개발
MySQL 쿼리 튜닝의 첫걸음

6분
2023.10.06.인기
21.1K
먼저 실행계획을 분석해보자

개발 업무를 하다 보면 성능이 중요하다는 말을 참 많이 듣게 됩니다. 이 때문에 스트레스를 받는 경우도 많고, 애써 작업한 코드를 뜯어고치는 경우도 수없이 많은데요. 면접을 볼 때에도 성능을 개선하기 위해 무엇을 했는지를 묻기도 하고요. 어느 부서에서는 업무성과를 성능 개선에 초점을 맞춰 평가하기도 합니다. 이렇게 중요하게 생각하는 성능, 데이터베이스의 쿼리에도 예외는 아니겠죠. 그러면 MySQL에서 쿼리 성능을 측정하고 튜닝 포인트를 어떻게 찾을 수 있을까요?
MySQL을 다루시는 대부분의 DBA(DataBase Administrator)나 백엔드 개발자분들은 익숙할 것으로 생각되는 명령어입니다. MySQL에서 데이터를 찾는 과정을 결과 셋으로 보여주는 명령어인데요. 이를 통해 Slow Query의 발생 지점을 체크할 수 있고, 이 결과를 가지고 Index 구성에 대한 고민을 해보며 쿼리 튜닝을 통한 성능 향상을 꾀할 수 있는 중요한 명령어입니다.
EXPLAIN [EXTENDED] SELECT ... FROM ... WHERE ...
이처럼 내가 조회할 SELECT 쿼리문 앞에 EXPLAIN 키워드를 붙이면 됩니다. 아래는 실행계획으로 나오는 결과에 대해 정리한 내용입니다.
01. id : select를 구분하는 번호
02. select_type : 현재 실행되는 쿼리의 SELECT문 종류와 위치
- SIMPLE : Union이나 Sub Query가 없는 단순한 Select문
- PRIMARY : Sub Query에서 최상위 쿼리에 대한 Select
- UNION : Union 내부의 Select
- DEPENDENT UNION : Union 내부의 Select 중, 외부 쿼리와 연관된 셀렉션
- UNION RESULT : Union의 결과이며, union의 각 결과를 셀렉션
- SUBQUERY : Sub Query의 첫번째 Select, 다시 말해 결과를 얻는 Select문
- DEPENDENT SUBQUERY : 외부 쿼리와 연관된 Sub Query
- DERIVED : FROM절의 Sub Query로, 이전 쿼리에서 처리된 결과를 기반으로 새로운 테이블 생성
- UNCACHEABLE SUBQUERY : 캐시할 수 없는 Sub Query
03. table : 참조하는 테이블
04. partitions : 사용되는 파티션의 목록
(*) 05. type : 현재 실행되는 쿼리의 테이블 접근 방법 (Best -> Worst 순)
- system : 단일 행을 반환하는 쿼리에 대한 최적화된 방식
- const: 기본 키(Primary) 혹은 고유 인덱스 값으로 검색하는 경우
- eq_ref : JOIN 시에 기본 키(Primary) 혹은 고유 인덱스(Index)를 사용하는 경우, 하나의 레코드만 검색
- ref : 참조하는 인덱스가 있는 테이블에 대한 검색, 여러 개의 레코드 반환
- fulltext : FULLTEXT 검색하는 경우
- ref_or_null : ref와 유사하지만, NULL값을 포함한 레코드 검색하는 경우
- index_merge : 여러 개의 인덱스(Index)를 조합한 쿼리를 수행하는 경우
- unique_subquery : IN절 안의 Sub Query에서 기본 키(Primary)가 걸리는 경우
- index_subquery : IN절 안의 Sub Query에서 인덱스(Index)가 걸리는 경우
- range : 인덱스(Index)를 범위로 검색하는 경우
- index : 인덱스(Index)를 Full Scan하는 경우
- all : 테이블을 Full Scan하는 경우
06. possible_keys : 쿼리에 사용될 수 있는 인덱스(Index)의 목록
(*) 07. key : MySQL 옵티마이저가 사용하기로 결정한 인덱스(Index) 정보, NULL일 경우 인덱스 사용하지 않음
08. key_len : 인덱스의 사용 길이로 인덱스의 일부를 사용하는 경우에 적용되며, 값이 작을수록 성능에 유리
09. ref : 연결 조건에서 사용되는 컬럼으로, 어떤 컬럼이 사용되었는지 나타냄
(*) 10. rows : MySQL 옵티마이저가 쿼리 실행 시 예상되는 총 행의 수, 이 값이 적을 수록 성능 우수
11. filtered : 각 실행 단계에서 반환되는 레코드의 비율
(*) 12. extra : 쿼리 실행과 관련된 추가 정보 (Best -> Worst 순)
- using index : 인덱스(Index)를 사용하여 데이터 추출
- using where : where 조건으로 데이터 추출
- using temporary : MySQL에서 임시 테이블을 생성하여 추출, ORDER BY 혹은 GROUP BY등의 연산 혹은 Sub Query 시 사용될 수 있으며 디스크 저장되기에 I/O의 비용으로 인해 성능하락 가능성
- using filesort : ORDER BY 수행 시에 인덱스(Index)를 사용하지 않고 정렬하는 경우 사용되며 이 또한 성능 하락 가능성
여기서 아래의 예시를 살펴보면서 쿼리를 튜닝하는 시나리오를 알아볼게요.
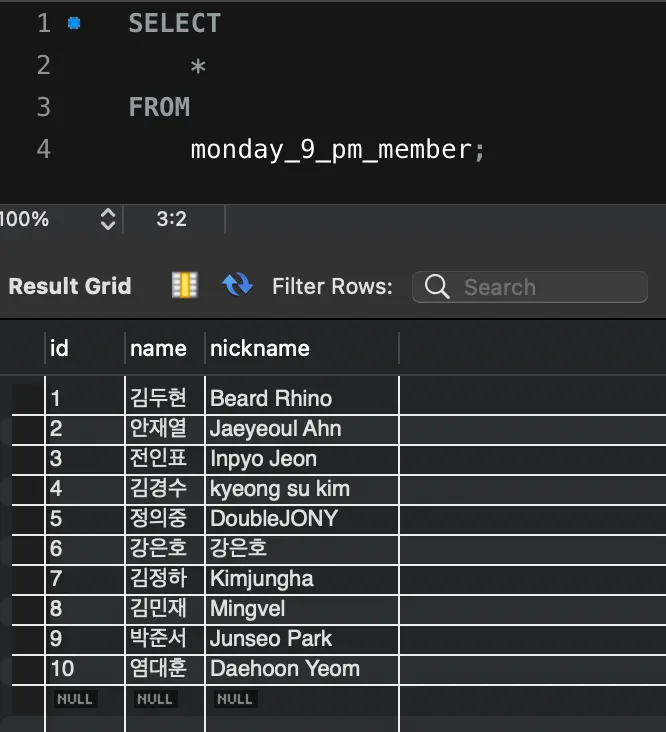
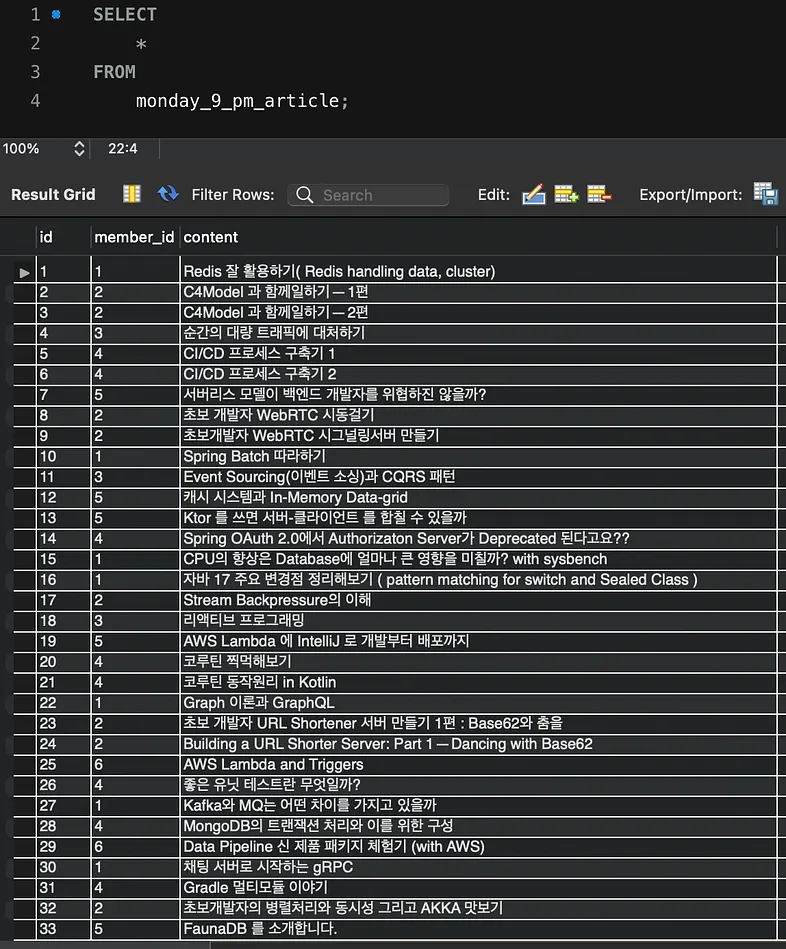
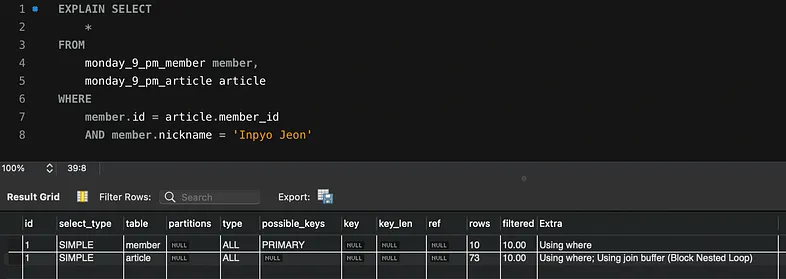
ALTER TABLE monday_9_pm_article ADD INDEX idx_member_id (member_id);
ALTER TABLE monday_9_pm_member ADD INDEX idx_member_nickname (nickname);
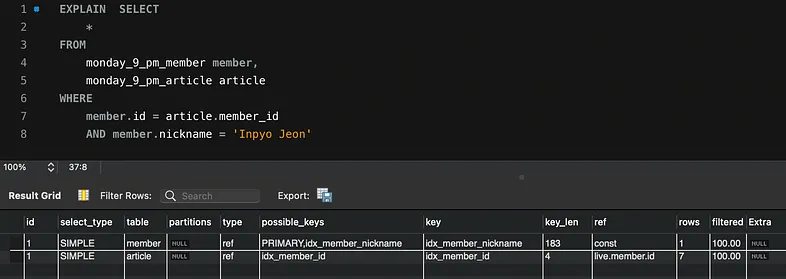
지금까지 EXPLAIN 명령어의 전반적인 내용을 살펴보았습니다. 그렇지만 한 가지 알고 있어야 하는 사실은, 이 EXPLAIN 명령어가 유용한 것임에는 틀림없는 사실이지만, 이를 활용한 분석의 정확성이 다소 떨어질 수 있다는 것입니다. 이에 대해 여러 가지 원인이 있겠지만, 주된 이유는 통계정보의 부족 혹은 불일치로 인한 것입니다. 여기서 말하는 통계정보 테이블은 열의 값과 데이터 분포 등을 담고 있는데요. EXPLAIN 명령어는 통계정보 테이블을 기반으로 동작합니다. 실행계획을 세울 때 기준이 되는 통계정보 테이블의 데이터가 부정확할 때 실행계획이 예상했던 것과 달라질 수 있습니다.
그렇다면 위에서 설명했던 그리고 부정확한 통계정보 테이블을 갱신하려면 어떻게 해야 할까요? ANALYZE 명령어를 사용하면 됩니다. 이 명령어는 인덱스 혹은 통계 정보 업데이트에 사용됩니다.
ANALYZE TABLE ...
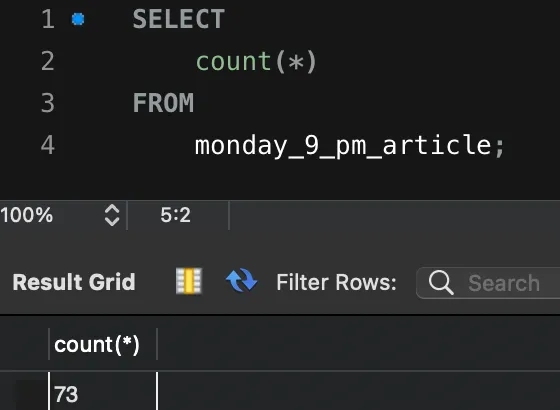

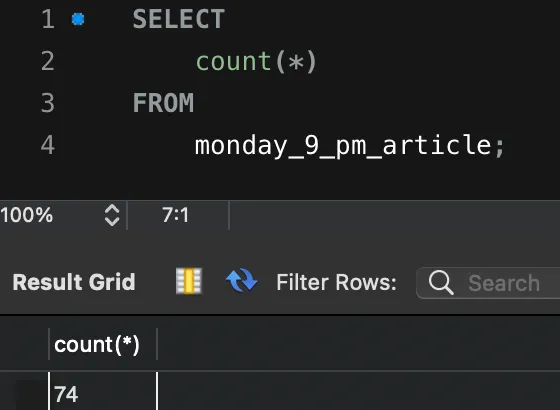

article의 수가 73개이고 이때 통계정보 테이블의 ROWS는 73입니다. 여기서 한 개의 article이 추가되어 74개가 되었음에도 통계정보 테이블의 ROWS의 값은 여전히 73입니다. 앞서 말씀드렸듯 EXPLAIN 명령어는 이 통계정보 테이블을 기반으로 하여 실행계획을 세우는데요. 이렇게 통계정보 테이블의 데이터가 틀어지게 되면, 보다 정확한 실행계획을 유추할 수 없게 됩니다.
ANALYZE 명령어 수행 후, 다시 확인해 보면 업데이트된 것을 볼 수 있습니다. 이제부터 EXPLAIN 명령어 수행 시에 최신화된 통계 테이블을 기반으로 실행계획을 세우게 될 것입니다.

지금 소개해드릴 명령어는 실행 계획뿐만 아니라 쿼리 수행 시간과 관련된 성능 통계 정보를 함께 제공합니다. 이를 통해 보다 상세하고 정확한 정보를 알 수 있습니다.
MySQL 8.0.18 버전부터 사용이 가능합니다. (링크)
EXPLAIN ANALYZE SELECT ... FROM ... WHERE ...
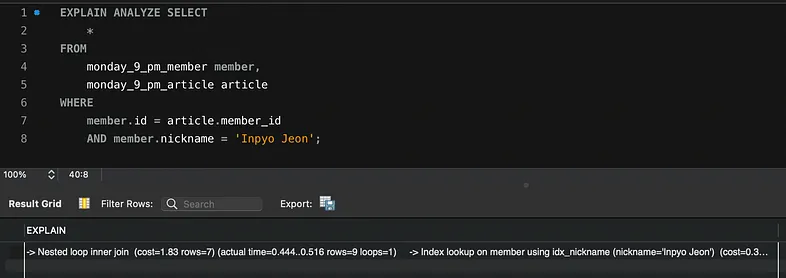
-> Nested loop inner join (cost=1.83 rows=7) (actual time=0.422..0.516 rows=9 loops=1)
-> Index lookup on member using idx_nickname (nickname='Inpyo Jeon') (cost=0.35 rows=1) (actual time=0.228..0.238 rows=1 loops=1)
-> Index lookup on article using idx_member_id (member_id=`member`.id) (cost=1.48 rows=7) (actual time=0.174..0.240 rows=9 loops=1)
1. (cost=1.83 rows=7)
-> 해당 쿼리의 총 비용이 1.83, 예상되는 결과 행 수가 7행
2. (actual time = 0.422..0.516 rows=9 loops=1)
-> 실제 쿼리 실행에 걸린 시간이 0.422초에서 0.516초 사이, 결과 행 수는 9행
이 두 명령어의 차이는 아래와 같습니다.
지금까지 MySQL 쿼리를 튜닝하기 위한 첫걸음으로 나의 쿼리가 어떻게 수행될지 예측해 보고, 그 예측의 정확도를 올릴 수 있는 방법과 예측도와 실제 수행 간의 차이는 어떻게 확인할 수 있는지 알아보았습니다. 다만 EXPLAIN ANALYZE 명령어는 실제 쿼리를 실행하는 것이기 때문에 상용 환경에서 주의를 가지고 사용해야 함을 명심해야 할 것입니다.
<원문>
©️요즘IT의 모든 콘텐츠는 저작권법의 보호를 받는 바, 무단 전재와 복사, 배포 등을 금합니다.