기획
모수와 표본: 모수가 이렇게 충분한데 그냥 쓰면 안 될까?

3분
2023.03.20.28.9K

[데이터 분석가의 숫자유감] 3화









‘이해가 어려운 것은 자신의 언어로 바꾸어서 생각하라’는 공부법이 있다. 구구단에서 2×2 = 4를 외우기가 힘들면 ‘사과 2개를 두 번 사오면 네 개가 된다’라고 생각하는 식이다. 이 방식은 대부분 사람에게 굉장히 효과가 좋아, 유용한 학습법으로 알려져 있다.
이 방식은 공부뿐만 아니라 삶의 전반에 사용된다. 많은 사람은 많은 개념을 자기가 아는 식으로 풀어서 생각하고 적용한다. 물론 이런 방식을 통해 지식의 저변을 넓히게 되고, 사과만 살 줄 알아도 구구단을 외우게 되지만, 이 방식에도 단점은 있다. 다양한 방식과 다양한 분야를 이해하지 못한 채, 자신이 생각하는 방식과 알고 있는 개념에 천착하게 되는 것이다. 그래서 새로운 개념이 생겼을 때 받아들이는 것을 어려워하는 사람이 되어버리고 만다. 요즘처럼 빠르게 변하는 세상에서 살아가기에는 꽤나 슬픈 일이다.
아마도 이런 사람들이 새로 받아들이기 어려워하는 것이 데이터의 세계요, 통계의 개념일 것이다. 데이터와 통계 개념을 널리 사용하게 된 것도 거의 10여 년이 다 되어가고 ‘이제는 먹고살기 위해서 데이터 사용이 필수 불가결하게 되었다’고 사람들도 겨우 인지하게 되었다. 그런데 이를 활용하는 사람 중 상당수가 ‘자신의 사고방식으로 풀어서’ 이해하고 받아들이고, 이 과정에서 적지 않은 블랙코미디가 발생한다. ‘모수’와 ‘표본’이 대표적으로 이렇게 오용되는 개념이다.
모수란 무엇일까? 의외로 많은 사람이 ‘모수’를 ‘모집단’의 수라고 생각한다. 그러면 모집단이란 무엇일까? 물어보면 ‘전체 집단’이라고 한다. 전체 집단은 무엇일까? 그냥 ‘전체 회원’이라고 생각한다.
하지만 ‘전체 집단’을 정의하는 것은 그렇게 간단하지 않다. 이 서비스에서 전체 회원이 매일 들어오지 않는다면, 하루의 회원 활동 스냅샷을 가지고 모집단이라고 할 수 없다. 그러면 전체 회원이 다 들어오는 그날까지의 데이터를 모으면 모집단일까? 그 기간까지의 모든 회원의 형태는 항상 동일할까?
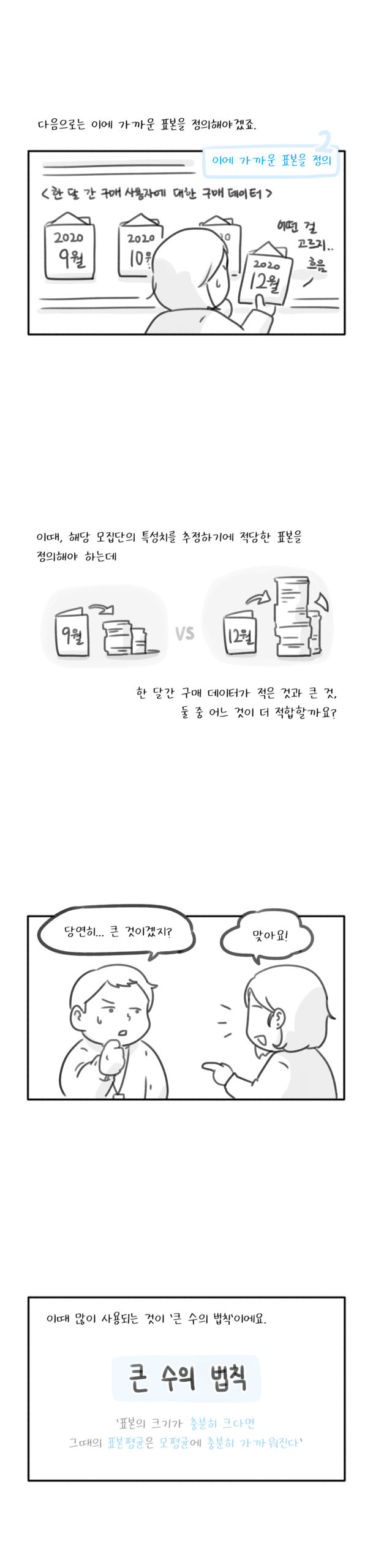
‘모집단’ 개념은 그래서 매우 간단한 듯하면서도 의외로 복잡하고 추상적인 면이 있다. 그래서 우리는 모집단을 어느 정도 정의한 후, 모집단에 가까운 표본을 정의하고, 이 표본을 구하는 방법을 고민한 후, 표본에 대한 데이터를 수집한다. ‘전체 사용자의 구매’ 패턴을 파악하고자 했을 때, ‘전체 사용자’라는 개념을 일단 어느 정도 정의하고, 이 중에서 사용할 데이터를 찾는다. ‘2020년 12월 한 달의 구매 사용자에 대한 구매 데이터’라고 사용할 데이터를 정의하면, 이 데이터는 일종의 ‘표본’이 된다.
표본을 정하고 나면 ‘표본’이 해당 ‘모집단’의 특성치를 추정하기에 적당한 것인지를 고민한다. 이때 많이 사용되는 것이 ‘큰 수의 법칙’이다. 큰 수의 법칙은 표본의 크기가 충분히 크다면 그때의 표본 평균은 모평균에 충분히 가까워진다는 것이다. 그래서 이렇게 정의한 한 달의 구매 사용자의 구매 데이터가 충분히 커진다면, 표본 데이터의 평균이 전체 사용자의 평균에 더 근접해질 것이다. 이 외에도 중심 극한 정리동일한 확률 분포를 가진 독립 확률 변수 n개의 평균의 분포는 n이 적당히 크다면 정규 분포에 가까워진다는 정리 등 다양한 가정을 사용해서 표본으로 모집단의 형태를 추정해나간다.
그렇다면 모수는 뭘까? 모수는 ‘모집단의 수치적 요약값’이다. 모평균이나 모표준 편차 같은 모집단에 대한 통계 값을 모수라고 한다. 그리고 표본 데이터에서 이런 통계 대푯값을 구한 후, 이를 모집단의 통계 값, 즉 모수라고 말하고 이를 근거로 모집단의 형태를 추정한다.
많은 데이터 분석은 이와 같이 모집단의 형태를 추정하는 식으로 이루어진다. 따라서 데이터 분석에서 ‘모집단’ 자체를 다룰 수 있는 경우는 거의 없다. 전체 데이터를 다 사용한다고 해도, 그 데이터가 서비스를 적게 사용한 사람들, 늦게 가입한 사람들, 중간에 탈퇴한 사람들을 모두 대표할 수는 없다. 사람들은 이런 사실을 종종 잊어버린다. 단순히 숫자를 보고, 또는 ‘빅데이터’를 손에 쥐고, 이제 모든 것을 다 가졌다는 착각을 하고야 만다. 그리고 다양한 통계 용어를 접하면서 자신이 데이터와 통계에 익숙해졌다는 망상에 빠진다. 그 결과, 여러 단어의 의미와 개념을 혼동한 채 이상한 방향의 결론을 쏟아놓기에 이르고 만다.
물론 데이터 분석에서 개념은 모를 수 있다. 하지만 무엇보다도 논리와 정의가 중요한 데이터 분석에서, 정의를 잘 모르는 단어를 대충 자신의 생각대로 사용하는 데에서 수많은 일그러진 분석 결과가 만들어지고, 데이터 분석가의 일그러진 표정이 만들어지곤 한다. 자신이 아는 것으로 모든 것을 해석하는 데는 한계가 있다. 자신이 익숙하지 않은 지식과 용어에 대한 정의를 객관적인 시각으로 이해하는 것, 자신의 시각에 비추어 오용하거나 남용하지 않는 것, 그리고 공감대를 형성하는 것. 이런 것이 데이터를 이해하기 전에 서로 잘 맞춰가야 하는 무엇보다 중요한 전제다.
<원문>
[데이터 분석가의 숫자유감] 3화 모수와 표본 : 모수가 이렇게 충분한데 그냥 쓰면 안 될까?
©️요즘IT의 모든 콘텐츠는 저작권법의 보호를 받는 바, 무단 전재와 복사, 배포 등을 금합니다.