개발
쿠팡이 클라우드 기반 ‘데이터베이스 백업 플랫폼’을 만든 이유

9분
2023.07.27.10.1K
국내 IT 기업은 한국을 넘어 세계를 무대로 할 정도로 뛰어난 기술과 아이디어를 자랑합니다. 이들은 기업 블로그를 통해 이러한 정보를 공개하고 있습니다. 요즘IT는 각 기업의 특색 있고 유익한 콘텐츠를 소개하는 시리즈를 준비했습니다. 이들은 어떻게 사고하고, 어떤 방식으로 일하고 있을까요?
이번 글은 국내 대표 이커머스 기업 ‘쿠팡(Coupang)’이 새로운 데이터베이스 백업 및 복구 플랫폼을 만든 배경과 과정에 대해 소개합니다.

데이터 재해로부터 쿠팡의 온라인 비즈니스를 보호하는 시스템에 관하여
By Junzhao Zhang
쿠팡에서 데이터는 대체 불가능한 자원입니다. A/B 테스트부터 시작해 구매 퍼널링(funneling)에 이르기까지 고객 여정의 모든 지점에서 데이터가 활용됩니다. DBA 엔지니어들은 데이터베이스에 문제가 발생하는 것을 원천 차단하고자 많은 노력을 기울이지만, 예측 불가한 일로 인해 데이터에 문제가 생길 수 있습니다. 예를 들어, 사소한 물리 디스크 장애로 데이터세트가 오염될 수도 있고, 개발자 실수로 데이터가 영구적으로 삭제될 수도 있습니다.
이러한 잠재적 데이터 재해를 빠르고 효율적으로 해결하기 위하여, 쿠팡 데이터베이스 엔지니어링 팀은 전체 백업 프로세스를 간소화, 자동화하는 강력한 백업 및 복구 플랫폼을 개발하였습니다.
쿠팡 데이터베이스 백업 플랫폼은 미션 크리티컬 데이터와 메타데이터의 손실을 손쉽고 안전하게 예방하도록 설계되었습니다.
이 포스트에서는 왜 새로운 데이터베이스 백업 및 복구 플랫폼이 필요했는지와 어떻게 개발했고 어떻게 일상 업무에 적용해 사용하고 있는지를 설명드리겠습니다.
시작에 앞서, 기존 백업 방식의 약점을 먼저 파악했습니다. 저희는 기존에 간단한 백업 관리 툴과 작업 스케줄러(cron jobs)를 활용해 데이터를 백업했습니다.
쿠팡이 작은 스타트업이었던 시절에는 이 방법을 통해 비지니스 요구사항들을 적절히 충족시킬 수 있었습니다. 그러나 수집하는 데이터의 양이 기하급수적으로 증가하자, 작업 스케줄러 스크립트는 점점 관리하기 어려워졌습니다. 여러 팀이 작업 스케줄러 수정 권한을 가진 상황에서, 스케줄러 버전과 팀 접근 권한도 관리되지 않았습니다.
쿠팡의 고객 수가 증가하면서 수집하는 데이터 양도 크게 늘면서, 다음과 같은 문제들을 기존 백업 방식에서 발견할 수 있었습니다.
전반적으로, 기존의 백업 방식은 여러 단계에서 개발자의 개입이 필요하여 인적 오류에 취약하고 일관성이 부족했습니다.
온라인 서비스에 지장을 주지 않고, 안전하게 데이터를 복구하고, 쿠팡의 비즈니스 요구사항을 충족시키는 백업 플랫폼이 필요했습니다. 검토 끝에, 다음과 같은 요구사항을 정의하였습니다.
위 요구사항을 고려하여 저희는 아래 백업 방법을 선택하였습니다.
저희 데이터 플랫폼의 목표는 백업 프로세스를 통합하고 반복적으로 일어나는 작업을 안전하고 효율적으로 표준화하는 것입니다. 이러한 목표는 수동 프로세스의 자동화, 검증 메커니즘 제공, 운영 로그 시스템 통합을 통해 달성했습니다. 또한, 쿠팡 백업 플랫폼은 누구나 쉽게 사용할 수 있는 인터페이스를 제공합니다.
이번 섹션에서는, 플랫폼 아키텍처의 일부를 설명하고 백업 운영의 효율성, 보안성, 유연성을 증진하기 위해 선택했던 설계 전략의 일부를 설명하겠습니다.

높은 모듈성, 속도 및 보안을 위해, 저희는 백업 플랫폼의 백엔드를 작은 용량의 바이너리 파일로 배포되고 메모리 공간을 적게 사용하면서 시스템 레벨 프로그램들 위에서 동작하도록 설계했습니다. 추가로 작업 구성(operation configuration), 일정, 감사 로그(audit log)를 저장하는 메타 데이터베이스가 있습니다. 플랫폼 아키텍처에 통합되어 있는 백엔드 컨트롤러는 백업 프로세스를 관리하는 툴입니다. 또한 프로그래밍 및 웹 UI에 사용할 수 있는 표준 RESTful API를 제공하여 자동화를 지원합니다.
쿠팡 백업 플랫폼은 자사의 비즈니스 요구사항에 따라 광범위한 백업 옵션을 제공합니다. 예를 들어, DBA 엔지니어가 물리적 백업에 대한 작업 일정을 생성할 때, 전체 백업이나 증분 백업 중에서 선택할 수 있습니다. 또한 데이터베이스 머신 유형을 여러 가지 인스턴스 중에서 선택할 수 있습니다. 각 인스턴스의 속도 제한과 파라미터는 일부러 각각 다른 설정을 갖게 했습니다. DBA 엔지니어는 작업에 적합한 인스턴스를 선택해 사용하면 됩니다.
백업 작업은 설정된 일정대로 실행됩니다. 온라인 서비스에 미치는 영향을 최소화하기 위해 백업 작업은 주로 트래픽이 가장 낮은 시간대에 실행됩니다. 그러나 높은 I/O 부하로 인해 여전히 때때로 안정성 문제 혹은 데이터 복제 지연 문제가 발생합니다.
저희는 안정성과 속도를 확보하기 위해 자동 최적화 기능을 구현했습니다. 예를 들어, MySQL 호스트 볼륨 처리량을 기반으로, 백업 툴은 I/O 이용률을 프로덕션 환경의 실제 통계값의 80%로 조절합니다. 이를 통해 리소스가 포화상태가 되거나 온라인 서비스에 영향을 미치는 것을 방지합니다. 스레드(thread)의 개수나 S3 파일 업로드 단위(chunk size)와 같은 기타 변수는 MySQL의 데이터 사이즈에 맞춰 자동 조절됩니다. 이 기능의 최적화 전략은 여러 가지 상황에 맞춰 유연하게 튜닝될 수 있습니다.
저장소(storage) 관점에서, 백업 저장소를 위한 두가지 방법이 있습니다: EBS 스냅샷과 S3.
EBS 스냅샷은 먼저 새로운 데이터 복제본을 클러스터에 추가합니다. 그 다음, 클러스터의 최신 데이터가 복제본으로 동기화됩니다. 동기화가 끝나면, EBS 볼륨이 분리되어 보존됩니다. 이 방법의 장점은 복제본을 클러스터에 추가해 데이터 복구를 완료하는데까지 몇 분 밖에 걸리지 않는다는 것입니다.
S3 저장소 백업 방법은, 디스크 공간 부족 리스크를 피하기 위해 암호된 파일을 임시 파일 없이 유닉스 파이프라인으로 S3에 바로 업로드합니다. 보안을 극대화하기 위해, S3 버킷 주소와 암호화 키는 각 비즈니스의 폐쇄형 가상 네트워크(VPC) 혹은 애플리케이션 종류에 따라 구분됩니다. 각 백업 노드는 데이터를 암호화하는 내부 백업 툴을 갖추고 있습니다.
클라우드 환경의 블록 저장소가 가진 유연성을 활용하여, 중복 데이터를 제거하고 전통적인 백업보다 빠른 복구 시간을 달성할 수 있었습니다. 내부 플랫폼 사용자들은 MTTR(평균복구시간) 요구사항과 한계 비용 사이에 선택하여 절충할 수 있습니다.
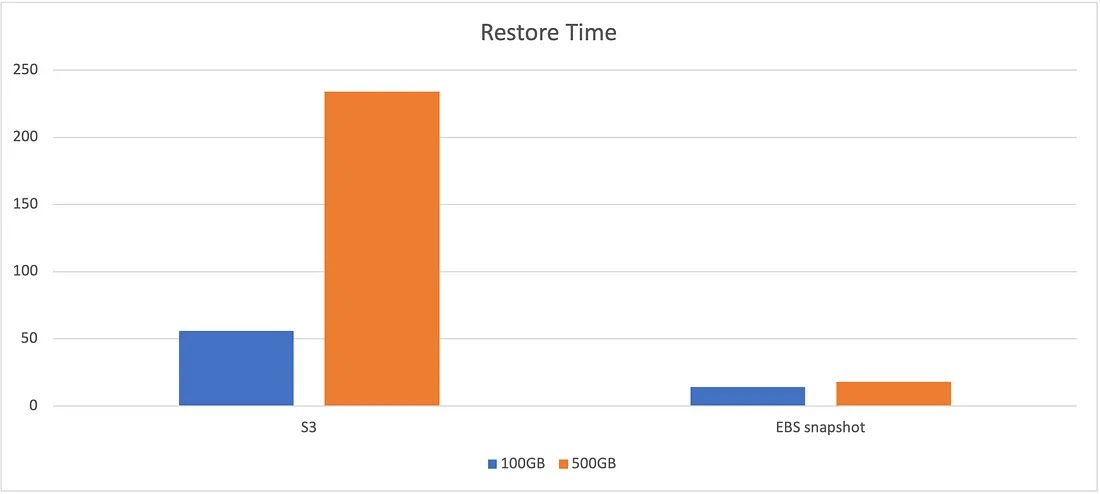
EBS 스냅샷 백업은 분리된 볼륨에 가장 최신 데이터의 스냅샷을 보관합니다. 데이터 복원 시 binlog를 활용해 가장 최근에 작성된 데이터만 동기화하면 됩니다. 그림 2에 나타난 것처럼, S3 백업에서는 스케일 아웃 시간이 선형적으로 증가하는 반면, EBS 스냅샷 백업에서는 스케일 아웃 시간이 데이터 사이즈와 상관없이 비슷합니다.
복제본의 빠른 복원은 온라인 리소스의 장애 조치(failover)에 있어 핵심적인 부분입니다. S3 백업으로 데이터베이스 복구 시 데이터 전송 대역폭에 제한이 있습니다. 프로덕션 환경에서 250M/s를 넘지 않습니다. 저희는 백업 속도가 중요했기 때문에, 주요 서비스 백업은 EBS 스냅샷을 사용하기로 했습니다. EBS는 비용이 더 많이 들지만, 몇 분 안에 복제본 서버를 복구할 수 있습니다. 중요한 쿠팡의 서비스를 신속하게 복구하기 위해 비용과 요구사항 사이에서 적절한 타협점을 찾은 것입니다.
백업 관리에는 백업 작업 생성, 일정 수립, 실행, 복구와 같은 다수의 프로세스가 있습니다. 게다가 쿠팡의 엔지니어들은 매일 수백 개의 클러스터에서 전체 및 증분 백업을 수차례 실행합니다. 복잡한 백업 프로세스를 쉽게 관리하기 위해, 쿠팡 백업 플랫폼은 단순하면서도 사용하기 쉬운 인터페이스를 제공하고 있습니다.

백업 스케줄러를 사용하면 백업 작업 로그, 실행 시간, 현재의 클러스터 머신, 적용된 수정사항 등을 쉽게 관리할 수 있습니다. 또한 사용자는 백업 상세 페이지에서 현재 작업의 백업 유형, 파일 사이즈 등 자세한 내용을 확인할 수 있습니다.
쿠팡 백업 플랫폼으로 백업 관리뿐만 아니라, 백업과 복구 프로세스를 자동화할 수 있습니다. 사용자가 신규 백업 작업 등록을 하려면 클러스터 명, 백업 머신, 실행 시간만 지정하면 됩니다. 실행 시간은 작업 스케줄러(crontab)에서 사용하는 작업 표현식(cron expression)으로 입력하면 됩니다.
마찬가지로, 복구 작업도 굉장히 간단합니다. 사용자는 플랫폼 인터페이스로 복제본 클러스터를 생성한 다음 백업 데이터와 동기화하면 됩니다. 복구 작업 시 EBS 혹은 S3 중 작업 방식을 선택할 수도 있습니다.

백업 데이터 세트의 정확성 및 효율성을 검증하기 위해 저희는 정기적으로 데이터 복구 및 검증 테스트를 합니다. 검증 테스트는 데이터 신뢰도를 향상시키지만, 프로덕션 환경에 영향을 미칠 수 있기 때문에 상당히 까다로운 작업입니다.
저희는 백업 플랫폼에서 아래와 같이 데이터를 검증합니다.
이번 포스트에서는 이전 백업 방식의 단점을 기술하고, 쿠팡 데이터베이스 환경에 적합한 백업 플랫폼을 개발한 사례를 소개했습니다. 백업 플랫폼으로 저희는 데이터 백업 및 복구의 효율성과 신뢰성을 향상시켰습니다.
새로운 플랫폼 덕분에 DBA 엔지니어는 스케줄링된 작업들(cron job)과 배시 스크립트(bash script)의 유지 및 관리 같은 수작업으로부터 해방되었습니다. 백업 프로세스의 모니터링, 알림 기능, 안전장치 모두 이제 자동으로 관리됩니다. 게다가 수동 작업 시 발생할 수 있는 보안 리스크나 운영 사고도 효과적으로 예방하고 있습니다. 전반적으로, 백업 플랫폼은 쿠팡 데이터베이스의 내부 사용자들에게 더 높은 수준의 편의성 및 안정성을 제공하고 있습니다.
이 백업 플랫폼의 개발을 위해 UI, 견고성, 편의성에 대해 끊임없는 피드백을 주었던 DBA 팀에게 감사를 전하고 싶습니다.
<원문>
©️요즘IT의 모든 콘텐츠는 저작권법의 보호를 받는 바, 무단 전재와 복사, 배포 등을 금합니다.