개발
파이썬 3.11은 어떻게 빨라질 수 있었을까?

9분
2023.06.30.인기
29.2K
2022년 스택오버플로우 서베이에서 파이썬은 가장 배우고 싶은 언어 2위를 차지할 정도로 인기가 많다. 이 인기가 현재 진행형이긴 하지만, 과연 미래에도 지속될지는 모르는 일이다. 파이썬은 아직도 개선점이 많고, 많이 쓰이지만, 그 사용이 제한적인 부분도 있기 때문이다. 귀도 반 로섬(Guido Van Rossum)에 의해 창시된 파이썬은 지금 동적 타이핑(Dynamically Typing), 인터프리터식, 그리고 객체지향 언어로 다양한 프레임워크, 즉 장고(Django), 플라스크(Flask), 패스트 에이피아이(FastAPI) 등등과 함께, 딥러닝 및 그외 여러 프로그램들과 함께 성장하며 그 위세를 떨치고 있다.
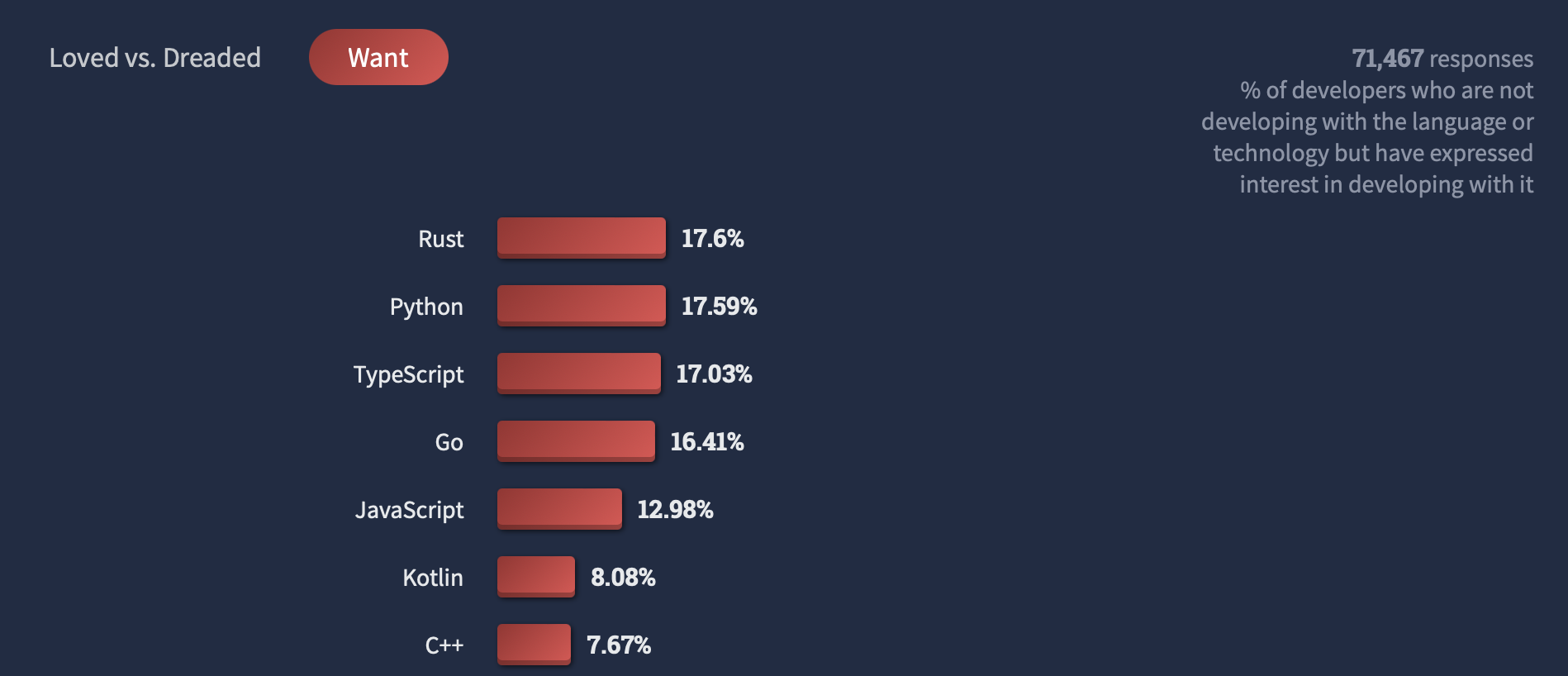
하지만 이러한 파이썬도 명확한 한계점이 지적된다. 속도이다. 속도가 무조건 프로덕트에 영향을 끼치는 것은 아니다. 오히려 파이썬의 다양한 라이브러리와 빠른 개발 속도를 통해 프로덕트의 개발 시간을 단축시킬 수도 있다. (그렇다고 파이썬으로 개발 시간을 단축한 뒤에도 그것이 점점 성장하는 회사의 대규모 인프라에 적합한가 하면 그건 또 의문이다.) 파이썬은 자바, C, C++만큼 빠르지는 못하다. 그리고 커뮤니티를 통해서 이러한 한계점이 지적되어 왔던 것도 사실이다.
귀도 반 로섬은 파이썬 랭귀지 서밋(Python Language Summit)에서 파이썬을 빠르게 만드는 것을 언급했으며, 파이썬 3.11은 그에 대한 첫 결과물로 볼 수 있을 것이다. 이 글에서는 파이썬 3.11이 어떻게 빨라졌는지에 대해 알아보려고 한다.
이번 업데이트에서는 변경된 점이 많은데, 다음과 같다.
5Ghz CPU에서 위와 같은 메모리 접근성을 보인다. 물리적인 접근은 L1, L2, L3 그리고 RAM으로 갈수록 소통이 비싸진다. 즉, 어느 프로그램이든 메모리 접근이 있으면 물리적인 한계로 인해 프로그램이 느려질 수밖에 없다. 만약 다른 프로그램이 특정 메모리 주소를 접근하려고 할 때, 다른 프로그램이 그 메모리 주소를 점유하고 있다면 더욱더 느려질 수밖에 없을 것이다.
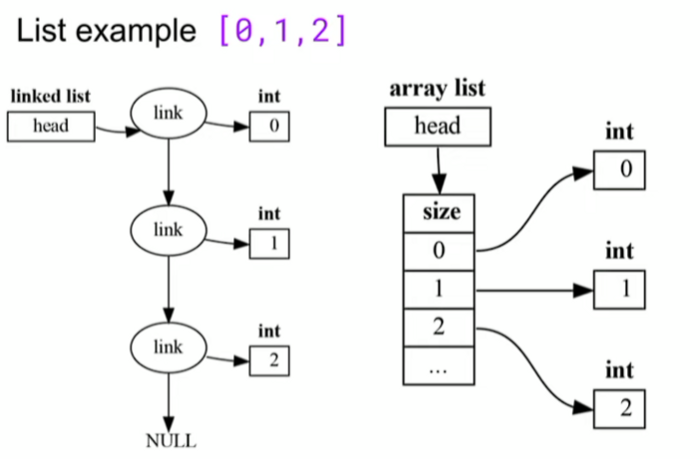
Linked List와 Array을 잠시 보고 가겠다. 만약 우리가 두 번째 요소를 읽겠다고 하면 Linked List의 경우는 Head에서 2번째 요소까지 4번 메모리 접근을 해야하는 악재가 따른다. 하지만 배열의 경우는 두번의 메모리 접근(즉, 헤드에서 Array로 그리고 Array에서 각 요소로 한번에 접근)할 수 있다. 메모리 접근에서는 이득을 보인다. 만약 메모리를 더 할당하려면 Linked List는 메모리를 더 할당해야 할 것이다. 따라서 이러한 의존성과 메모리 접근을 최대한 피하기 위한 프로그래밍 언어 설계는 힘든 편이기도 하다.
여기서 다른 이야기인 프레임(Frame) 스택에 대해 이야기하고 넘어가야 할 것 같다. 이 프레임 스택은 파이썬 함수를 부를 때 사용되는 객체이다. 각각의 파이썬 함수를 부를 때마다, 프레임 객체(Frame Object)를 스택에 넣는다. 이때 이 프레임은 지역 변수, 임시 값을 위한 공간, 이전 프레임, 전역 변수 그외 등등을 위한 참조, 그리고 디버깅 정보를 가지고 있다.
위에서 설명했다시피 파이썬 프레임은 Linked List로 연결되어 있었고, 이는 Top에 있는 스택만 가져와서 부르기에는 편했다. 하지만 다른 스택을 부르기에는 추가적인 비용도 들고 새로운 공간 할당을 위해 공간을 비워둬야 하는 등 위에서 말한 메모리 접근 측면에서 굉장히 큰 비용을 치르게 된다. 3.10이하 에서는 이러한 공간 할당을 위한 Caching이 없었고, 그리고 있었다 하더라도 그렇게 효과적이지 않았다. 실제로 3.10이하에서는 링크 스택을 위해 많은 메모리 청크가 스레드마다 할당되어 있었고, 만약 새로운 프레임이 생성될 경우 기존 메모리를 참고해야 하는 경우가 생긴다. 이는 곧 L1같은 빠른 메모리에서, L2, L3, 그리고 RAM같은 느린 메모리로 접근할 때 많은 대가를 치르게 된다.
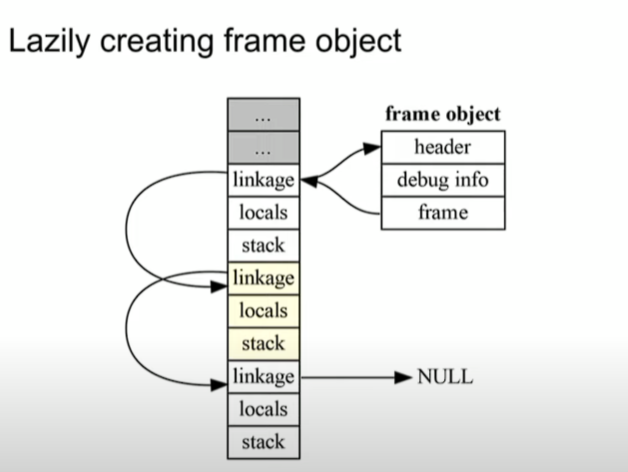
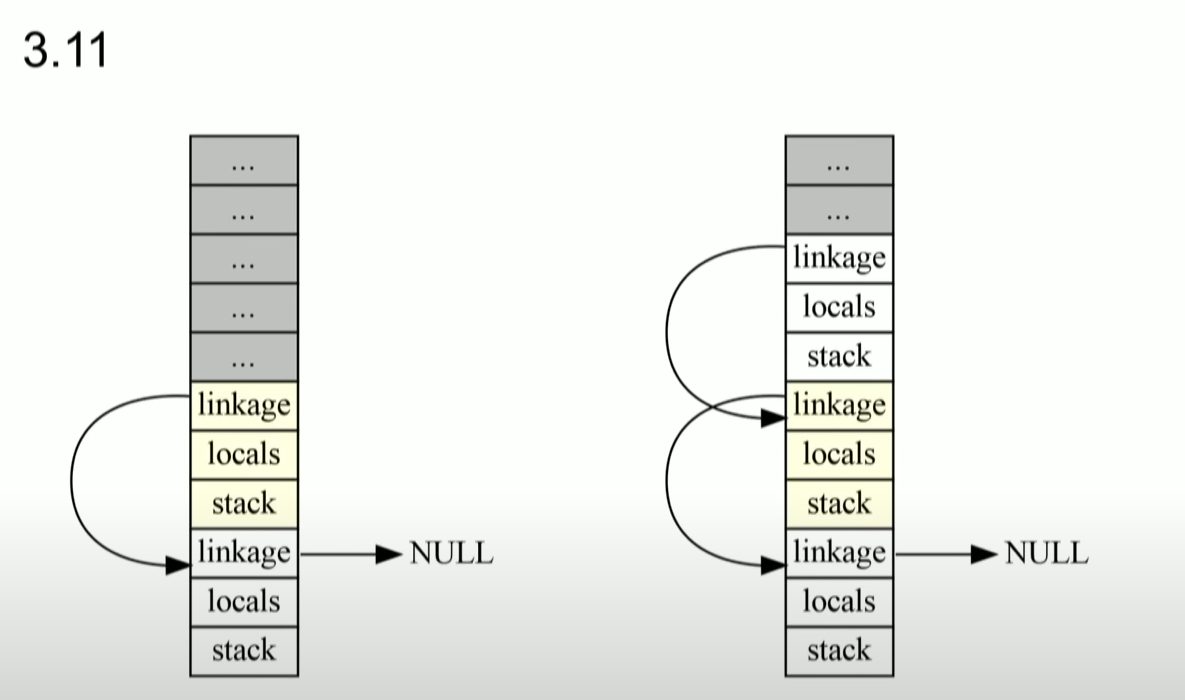
파이썬 3.11에서는 이를 아주 큰 메모리 할당을 통해 해결하고자 했다. 일단 미리 큰 메모리를 할당해놓는데, 얼마나 큰 프레임 스택을 얻게 될지 몰라서이다. 그리고 메모리에서 새로운 할당보다는, 재사용을 통해 메모리 활용성을 높이고자 했다. 그리고 이러한 프레임 객체를 재활용할 때, 파이썬 3.11에서 프레임 객체는 느리게(lazily) 생성된다. 이는 곧 더 적은 메모리를 요구한다. 물론 이러한 느린(lazily) 생성은 무조건 모든 케이스에 맞는 것이 아니지만, 이러한 경우는 적기에 3.10과 비교했을 때 굉장히 큰 이득을 얻게 된다.
그래서 3.10 이하와 비교했을 때 3.11은 두 가지 변경점을 가진다. 먼저 디버깅 정보가 느리게 생성된다. 왜냐하면 이는 기본적으로 프레임 스택의 직접적인 파트가 아니기 때문이다. 그리고 Exception 스택이 버려졌다. 또한 네임 스페이스 Dict이 키값을 가능할 때마다 공유한다.
위의 그림을 보다보면, Exception 스택이 없어진 것을 확인할 수 있다. 이는 메모리 절약을 위해 사용된다. 그 이유를 알기 위해 Exception이 어떻게 활용되는지를 보면 된다.
3.10에서, try-except는 바이트코드에 명시적으로 구현되어 있다.
3.11에서 정보는 테이블에 저장된다.
꽤나 Zero, 하지만 완벽하지 않은 Zero

위의 코드는 두개의 attribute를 가지고 있으며 a, b를 할당한다. 위의 코드가 메모리 상에서 어떻게 접근하고 메모리를 점유하는지 알아보자.
대부분의 모든 파이썬 객체는 __dict__을 가지고 있다. 이때 __dict__ 속성은 거의 직접적으로 사용되지 않는다. 파이썬 객체는 고정된 크기를 가지고 있지 않다. 그리고 __slots__이라는 속성을 가지고 있을 수 있다. 또는 List처럼 빌트인 타입들로부터 상속받을 수 있다. 이러한 것들은 읽기 쉽고 직관적인 코드를 제공해준다. 이는 곧 dict["attribute"]처럼 할 필요 없이 dict.attribute로 가능케 한다. 하지만 모든 객체가 이러한 방식을 사용하는 것이 아니다. 아까 언급했듯이 __slots__라는 속성을 가지고 있을 수 있고, 그 외에도 다양한 타입을 가질 수 있다.
이는 곧 다시금 말하지만 크기가 가변적이라는 것이다. 이러한 특성으로 인해 일반적인 파이썬 객체의 실행은 느리다.
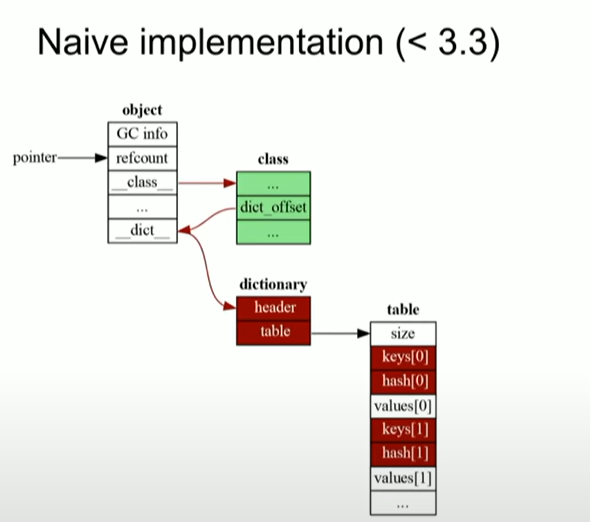
위의 그림을 보면, 흰색 박스로 된 객체가 있다. 그 객체는 클래스로 향하는 포인터를 가지고 있다. 그리고 다시 이 클래스는 객체를 가리키는 포인터를 가지고 있다. 이는 가변적인 사이즈로 인해 발생하는 문제이다. 따라서 dict_offset을 통해 __dict__이 있는 곳을 찾는다. 여기서 사진의 초록색으로 칠해진 클래스(class)는 객체가 몇개가 있든 단 하나만 존재한다. 하지만 빨간색으로 칠해진 곳은 다르다. 빨간색으로 칠해진 dictionary(header와 table) 속 값들은 해시와 키, 그리고 값들로 이루어져있다.
따라서 위의 경우를 self.a에 대입하면, 키 a에 저장되는 값들이 테이블로 이루어진다. 이를 개선한 것이 3.2까지의 일이다.
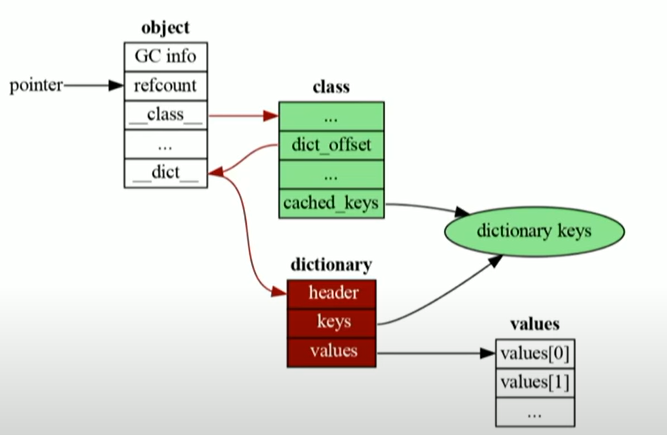
3.3부터 3.10까지는 데이터 구조를 조금 변경해서 딕셔너리 키들(3.2까지는 테이블에 있던 것들을) 클래스의 인자로서 작동하도록 만들었다. 이를 통해 중복되는 키값을 지울 수 있게 되었다. 이러한 것들은 전부 분리된 데이터 구조로 나뉘어 class와 dictionary가 공유되도록 해준다.
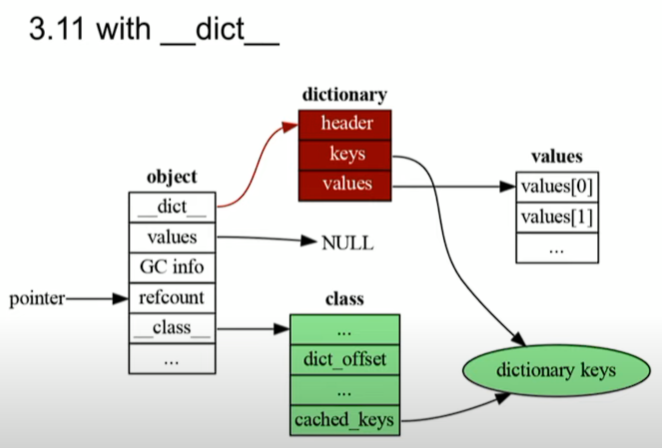
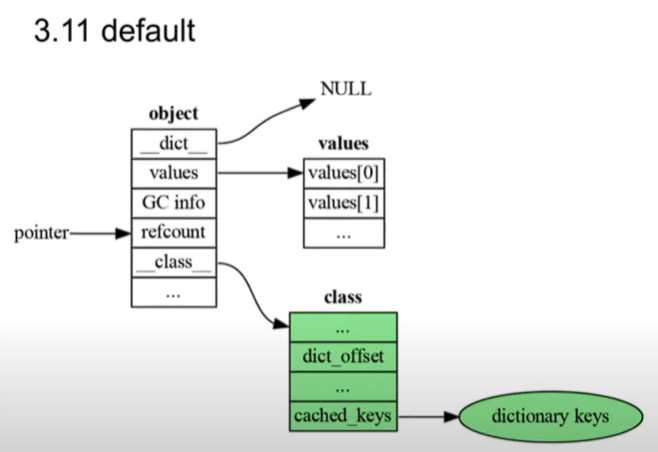
3.11에서는 한 번 더 바뀌게 되는데, 포인터의 위치 변경이다. 기본적으로 딕셔너리의 포인터 __dict__이 고정된 offset 즉, object의 앞으로 옮겨지게 되었다. 이는 곧 dict_offset을 통해 참조할 필요가 없어짐을 보이는 것이며, 이를 통해 메모리 접근을 줄이는 결과를 보이기도 한다. 즉 메모리 크기를 줄인 것은 아니지만, 메모리 접근, 메모리 사이클에 대해서 어느 정도 줄이게 되었음을 의미한다. 또한 딕셔너리를 줄여서 딕셔너리 키를 class를 통해 접근할 수 있게 한다. 모든 값들이 object에 넣어졌을 때 접근할 수 있도록 하기도 했다.
즉 이를 요약하자면, 기존에 있던 dictionary의 메모리 크기는 줄이지 않았지만, 메모리 자체에 대한 접근을 줄여서 속도를 향상시킨 것이다.
간단하게 설명하자면 기계어와 소스코드 사이의 중간 코드라고 보면 편하다. 파이썬의 경우 인터프리터 처럼 한 줄씩 읽고 실행할 수 있다. 인터프리터 언어와 컴파일 언어 등등 많은 분류법이 있지만, 인터프리터와 컴파일은 하나의 실행 방식이며 언어의 구성요소가 아니다. 따라서 파이썬은 컴파일 언어라고도 볼 수 있고 인터프리터 언어라고도 볼 수 있다. 왜냐하면 실행 방식에 따라 달라지기 떄문이다. 만약 당신이 CPython(C기반의 바이트코드 컴파일 도구)이나 Jython(Java기반의 바이트코드 컴파일 도구)를 사용한다면 바이트코드로 변환할 것이다. 하지만 PyPy를 쓴다면 Just-In-Time컴파일러로 사용된다. 즉 상황에 따라 달라질 수 있다.
이 글에서는 가장 표준적인 파이썬 구현체 CPython에 대해 이야기할 것이다. CPython은 바이트코드로의 컴파일을 자동으로 해주는 인터프리터이다.
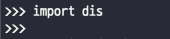
파이썬에는 특별한 모듈이 있다. 바로 dis모듈이다. 이 모듈을 이용하면 CPython 바이트코드를 역 어셈블하여 분석을 지원한다. 다음과 같은 함수를 dis 모듈을 이용하여 분석해 보겠다. (이 경우 파이썬 3.11의 직전 버전인 3.10을 사용했다.)
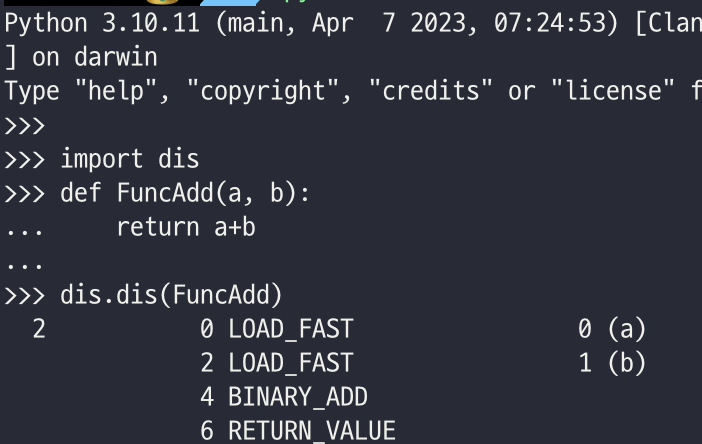
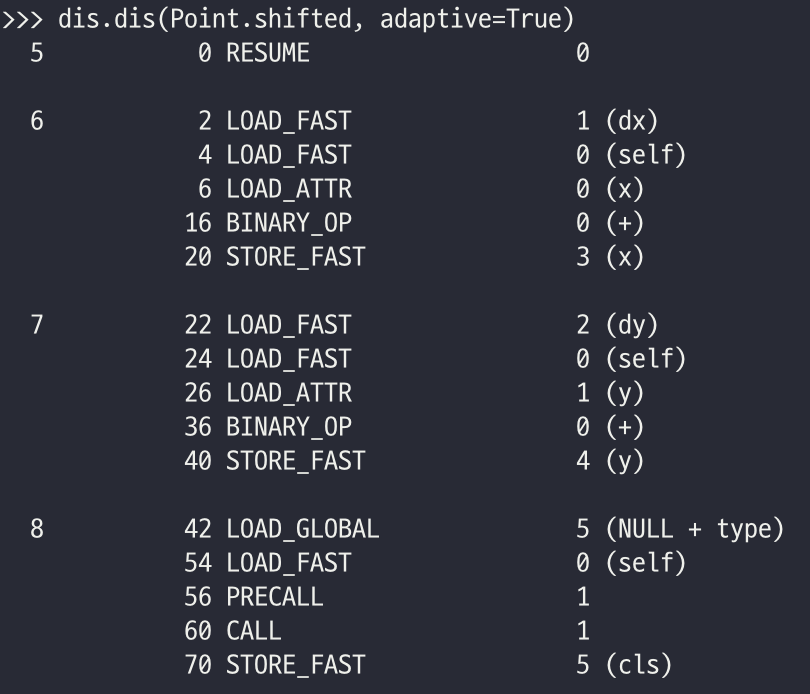
위와 같이 바이트 코드가 나오는 것을 볼 수 있다. dis에서 dis메소드를 통해 분석할 수 있는데, 이를 통해 나온 결과물이 위의 사진이다. 이 함수의 경우 두 인자를 받아서 첫 번째 인자에서 두 번째 인자를 더하는 것이다. 간단하게 이를 분석해 보자면 다음과 같다. 일단은 각 바이트코드(OP CODE)가 무엇을 의미하는지부터 알아보겠다.
여기서 파이썬 3.11은 한 가지 사실에 주목한다. 위에서 작성한 함수 FuncAdd와 같은 함수가 불렸을 때, 여러 번 호출된다면 같은 것을 여러 번 활용하는 것이 새로 여러 번 만드는 것보다 더 이득이다. 즉 파이썬은 이 점에 주목해서 코드가 일정 횟수 이상 호출되면 최적화 - 적응화가 되는 것이다.
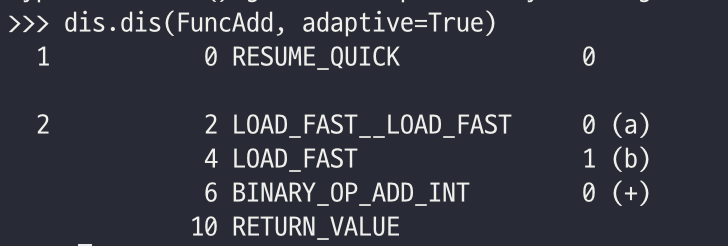
위의 코드를 한번 for문에 넣어서 여러 번 반복해 보았다. 여러 부분이 바뀐 것을 확인할 수 있다. 일단 먼저 첫번 째 줄인 LOAD_FAST__LOAD_FAST이다. 이는 Superinstructions으로 위의 예시에서는 두 개의 인자가 아니지만, 일단 LOAD_FAST__LOAD_FAST의 경우 두개의 Instruction을 동시에 실행하는 것이다. 이는 다음과 같은 코드에서 발견할 수 있다.

위의 코드를 여러 번 불러보면 다음과 같은 코드로 변환이 된다. 즉 여러 번 돌리면서 일정 수준 이상의 코드가 반복되면 파이썬 인터프리터에서 자체적으로 최적화를 하는 것이다.
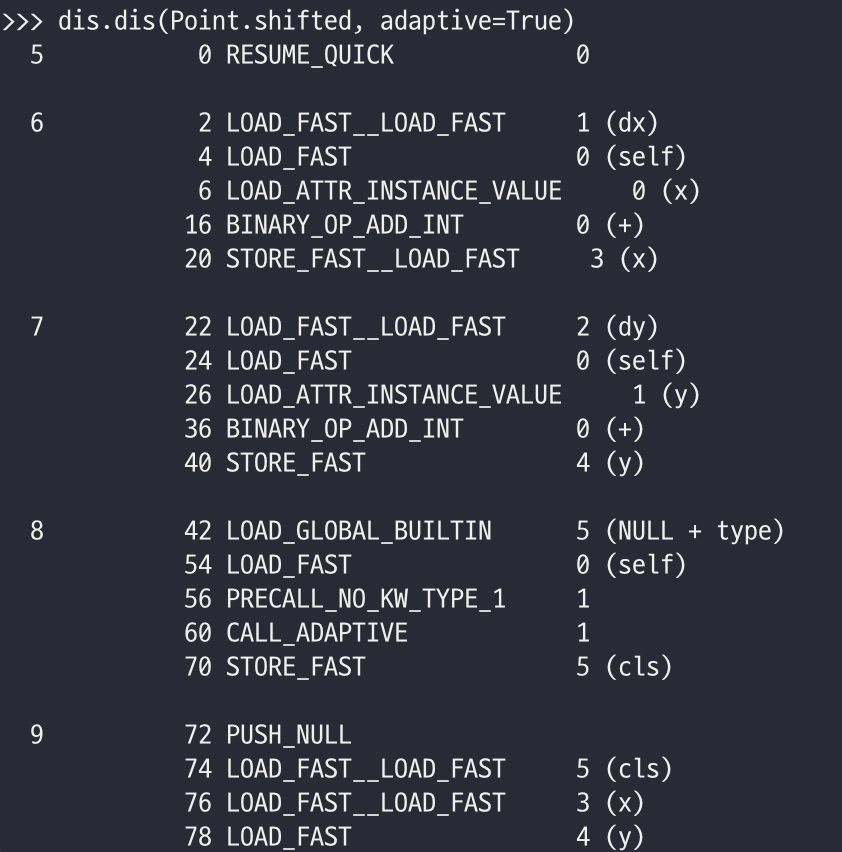
도중에 들어가 있는 BINARY_OP_ADD_INT를 한번 살펴보겠다. 이는 더하기 연산자의 최적화된 버전으로 앞에서 이야기했듯이, 여러 번의 데이터 타입 체크가 이루어진 후, 만약 이 부분이 계속해서 이루어져서 더 이상 괜찮다고 판별될 경우, 바로 스킵하고 더하기 연산자를 실행한다.
즉, 여러 번의 코드가 실행되고 만약 이것이 더 이상 의미 없는 과정을 포함하고 있으면 과감하게 스킵해 버리는 것이다. 만약 그런 경우가 아니라면? 바로 기존의 OP코드로 돌아가게 되고 비슷한 과정을 거친다.
PRECAL_NO_KW_TYPE_1도 주목할만한 변경점이다. 앞에서 말했듯이 호출은 굉장히 큰 속도 저하를 일으킨다. 위의 경우에는 type을 호출하고 있다. 만약 기존의 경우라면 계속해서 type을 호출했을 것이다. 만약 type이 계속 호출된다면, 일정 숫자를 넘길 시 바로 인자의 클래스를 가져온다.
정리하자면, 계속해서 비슷한 경우가 발생할 경우 이에 대해 최적화된 OP코드로 변환시키고 만약 도중에 그렇지 않을 경우 전으로 돌아간 다음에 다시 이와 같은 경우를 반복하는 것이다.
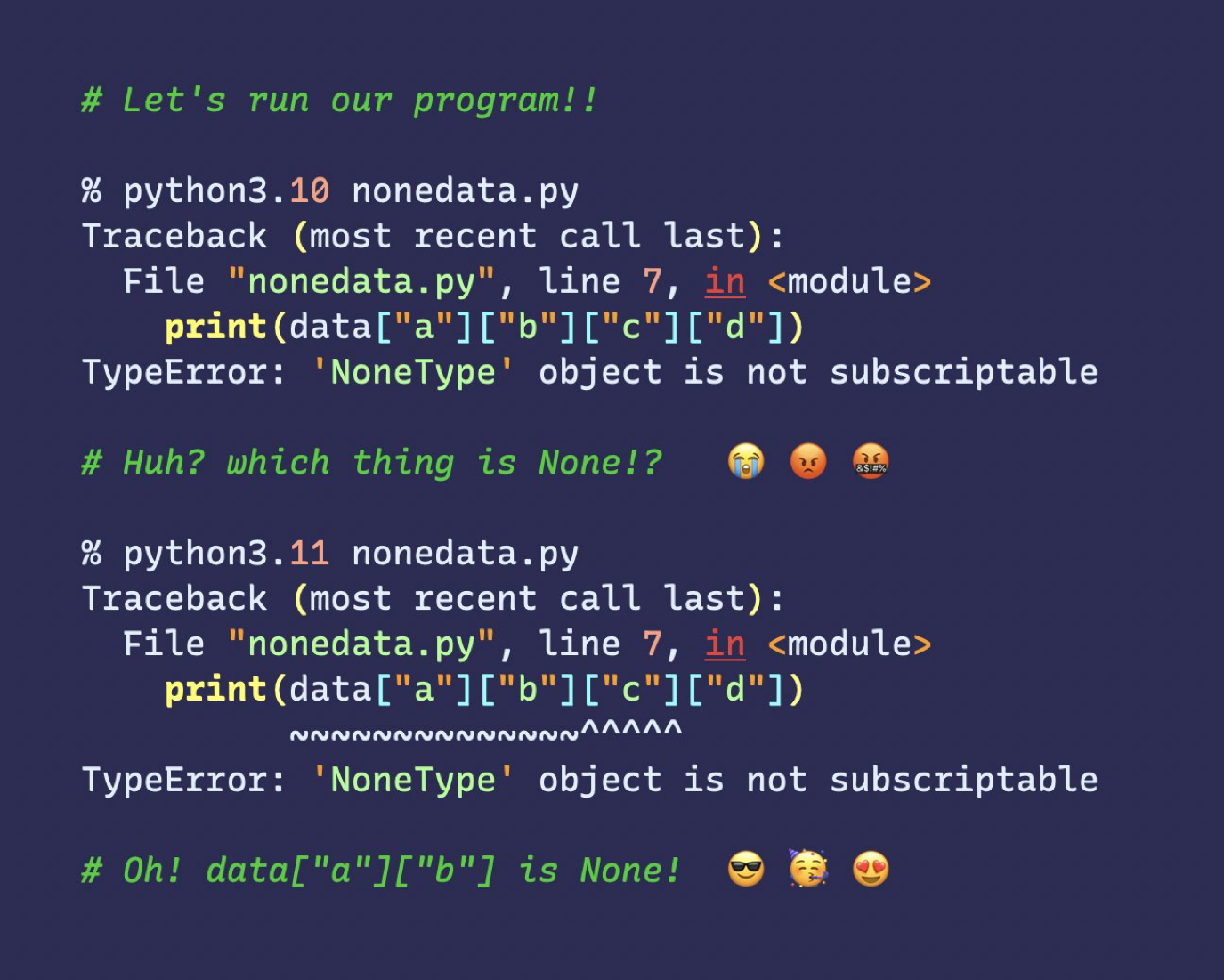
그 외에도 여러 가지 변화점이 있지만, 아주 현실적으로 프로그래머들에게 와닿을 변경점은 바로 에러 표시의 정확성이다. 기존에는 어느 부분에서 에러가 났는지 대충이나마 파악할 수 있었다면 이제는 더더욱 세밀하게 파악할 수 있게 된 것이다.
앞에서 말했듯 많은 팬층을 가지고 언어로서, 다양한 발전을 보여주고 있는 것은 파이썬 유저로서 굉장히 반가울 다름이다. 이렇듯 파이썬은 계속해서 발전해 나갈 거라고 믿으며 오늘 하루도 파이썬으로 프로그래밍을 해본다.
©️요즘IT의 모든 콘텐츠는 저작권법의 보호를 받는 바, 무단 전재와 복사, 배포 등을 금합니다.