개발
GraphQL을 이용한 OLAP Star Schema의 설계

6분
2022.09.14.4.4K

비즈니스는 ‘애자일(Agile)한 방식으로 점차 빠른 구현과 검증을 요구하는 형태로 변화하고 있다. 이에 따라 ‘애플리케이션(Application)’도 빠른 대응을 위한 유연한 구조를 원하고 있고, 데이터를 관리하는 인터페이스도 유연한 구조를 원하고 있다.
데이터웨어하우스(Datawarehouse, DW)는 의사 결정에 필요한 정보를 사용자에게 제공하기 위한 빅데이터 시스템이다. 현대 기업에서는 다양한 DBMS를 이용하여 구축한 데이터웨어하우스를 활용해 기업의 의사결정 지원을 다차원의 데이터 분석과 복잡한 질의를 수행하고 있다. 이를 온라인분석처리(Online Analytical Processing, OLAP)라고 하며 내부적으로는 Star Schema등의 모델을 이용하여 의사결정데이터를 활용한다.
스타스키마는 DW에서 OLAP을 구축할 때 사용되는 데이터모델로, 분석을 위한 다차원 데이터를 표현하기 위해 Fact(사실) 테이블과 Dimension(차원) 테이블로 구축된다.
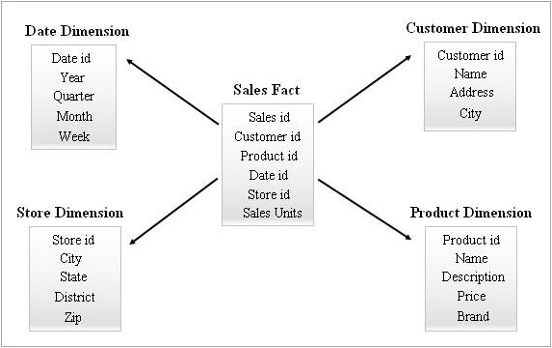
스타 스키마는 다양한 DBMS를 이용하여 구현이 가능하다. 관계형 데이터베이스를 통해서도 구현할 수 있지만, 컬럼 지향형 데이터베이스나 NoSQL등을 통해서도 구축할 수 있다. 이번 글에서는 OLAP-Stars schema를 GraphQL을 통해서 구현하는 방법에 관해 다룰 계획이다. 기업의 의사결정을 돕는 데이터를 제공하며, 유연한 Application을 구축하는 방안을 생각해보고자 한다.
DW와 OLAP에 관한 물리적 설계 방식과 적용에 관한 기존 선행연구는 중앙집중식 환경의 관계형 데이터베이스를 중심으로 이뤄졌다. 그러나 NoSQL에 OLAP 적용을 위한 디자인과 성능에 관한 연구는 비교적 많이 이뤄지지 않았다.
최근 연구는 Column Oriented DBMS인 NoSQL Hbase를 기반으로 OLAP 적용을 위한 디자인과 성능을 확인한 연구가 진행된 바 있다. 해당 연구에서는 NoSQL의 Column Oriented DB 쿼리수행 성능과 효율성 확인 및 설계방법에 대한 검증을 진행했다. 예전에 진행했던 연구(CNSSB, SameCF)를 기반으로 FactDate설계를 제안하였으며, CNSSB, SameCF, FactDate 방식의 물리적 DW 설계를 쿼리 성능과 배포 관점에서 비교 분석했다.
실험결과 하나의 NoSQL - column-families에 모든 데이터를 저장하는 것이 고차원 쿼리에서의 성능이 좋은 것으로 나타났다. 각 설계의 특장점으로는 SameCF가 배포에 적합했으며, Date 차원에서의 1,2차원 쿼리에는 FactDate 디자인이 가장 성능이 좋은 것으로 나타났다.
REST의 경우 리소스의 식별자를 구성하는 규칙에 의해서 항상 계층적인 구조를 가져야 하는 한계가 있다. 이는 OLAP에서의 빠른 Dimension구성하는데 제약사항이 된다.
이런 문제를 포함하여 2012년 ‘페이스북(Facebook)’은 REST 방식의 API의 여러 부분에서의 한계점을 개선하기 위해서 GraphQL을 개발하였다. GraphQL 쿼리는 해석과 이행을 위해서 서버로 문자열을 전송하며, Json 형태의 데이터를 클라이언트에 반환한다.
GraphQL은 쿼리의 형태가 쿼리에 대한 응답과 거의 유사하기에 서버에 대해 자세히 모르는 상태임에도 쿼리가 응답할 결과를 예측할 수 있다. GraphQL은 질의가 가능한 데이터를 설명하는 메타정보를 스키마와 타입으로 개략적으로는 정의한다. 쿼리 요청이 들어오면 해당 서비스의 스키마에 대해 유효성 검사를 진행 후 실행된다.
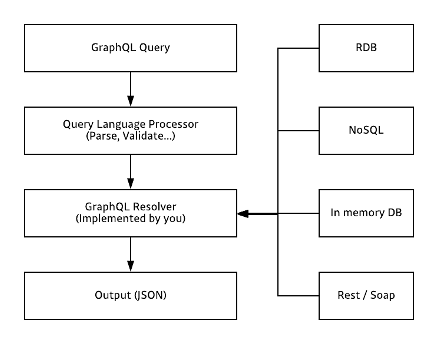
GraphQL은 REST와 대비하여 소프트웨어 개발자가 구현에 드는 시간 비용을 줄일 수 있는 것으로도 분석되었다. 아래 그림은 대학원생과 학부생을 대상으로 개발에 소요되는 시간을 분석한 결과이다.
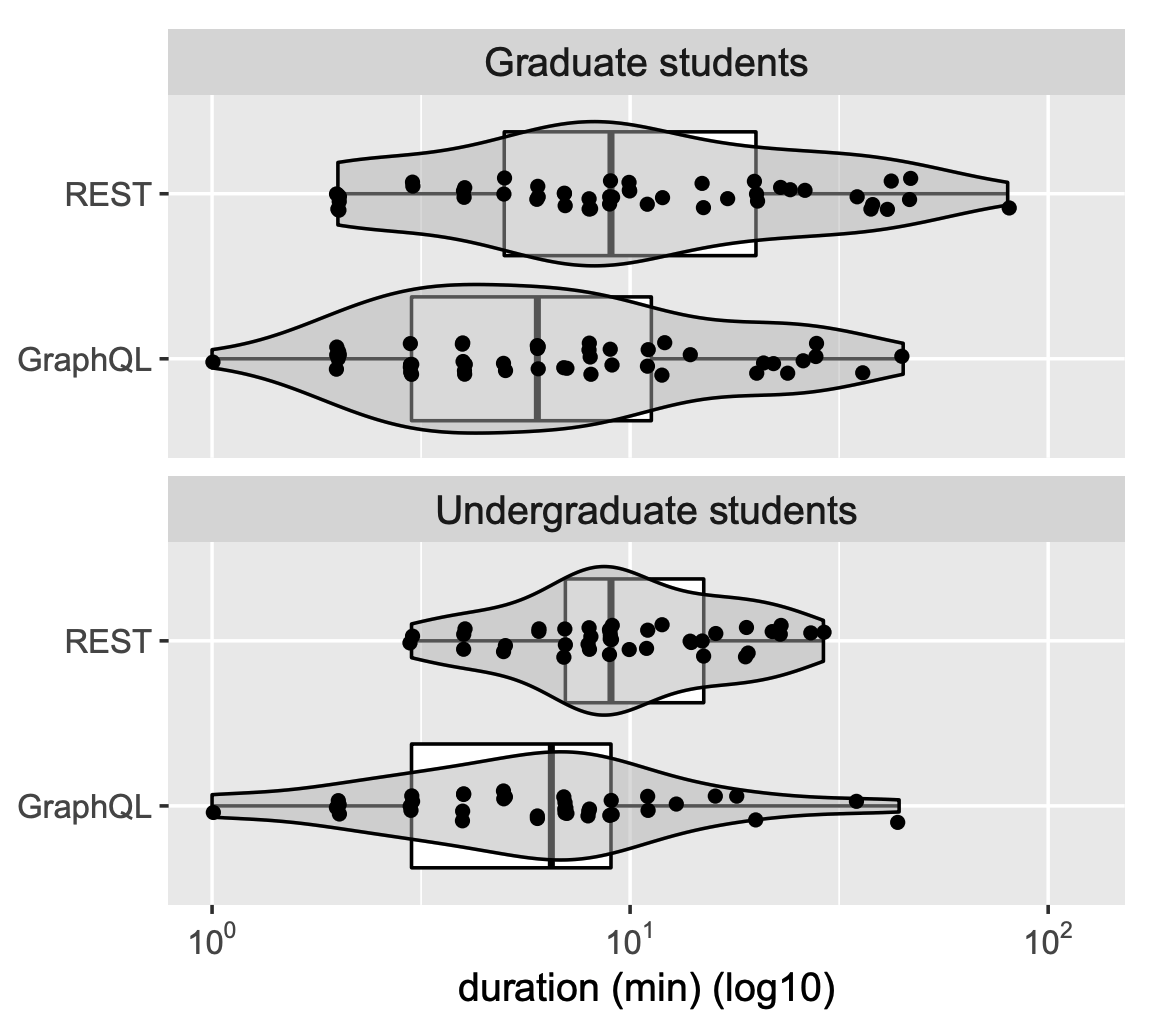
GraphQL은 HTTP를 이용하며 메서드는 POST를 이용한다. HTTP 클라이언트는 아래 그림과 같이 클라이언트가 희망하는 컬럼을 추가하여 진행하면 된다.

CLI를 이용한 Graph QL이 어렵다면 Apollo와 같은 GraphQL 서버를 이용하여 GUI 형태로 사용할 수 있다.
2013년 Facebook이 개발한 빅데이터 분석 도구로, 분산 SQL 쿼리 엔진이다. 34종의 이기종간 데이터베이스를 함께 사용할 수 있고, ANSI SQL을 이용해 RDB를 포함하여 No SQL 또한 동일한 문법을 사용할 수 있다. 이는 사용자의 학습비용을 낮추는 결과를 기대한다.
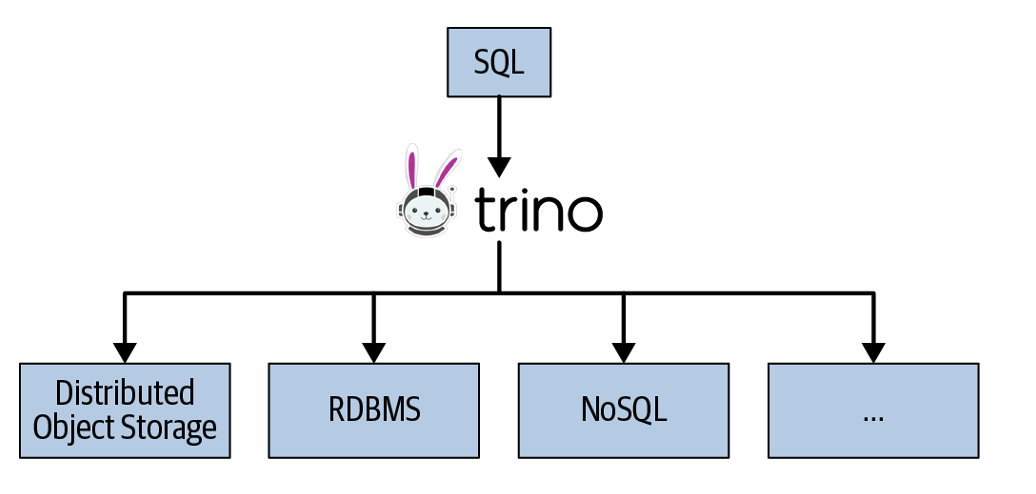
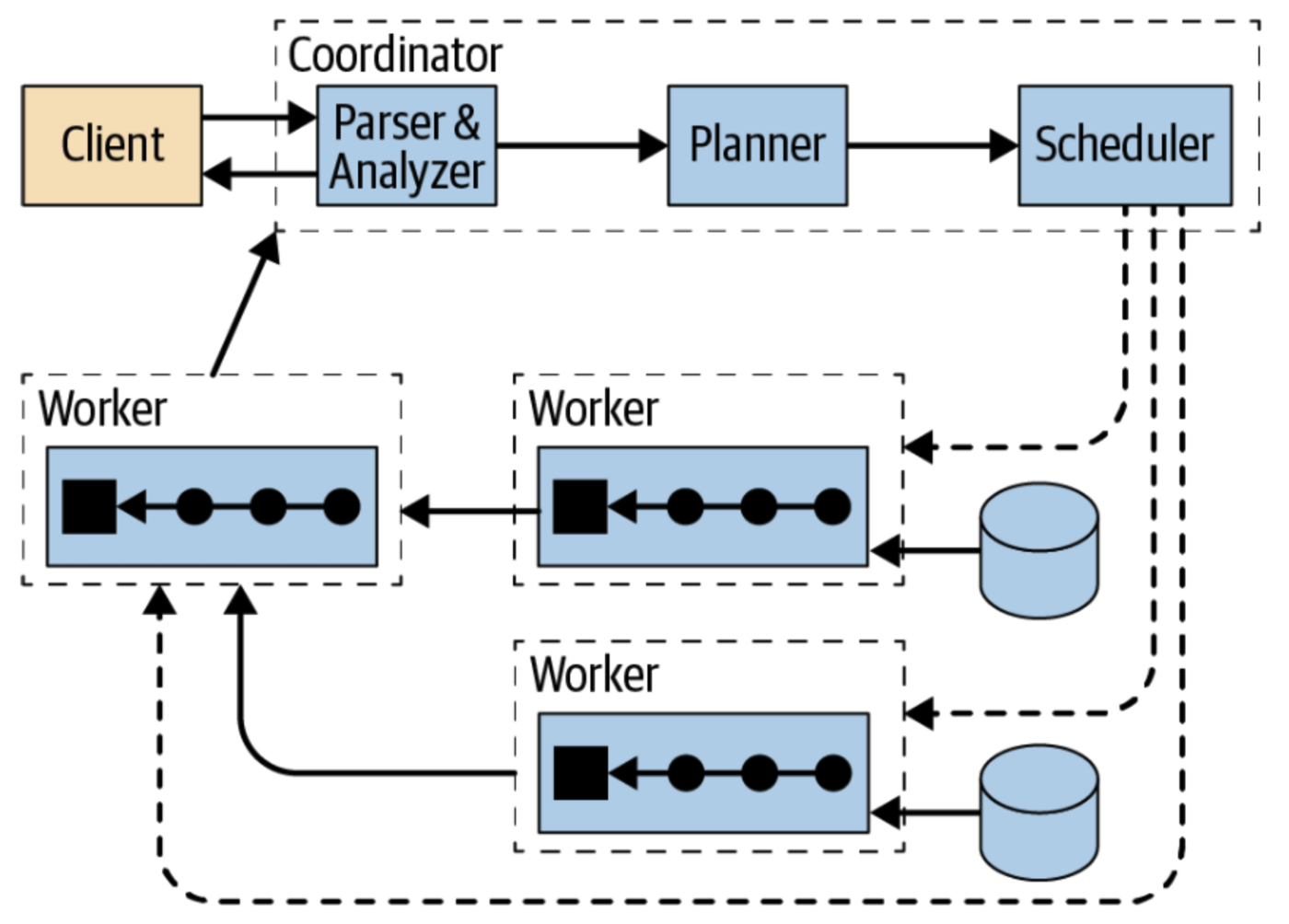
또한 질의 처리에 연산비용이 높은 경우에는 Trino의 클러스터링을 이용하여 병렬처리를 활용하여 높은 효율의 문제 해결을 기대할 수 있다.
GraphQL과 Trino를 이용하여 여러 BI 솔루션에 유연하게 대응하고 다양한 DBMS를 지원할 수 있도록 설계하였다. 또한 클라우드 환경에서의 사용을 위해 Docker Container를 기반으로 설계 및 구현을 진행하였다.
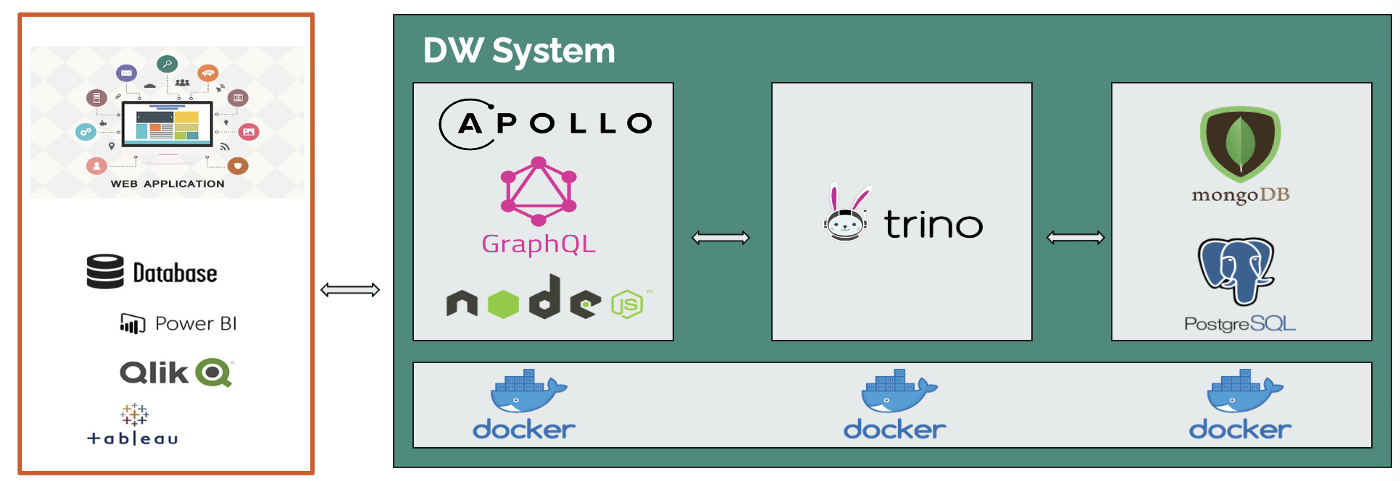
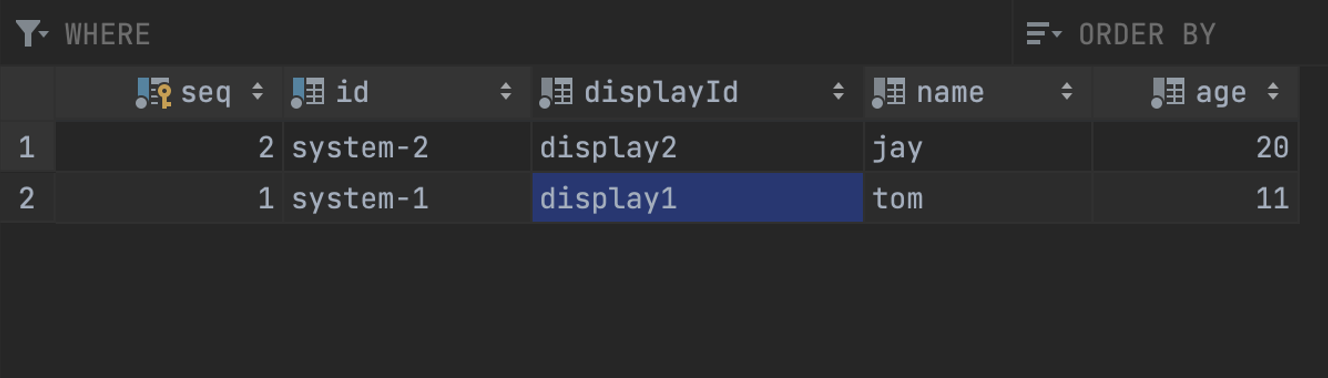
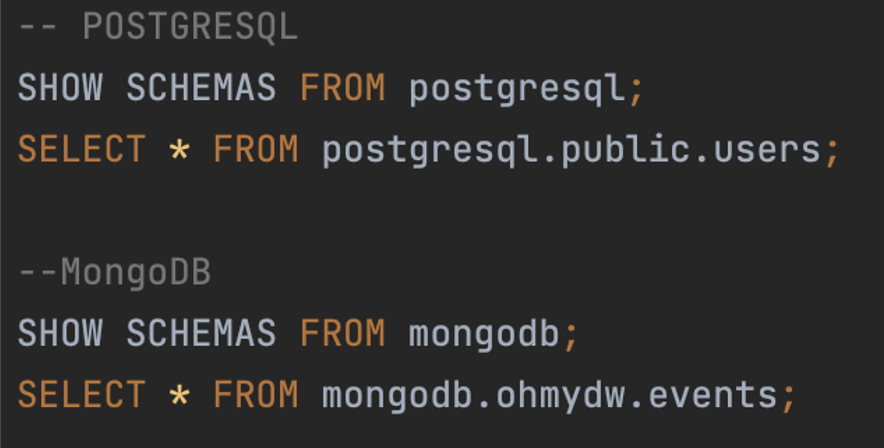
OLAP을 위한 데이터베이스로 RDB는 PostgreSQL를 사용하였으며, NoSQL는 MongoDB를 이용하였다. PostgreSQL에는 사용자의 기본정보를 담는 테이블 User를 설계하고 데이터로 Id, displayId, Name, Age를 컬럼으로 추가하였다.
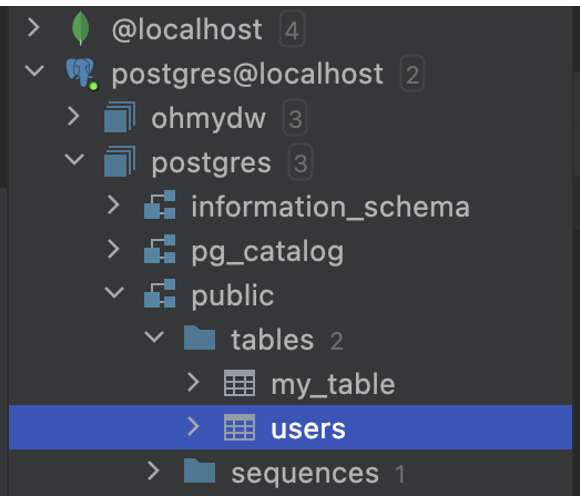
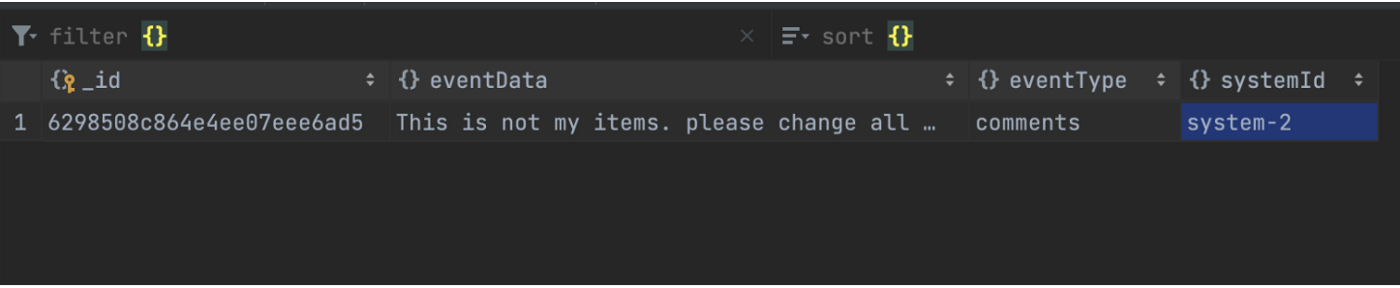
NoSQL의 경우에는 이벤트성 데이터가 수집되는 테이블을 구성하였으며, EventData, EventType, SystemId를 포함했다.
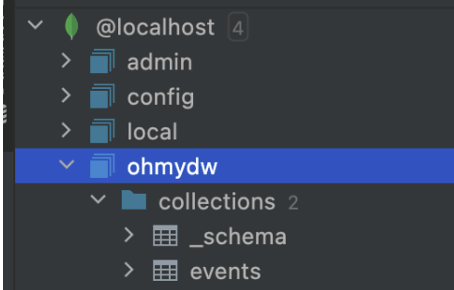
구성된 PostgresSQL과 Mongo DB는 Trino의 카탈로그로 등록한다. 등록된 카탈로그는 아래와 그림과 같이 Mongodb, PostgresSQL, System 등 총 세 개이다.
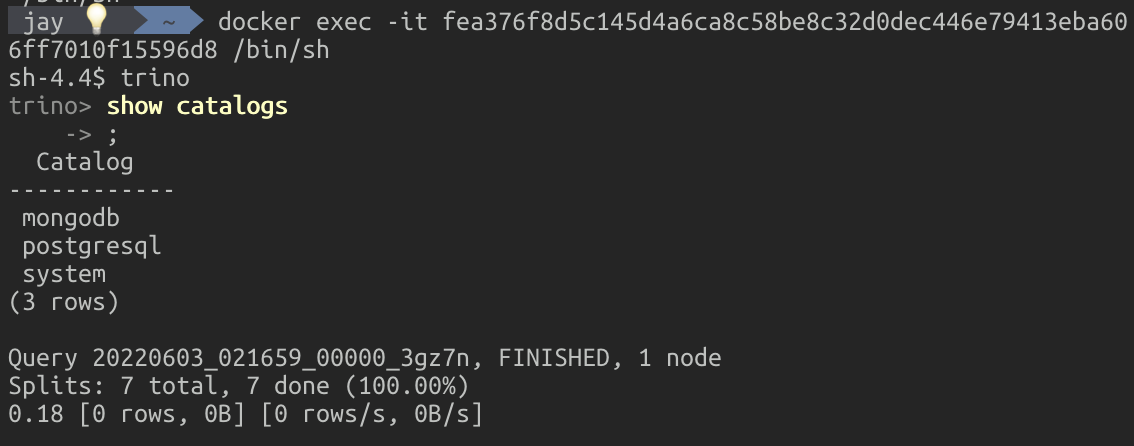
구성된 시스템에서는 각각의 데이터베이스별로 Trino의 카탈로그를 이용하여 Ansi SQL 문법을 활용하여 접근이 가능하다.
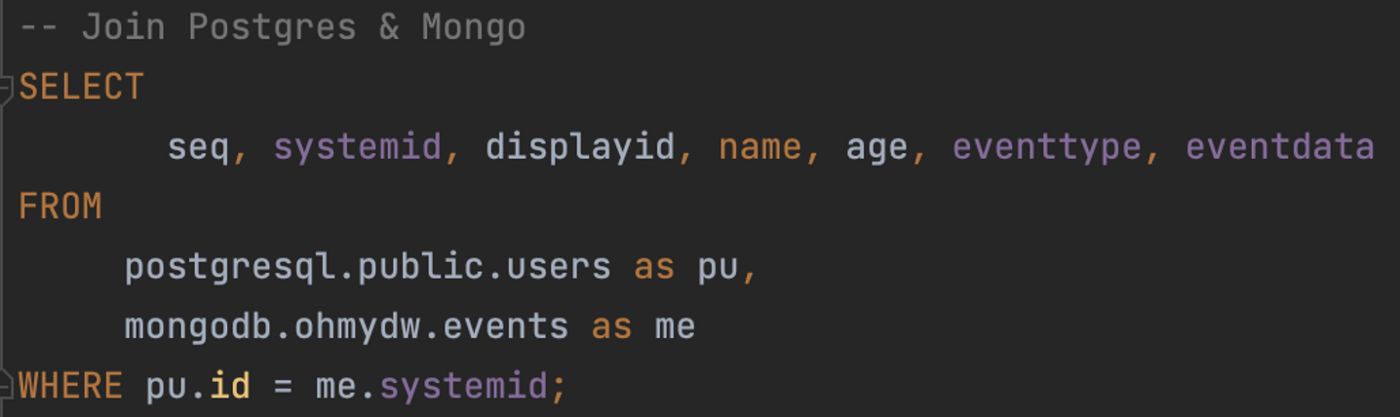
또한 이기종의 DBMS간 조인 쿼리도 지원한다.

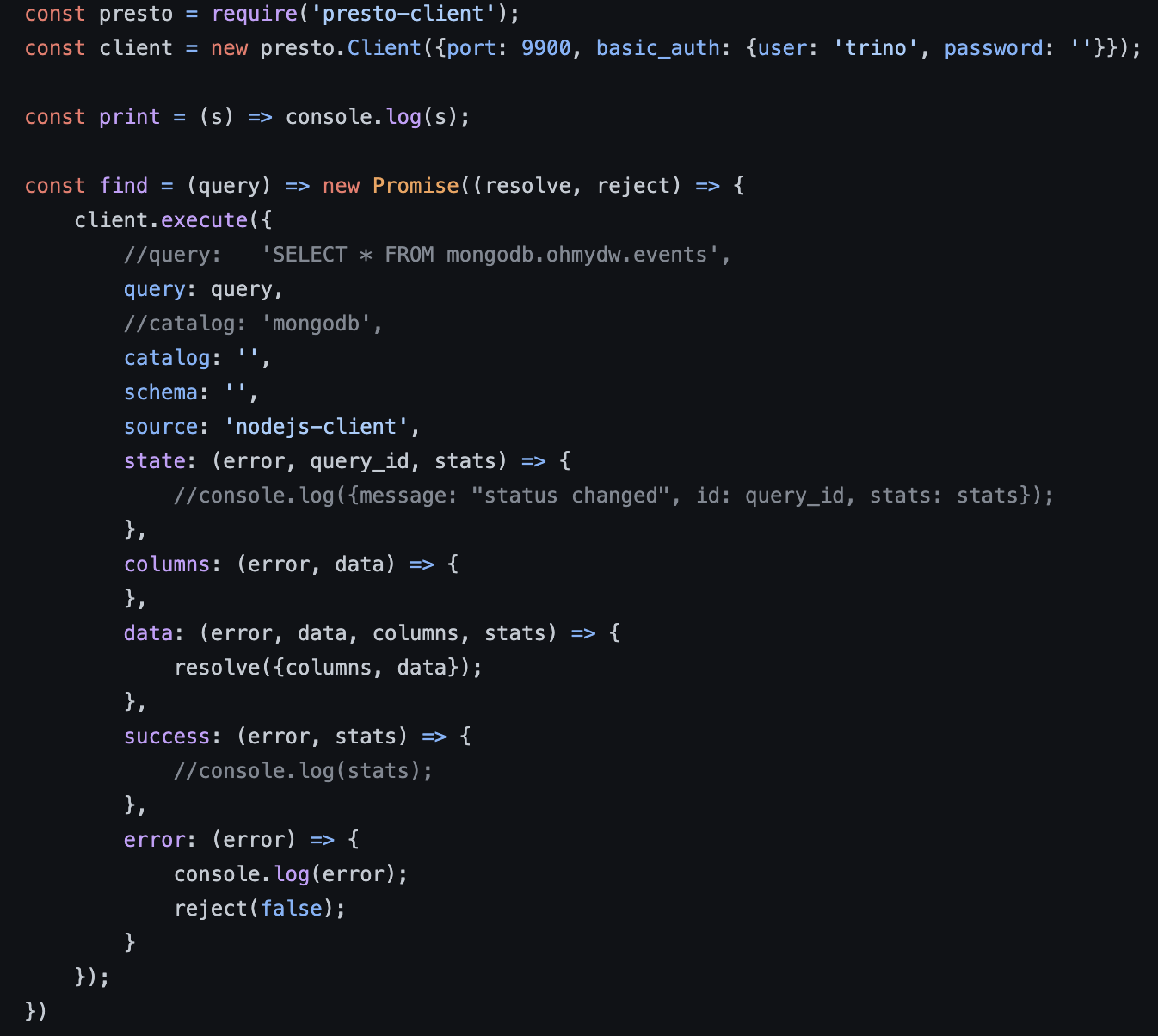
구현된 Trino의 카탈로그는 GraphQL을 이용해 연결한다. 이번에는 Node.js와 Javascript를 이용하여 작성하였다. GraphQL은 Apollo 오픈소스 프로젝트를 이용하였다. Trino와의 인터페이스 연동은 HTTP를 사용하며, ‘Presto-client’ 오픈소스를 이용해 별도의 Async 모듈을 아래 그림과 같이 추가 구현하였다.
GraphQL에서 OLAP의 Dimension을 사전에 정의할 필요가 있는데, 이번에는 UserEventWithBasicInfo라는 Dimension의 메타정보를 정의 후 아래와 같이 추가하였다.
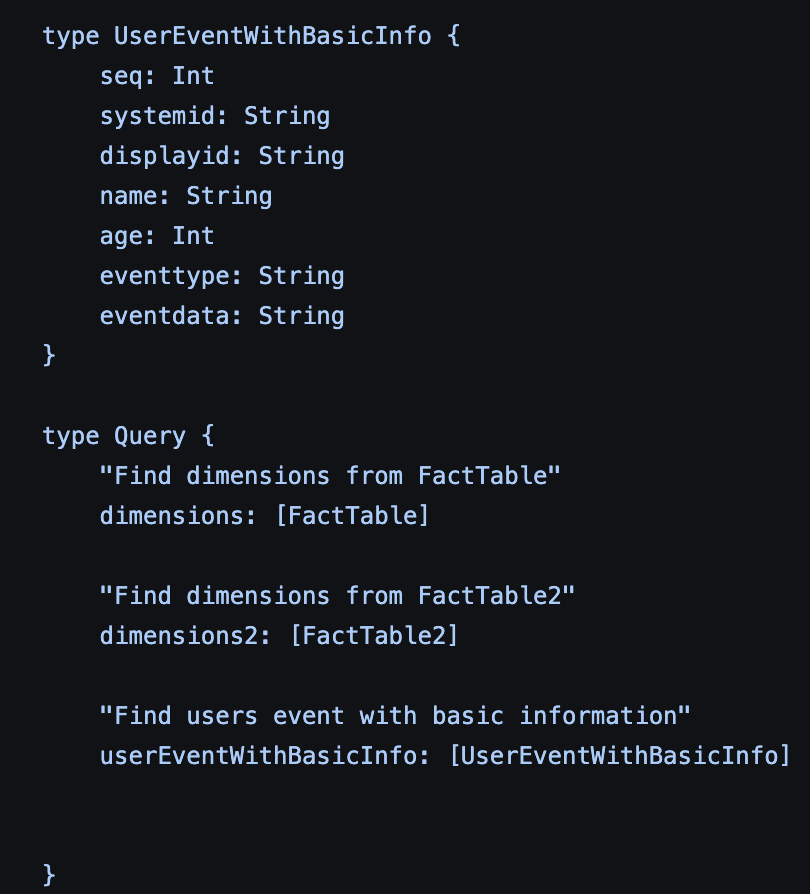
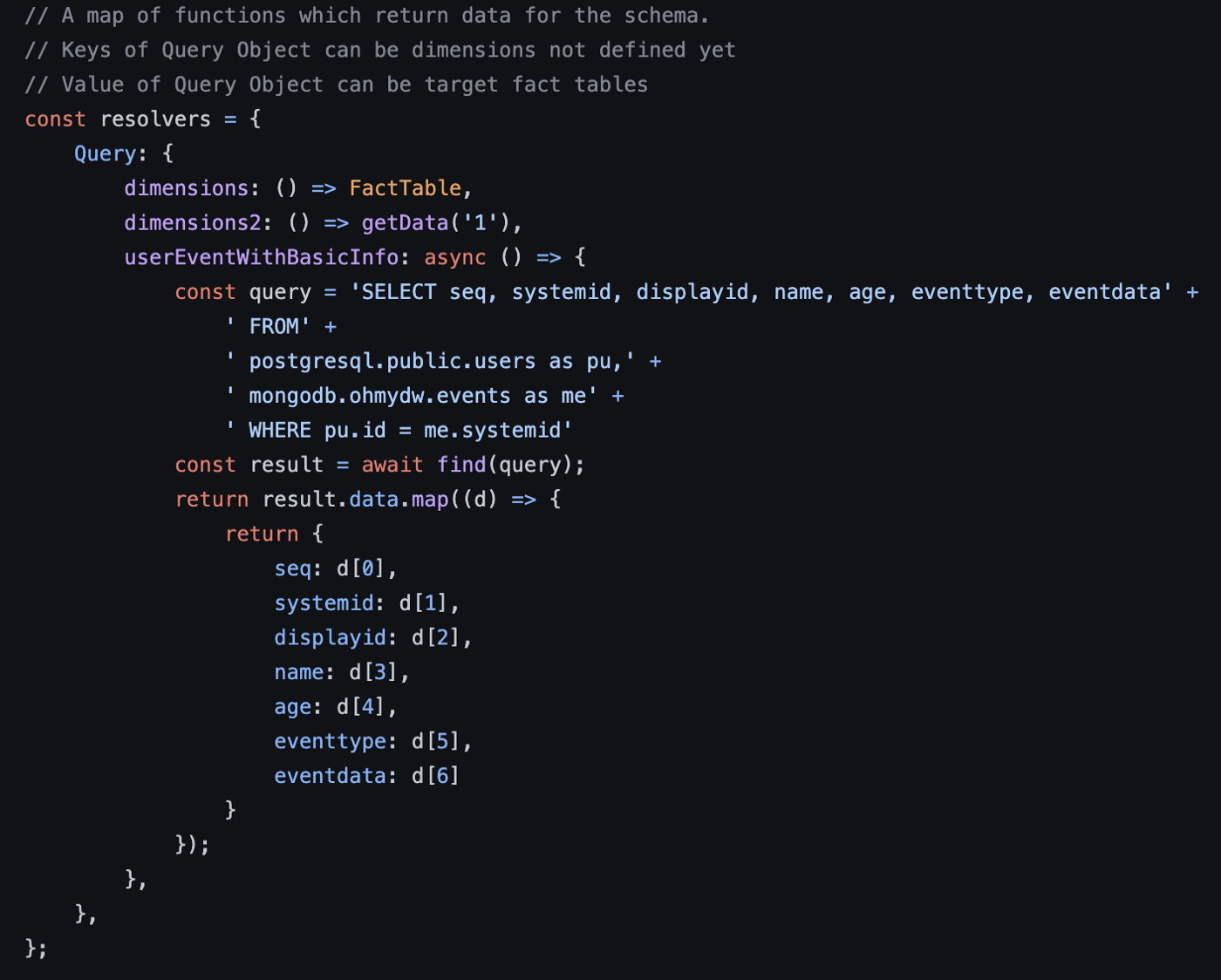
Trino Client와 Dimension 메타정보 등록이 완료된 후에는 GraphQL의 Resolver를 등록한다. 아래와 같이 Object로 선언하면 된다.
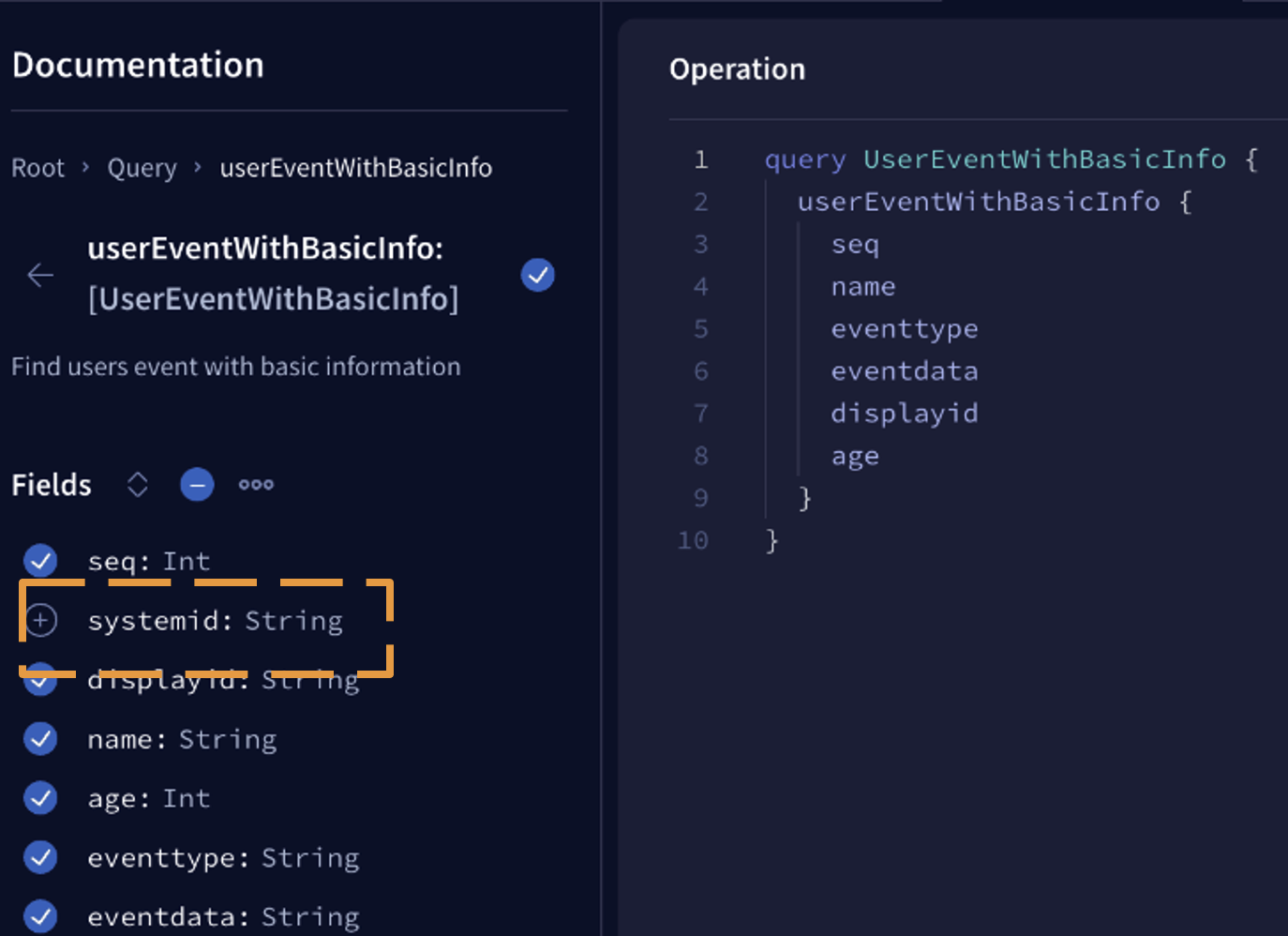
적용 결과 사용자가 필요하지 않다고 판단되는 컬럼은 제거하고 이기종의 DBMS로부터 데이터를 확인할 수 있다. 비즈니스 수준에서 검토 후 반영할 Dimension을 즉시 처리 해 볼 수 있는 시스템 구조를 갖게 되었다.
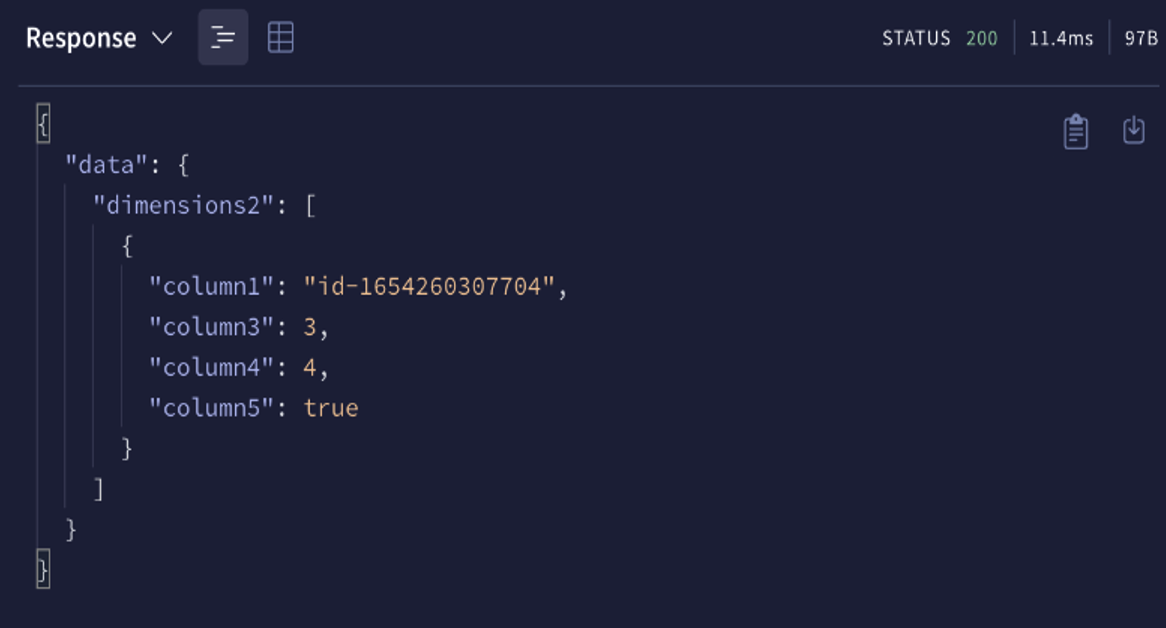
예를 들어 아래 그림은 System Id라는 값이 사용자에게는 무의미하여 제거 후 결과 값을 받아보는 예시다.
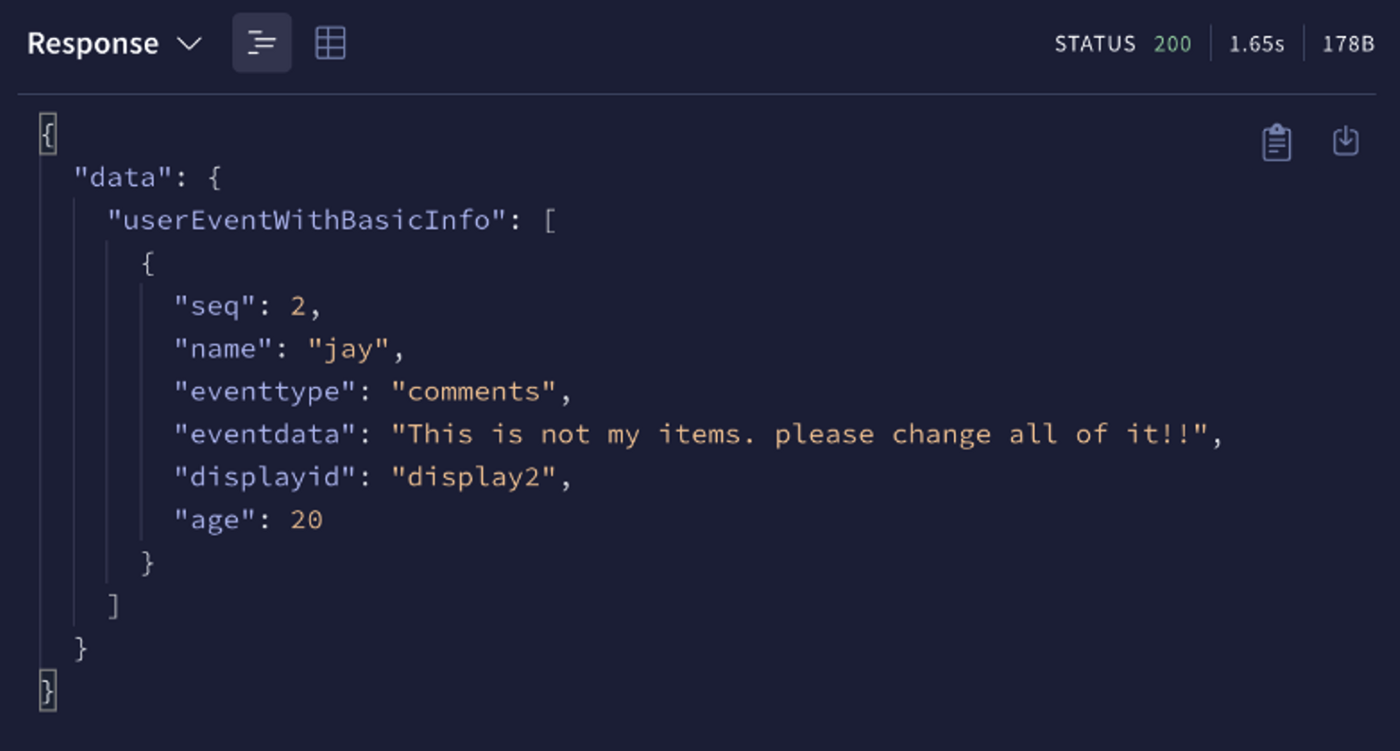
정의된 결과와 질의를 Apolo 서버로 요청하면, 해당 서버는 Resolver에 등록된 Trino DB에게 요청한 쿼리를 전달하게 되고 그 결과를 아래와 같이 받아서 클라이언트에게 전달한다.
급변하는 비즈니스 상황에 대응하기 위한 OLAP 시스템 설계의 방법을 알아보았다. REST와 대비하여 리소스를 계층관계로 표현하지 않아도 되고, 동적으로 Dimension을 구성할 수 있었다. 또한 다양한 DBMS를 지원하며 이기종의 DBMS를 동시에 Fact Table로 이용을 할 수 있음을 확인하였다.
다만 성능부분에서의 한계를 확인하고 이를 해결할 수 있는 추가적인 연구가 필요하다. 응답 결과는 1.5s 내외로 측정이 되어 프로토콜과 인터페이스 성능 부분에서 추가적인 확인이 필요함을 알 수 있다. 또한 각 DBMS의 성능이 GraphQL의 응답 속도에 영향을 미칠 것으로 예상된다. 따라서 필요시 추가적인 Cache와 검색엔진 도입 검토 요건을 확인하고, Trino에서 제공하는 클러스터링의 도입 전후 결과를 비교하는 연구도 필요하다.
©️요즘IT의 모든 콘텐츠는 저작권법의 보호를 받는 바, 무단 전재와 복사, 배포 등을 금합니다.