개발
스프링 부트 서버 모니터링하는 법

11분
2023.10.20.인기
22.3K
국내 IT 기업은 한국을 넘어 세계를 무대로 할 정도로 뛰어난 기술과 아이디어를 자랑합니다. 이들은 기업 블로그를 통해 이러한 정보를 공개하고 있습니다. 요즘IT는 각 기업의 특색 있고 유익한 콘텐츠를 소개하는 시리즈를 준비했습니다. 이들은 어떻게 사고하고, 어떤 방식으로 일하고 있을까요?
이번 글은 관계 지향형 AI 챗봇을 개발하는 AI 스타트업 '스캐터랩'에서 언제 터질지 모르는 서비스 장애를 대비하기 위한 스프링 부트 서버 모니터링 방법을 소개합니다.
Spring Boot 서버 모니터링하기. 근데 이제 Prometheus를 곁들인
서비스를 출시하는 날이 되었다고 생각해 봅시다. 몇 달간 고생하며 개발해 온 팀원들은 저마다의 이유로 두근두근합니다. 특히 서버 개발자는 혹여 장애가 터질 까봐 신경을 곤두세우고 있을 겁니다. 서버의 특성상 24시간 언제든지 장애가 발생할 수 있는 데다가, 장애가 났을 때 많은 사용자가 동시에 영향을 받는 경우가 흔하기 때문입니다. 서비스 장애에 신속히 대응하기 위해서는 모니터링 시스템을 촘촘히 구성해야 합니다. 이번 글에서는 핑퐁팀이 서버를 모니터링하는 방법을 소개하겠습니다.
핑퐁팀은 너티(Nutty) 메신저와 이루다의 서버를 Spring Boot로 개발했습니다. 이 서버를 도커 이미지로 만들어서 Kubernetes 환경에 배포하고 있습니다. 서버의 배포 환경을 고려하여 Prometheus와 Grafana를 모니터링 도구로 사용했습니다. Prometheus는 서버의 각종 metric을 수집하고, Grafana는 수집된 시계열 데이터를 시각화합니다. 최종적으로 구축된 모니터링 시스템은 다음 그림과 같습니다.
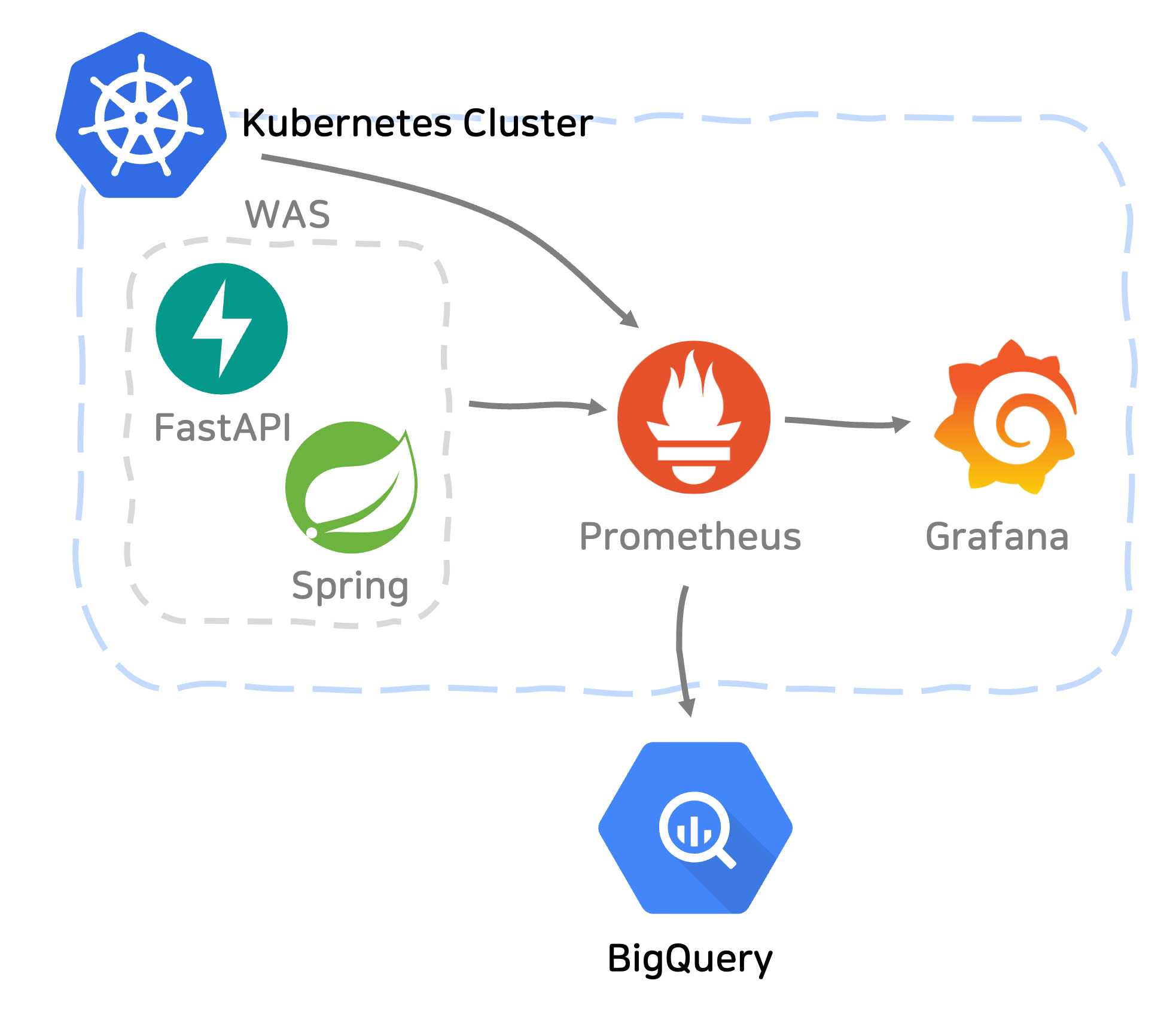
모식도에서 Prometheus는 Spring Boot 서버뿐만 아니라 FastAPI 서버와 Kubernetes 클러스터의 metric도 수집하고 있습니다. 여기서의 FastAPI 서버는 이루다 서버 내부에서만 호출되는 대화 모델 추론 서버입니다. Prometheus를 사용하면 이처럼 개발 언어나 서버 프레임워크에 구애받지 않고 여러 서비스의 지표를 모아 볼 수 있습니다. 모든 서비스 지표가 최종적으로 한 곳에 모이도록 시스템을 구성하면 모니터링 담당자의 부담을 한결 덜 수 있습니다.
이제 모니터링 시스템을 구성하는 각 요소에 대해서 소개하겠습니다. 다만 핑퐁팀의 모니터링 스택은 어디까지나 한 가지 사례에 불과하고 상황에 맞춰 다르게 고를 수 있습니다. 때문에 설치 과정이나 예시 코드를 일일이 쓰는 대신 각 기술의 주요 특징과 참고 자료를 제시하는 수준에서 그치겠습니다.
Prometheus는 모니터링 주체(Prometheus)가 모니터링 대상(서버)에게 HTTP 요청을 해서 metric을 가져오는 pull 방식을 사용합니다. 따라서 모니터링 주기를 대상 서버가 아닌 Prometheus가 통제합니다. 서버가 어떤 metric을 제공할지 설계할 때 이 특징을 잘 고려해야 합니다.
예를 들어, 서버에서 “최근 10초간 요청 수”라는 metric을 제공한다고 생각해 봅시다. 만약 Prometheus가 30초에 한 번씩 스크래핑한다면 최근 10초를 제외한 나머지 20초의 정보는 손실됩니다. 물론 Prometheus의 스크래핑 주기를 알고 있다면 “최근 30초간 요청 수”를 제공해도 되지만, “누적 요청 수” metric을 제공하는 편이 모니터링 주기가 바뀌어도 유연하게 대응할 수 있다는 장점을 갖습니다.
Prometheus에서는 시간이 지남에 따라 단조 증가하는(즉, 감소할 수 없는) metric을 counter metric이라고 정의하고, 이러한 counter metric의 기울기를 계산해 주는 rate() 함수와 같은 유용한 기능도 제공합니다. 다른 metric의 유형과 활용 방법을 알아보고 싶다면 다음 공식 문서를 참고하세요.
핑퐁팀은 Kubernetes를 이용해서 서버를 배포하고 있고 Prometheus는 이러한 배포 환경에 특히 잘 어울립니다. 별다른 복잡한 설정 과정 없이도 컨테이너와 인스턴스의 CPU, 메모리, 네트워크 사용량을 쉽게 볼 수 있기 때문입니다. 게다가 Prometheus Operator를 이용하면, Kubernetes 환경에 친숙한 방법으로 Prometheus의 모니터링 설정을 쉽게 변경할 수 있습니다.
보통은 Prometheus가 Kubernetes metric을 수집하지만, 반대로 Kubernetes가 Prometheus에 수집된 metric을 이용할 수도 있습니다. 예를 들면 실시간 트래픽이 급증했을 때 Horizontal Pod Autoscaler를 제어해서 자동으로 서버의 대수를 늘릴 수 있다는 것입니다. Kubernetes의 metric 수집 방식과 구체적인 적용 사례가 궁금하면 다음 글을 읽어보세요.
Prometheus는 시계열 데이터를 저장하기 위한 자체 데이터베이스를 가지고 있습니다. 이 데이터베이스는 로컬 디스크를 사용하는데, 시간이 지나면서 metric 정보가 많이 축적되면 디스크 용량에 부담이 됩니다. 보통은 --storage.tsdb.retention.time과 --storage.tsdb.retention.size 옵션을 적용하여 특정 범위를 넘어가는 오래된 데이터를 자동으로 지우게 설정합니다.
과거의 metric을 이용해서도 좋은 분석을 할 수 있는데 그냥 삭제하는 게 찝찝하다면, Prometheus에서 지원하는 remote storage integration을 이용하여 외부 저장소에 시계열 정보를 저장할 수 있습니다. 핑퐁팀은 KohlsTechnology/prometheus_bigquery_remote_storage_adapter를 이용하여 Prometheus가 수집한 metric을 BigQuery에 적재하도록 설정했습니다. Prometheus는 BigQuery 이외의 다른 데이터 플랫폼과도 연동할 수 있으며 몇 가지 예시는 다음 공식 문서에서 찾아볼 수 있습니다.
Grafana는 Prometheus를 포함하여 다양한 데이터를 대시보드 형태로 시각화할 수 있습니다. 핑퐁팀은 Amazon CloudWatch나 Google Cloud Logging 등 클라우드 서비스의 metric도 Grafana에 통합하여 모니터링하고 있습니다.
Grafana의 Alerting 기능을 활용하면 지표가 정상 범위를 벗어났을 때 Slack과 같은 외부 서비스로 알림을 보낼 수도 있습니다.
서버의 상태가 모니터링 담당자에게 전달되기까지의 과정을 알아봤으니, 이제는 모니터링 시스템에 보낼 metric을 서버 내부에서 어떻게 수집할지 결정해야 합니다.
Spring Boot는 운영 환경에 배포된 애플리케이션을 쉽게 모니터링할 수 있도록 Actuator 모듈을 제공합니다. 이 모듈을 이용해서 다음과 같이 간편하게 Prometheus용 metric API를 노출시킬 수 있습니다.
org.springframework.boot:spring-boot-starter-actuator 의존성 추가io.micrometer:micrometer-registry-prometheus 의존성 추가 (runtimeOnly)management.endpoint.prometheus.enabled=true properties 적용management.endpoints.web.exposure.include=prometheus properties 적용
그 후 웹 브라우저에서 /actuator/prometheus에 접속하면, 다음 화면처럼 Prometheus에서 사용할 수 있는 각종 metric을 확인할 수 있습니다.
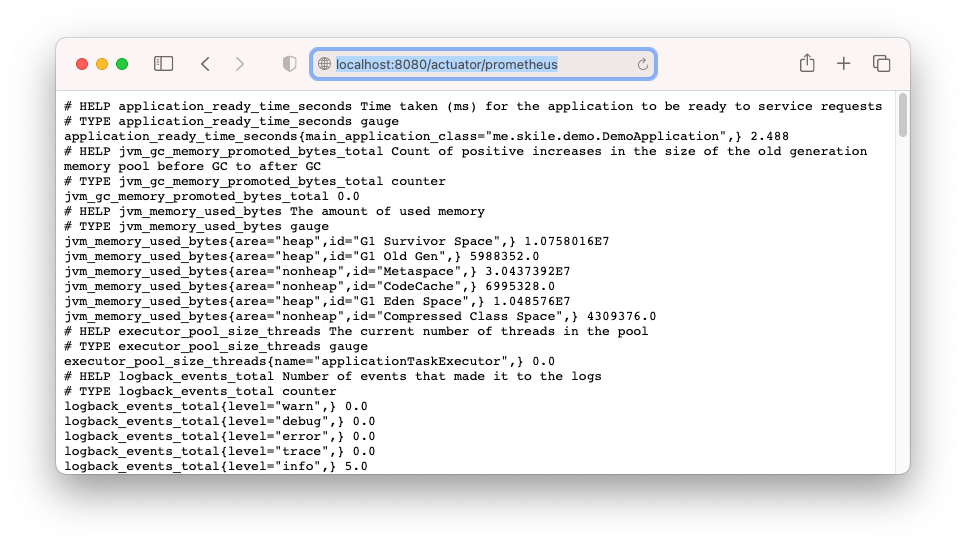
다만 운영 환경에 배포할 때는 민감한 metric을 외부 사용자가 가져가지 못하도록 해당 API의 접근을 제한해야 합니다.
Actuator는 Prometheus metric 이외에도 다양한 유용한 엔드포인트를 제공하고 있으며, 구체적인 사례가 궁금하면 다음 공식 문서를 읽어보시기를 추천합니다.
Micrometer는 metric을 측정하는 통일된 인터페이스를 제공하는 라이브러리로, Prometheus뿐만 아니라 다양한 모니터링 시스템과 호환되는 API를 제공합니다. Spring Boot Actuator는 Micrometer를 의존성으로 갖고 있고, Micrometer의 MeterRegistry 빈을 자동으로 주입합니다.
덕분에 @Autowired 어노테이션으로 MeterRegistry 빈을 가져와 다음과 같이 한 줄로 사용자 지정 metric을 누적할 수 있습니다.
registry.counter("push").increment();
위 코드가 실행될 때마다 /actuator/prometheus에서 push_total metric의 값이 1씩 증가합니다. 이러한 사용자 지정 metric은 해당 분야를 이해하고 있는 애플리케이션 개발자의 필요에 의해 설정됩니다. 이루다의 경우 “루다가 보낸 선톡 개수”가 그 예가 될 수 있는데, 선톡을 많이 보내면 답장하러 들어오는 사용자가 늘어나 트래픽에 영향을 주기 때문입니다.
Micrometer는 단순 Counter metric 이외에도 메서드의 실행 시간을 측정할 수 있는 @Timed 어노테이션 등 다양한 기능을 제공하고 있고, 상세한 정보는 아래 공식 문서에서 확인 가능합니다.
글을 읽으며 아마 느끼셨겠지만, 요즘은 오픈 소스인 모니터링 기술이 많고 다른 서비스와의 통합도 잘 되어 모니터링 시스템 구축이 쉽습니다. 오히려 너무 metric이 많아서 무엇에 집중을 해야 될지 막막할 정도입니다. 물론 실제 장애를 겪고 사후 검토(postmortem)를 하는 과정에서 모니터링 노하우가 점점 쌓이겠지만, 서비스를 갓 출시한 상황에서는 서비스의 핵심 지표를 선정하고 연관된 metric부터 관리하는 것이 좋은 전략일 수 있습니다.
루다의 경우 “대화량”이 서비스에서 가장 중요한 지표기에, “이루다 서버에 들어온 대화 요청 수”, “이루다가 보낸 메시지 수”와 같은 사용자 metric을 설정하였습니다. 대화량이 급감하는 장애 상황이 발생하면 빠르게 원인을 파악하고 서버 재부팅 등의 긴급 조치를 취한 뒤, DB의 처리량(throughput)과 스레드 풀에서 활성화된 스레드 수 같은 metric을 감시하는 알람을 추가했습니다.
이 글의 나머지 부분에서는 대부분의 서비스에서 중요하게 다뤄지는 핵심 지표를 공유하고, Spring Boot Actuator + Prometheus + Kubernetes로 구성된 모니터링 스택에서 어떤 metric으로 표현되는지 예시도 보여드리고자 합니다.
Spring Boot Actuator는 웹 서버의 가장 기본이 되는 URI 별 HTTP 요청 수, 평균 지연 시간 등의 정보를 제공합니다. http_server_requests_seconds_{count,sum,max} metric을 사용하면 되고 metric tag의 상세 정보가 궁금하시면 다음 문서를 참고해 주세요.
server.tomcat.mbeanregistry.enabled=true로 설정하면, tomcat_global_request_seconds_count로 톰캣 서버로 오는 전체 요청을 확인할 수도 있습니다.
인프라가 마이크로 서비스 아키텍처로 구성되었고 Kubernetes에 배포된 경우에는, Istio와 같은 service mesh의 metric을 활용할 수도 있습니다. 이 경우에는 요청을 보낸 서비스와 받은 서비스가 각각 기록되기 때문에 요청의 흐름을 추적하기에도 용이합니다. 대표적인 metric으로는 istio_requests_total이 있으며 관련된 문서로는 다음이 있습니다.
서드 파티 API를 사용하거나 마이크로 서비스 아키텍처를 차용한 경우 웹 서버 내부에서 또 다른 HTTP 요청을 보내는 일은 흔합니다. 이러한 HTTP 요청도 연결을 맺을 때 오버헤드가 들고 네트워크 I/O가 필요하기 때문에 병목이 될 수 있습니다.
Spring Boot에서 만들어 준 WebClient.Builder로 WebClient를 생성하면 http_client_requests로 시작하는 각종 metric을 사용할 수 있습니다. 또는 별개로 사용하고 있는 HTTP 클라이언트가 있다면 PoolingHttpClientConnectionManagerMetricsBinder와 같은 바인더를 사용해서 커넥션 풀의 상태를 모니터링할 수 있습니다.
웹 서버가 DBMS와 통신하는 과정도 병목이 될 수 있습니다. DB 커넥션 풀의 크기가 적절하게 설정되었는지, DB 쿼리가 의도한 것보다 느리게 실행되지는 않는지, 읽기 전용 복제본(read replica)을 운영한다면 부하가 잘 분산되는지 등을 잘 모니터링할 필요가 있습니다.
사용하는 DBMS 종류에 따라 봐야 하는 metric은 달라집니다. 관계형 데이터베이스에 연결할 때 사용할 수 있는 JDBC 기반 metric으로는 다음이 있습니다.
MongoDB를 사용할 때는 다음과 같은 자동으로 설정(auto-configured)된 metric을 사용할 수 있습니다.
Spring Data의 repository 패턴을 사용하는 경우, 사용하는 DBMS 종류와 무관하게 repository 메서드 별 호출 횟수와 실행 시간이 spring_data_repository_invocations_{sum,count} metric으로 측정됩니다.
지금까지는 DB를 사용하는 웹 서버 입장에서 측정할 수 있는 metric이었지만, 웹 서버에서 알 수 없는 DB 서버의 내부 지표는 별도로 가져와야 합니다. 핑퐁팀은 AWS 클라우드에서 제공하는 관리형 DB(RDS, DocumentDB)를 사용하기 때문에, Amazon CloudWatch로 로깅되는 DB 지표를 Grafana에 통합해 관리하고 있습니다.
jvm_threads_states_threads metric을 사용하면 스레드의 생명주기별로 스레드가 총 몇 개인지 알 수 있습니다.
# HELP jvm_threads_states_threads The current number of threads# TYPE jvm_threads_states_threads gaugejvm_threads_states_threads{state="runnable",} 7.0jvm_threads_states_threads{state="blocked",} 0.0jvm_threads_states_threads{state="waiting",} 11.0jvm_threads_states_threads{state="timed-waiting",} 3.0jvm_threads_states_threads{state="new",} 0.0jvm_threads_states_threads{state="terminated",} 0.0
만약 state="waiting"인 스레드 개수가 지나치게 많고 시간이 지나도 줄어들지 않는다면 교착 상태가 발생했다고 의심해 볼 수 있습니다. 하지만 이 정보만으로는 비효율적으로 스레드를 생성하는 위치를 알기 어려워 jstack 명령어로 스레드 덤프를 들여다볼 필요가 있습니다.
I/O의 비중 등 작업의 특성에 따라 실행되는 스레드 풀이 적절히 분리되어 있다면, ExecutorServiceMetrics.monitor 메서드를 사용해서 스레드 풀의 상태를 모니터링할 수 있습니다.
Kubernetes 파드에는 memory request와 limit을 지정할 수 있습니다. 이 값이 부족하게 설정되면 OOMKill이 자주 일어나고 과하게 설정되면 노드의 리소스를 낭비하게 됩니다. 그렇다고 아예 설정하지 않으면 파드의 QoS 클래스가 가장 낮은 BestEffort로 설정되어 노드의 메모리가 부족할 때 가장 먼저 evict 당할 수 있습니다. 이럴 때 Kubernetes가 제공하는 container_memory_usage_bytes 등의 metric을 사용하면 적정 수준을 정하는 데 도움이 됩니다.
한편 JVM에서는 GC(Garbage Collector) 기능이 있기 때문에, 메모리 관리를 비효율적으로 하면 GC가 작동하느라 다른 스레드가 모두 중지되는 stop-the-world 현상이 발생할 수 있습니다. GC가 지나치게 실행되는 경우 메모리 프로파일링을 통해 비효율적인 메모리 할당을 최적화하거나, G1 GC 등 다른 GC 알고리즘을 선택하는 방안을 고려해 볼 수 있습니다.
Spring Boot Actuator를 이용하면 기존 jstat 명령어로 얻을 수 있던 것과 동일한 metric을 얻을 수 있습니다. 대표적인 예시로는 jvm_gc_pause_seconds_{count,sum}과 jvm_memory_used_bytes가 있습니다.
모니터링 시스템은 장애 상황을 빠르게 탐지하고 원인을 분석하는 데 도움을 주는 유용한 도구입니다. 하지만 아무리 많은 metric와 알람을 설정한다고 한들 실제 문제를 해결하는 데 사용되지 않는다면 유명무실하겠죠. 그래서 저는 모니터링 시스템보다는 전체적인 장애 대응 프로세스를 잘 세우는 것이 더 중요하다고 생각합니다.
빠르게 변화하는 스타트업에서 모든 이슈를 완벽히 처리하기는 불가능에 가까워서, 어떤 이슈가 더 많은 유저에게 더 심각한 영향을 주는지 그 우선순위를 잘 따져야 합니다. 어떤 장애는 매우 치명적이라 새벽에 잠자는 개발자를 전화로 깨워야 할 수도 있고, 또 다른 장애는 사용자 경험에 주는 영향이 미미해 대응을 무기한 보류할 수도 있습니다.
이 글을 통해 모니터링 시스템을 통해 장애 대응 프로세스를 뒷받침하는 충분한 metric을 마련하고, 개발자 팀원들 사이에서 장애 대응 우선순위에 대한 합의를 잘해서, 어떤 기능을 배포하더라도 담담히 장애를 맞닥뜨릴 수 있는 날이 오기를 기대해 봅니다.
<원문>
©️요즘IT의 모든 콘텐츠는 저작권법의 보호를 받는 바, 무단 전재와 복사, 배포 등을 금합니다.