개발
프론트엔드 아키텍처의 가장 최근 트렌드는?

13분
2022.08.26.인기
68.5K

오늘 할 이야기는 상태 관리, 비즈니스와 View 로직의 분리 프론트엔드 개발의 구조 등 프론트엔드의 아키텍처에 대한 이야기입니다. 프론트엔드를 하다 보면 많이 물어보는(저 역시 지금도 고민하는) 질문들을 꼽아보면 아래와 같습니다.
질문들의 형태는 다르지만 결국 좋은 아키텍처가 무엇인가에 대한 질문이라고 생각합니다.
처음에는 그냥 기능 구현을 하면 되지만 프로젝트의 크기가 커지다 보면 ‘제대로 정리해두지 않으면 정말 안 될 것 같은 순간’들을 맞이하게 됩니다. 그냥 만들면 쉬운 요구사항도 기존 코드에 확장하는 것이 쉽지 않고, 점점 디버깅도 힘들어지는 걸 느낍니다. 이러한 문제에 부딪힌 많은 프론트엔드 개발자가 기존 구조에서 조금씩 더 나은 아키텍처와 프레임워크 형태, 그리고 라이브러리리를 제안했습니다. 덕분에 짧은 시간 안에 새로운 아키텍처들과 방법들이 꾸준히 탄생했습니다.
그 결과, 특정 벤더가 존재하지 않는 웹의 특성과 요구사항 변화, 빠른 대응이 중요한 프론트엔드 직군의 특성이 만나면서 웹 프론트엔드는 더 나은 선택지로의 트렌드 변화가 참 빠른 곳이 되었습니다. 이번 글이 얼마만큼 빨리 낡아질지는 모르나 현재 프론트엔드 아키텍처의 가장 최근 트렌드에 대해서 한번 이야기해보겠습니다.
의도하진 않았지만, 웹은 HTML과 JS, 그리고 CSS가 순서대로 탄생했고 각자의 방식대로 성장했습니다. HTML은 서버가 작성하는 영역이었고 JS는 간단한 동작과 CSS는 화면을 관리했습니다.
‘에이잭스(Ajax)’의 탄생으로 서버에서는 HTML을 만들지 않고 데이터만 교환이 가능하게 됐습니다. 그래서 JS를 이용해 데이터로 DOM을 조작하는 작업이 중요하게 되었고, 이에 따라 jQuery와 같은 Ajax와 DOM을 잘 다룰 수 있는 도구를 통해서 개발하게 되었습니다.
그러다 보니 HTML과 JS를 함께 다루는 편이 더 나았고 이후 앱을 만들던 MVC의 아키텍처를 표방하면서 데이터를 조작하고 DOM을 조작하는 로직을 하나로 관리하려는 움직임이 생겨났습니다. 그러면서 자연스레 화면 단위가 아니라 컴포넌트 단위로 발전하게 됩니다. 또한 MVC 방식으로 화면을 만들고자 하는 backbone.js와 같은 프레임워크들도 만들어졌습니다.
매번 데이터 변경 때마다 템플릿 방식으로 HTML을 작성하는 방안이 연구되었고, 이를 자동화하는 과정에서 knockout.js와 angaulr.js 등을 바탕으로 웹 서비스를 개발하는 MVVM 아키텍처가 만들어집니다. 이후 React, Vue, Angaulr를 비롯한 수많은 프레임워크가 이런 방식으로 만들어지기 시작합니다.
데이터가 많아지고, 로직이 흩어지면서 컴포넌트는 점차 복잡해졌습니다. 이렇게 재사용성이 떨어지면서 데이터를 받아서 보여주기만 하는 readonly 스타일의 ‘Presenter형 컴포넌트’와 데이터 조작을 주로 다루는 ‘Container형 컴포넌트’를 분리하기로 했습니다. 이후 Container에서 props를 Presenter로 내려주면서 로직을 한군데에 모으고 화면을 다루는 View 방식이 재사용 형태의 아키텍처 주류가 됩니다.
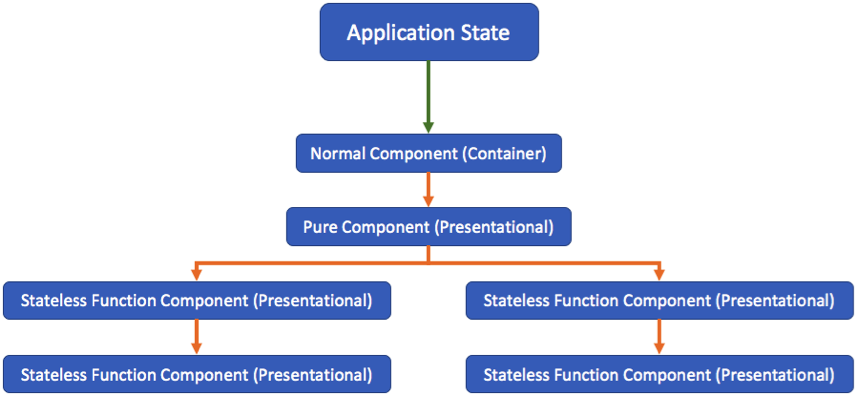
이런 식으로 컴포넌트를 작성하게 되면 필연적으로 상위 props들이 하위로 전달되는 과정에서 중간 컴포넌트를 사용하지 않고 하위에 데이터를 보내기 위한 props가 필요해졌습니다. 컴포넌트의 독립과 재사용성을 위해서 컴포넌트를 분리했지만, 중간 컴포넌트로 인해 오히려 상위 컴포넌트와 하위 컴포넌트가 더 단단하게 결합하는 꼴이 된셈입니다. 이렇게 상위 props를 하위 컴포넌트로 전달할 때 중간 컴포넌트에서 사용하지도 않은 props를 추가해야 하는 Props Drilling 문제가 대두되게 됩니다.
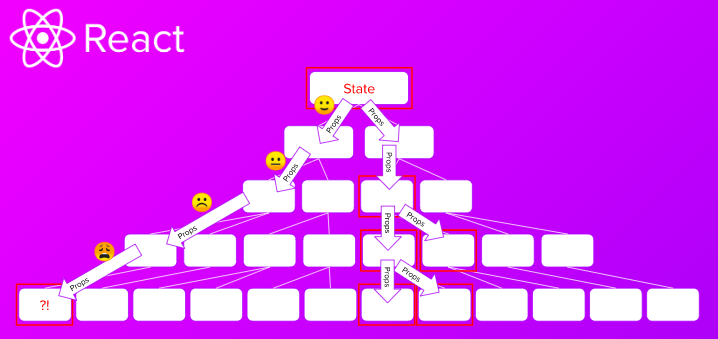
그러다 보니 비즈니스 로직을 굳이 컴포넌트 계층구조로 만들 필요가 없는 것을 알게 됩니다. 그래서 View와 비즈니스 로직을 분리해 단방향 데이터 구조를 가지는 FLUX 패턴이 대두되고, Redux 등을 통해 사용하게 되면서 이러한 형태가 주류 아키텍처가 됐습니다.
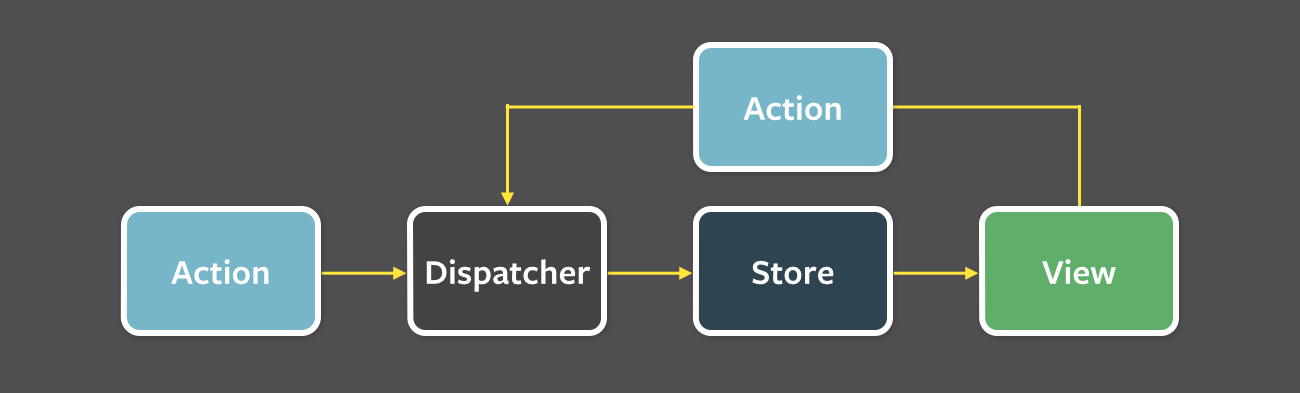
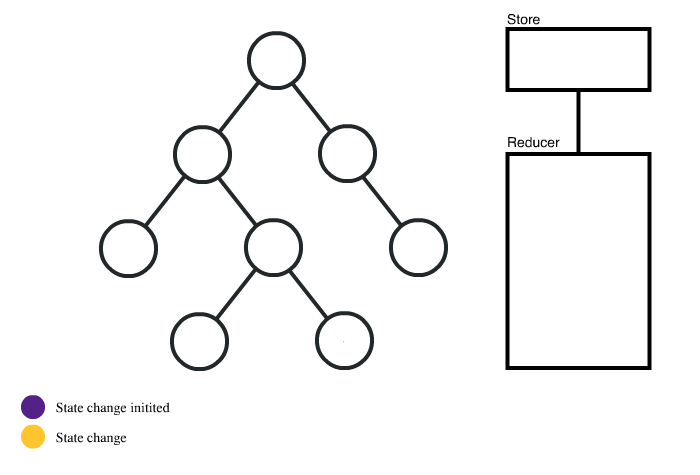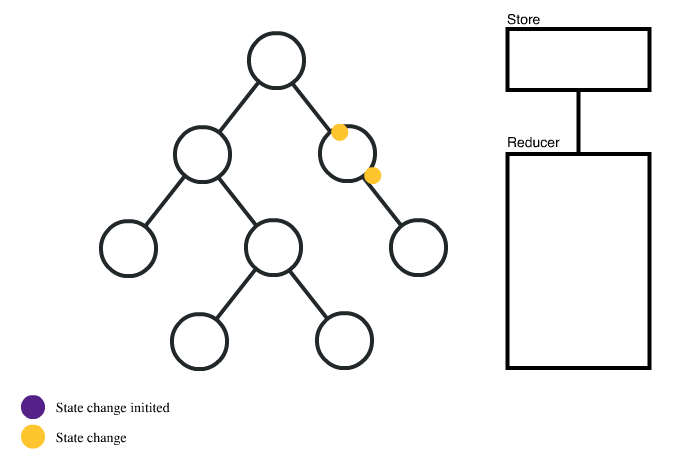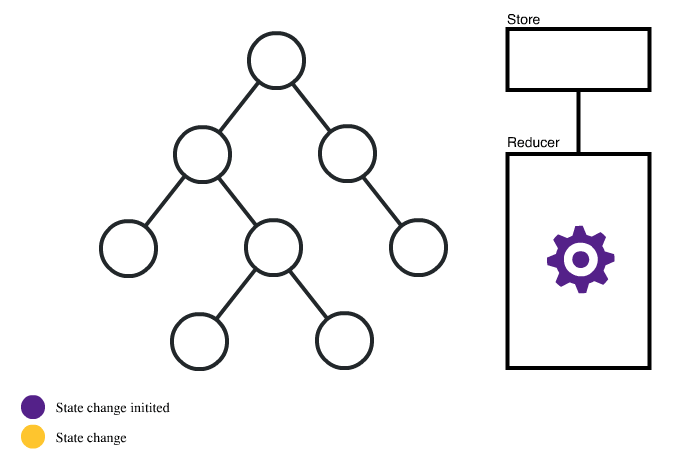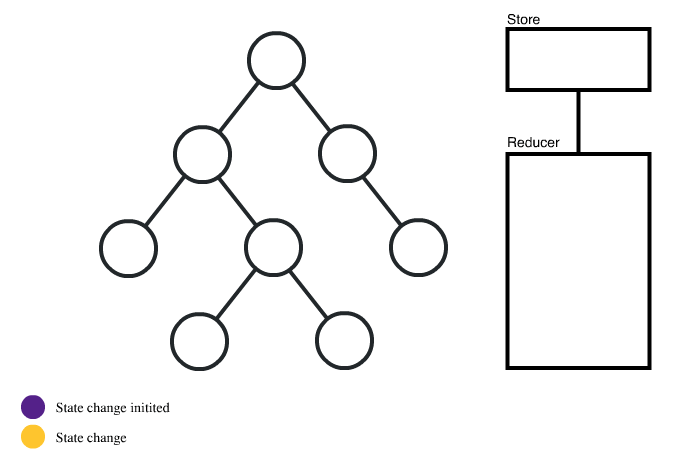
이때부터 비즈니스 로직을 컴포넌트에서 분리하고, 별도로 관리하는 도구들이 주류가 됐으며, 이러한 개념을 ‘상태관리(State Management)’라고 부르게 됩니다.
이후 Redux를 따라 Vue 진영에서는 Vuex가 만들어지고 클래스 데코레이터를 이용하여 조금 더 쉽게 만든 Mobx도 유행했습니다. Angaulr 진영에서는 Rx.js를 베이스로 한 Ngrx가 만들어졌고 이후 조금 더 API를 간소하게 만든 버전인 Ngxs도 만들어졌습니다. 그 밖에 유한상태기계에서 영감을 받은 XState나 기타 Overmind, Effector.js 등 여러 가지 상태관리 도구들이 생겨납니다.
하지만 주류가 된 Redux는 너무 많은 보일러플레이트(최소한의 변경으로 여러 곳에서 재사용되며, 반복적으로 비슷한 형태를 띠는 코드)가 필요했습니다. 컨셉과 시도는 좋았지만, 과한 문법 체계를 가지고 있었기에 대형 프로젝트가 아니라면 중소규모에서 대부분은 오버엔지니어링이 되었습니다.
이후 React는 조금 더 간결한 문법과 외부에서 데이터를 사용할 수 있도록 Hooks를 통해서 외부 비즈니스 로직을 쉽게 연동할 수 있도록 만들었습니다. 또한 Context를 통해서 Props Drilling 없이도 상위 props를 하위로 전달할 방법을 제공하면서 Redux는 더더욱 쓰기 싫은 기술이 되었습니다.
그렇지만 React에서 기본적으로 제공하는 hook API만으로는 전역적인 상태관리가 용이하지 않았습니다. 그래서 Atom이라고 불리는 전역객체를 이용해 데이터를 기록하고, 변경감지를 통해 View로 전달하는 형태인 Recoil이나 Zustands, Jotai 같은 방식이 최근 새로운 대안으로 제시되고 있습니다.
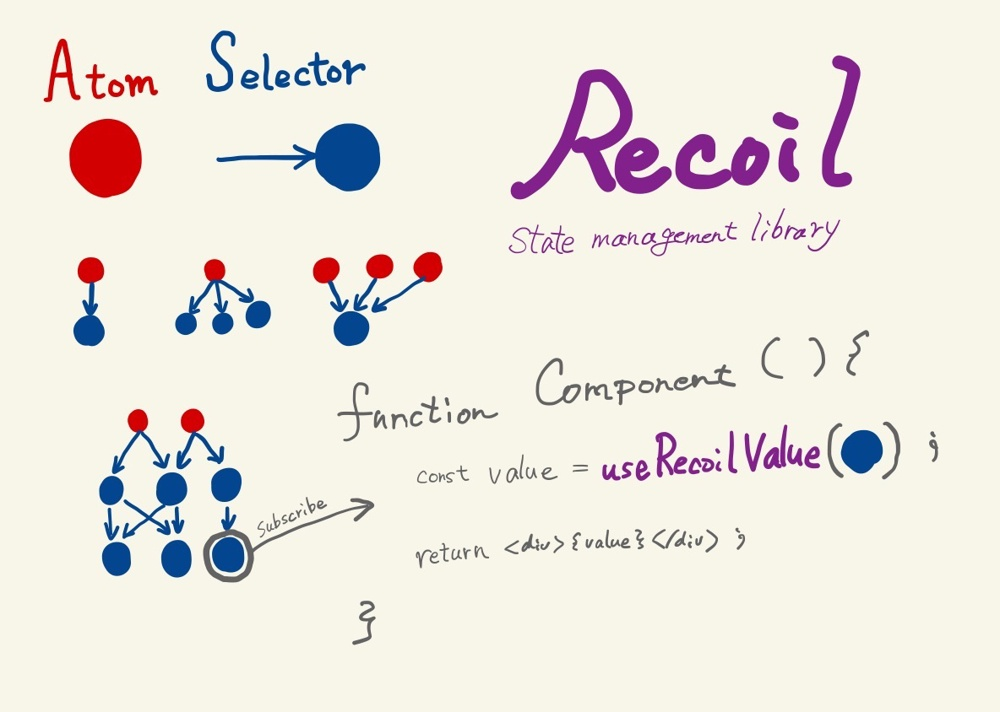
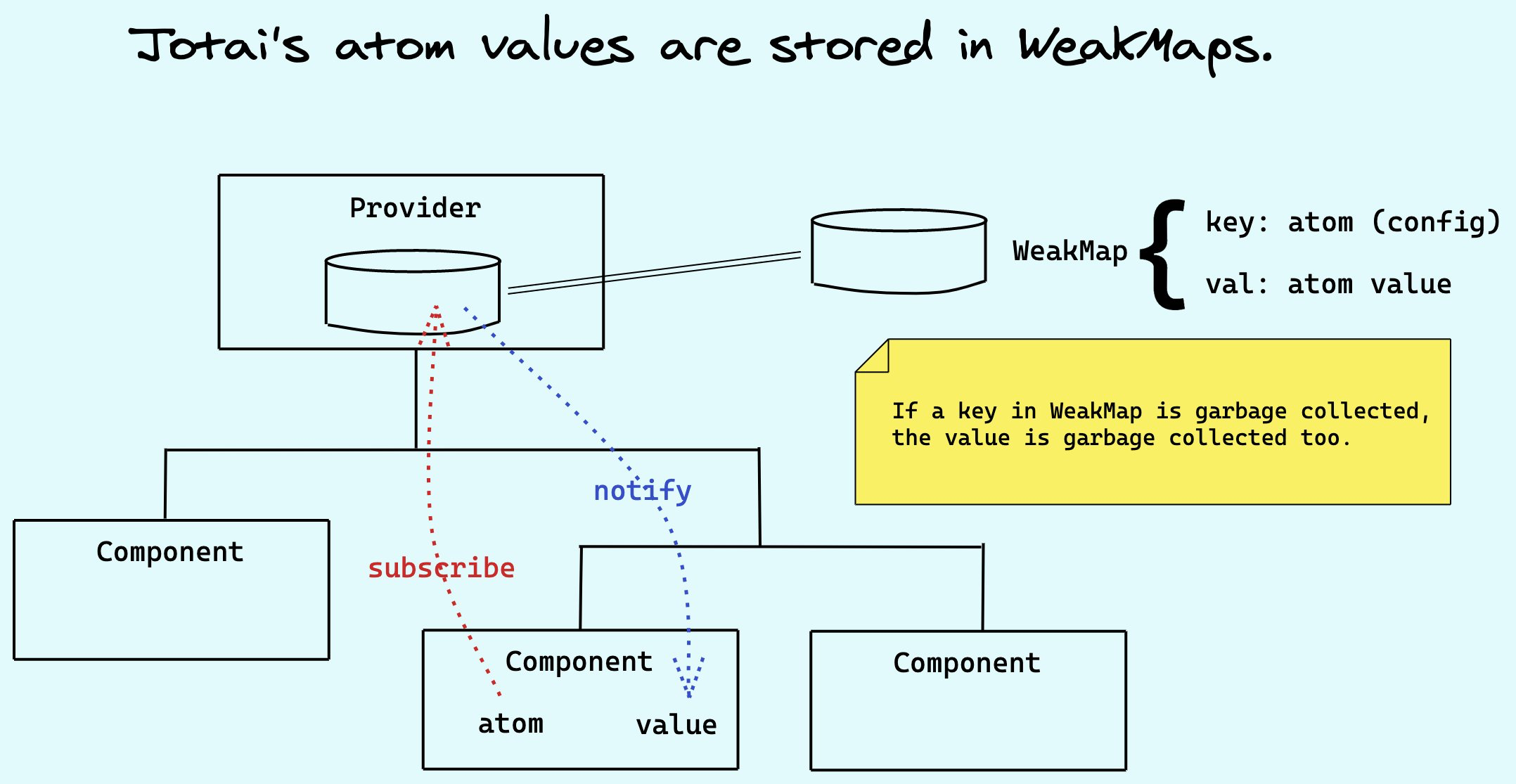
대부분의 프론트엔드에서 전역적인 상태관리가 필요한 이유는 서버와 API에 있습니다. 웹의 특성상 데이터의 보관과 조회, 수정이 서버에서 이루어져야 하고, 그렇기에 비즈니스 로직이 대부분 백엔드에 보관되기 때문입니다.
그렇다면 View는 서버 데이터를 보여주고 서버에 Action을 전달만 하는 경우가 대부분이었습니다. 그러자 백엔드와 직접 연동해 기존 상태관리에서 로딩, 캐싱, 무효화, 업데이트 등 복잡하게 진행하던 로직들을 단순하게 만들어주는 방식도 생겨났습니다. 이러한 방식을 통해 많은 부분을 차지하고 있었던 ‘API를 통한 전역 상태관리’가 단순해지는 결과가 나왔습니다.
Vue가 3.0이 되면서 Proxy를 바탕으로 하는 Composition API를 제공하였습니다. 이를 통해 웹에서 사용하던 연산자나 함수를 그대로 사용해 로컬에서 데이터 변경감지를 할 수 있는 전력 관리 기능도 생겼습니다. 이러한 방식에 영감을 받아 React에서는 Valtio라는 라이브러리도 생겨났습니다. 또한 기존 상태 관리 도구들의 단점인 복잡한 상용구와 Nested한 Object를 다루기 어려운 점을 쉽게 풀어낸 Hookstate와 같은 라이브러리도 생겨나고 있습니다.
서버에서 생성하는 결과물이 HTML에서 JSON으로 바뀌면서, 변경된 데이터를 화면에 반영하는 개발이 프론트엔드의 역할이 되었습니다. 그래서 프론트엔드는 데이터를 화면으로 변경하는 작업을 자동화하는 방향으로, 그리고 페이지 단위에서 컴포넌트 단위로 작업 방식이 진화하였습니다.
컴포넌트의 재사용성과 독립성이 중요해지면서 데이터를 다루는 컴포넌트와 그렇지 않은 컴포넌트를 구분하는 식으로 발전했습니다. 그렇지만 컴포넌트의 계층구조와 데이터의 계층구조가 다른 상황에서 화면과 컴포넌트의 계층구조가 복잡해지다 보니, 컴포넌트 간의 데이터교환까지 복잡해지는 결과를 가져옵니다.
이를 타파하기 위해 컴포넌트와 데이터를 분리하는 단방향 아키텍처가 제기되고, 이때부터 컴포넌트와 데이터를 기조가 나타나게 됩니다. 그러면서 데이터의 변화를 다루는 상태관리가 컴포넌트 프레임워크와 분리되며, 독자적인 발전양상이 나타나게 됩니다.
하지만 상태관리가 고도화되고, 코드가 복잡해지면서 ‘제대로 기능하는지’에 대한 의구심이 커졌습니다. 이후 컴포넌트와 비즈니스 로직은 분리하되 조금 더 간결하게 데이터의 변경감지를 전달할 수 있는 형태로 발전했습니다. 또한 전역적인 데이터 스토어 방향과 서버 상태를 조금 더 편하게 다룰 수 있는 방향으로 발전하기도 했습니다.
그밖에 상태관리를 위한 불변성 관리가 필요해지면서 복잡해진 Nested한 Object를 다루는 방법들을 해결하기 위한 방안들이 모색되고 있습니다.
이러한 배경지식을 바탕으로 본격적인 주제인 비즈니스 로직과 View 로직의 분리, 그리고 상태관리에 대해 이야기를 이야기해보겠습니다.
MVC, MVP, MVVM에 대한 프론트엔드 아키텍처의 변천사에 대한 자세한 이야기는 ‘프론트엔드에서 MV* 아키텍처란 무엇인가요?’ 글을 참고해주시면 좋습니다. 이번에는 최신 아키텍처인 MVI(Model - View - Intent)에 대해서 한번 알아보겠습니다.
본격적인 아키텍처를 설명하기에 앞서 이해를 돕기 위해 UI 프로그래밍 개론을 준비했습니다.
프로그래밍에 대해 한번 생각해봅시다. 최초 컴퓨터는 계산하기 위해 태어났고, 전기신호의 점등에 따른 이진법을 통해 숫자를 만들어 냈습니다. 이렇게 표현되는 값을 데이터라고 부르게 되었습니다. 데이터는 가만히 있어서는 가치가 없으며, 기존 데이터에서 계산을 통해 새로운 데이터를 만들어 낼 때 가치가 생겨납니다.
그래서 이러한 데이터를 보관하고 수정하고 수정하여 새로운 데이터로 계속 만들어가는 처리방법을 기술한 것이 바로 프로그램입니다. 이 데이터를 변화시키는 과정을 기술한 것이 프로그래밍입니다.
일반적으로 사람은 0, 1로만 되어 있는 이진법 데이터들을 알아보기가 힘듭니다. 그래서 이진수를 모아서 숫자로 만들고, 문자로 만들고, 배열을 만들고, 객체를 만들어내면서 조금 더 이해하기 쉬운 형태의 데이터 구조를 만들어냈습니다. 이러한 것들을 우리는 자료구조라고 부릅니다. 우리는 자료구조를 통해서 조금 더 이해하기 쉬운 코드와 프로그램을 작성할 수 있게 되었습니다.
그러나 이렇게 조금 더 이해하기 쉬워진 데이터들도 일반적인 사람들은 다루기가 어려웠습니다. 필요한 데이터를 보는 것도 쉽지 않았고 데이터를 조작하는 것은 훨씬 더 어려웠습니다. 그래서 일반 사용자들에게 데이터를 다루게 하기 위해서는 조금 더 편리한 도구를 제공해야 했고, 이것이 데이터와 사용자 사이에 있는 가상의 매개체인 User Interface가 되었습니다.
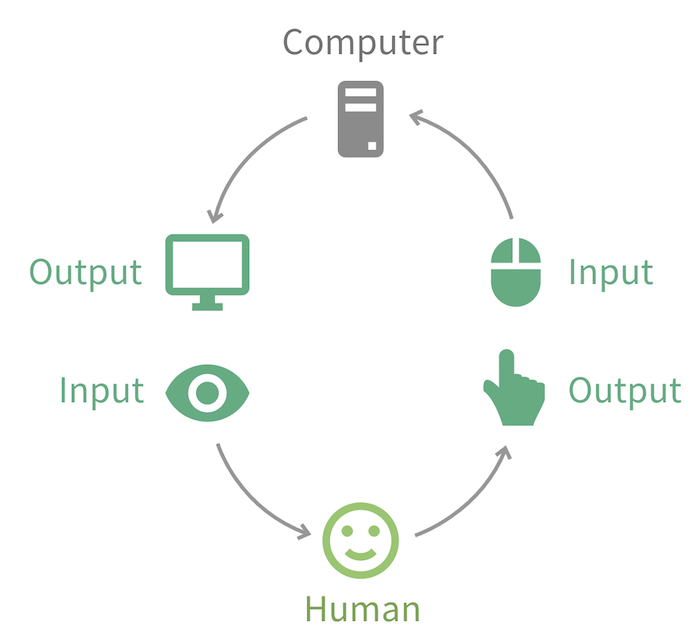
이러한 User Interface는 기존 프로그램의 Input과 Ouput 사이에 화면과 행동을 추가해 새로운 Input과 Ouput을 사용자로부터 받는 매개체의 역할을 하게 됩니다. 이는 프론트엔드 개발자가 만들어야 하는 영역이기도 합니다.
User Interface는 데이터와 사용자 간 흐름의 방향에 따라 다음과 같이 2가지로 생각해볼 수 있습니다.
1) 데이터 → (화면) → 사용자: 데이터의 시각화
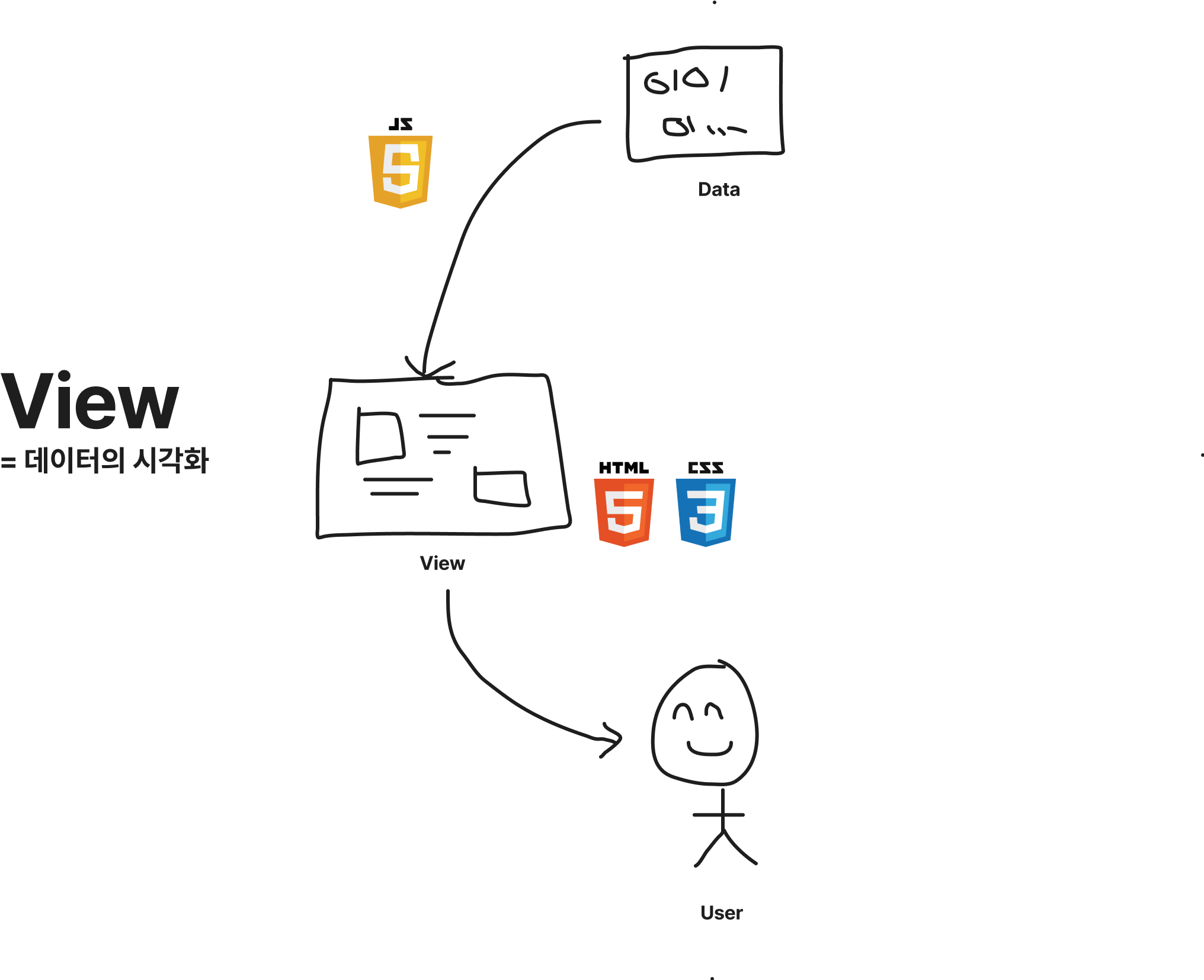
데이터를 사용자에게 더 친숙하고 알기 쉬운 형태로 보여줘야 하는 방법이 필요했습니다. 우리는 웹 브라우저를 통해서 이러한 기능을 제공하고 있습니다. 웹 브라우저는 HTML과 CSS로 화면을 만들어서 보여주고, 개발자들은 데이터를 적절한 형태의 HTML과 CSS로 만들기 위해 JS를 사용하여 DOM을 조작합니다.
2) 사용자 → (행동) → 데이터: 사용자의 행동으로 데이터를 조작
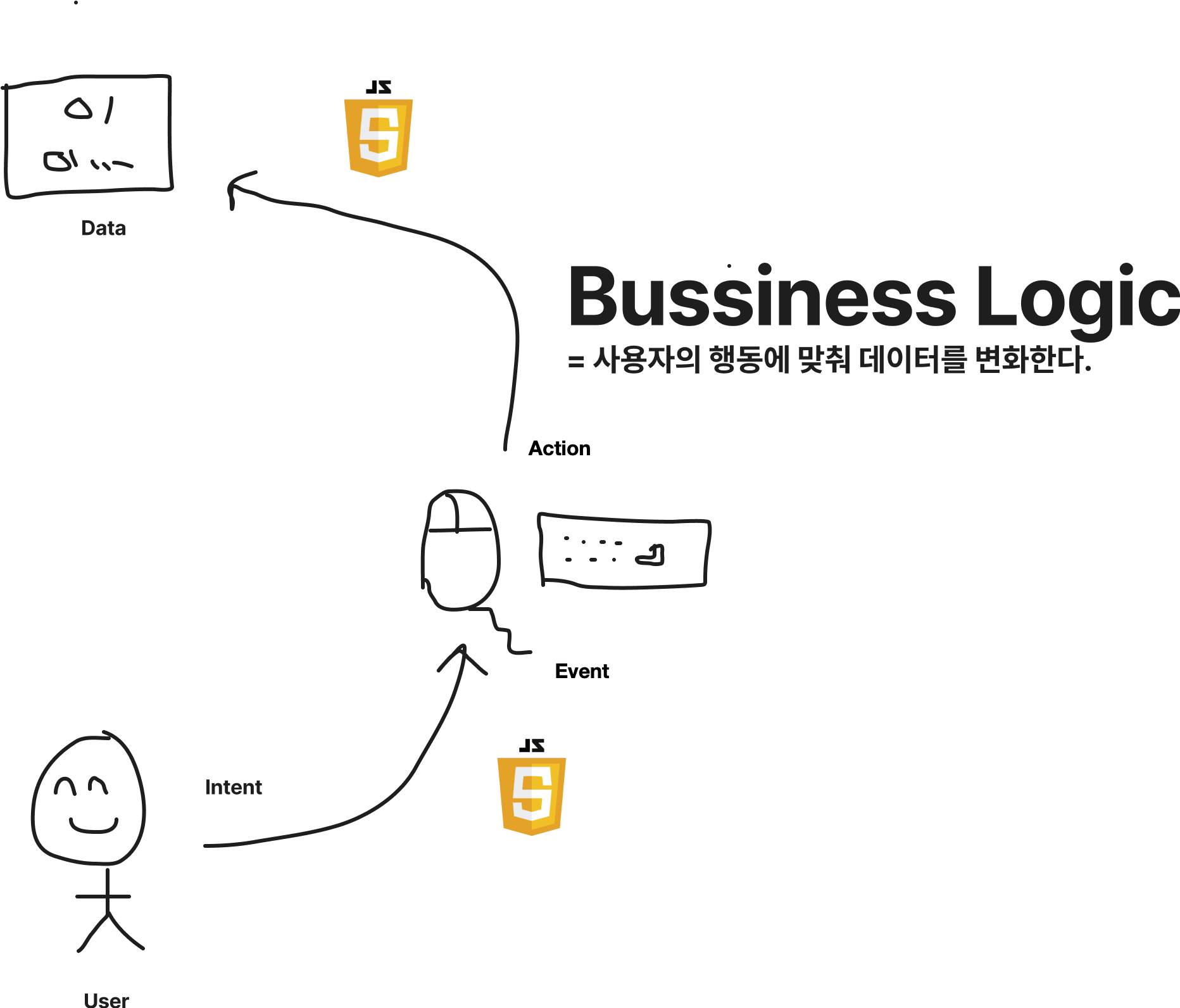
이렇게 전달받은 화면을 통해 데이터를 보면서, 우리는 마우스나 키보드 등의 외부 입력장치를 통해 데이터를 조작하기 위한 특정한 행동(Behavior)으로 명령을 내릴 수 있게 됩니다. 그러면 프로그램은 사용자가 발생시킨 이벤트(Event)를 통해 의도(Intent)에 맞는 동작(Action)을 전달하게 됩니다. 이후 이에 맞는 적절한 데이터 변화가 발생하고, 이는 다시 첫 번째로 돌아가게 되면서 순환구조를 가지게 됩니다.
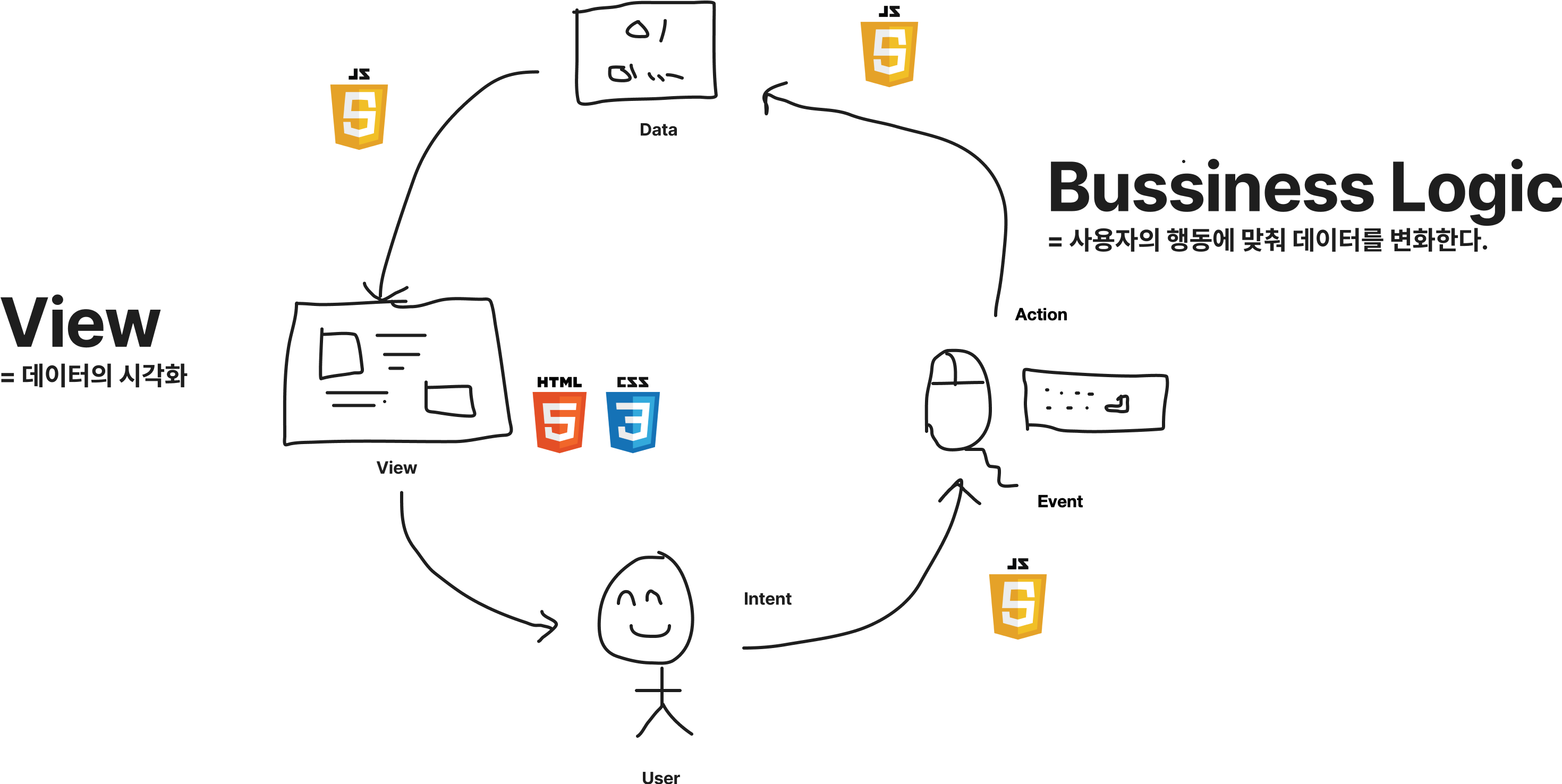
사용자가 다른 동작을 해도 실제로 같은 데이터의 변화를 의미하는 경우가 있습니다. 가령 사용자가 "+" 버튼을 누르거나 위쪽 방향 키보드를 눌렀을 때 동일하게 숫자가 1 증가하도록 설정할 수 있습니다. 이 경우 사용자가 한 행동은 다르지만, 데이터의 입장에서는 같은 동작을 수행한 셈입니다.
우리는 이를 통해서 비즈니스 로직을 2가지 레이어로 나눌 수 있는 걸 알게 되었습니다.
1) 사용자가 View를 통해서 전달한 UI Event를 어떠한 데이터 변화를 하게 할지 전달하는 역할
2) 전달받은 요청에 따라서 적절히 데이터를 변화하는 역할
개발자들은 1)을 사용자의 의도를 파악하는 단계로 정의하고, Intent라 이름 지었습니다. 2)는 데이터를 다루므로 전통적인 이름인 Model이라고 정의했습니다. 그래서 Model - View – Intent = MVI라는 아키텍처가 되었습니다.
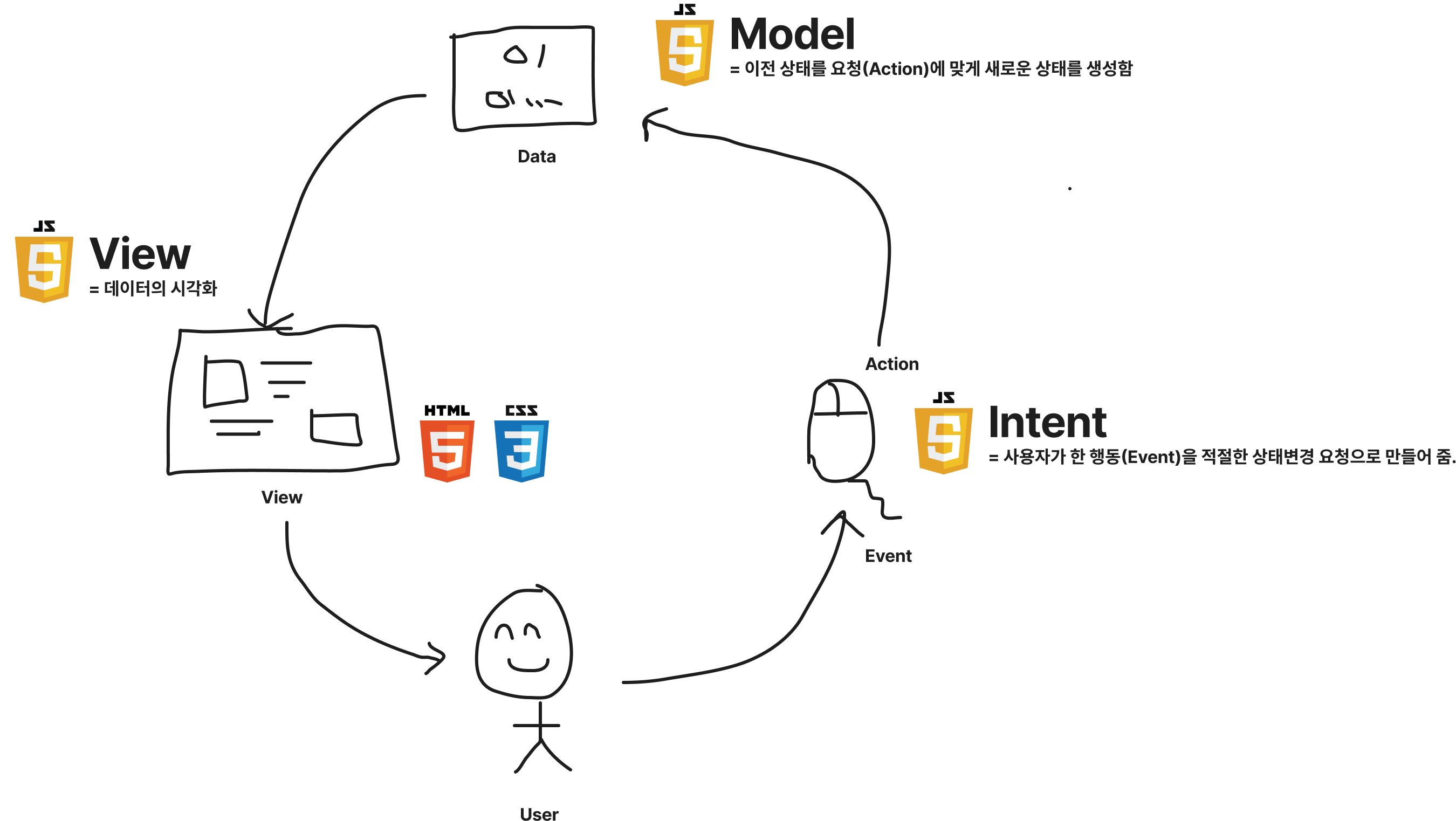
MVI 아키텍처가 기존의 MVC나 MVVM과는 다른 점은 이 구성이 하나의 컴포넌트가 아니라 앱 전체에 적용이 되는 것입니다. 그래서 전체적으로 데이터 방향성이 단방향으로 연결이 되며, 데이터가 전역적으로 구성이 되는 것이 특징입니다. View는 모델에 의존적이지만 비즈니스 로직은 View와의 의존성이 없기 때문에 화면변화에 유연하며, 별도로 테스트하기 쉽습니다. 또한 컴포넌트 간 데이터 통신에 의존하지 않기 때문에 일관성 있는 상태를 유지하기도 용이합니다.
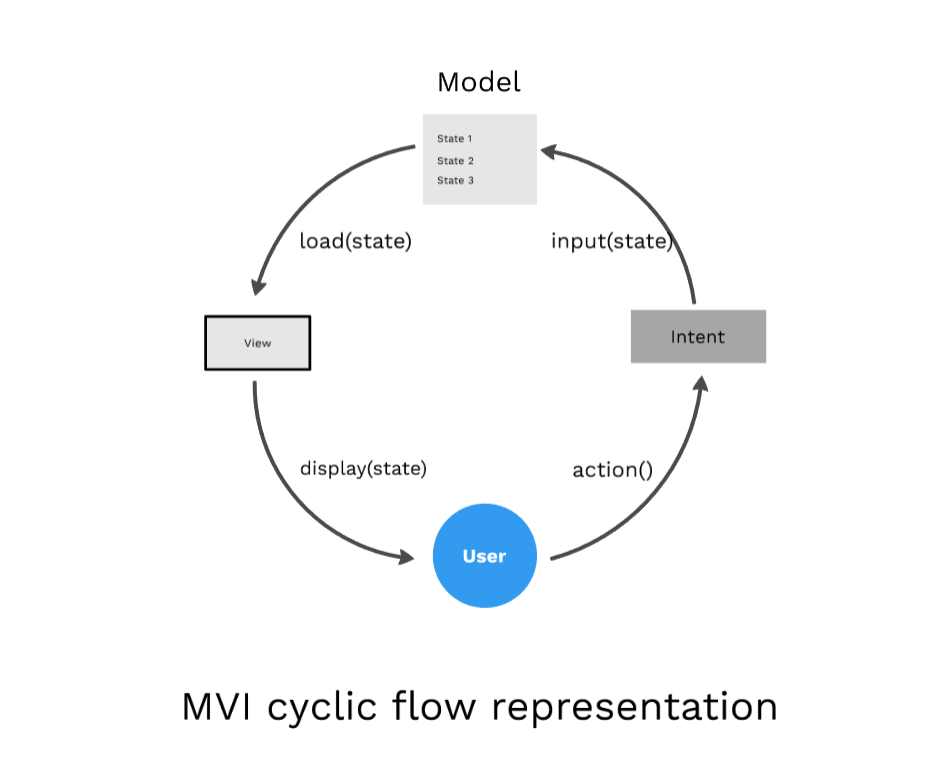
그렇습니다. 눈치채신 분들이 있겠지만 FLUX 패턴, Redux 패턴, 상태관리 등 그동안 프론트엔드에서 줄곧 제시되었던 방법들을 잘 정리하여 아키텍처로써 구성된 모양새입니다.
결론만 정리하자면, 재사용이 가능한 독립적인 컴포넌트를 조립하여 서비스를 구성하는 기존 구조와 달리 현재 프론트엔드 아키텍처 방향성은 View와 비즈니스 로직을 완전히 분리하여 생각하고 있습니다.
비즈니스 로직은 1) 데이터를 관장하는 Model과 2) 사용자의 행동을 데이터 변화로 매핑하는 Intent 영역으로 분리합니다. Model은 다시 1) 변화를 감지하고 변경사항을 전파하는 영역과 2) 데이터를 변화하는 로직을 구분하여 작성합니다. 이를 통해 View에서는 Model로부터 데이터를 조회하는 Query와 데이터를 변화시키는 Command를 언제든 조립해서 사용(CQRS 패턴) 할 수 있습니다. 또한 View는 비즈니스 로직에 의존적이지만, View끼리는 느슨하게 결합하여 UI 요구사항 변화에 긴밀하게 대응할 수 있게 됩니다.
그렇다고 전통적인 독립 UI 컴포넌트가 필요 없는 건 아닙니다. 프론트엔드에서 컴포넌트 계층의 맨 아래에 있는 재사용이 가능한 독립적인 UI 컴포넌트를 조립하여 화면을 만드는 전략은 여전히 유효합니다.
그러나 Props Drilling을 유발하며 경직된 구조를 만들어내는 중간 계층의 컴포넌트들은 사실 독립적일 필요도 없고, 재사용도 되지 않는 컴포넌트인 경우가 많습니다. 이러한 컴포넌트들은 대개 비즈니스 로직을 담당하기 때문에 ‘거대한 컴포넌트(Massive-View-Controller)’가 되기 마련입니다.
기존에는 ‘컴포넌트는 독립성을 유지하고 의존성을 최소화해야 한다’는 원칙에 따라 최대한 props를 통해서 컴포넌트 계층 구조를 유지하려고 했습니다. 하지만 이 방식이 되려 경직된 구조를 만들어냈기에 어차피 재사용하지 못할 컴포넌트라면 비즈니스 모듈에 의존적이더라도 언제든 교체가능한 방식으로 만들어내는 것이 변화에 대응하기 좋습니다.
FLUX 패턴에서 생소한 개념인 Reducer는 ‘왜 이렇게 작성해야 하는지?’에 대해 의문을 품는 사람들이 많습니다. 일반적으로는 보통 이벤트 핸들러에서 직접 모델의 여러 데이터들의 변화를 기술하는 식으로 작성하는 경우가 많습니다.
// View에서 직접 여러가지 값들의 변화를 기술한다.
const onClick = () => {
setVisible(!visible)
setCount(count + 1)
setTodos([...todos, {title: "할일추가"})
}
이러한 방식은 우리가 알고 있는 실행순서와 일치하기 때문에 작성할 때는 어렵지 않습니다. 그러나 문제는 디버깅할 때입니다. 디버깅은 결과를 보고 원인을 찾아내는 역순의 과정을 밟아야 하기 때문에 특정 데이터의 변화를 다 추적해야 할 필요가 생깁니다. 이때 데이터가 변화하는 View 코드에 흩어져 있으면 어떤 식으로 데이터가 변화하는지 추적이 어렵습니다. 그뿐만 아니라 View에서 직접 데이터를 수정하도록 작성하게 되면 View와 모델 간의 의존성뿐만 아니라 모델과 View 간의 의존성이 생기게 됩니다.
따라서 View에서는 의도만을 전달하고 의도에 맞는 데이터 변환은 모델에서만 처리할 수 있도록 만들어야 합니다. 데이터를 변화하는 코드를 Model 모듈에 모으게 되면 응집도가 높아지고 추후 디버깅에 용이하며, 특히 View가 비즈니스 로직으로부터 느슨한 결합을 할 수 있습니다.
내가 사용하고 있는 상태관리를 떠올려보세요. 최소한의 코드로 데이터의 흐름과 아키텍처의 느낌만 이해할 수 있도록 작성해봤습니다.
// Action
export const _INCREASE = action("_INCREASE")
export const _DECREASE = action("_DECREASE")
export const _RESET = action("_RESET")
// Model
export const store = createStore({count:0}, state => {
on(_INCREASE, (value) => state.count += value)
on(_DECREASE, (value) => state.count -= value)
on(_RESET, () => state.count = 0)
})
// Component
export const App = (props) => {
// Query
const count = SELECT(store.count)
// Computed Value
const doubledCount = count * 2
// Intent
const onClick = () => dispatch(_INCREASE(+1))
// View
return <button onCLick={onClick}>{count}</button>
}
이러한 방식으로 작성하게 되면 화면을 구성할 때 컴포넌트 간의 종속성이나 비즈니스 모델의 구현과 관계없이 유연하게 화면을 만들 수 있게 됩니다.
// Component1
const Component1 = (props) => {
const count = SELECT(store.count)
return <div>{count}</div>
}
// Component2
const Component2 = (props) => {
const onClick = () => dispatch(_INCREASE(+1))
return <>
<Component1/>
<button onCLick={onClick}>1 증가</button>
</>
}
프론트엔드 아키텍처 트렌드는 정말 빨리 바뀌고 있습니다. 몇 년만 지나면 벌써 내 코드나 아키텍처가 낡은 방식이 되고 맙니다. 조금 지나기는 했지만, 여전히 Redux에 의구심을 품으면서 상태관리를 중심으로 여러 가지 대안들이 제시되고 있는 모습입니다.
패러다임과 아키텍처는 실제가 아니라 방향성입니다. 내가 쓰고 있는 라이브러리가 정확히 이러한 형태에 맞지 않을 수 있습니다. 그렇지만 이러한 대략적인 방향성과 흐름을 이해한다면 여러 상태관리 라이브러리를 선택하거나 컴포넌트의 구조를 설계할 때 더 넓은 시각으로 바라볼 수 있을 거로 생각합니다.
이 글이 좀 더 나은 컴포넌트와 프론트엔드의 구조를 설계하는 데 도움이 될 수 있는 마중물이 되길 바라며, 다음번에는 조금 더 깊은 이야기로 찾아뵙겠습니다. 긴 글 읽어주셔서 감사합니다.
©️요즘IT의 모든 콘텐츠는 저작권법의 보호를 받는 바, 무단 전재와 복사, 배포 등을 금합니다.