제는 오로지 index.js만 남게 됩니다.
만약 배포를 원하는 파일이 index.js라고 상상해 보면 세 번째 커밋에서 index.js밖에 남지 않았으니 git clone --branch deploy를 하게 되면 index.js 파일만 가져오게 되는 걸까요? 그렇지 않습니다. git clone은 deploy와 main 브랜치를 모두 가져올 뿐만 아니라 main의 이전 커밋에 사용했던 blob과 tree 정보까지 모두 다운로드하게 합니다. 비록 working directory에는 index.js만 보이겠지만요.
같은 원리로 git sparse checkout 같은 명령어도 사실 working directory만 봐서는 필요한 파일만을 다운로드하는 것처럼 보이지만 실제 .git 내부에선 모든 objects를 가지고 있습니다. 로컬 머신에서는 git reset 등의 가능성이 존재해서 이 파일들이 의미가 있지만, build 머신에서는 이전 커밋 혹은 다른 브랜치에서 사용했던 blob은 그저 모두 가비지 대상입니다.
이를 위해서 git clone에는 여러 옵션을 제공해 주지만 가장 간단한 필터는 다음과 같습니다.
git clone -b $(refs 값) --no-tag --single-branch --depth 1
이처럼 필요한 objects를 분리하고 refs를 만들어 배포함으로써 빌드 시에 clone 비용을 최적화하는 것이 가능해집니다.
저희가 이러한 원리를 깊이 파고들어야 했던 이유는 git clone 시간을 최적화하기 위한 몇 가지 도구를 만들어야만 했습니다. 이때 실행하기 위해 반드시 필요한 파일들을 추려냄으로써 용량을 최적화하는 것이 필요했고, 여러 가지 가비지 커밋들과 프로젝트들을 제거함으로써 문제를 해결할 수 있었습니다. 이뿐만 아니라 내부 원리를 공부하면서 checkout, reset, rebase과 같은 기능들이 어떻게 동작하는 지도 더 깊이 알 수 있었습니다.
여러분도 이 글을 읽고 나서 좋은 영감과 기능에 대한 깊은 이해를 하는 데 있어 도움이 되길 바랍니다. 읽어 주셔서 감사합니다.
<원문>
©️요즘IT의 모든 콘텐츠는 저작권법의 보호를 받는 바, 무단 전재와 복사, 배포 등을 금합니다.