개발
개발자에게 편리함을 주는 ‘GraphQL’ 도입 시 주의할 점은?

7분
2023.07.10.인기
31.1K

프론트엔드 개발자에게 API 통신 비용은 언제나 고민되는 요소다. 모던 브라우저의 경우 성능이 많이 좋아져서 유저가 불편할 정도의 지연은 자주 발생하지 않지만, API 통신은 네트워크 환경의 영향을 많이 받고, 데이터 크기에 따라 속도 차이가 발생할 수 있다. 그래서 API 통신이 포함된 로직을 설계할 때는 유저에게 보여줄 데이터를 언제 캐싱하고, 언제 서버에서 새로 받아올지 잘 결정해야 한다. 그래서 이러한 API 통신 비용 문제를 해결할 수 있는 대안으로, 페이스북에서 개발한 쿼리 언어 ‘GraphQL(그래프QL)’이 등장했다. 이번 글에서는 GraphQL 도입을 고려하고 있는 입장에서 살펴본 GraphQL의 장단점에 대해 소개하고자 한다.
Rest API 시스템에서는 요청의 목적에 맞게 엔드포인트와 응답할 데이터들을 미리 정의한다. [GET] 메서드로 유저 정보를 받아오고 싶다면, 대체로 서버 도메인 끝에 ‘user/[userId]’ 와 같은 경로 변수를 붙여서 요청을 보낸다.
이때 유저 정보를 보여주는 UI가 페이지마다 조금씩 다를 수 있다. 메인 화면에서는 유저의 닉네임만 보여주고, 계정 설정 화면에서는 닉네임과 이메일을 모두 보여주는 경우가 그렇다. 필요한 데이터의 형태가 다르니까 API의 엔드포인트를 두개로 나누어야 할까? 만약 그렇다면 새로운 엔드포인트의 경로 변수는 무엇으로 정해야 할까? 이미 느꼈겠지만 이 방식은 모호하고 비효율적이다. 데이터에 포함할 필드를 유연하게 바꿀 수 없어서 불필요한 필드 값까지 주고받는 오버페칭의 사례이다.
언더페칭은 필요한 데이터들을 한 번의 API 통신으로 전부 받아올 수 없는 경우를 말한다. 앞서 언급했듯 API 통신은 네트워크 환경의 영향을 많이 받는다. 여러 개의 API를 호출할 때는 이 점을 염두에 두어야 하며, 횟수를 줄일 수 있다면 줄이는 것이 좋다. 하지만 통신 횟수를 줄이기 위해 화면마다 1:1로 대응되는 API를 만드는 건 너무 비효율적인 일이다. 따라서 페이스북은 이러한 오버페칭과 언더페칭에 문제의식을 느끼고, ‘GraphQL’이라는 새로운 API 시스템을 설계했다. 그렇다면 GraphQL은 어떤 장단점이 있을까?
장점
GraphQL 시스템의 목적은 클라이언트에서 필요한 필드들을 포함하여 쿼리를 날려서 원하는 데이터들을 유연하게 응답받을 수 있도록 하는 것이다. 물론 클라이언트에서 직접 DB에 접근하는 것은 아니고, 요청 쿼리에 포함될 수 있는 모든 필드에 대해 어떤 데이터를 가공해서 보낼지 미리 서버에서 구현해 두어야 한다. GraphQL을 통해 API 요청을 유연하게 보낼 수 있게 됨으로써, Rest API에서의 오버페칭, 언더페칭을 개선하고 클라이언트의 자유도가 높아질 수 있다.
Rest API와 달리, 하나의 엔드포인트에 대해서 요청을 보내도록 되어 있기에 API별로 엔드포인트를 지정하고 요청 객체의 형태를 논의해야 하는 수고가 사라진다. DB 모델, 혹은 백엔드에서 재정의한 데이터 스토어 모델의 형태를 참고하여, 원하는 필드를 요청 쿼리에 포함해서 보내기만 하면 된다. 결과적으로 프론트엔드와 백엔드 사이의 의사소통 비용이 줄어든다.
GraphQL은 필요한 필드만 응답받기 때문에 클라이언트에서 응답 데이터의 타입을 정의하거나, 응답 데이터의 객체를 필터링하는 로직을 넣지 않고 받은 데이터를 그대로 사용할 수 있다. 오버페칭 해결로 인한 직접적인 장점으로 볼 수 있다. 물론 로직이 간결해진다는 것은 클라이언트 입장에서의 장점이다. 백엔드 쪽에서는 Rest API에 비해 요청 쿼리 핸들링을 위한 추가 로직이 더 필요해질 수도 있다.
단점 및 한계
GraphQL은 아직 성장하고 있는 오픈소스인 만큼 지속적으로 기능이 추가되고 있다. 또한 논의 중인 이슈들도 많아 앞으로 스펙 상 변경도 많을 것으로 예상된다. 따라서 머지않아 여러 문제가 해소될 가능성이 높지만, 우선 현시점을 기준으로 단점이라 언급되는 점들은 다음과 같다.
HTTP 통신 시 헤더 설정을 통해 데이터를 캐싱할 수 있는데, Rest API 시스템에서는 각각의 엔드포인트별로 얼마 동안 캐싱해둘지 API 헤더를 통해 간단하게 지정해둘 수 있다. 반면 GraphQL은 단일 엔드포인트를 사용하기 때문에 HTTP 캐싱의 이점을 누리기 어렵다.
이에 GraphQL 사용자를 타깃으로 플랫폼을 만드는 Apollo팀은 이를 해결하기 위해 자체적인 라이브러리를 만들었다. Apollo Client 라이브러리에서는 캐시 옵션을 제공하고, 이 옵션으로 캐싱을 걸어 두면 메모리 상에 캐싱 데이터가 저장된다.
GraphQL에서는 여러 개의 데이터를 쿼리로 요청하는데, 성공한 쿼리는 data 필드에 담기고, 실패한 쿼리들은 erros 필드에 배열로 담긴다. error 배열이 가지고 있는 객체들은 각 쿼리 필드에 대한 실패 사유와 실패한 위치 정보를 담고 있다. 클라이언트에서는 요청한 데이터 각각에 대한 에러 여부를 파악하고 대응해야 하므로 에러 핸들링이 매우 까다롭다. 사실 여러 개의 데이터를 한 번에 요청하는 경우, 에러 핸들링은 Rest API 시스템에서도 어려운 일이다. 그런데 GraphQL에서는 항상 여러 개의 데이터를 요청하는 것을 기본 전제로 하므로 더 어려워진 것이다.
앞서 언급한 Apollo Client 라이브러리는 에러 핸들링을 위해, 데이터 흐름을 제어할 수 있는 Link라는 기능도 제공한다. 이를 활용하면 에러를 중간에 가로챌 수 있고, 렌더링 로직과 분리해서 비교적 깔끔하게 핸들링할 수 있다.
사실 프론트엔드에서 GraphQL을 사용하기 위해서는 Apollo Client 라이브러리를 쓰는 게 편하다. 여러 유용한 기능이 제공할 뿐만 아니라 사용자가 많아 생태계도 넓기 때문이다. 만약 라이브러리에 의존하는 것이 싫고 직접 쿼리를 fetch하고 싶다면, 이 글에서 언급한 문제들을 비롯해 여러 문제를 직접 핸들링해야 하므로 개발 시간이 늘어나는 것을 감수해야 한다.
이는 백엔드 개발자의 입장에서 단점으로 볼 수 있는데, GraphQL의 최대 단점은 Rest API에 비해 구현하기 복잡하다는 것이다. 클라이언트에게 자유롭게 쿼리를 보낼 수 있도록 열어준 순간부터, 서버는 그 모든 쿼리 조합을 어느 정도 예상하고 미리 대응해야 한다. 클라이언트에서 요청하는 데이터는 쿼리 때문에 무거워지고, 응답 데이터는 그보다 훨씬 더 무거워질 수 있다. 따라서 서버에 부담을 주지 않도록, 쿼리의 최대 개수나 뎁스를 제한하는 것을 고려할 수도 있다. 이처럼 API 설계 시 고민할 지점들이 매우 많아지는 것이다.
만약 반복적으로 적은 양의 데이터만을 주고받는 가벼운 서비스에서 GraphQL을 도입하면 오버 엔지니어링을 유발할 수 있다. Rest API와 GraphQL에 따른 성능 차이가 미미하다면, 단순하고 빠르게 개발할 수 있는 Rest API 방식을 채택하는 게 합리적이다. 개인적으로 가벼운 프로젝트에서는 Rest API와 GraphQL의 성능 차이를 크게 느끼지 못했고, Rest API 방식이 구현하기에 단순하다고 느꼈다.
실제로 GraphQL을 적극적으로 채택한 개발팀을 보면 깃허브, 페이스북, 넷플릭스 등 서비스 규모가 큰 기업들이다. 그들도 분명 GraphQL을 도입할 때 개발의 복잡성과 서비스 퍼포먼스 사이의 트레이드오프를 계산했을 것이다. 또한 해당 서비스들은 다양한 형태의 요청이 자주 있기 때문에, GraphQL의 도입이 더 의미 있었다고 볼 수 있다.
최근 마이크로서비스 아키텍처(MSA)를 채택하는 곳이 많아지고 있다. MSA는 큰 서버를 기능별로 잘게 쪼개 작은 서비스로 모듈화하는 방식이다. 각각의 서비스는 따로 개발되고 빠른 주기로 배포하여 서로 API를 통해 통신한다. 이는 모놀리식 아키텍처에 비해 복잡하지만 생산성이 높다고 평가받는 아키텍처이다.
앞서 말한 넷플릭스에선 이러한 MSA를 채택하고 있는데,백엔드 서버가 MSA인 경우 클라이언트에서 각 서비스에 API 요청을 각각 보내야 해서 또다시 언더페칭이 발생한다. 언더페칭을 해결하기 위해 복잡성을 감수하며 GraphQL을 채택했는데, 다시 언더페칭이 발생한다면 결국 복잡하다는 단점만 남게 되는 것은 아닐까? 이에 아폴로 팀에서는 ‘federation’이라는 개방형 아키텍처를 제공함으로써 이 문제를 해결했다.
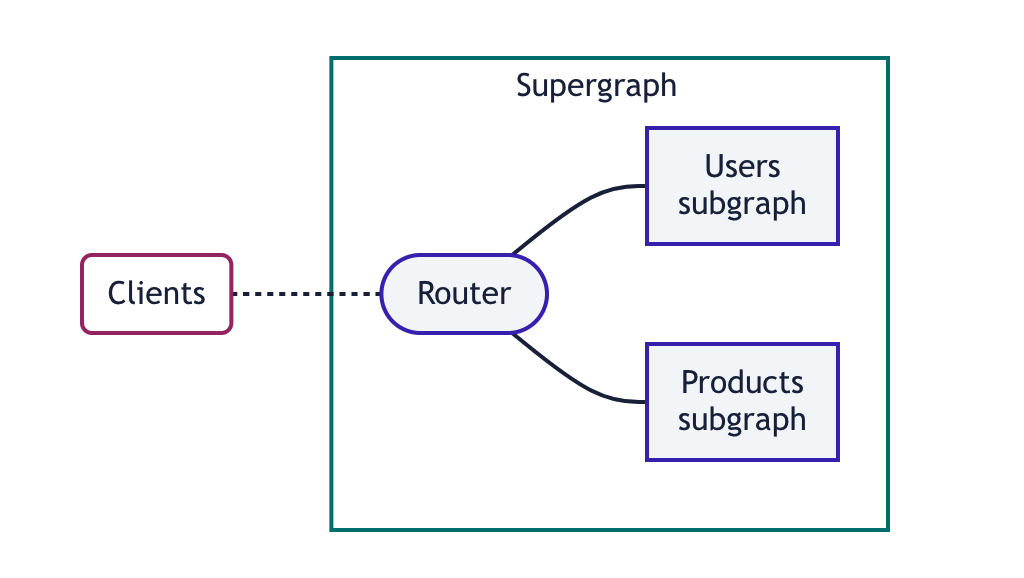
아폴로 팀에서 만든 ‘Apollo Federation’ 스키마는 일종의 게이트웨이 역할을 한다. 여러 개의 백엔드 서비스가 있을 때, 각각의 요청은 하나의 ‘Federation’ 그래프로 보내지고, 각각의 요청이 다시 서브 그래프로 라우팅되는 개념이다. 따라서 각각의 서비스는 subgraph로서 개별 스키마를 갖는다. 이 스키마는 supergraph로 합쳐지고, 클라이언트는 슈퍼그래프에 쿼리 요청을 보낸다.
supergraph는 요청받은 쿼리를 각각의 subgraph에 라우팅해서 응답 결과를 받아 클라이언트에게 돌려준다. 각각의 subgraph들이 마치 연방제처럼 자율성을 가지고 협력하는 형태이다. 현재 GraphQL을 도입하여 사용하고 있는 넷플릭스도 Apollo federation 스키마를 적극적으로 사용하고 있다고 한다.
API를 가져다 써야 하는 프론트엔드 개발자로서 생각해 보면, GraphQL을 도입하면 개발을 더 능동적으로 할 수 있어 장점이 크게 느껴진다. 어쩌면 곧 GraphQL이 지금보다 더 널리 활용될 수도 있을 것 같다는 생각이다. 또한 Rest API는 유연하지 못하다는 단점이 있으니, 컴퓨팅 파워만 충분하다면 클라이언트에서 직접 쿼리를 보내 원하는 데이터를 얻는 방식은 충분히 효율적이다.
하지만 현재 기준으로 성능 트레이드오프를 고려할 때, GraphQL은 아직 서비스 특성에 따라 장단점이 극명하다. 따라서 다른 많은 기술과 마찬가지로 GraphQL 도입 여부는 신중하게 검토해야 한다. 도입 전 아래 질문에 답변해 보자.
팀에 따라 고민해 볼 사항은 이것 말고도 더 있을 수 있다. 만약 모두에게 긍정적인 결론이 나왔다면 그때 마이그레이션을 시작해 봐도 좋을 것이다.
<참고 자료>
©️요즘IT의 모든 콘텐츠는 저작권법의 보호를 받는 바, 무단 전재와 복사, 배포 등을 금합니다.