개발
Etag를 이용하여 더 나은 Restful API 만들기

7분
2022.11.04.23.2K

요즘 웹 개발자라면 Restful API를 한 번쯤 다뤄본 경험이 있을 것입니다. HTTP 사양의 주요 저자 이자 REST를 세상에 처음 알린 ‘로이 필딩(Roy Fielding)이 주장하는 REST 아키텍처 구성요소는 잘 몰라도 HTTP를 이용해 원하는 데이터를 URI로 호출하여 JSON 등의 문서 포맷으로 데이터를 주고받는다는 내용은 알고 있을 정도니까요.
이처럼 널리 알려져 있다 보니 많은 서비스에서 Restful API를 활용하고 있습니다. 그래서 오늘은 Rest API와 캐시에 관해 간략히 필요성을 살펴보고, HTTP의 Etag를 이용하여 캐시를 구현하는 방안에 대해서 살펴보고자 합니다.
Rest가 나오기 이전에는 Soap이나 XML-RPC와 같은 복잡한 API를 통해 컴퓨터 네트워크상에서 데이터를 교환했습니다. 하지만 사용하기 쉽고 편한 Restful API가 등장하자 기업과 개발자들은 빠르게 여러 기술에 활용하기 시작했습니다.


Restful API는 데이터의 생성, 삭제, 수정에도 사용할 수 있지만, 특히 개발자가 원하는 데이터를 조회할 때도 많이 활용합니다. 특히 빠른 시간 주기로 데이터가 추가되거나 갱신되는 데이터를 구하고자 할 때 Restful API를 이용합니다. 가령 날씨나 국토정보 등 국가적으로 관리하는 데이터들은 행정안전부의 공공데이터포털에서 확인할 수 있는데, 해당 포털에서는 22년 10월 기준 약 5,100건의 Restful API를 제공하고 있습니다. 이 데이터는 기업 혹은 개인이 앱이나 서비스를 만드는 데 활용되고 있습니다.
API를 사용해서 데이터를 주고받을 때 고려해야 하는 여러 항목이 있습니다. 이중 API를 통해 조회하는 데이터의 크기는 비용의 문제 때문에 자주 거론됩니다. 데이터가 크면 클수록 데이터를 주고받는 네트워크 구간에서의 비용이 많이 들기 때문입니다. 예를 들어 10Mb 크기의 데이터를 주고받는다면 보내는 곳에서도 메모리를 최소한 10Mb를 써야 하며, 받는 구간에서도 10Mb 메모리를 사용해야 합니다.
그런데 우리가 사용하는 인터넷은 무전기처럼 직접 상대방과 연결된 Peer to Peer 통신이 아닙니다. 네트워크라고 불리는 시스템이 구축되어 있고 우리는 그 위에서 인터넷을 이용하는 것입니다. 네트워크 시스템에는 라우터나 스위치 등의 수많은 컴퓨터가 있습니다. 해당 시스템의 구간마다 10Mb를 사용하게 되며, 이는 엄청난 비용으로 돌아오게 됩니다.
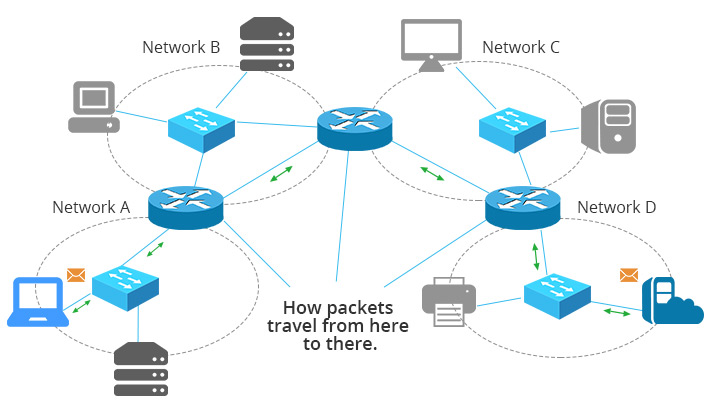
그래서 많은 개발자가 ‘캐시’라는 시스템 설계를 도입하여 비용은 줄이고 사용자가 더 빠른 결과를 받아 볼 수 있도록 노력합니다. 여기서 캐시는 데이터를 미리 복사해 놓는 일종의 임시저장소를 말합니다. 캐시의 접근 시간에 비해 원래 데이터에 접근하는 시간이 오래 걸리거나 값을 다시 계산하는 시간을 절약하고 싶은 경우에 사용합니다. 캐시에 데이터를 미리 복사해 놓으면 계산이나 접근 시간 없이 더 빠른 속도로 데이터에 접근할 수 있기 때문입니다. 특히 요청한 데이터가 이전과 동일하면 클라이언트는 캐시에 있는 데이터를 재활용할 수 있어 더 빠르고 비용을 줄일 수 있습니다.
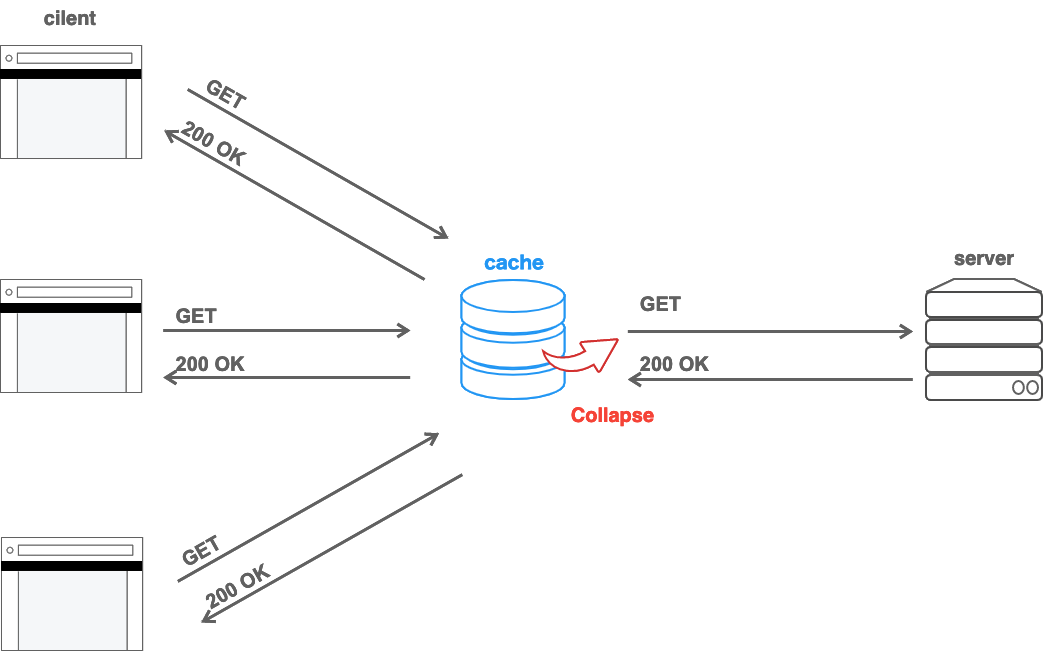
이런 캐시는 각 클라이언트가 내부적으로 캐시를 구축하고 있는 경우가 있고, 별도의 캐시 서버를 운영하는 형태도 있습니다. 따라서 Restful API를 지원하는 시스템 개발자는 다양한 수준에서 캐시 구현 전략을 고민하게 됩니다.
Etag는 클라이언트(ex. 모바일 디바이스, 웹 브라우저 등)가 이전에 요청했던 데이터와 최신 데이터의 변경사항 유무를 검증하는 데 사용하는 HTTP 응답 헤더입니다. 클라이언트에서 최신 데이터 자료를 요청할 때(HTTP Get 요청) 응답 헤더로 Etag 값이 반환됩니다. Etag의 값은 일반적으로 MD5 등의 Hash 함수를 이용하여 생성된 값인 Message Digest를 사용합니다.
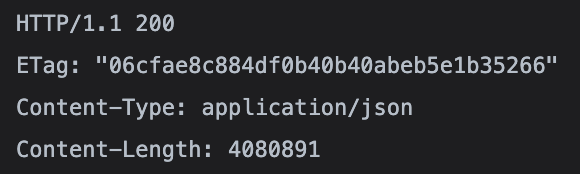
반환된 Etag의 값을 HTTP 요청 헤더 If-None-Match에 담아서 요청 데이터가 최신인지 아닌지를 검증합니다. 만약 데이터의 변경이 없어서 요청한 Etag의 값과 현재 데이터의 Etag의 값이 동일하면 HTTP 응답코드로 304 Not Modified를 반환 받습니다.
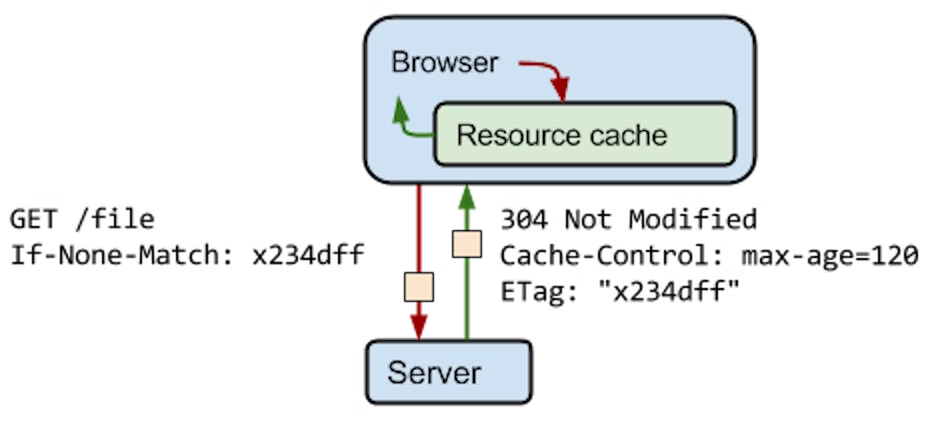
정리하면, 클라이언트에서 데이터를 받기 위해 네트워크에 데이터를 요청했을 때 Etag를 이용해 최신 정보를 확인하고, 이때 데이터의 변경이 없으면 추가 데이터를 주고받지 않고 클라이언트에 저장된 자료인 캐시를 활용합니다. 결국 API 클라이언트는 캐시를 활용해 더 빠르고 저렴하게 서비스를 운영할 수 있습니다.

스프링프레임워크는 국내 외에서 가장 활발하게 사용되는 자바 기반의 웹 애플리케이션 프레임워크입니다. 특히 스프링 부트(Spring Boot)는 스프링프레임워크의 경량화된 버전으로 2021년에 전 세계에서 가장 많이 사용하는 자바 웹 프레임워크입니다.
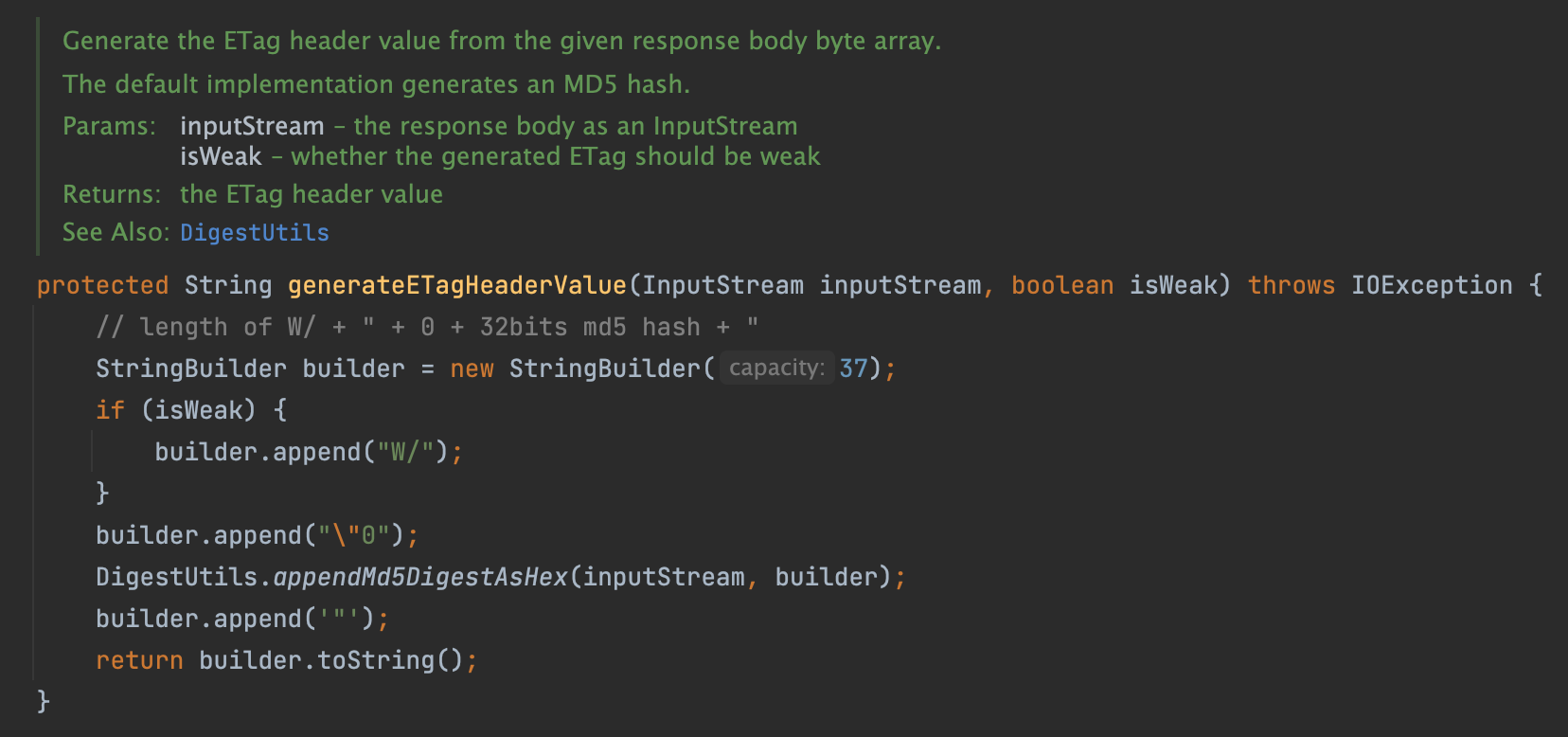
스프링프레임워크는 Web.Filter 패키지의 ShallowEtagHeaderFilter 클래스에서 Etag의 표준 기능을 구현하고 있습니다. 이 기능은 Servlet 3.1 이상에서 지원합니다.

ShallowEtagHeaderFilte는 Etag의 생성 시 MD5 해시 함수를 사용하고 있습니다.
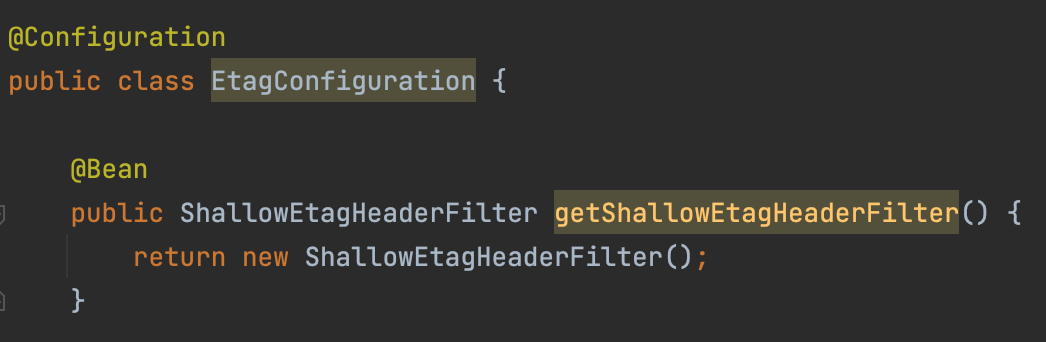
ShallowEtagHeaderFilte의 적용은 아래와 같이 스프링이 관리하도록 빈을 등록시켜주면 됩니다.
특정 URI 패턴만 적용하려면 아래와 같이 FilterRegistrationBean과 함께 사용하면 됩니다.
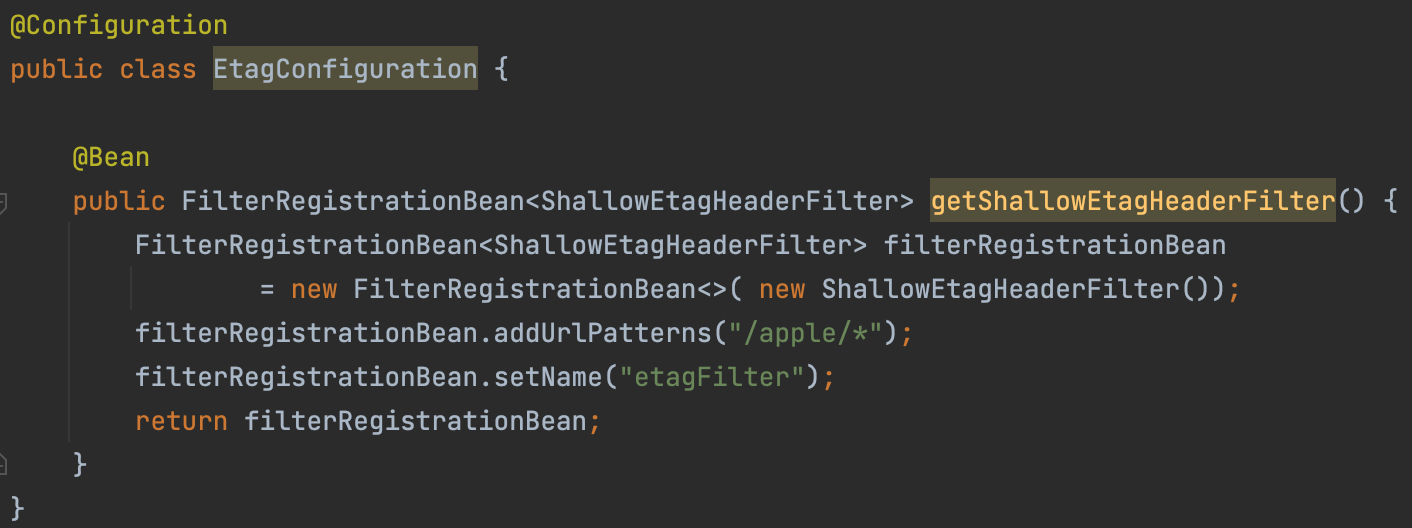
다만 필터의 로직 처리는 해당 요청의 시작과 응답의 마지막에 수행되는 점을 주의해야 합니다. 즉 항상 모든 데이터에 대한 Hash 함수처리를 진행합니다. 따라서 API로 제공하는 데이터 크기가 클수록 Hash 함수로 값을 계산하는 시간이 증가하여 HTTP 응답시간이 길어집니다.
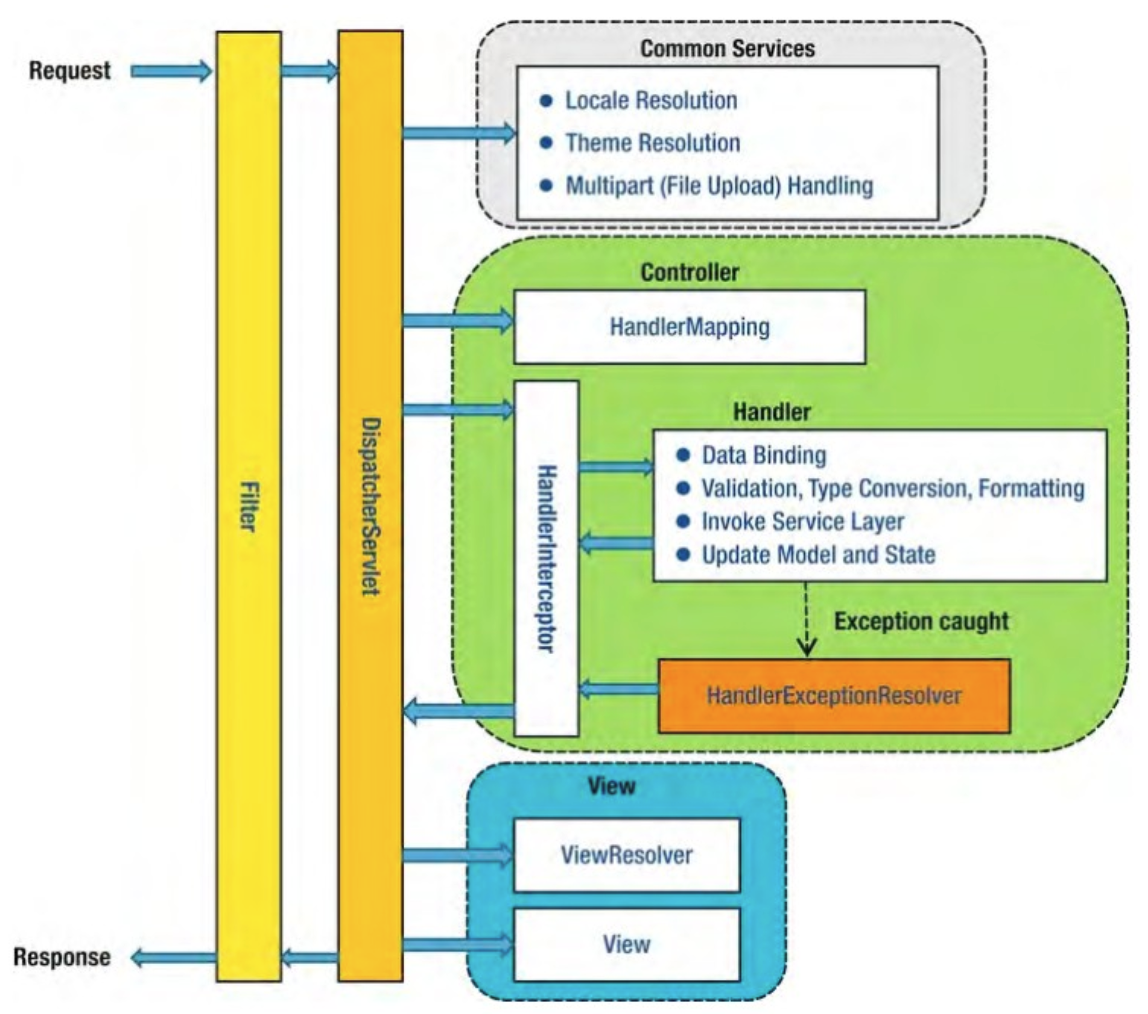
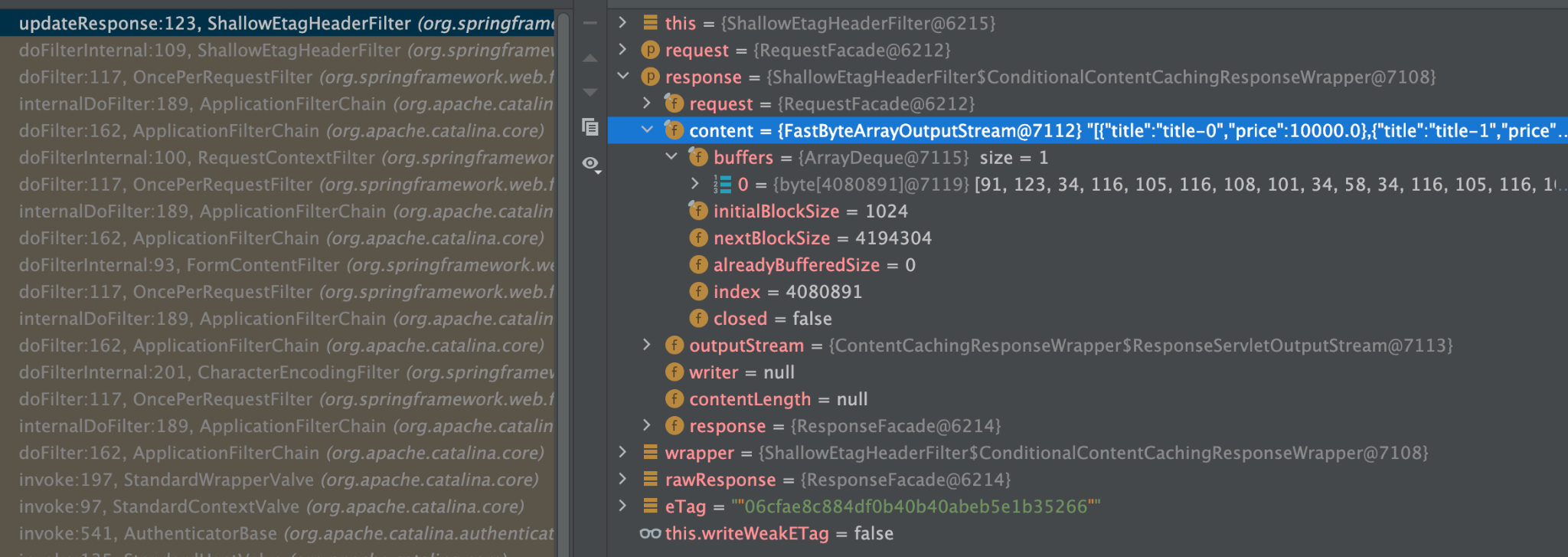
여기서 우리는 Etag를 사용해서 캐시를 구축하는 것이 아닙니다. Etag를 이용해서 API 클라이언트가 캐시를 운영할 수 있도록 설계하는 것이 목적입니다. 또한 불필요하게 동일한 데이터를 주고받는 행위를 줄여서 전반적인 네트워크 트래픽 비용을 줄이는 데 의의가 있습니다.
간단한 API를 구축하고 Etag를 사용했을때 절약되는 데이터를 확인해보겠습니다. 앞서 설명한 스트링 부트를 이용해서 약 20Mb 정도의 데이터를 반환하는 임의의 API를 구축하고 테스트를 진행해보았습니다.
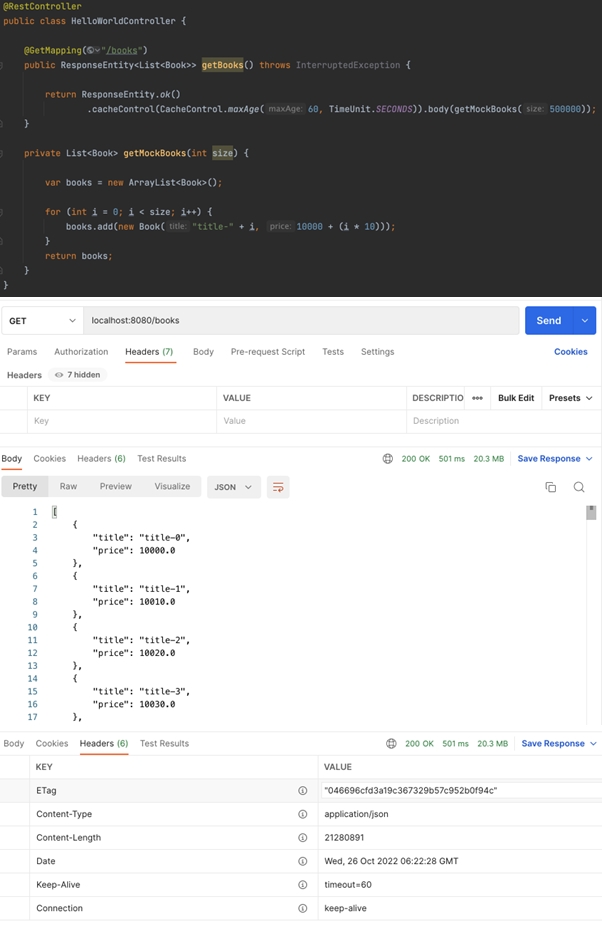
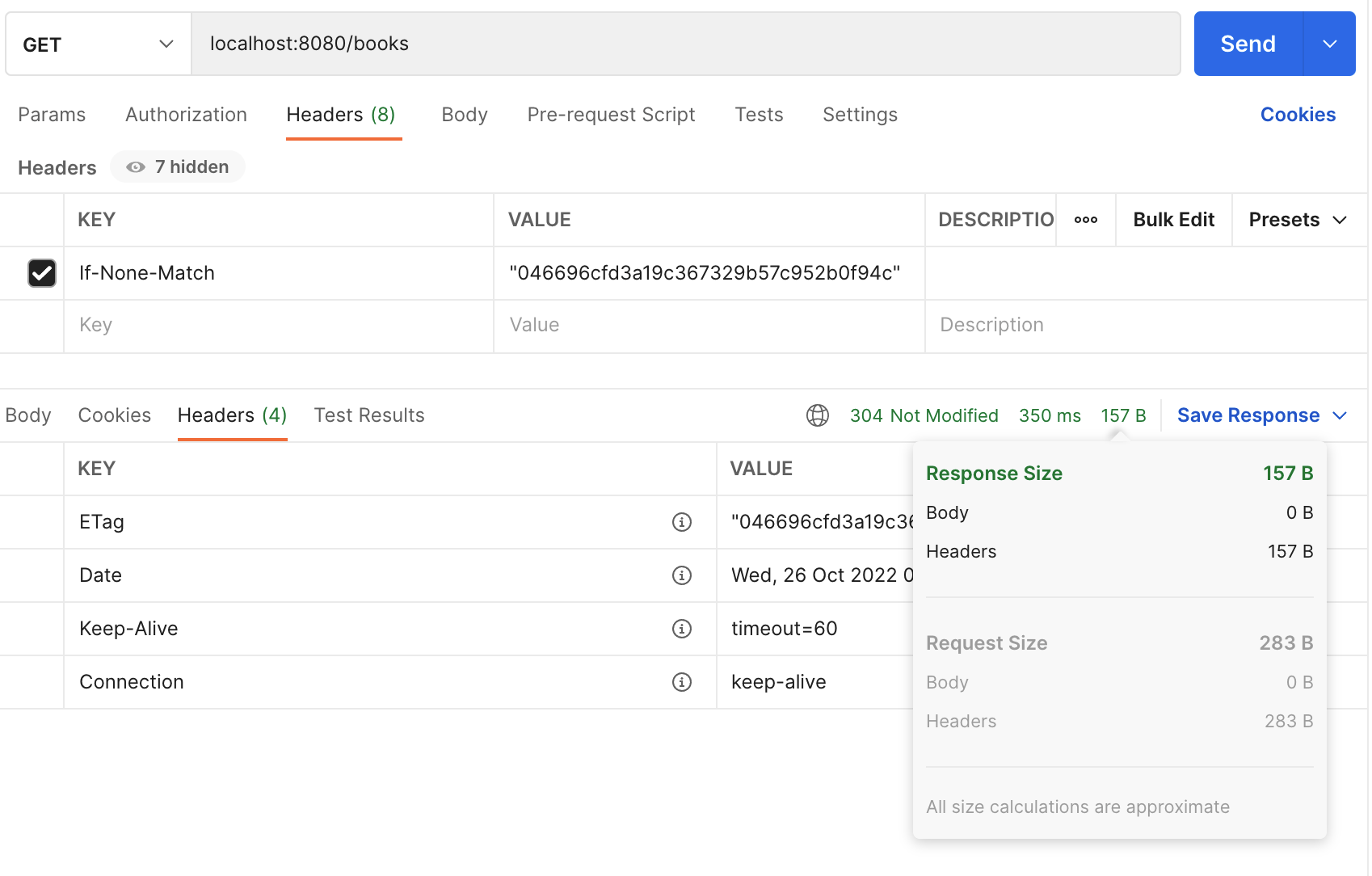
최초 응답 값으로 넘어온 Etag 046696cfd3a19c367329b57c952b0f94c를 If-None-Match로 헤더에 넣어서 재응답하면 아래와 같이 304 NotModified와 함께 Body가 비워져서 응답합니다. 응답 헤더에는 요청했던 Etag와 동일한 값의 Etag가 포함되어 있습니다. 동일한 데이터 20Mb를 한 번 더 주고받을 필요 없이 157 Byte로 유효성 검증을 완료했습니다. 약 20,971,520 Byte(20Mb)의 네트워크 비용을 157 Byte로 줄였으니 약 14,000배 정도의 네트워크 비용을 절감했습니다.
API를 사용하는 클라이언트의 형태에 따라서 캐시의 구현 방법도 다양합니다. 브라우저의 경우, 이전 요청에서 Etag를 반환하면 다음번 요청부터는 헤더에 If-None-Match에 Etag 값을 담아서 요청합니다. 응답 값으로 304 Status Code를 받으면 이전에 사용하던 데이터를 재사용합니다.
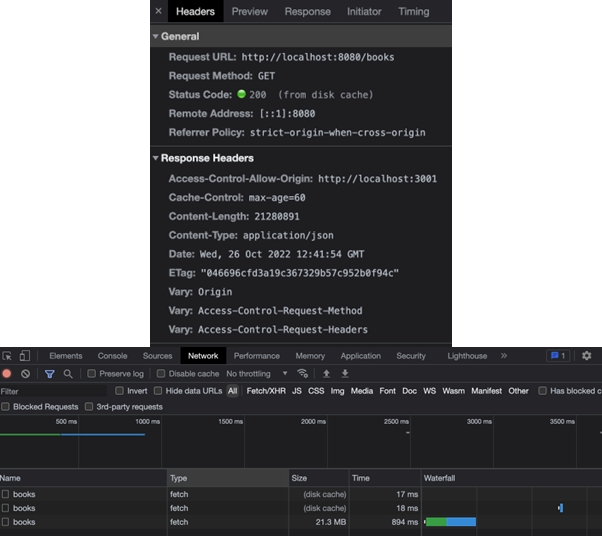
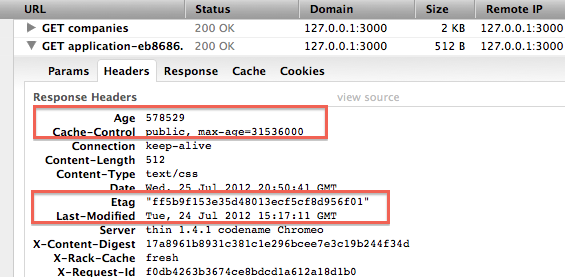
가령 테스트 페이지를 구성하고 프론트엔드에서 API를 ‘자바스크립트(JavaScript)’의 Fetch로 호출해 보겠습니다. 크롬은 아래 이미지와 같이 disk cache로 재사용하는 걸 알 수 있습니다. Status Code에 from disk cache가 표기되고, Network의 Size에도 disk cache로 표기되고 있습니다.
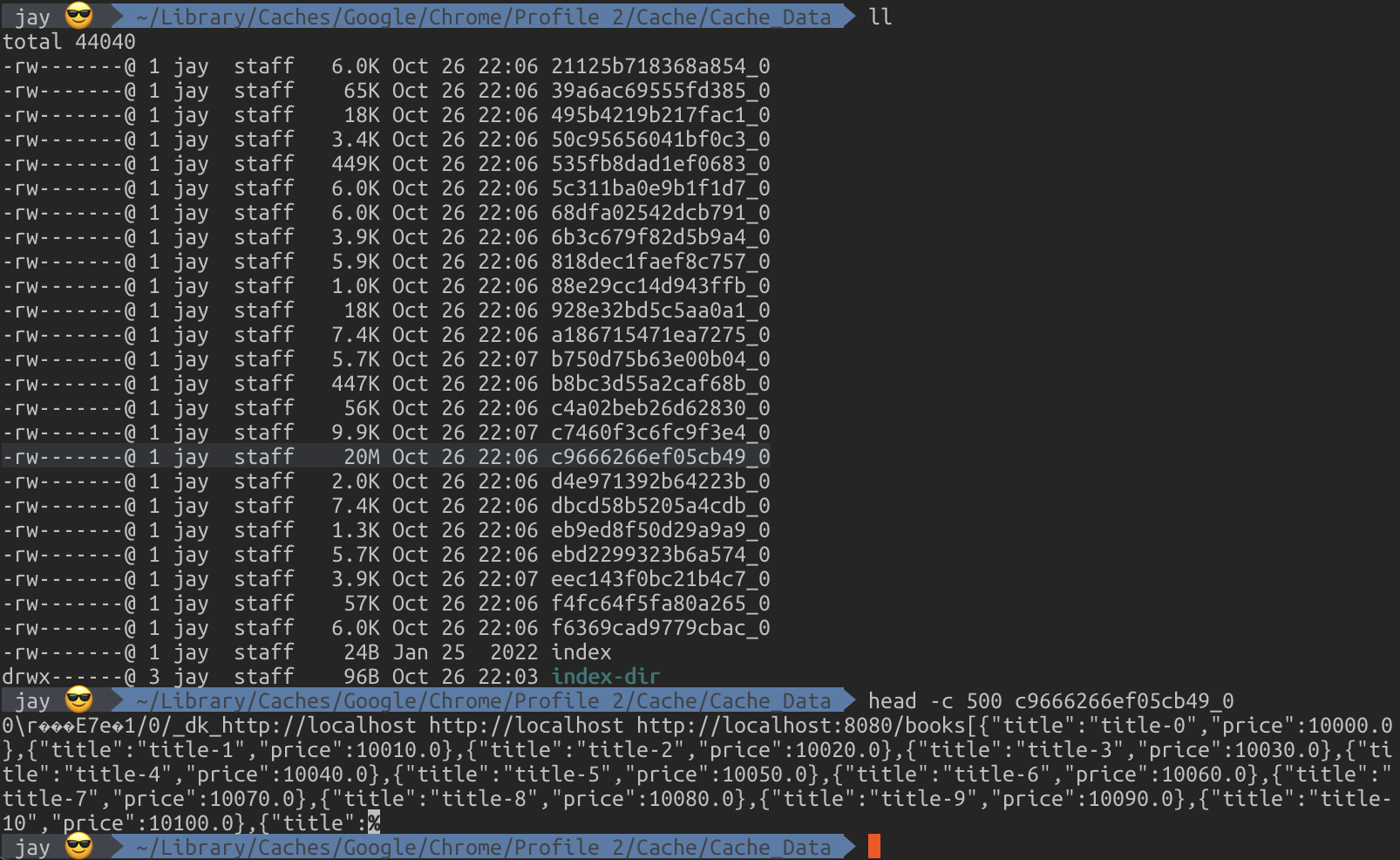
실제로 Mac OS를 기준으로 사전에 크롬이 설정한 캐시 데이터 위치로 이동하면 캐시의 index 파일과 함께 테스트에 이용했던 캐시 데이터를 확인할 수 있습니다.
브라우저가 아닌 Server to Server 통신에서는 캐시의 구현을 개발자가 자유롭게 선택하여 구축할 수 있습니다. 사용하고자 하는 서버의 상황에 맞춰서 적절한 페이지 교체 알고리즘과 데이터의 저장위치를 고려하여 구성하면 됩니다.

만약 분산 환경에서의 사용을 고려 중이라면 인메모리 DB인 Redis(이하 레디스)를 활용하는 것도 좋은 방법입니다. 레디스를 캐시로 이용했을 때 약간의 시간 지연이 허용되는 데이터 조회는 레디스를 최우선으로 탐색하고, 반면 실시간성이 중요한 데이터는 API를 통해 받도록 설계할 수 있습니다. 또한 레디스를 이용하면 메모리 정책을 설정하여 LRU 등의 알고리즘을 선택 적용할 수 있어 편리합니다.
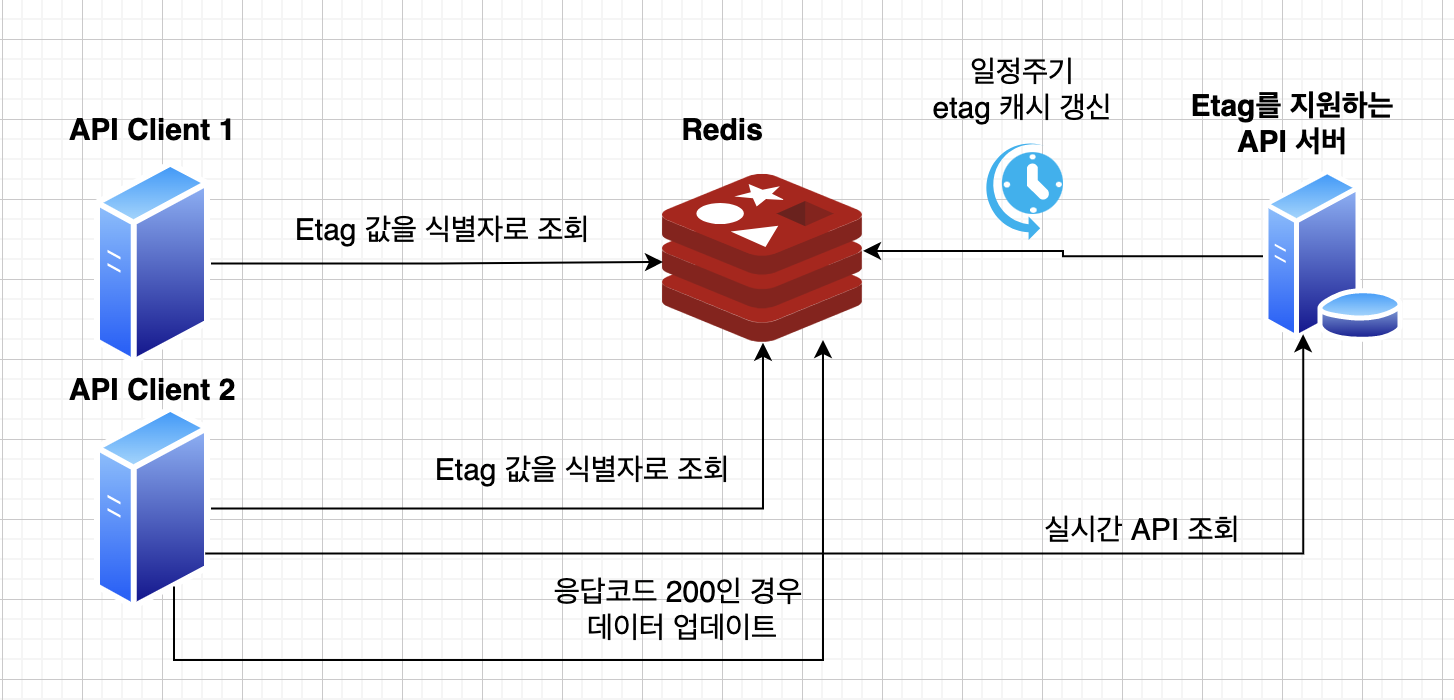
하지만 캐시를 잘 관리하려면 기본적으로 스케줄러 등의 방법으로 데이터를 최신화할 수 있도록 하는 노력이 필요합니다. 가장 단순한 방법으로는 API 서버 내 혹은 별도의 스케줄링 프로세스를 구축해 일정 주기로 레디스 캐시 데이터를 업데이트하는 방법이 있습니다.
더 나아가 Etag 외에 HTTP의 Last-Modified와 Cache-Control의 Max-Age를 추가로 설정하면 API를 통해 항상 최신 데이터를 유지할 수 있습니다. 만약 현재 시각이 Last-Modified + max age의 시간 이후라면 API Client가 직접 API를 조회 후 레디스값을 업데이트해주는 전략을 꾀할 수도 있습니다.
지금까지 HTTP의 Etag를 이용하여 네트워크 자원을 절약하고 캐시를 지원하는 방법에 대해 알아보았습니다.
이런 Etag를 사용하는 API는 REST 아키텍처의 Cacheable(캐시가능성) 요건을 만족합니다. 또한 레디스를 이용한 캐시 DB나 캐시 데이터 갱신용 스케줄러 프로세스 등을 구현하는 설계 방법을 통해 Layered System(계층화 시스템)이라는 요건이 충족하도록 돕습니다.

Etag를 추가하여 더욱 Restful 한 API, 더 나은 Restful API를 만들 수 있다는 사실이 여러 개발자에게 조금이라도 도움이 되었기를 바랍니다. 감사합니다.
©️요즘IT의 모든 콘텐츠는 저작권법의 보호를 받는 바, 무단 전재와 복사, 배포 등을 금합니다.