개발
개발자를 위한 AWS 클라우드 보안: ②로깅 및 모니터링과 데이터 보호

16분
2022.08.12.5.5K

국내 유명 IT 기업은 한국을 넘어 세계를 무대로 할 정도로 뛰어난 기술과 아이디어를 자랑합니다. 이들은 기업 블로그를 통해 이러한 정보를 공개하고 있습니다. 요즘IT는 각 기업의 특색 있고 유익한 콘텐츠를 소개하는 시리즈를 준비했습니다. 이들은 어떻게 사고하고, 어떤 방식으로 일하는 걸까요?
이번 글은 딥러닝 기술을 활용해 사람처럼 친근한 대화를 할 수 있는 관계 지향형 AI 챗봇을 개발하는 AI 스타트업 '스캐터랩'의 Engineering 팀의 이야기입니다. 스캐터랩이 효율적인 클라우드 인프라를 구축하기 위해 진행한 작업을 살펴보고, 어떤 방식으로 AWS 클라우드 보안 강화를 했는지 알아보겠습니다.
지난 글에 이어 이번 글에서는 로깅 및 모니터링 영역과 데이터 보호 영역에 대해 살펴보겠습니다.
로깅 및 모니터링 영역은 클라우드 환경에서 발생하는 로그를 중앙으로 모아 보관하여 잠재적 보안 문제나 의심스러운 활동의 원인을 쉽고 빠르게 조사, 분석, 식별할 수 있는 환경을 구축하는 것을 목표로 합니다. 로깅 및 모니터링 아키텍처를 잘 갖추면 클라우드 사용 중에 발생하는 문제를 빠르게 파악하고, 문제의 원인 또한 수월하게 찾을 수 있습니다.
핑퐁팀에서 로깅 및 모니터링 영역 강화를 위해 적용한 내용을 소개하겠습니다.
로깅 및 모니터링 영역에서는 로깅이 가장 중요합니다. 로그가 없으면 후술할 모니터링이 애초에 불가능할 뿐만 아니라, 사고가 발생했을 때 원인을 분석할 수 없기 때문입니다. 애플리케이션에서 오류가 발생하면 로그를 분석하여 원인을 찾는 것처럼, 클라우드 환경에서의 오류 또한 마찬가지입니다. 따라서 클라우드 API 호출과 관리 콘솔을 이용한 동작을 로그로 남겨야 합니다.
AWS에서 로깅을 위해서는 대표적으로 CloudTrail을 사용할 수 있습니다. CloudTrail은 클라우드 감사 로그 서비스로, 활성화하면 사용자의 모든 활동이 사용한 역할(role), 활동의 위치(source IP), 행위의 형식(API 호출/관리 콘솔 접근 등), 요청의 파라미터 등과 함께 기록됩니다. CloudTrail을 활용하면 개발자의 실수나 보안 사고로 인해 클라우드 자원의 설정이 변경되거나 자원이 유실되는 경우에도 행위를 역추적하거나 의심스러운 활동을 분석하고 식별할 수 있습니다.
보안 강화를 위해서는 감사 로그뿐만 아니라 AWS 관리형 서비스의 로그도 수집해야 합니다. 아래 목록은 핑퐁팀에서 수집하는 AWS 서비스 로그입니다.
수집한 로그를 계속 적재하게 되면 용량이 너무 커지게 되므로 오래된 로그는 주기적인 정리가 필요합니다. 다만 관계법령에 따라 특정 기간동안 보존해야 하는 로그도 있습니다. 이렇게 특정 기간을 두고 로그를 정리해야 하는 경우 보관 주기(Retention Period)를 정의하여 관리해야 합니다.
핑퐁팀에서는 로그 보관 주기를 로그별로 정의하고, 이를 손쉽게 적용하기 위해 S3 Object Lifecycle Policy를 이용했습니다. 우선 로그 파일이 S3 버킷에 생성되고 90일이 지났다면, 아마 자주 열람할 필요가 없을 것이므로 S3 Glacier로 보내서 옛날 로그에 대한 저장 비용을 줄였습니다. 그리고 365일(또는 관계법령에서 정한 일정한 기간)이 지나면 완전히 파기하는 방식을 택했습니다.
S3 Object Lifecycle Policy 이외에도 CloudWatch처럼 자체적으로 Retention Period 설정 기능을 제공하는 경우 이 기능을 이용할 수도 있습니다. 단 CloudWatch에서는 보관 주기가 지나면 자동으로 파기되기 때문에 백업을 위해서는 다른 방법을 사용해야 합니다. 이 부분은 뒤에서 자세히 살펴보겠습니다.
AWS의 다양한 서비스를 이용하다 보면 의외로 수집해야 할 로그 종류가 꽤 많아집니다. 그런데 지난 글에서 살펴본 것처럼, 핑퐁팀은 다중 계정 구조를 도입했습니다. 따라서 계정별로 로그 저장소가 존재하게 됩니다. 이대로 둔다면 각 계정의 저장소마다 보관 주기를 일일이 설정해야 하고, 계정마다 모니터링 환경을 개별적으로 구축해야 하기 때문에 관리하기 복잡해집니다.
또한 CloudTrail과 같은 감사 로그의 경우 보안 로그로 분류되기 때문에 무결성이 굉장히 중요하므로 로그 저장소에 대한 접근 권한이 엄격하게 통제되어야 합니다. 하지만 보안 로그는 모든 계정이 필수로 수집해야 하므로, 계정마다 CloudTrail 로그 저장소에 대한 권한을 엄격하게 통제해야 한다는 번거로움이 있습니다. 확장성을 고려한다면 좋은 방법이 아닙니다.
위와 같은 문제를 해결하기 위해 핑퐁팀은 로그 저장소를 중앙화했습니다. 앞서 적용한 Control Tower의 Log Archive 계정으로 모든 로그를 보내고 해당 계정의 S3 버킷에 로그를 저장하도록 설계했습니다. 로그 저장소를 중앙화하면 다음과 같은 장점들이 있습니다.
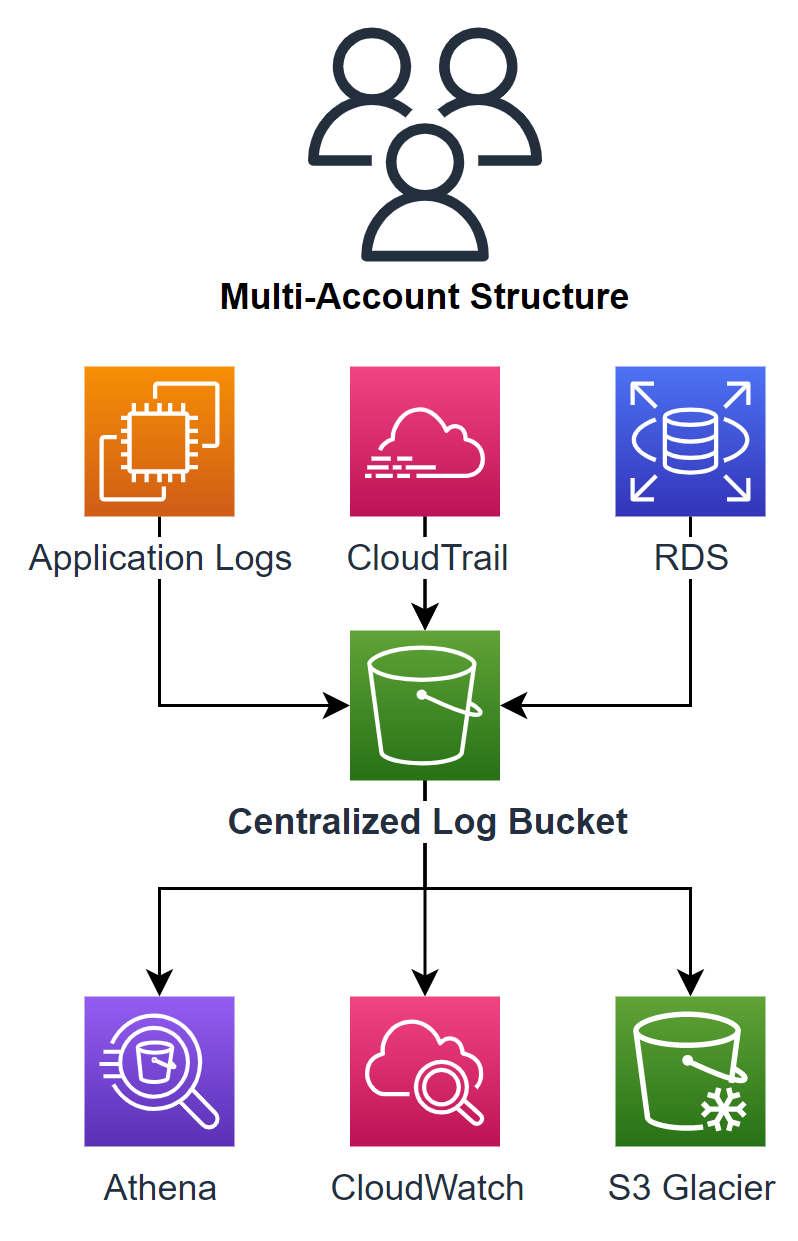
위와 같은 장점이 있음에도 불구하고, 실제로 로그를 중앙화하는 과정은 꽤 복잡했습니다.
지난 글에서 요청하는 계정과 리소스가 존재하는 계정이 다른 경우 자격 증명 기반 정책과 리소스 기반 정책을 모두 설정해야 한다고 했습니다. 이에 따라 로그를 보내고자 하는 계정(A)과 Log Archive 계정에서 권한을 모두 설정해야 하는 번거로움이 있었습니다.
번거로운 작업이지만, 처음 세팅할 때만 신경 써주면 되는 부분이라 큰 문제는 아니었습니다.
WAF ACL Logs, VPC Flow Logs를 수집하기 위해 AWS 콘솔을 사용하면 destination을 같은 계정 내의 S3로만 설정할 수 있습니다. 그래서 destination을 Log Archive의 S3 버킷으로 설정하기 위해 AWS CLI를 사용해야 했습니다.
DNS Query Logs, Document DB Audit/Profiler Logs, EKS Control Plane Logs의 경우 로그가 S3 버킷이 아닌 CloudWatch에 수집됩니다. 하지만 핑퐁팀의 목표는 모든 로그를 Log Archive의 S3 버킷으로 모으는 것이기 때문에 CloudWatch의 Export to S3 기능을 이용해서 로그를 내보내야 했습니다. Export to S3 기능을 주기적으로 호출하기 위해 AWS Lambda와 Amazon EventBridge(구 CloudWatch Events)를 사용했습니다.
우선 AWS Lambda에서는 CloudWatch 로그 그룹 중 ExportToS3: true 태그가 부여된 로그 그룹만 필터링해 가져옵니다. 그리고 AWS System Manager Parameter Store에서 가져온 해당 로그 그룹의 ‘마지막으로 내보낸 시각’이 24시간이 지났을 때만 로그를 내보냅니다. 로그를 지나치게 자주 내보내면 비용이 과하게 청구될 수 있기 때문입니다. 이 Lambda 함수는 4시간마다 호출되도록 Amazon EventBridge에서 규칙을 설정했습니다.
위 과정을 통해 Log Archive 계정으로 로그를 모을 수 있었지만, 아쉬운 점이 하나 있었습니다. 내보내기 결과 파일들의 prefix에 Export Task ID(UUID 형태)가 무조건 포함되면서 로그 파일의 prefix가 쿼리하기 매우 불편한 형태가 됩니다. 이 부분은 나중에 후처리하기로 했습니다.
S3 Access Logs의 경우 destination이 반드시 해당 계정 내의 S3 버킷이어야 하므로, 우선 각 계정의 S3에 로그를 적재한 후 이를 Bucket Replication을 통해 Log Archive 계정으로 로그를 전송했습니다. 그리고 각 계정에 적재된 원본 로그가 오래 남아있지 않도록 Object Lifecycle Policy를 적용하여 하루 뒤에 삭제되도록 했습니다.
AWS 공식 문서에 누락되거나 잘못 적힌 내용이 있어 로그 중앙화 과정에서 어려움을 겪기도 했습니다. AWS에서 로그를 중앙화할 때 참고할 수 있도록 몇 가지 사례를 공유합니다.
<bucket_name>.s3.amazonaws.com으로 설정해야 합니다.
위의 험난한 과정을 거쳐 로그 중앙화에 성공했습니다. 단, 리전 이슈가 있어 로그 버킷은 서울(ap-northeast-2)과 버지니아 북부(us-east-1)에 각각 구성했습니다.
서비스의 종류에 따라 형식이 조금 다를 수 있지만, 아래는 로그 저장용 S3 버킷에 저장된 로그 파일의 Prefix 구조 예시입니다.
# 로그가 CloudWatch를 거쳐서 가는 경우s3://centralized-log-bucket/<Organization ID>/AWSLogs/<Account Number>/aws/<Service># 로그가 S3로 바로 전송되는 경우s3://centralized-log-bucket/<Organization ID>/AWSLogs/<Account Number>/<Service>/<Region>
S3의 오브젝트들은 디렉터리 구조로 보이기 때문에, 모든 로그를 중앙으로 모았지만, 콘솔에서는 계정별로, 서비스별로, 리전별로 잘 정리된 것처럼 보이게 되어 로그를 보는 데 큰 문제는 없습니다. CLI에서도 정해진 Prefix를 이용해서 검색할 수 있기 때문에 편리합니다.
아래는 핑퐁팀에서 수집하는 로그와 전송 과정, 보관 주기를 정리한 도표입니다.
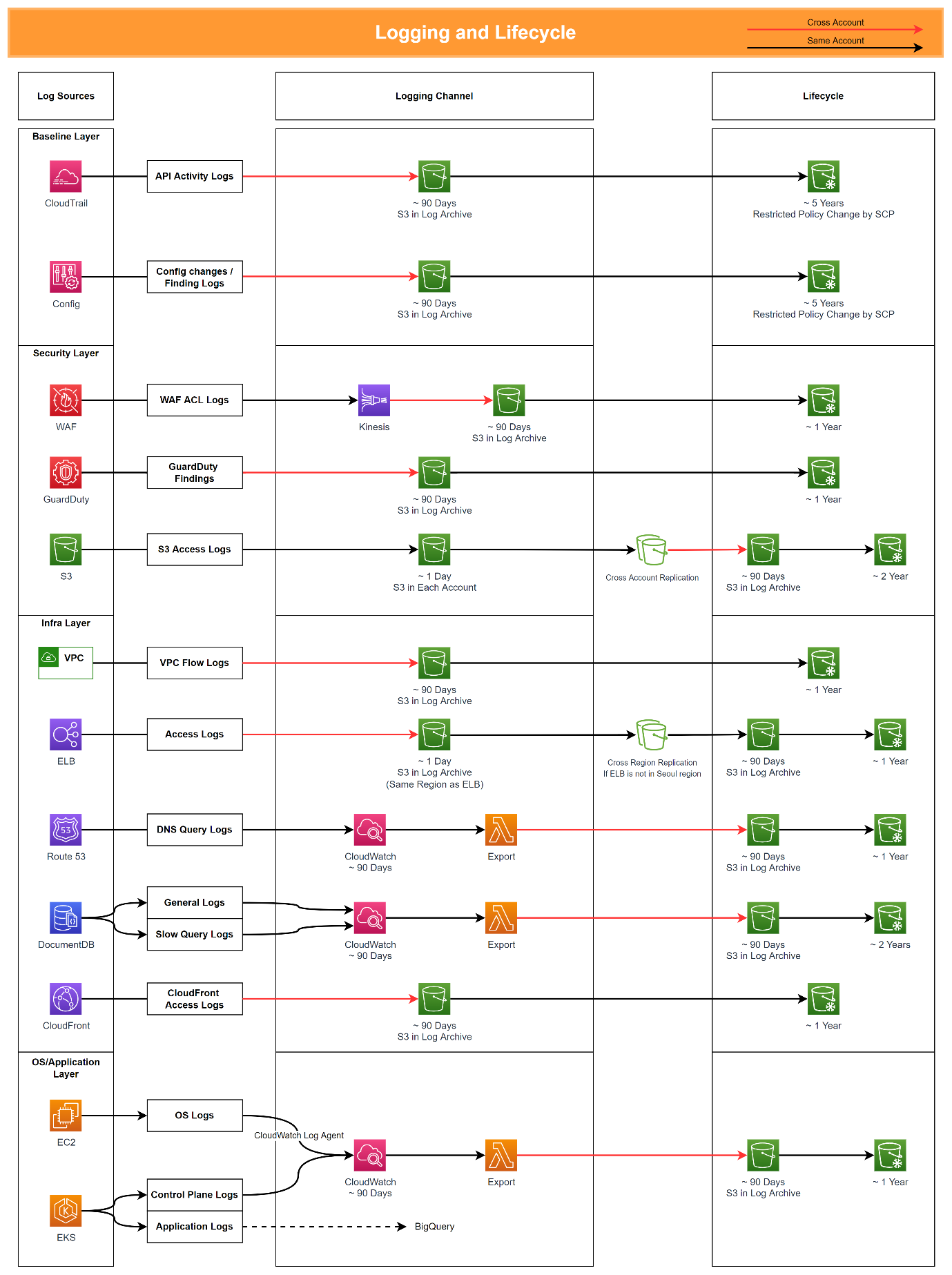
위 방법을 통해 중앙 저장소로 모인 로그는 보안 감사를 위해 주기적으로 분석해야 하고, 효율적인 분석을 위해 모니터링 시스템을 구축해야 합니다.
AWS의 경우 Athena를 이용해 SQL 쿼리로 로그 파일의 내용을 검색할 수 있습니다. 혹은 저장소에 들어오는 모든 로그를 AWS Opensearch와 Kibana를 이용해 대시보드를 구성하는 방법도 있습니다. 이외에도 SIEM 솔루션을 도입한다면 모니터링 환경을 빠르게 구축할 수 있습니다.
핑퐁팀에서는 초반에 AWS Opensearch(구 ElasticSearch)와 Kibana를 이용해 대시보드를 구성했으나 활용도가 낮다고 판단하여 사용하지 않기로 했습니다. SIEM(Security Information & Event Management) 솔루션 도입도 고려했으나 현재 핑퐁팀의 상황에 맞지 않다고 판단했습니다. 그래서 핑퐁팀은 CloudWatch/CloudWatch Alarms를 통해 대시보드를 만들고 알람을 설정하는 방법을 통해 클라우드 인프라를 모니터링하기로 했습니다. Custom Metric을 추가해서 알람을 설정하거나, 로그 필터를 사용하여 로그로부터 특정 패턴을 검사해 확인이 필요한 로그를 필터링하도록 했습니다. 예를 들어 보안 그룹과 관련된 Custom Metric을 생성하고 알람을 설정하여, 보안 그룹의 설정을 변경하거나 보안 그룹을 추가/제거하면 슬랙으로 알림이 오도록 설정했습니다.
로그 모니터링뿐만 아니라 리소스의 사용량도 모니터링해야 합니다. CPU/메모리/디스크 사용량을 꾸준히 모니터링 하지 않으면 보안 사고가 발생했을 때 알지 못한 채로 넘어가거나, 서비스의 가용성에 영향을 줄 수도 있고 사고 대응이 늦어지게 됩니다.
CloudWatch는 EC2의 CPU/메모리 사용량, DocumentDB의 CPU/메모리 사용량, 커넥션 개수 등 유용한 지표를 수집하고 있으니 이를 참고하면 더욱 다양한 리소스를 손쉽게 모니터링할 수 있습니다.
리소스의 보안 규정(compliance) 준수 여부에 대한 지속적인 관리 또한 로깅 및 모니터링 영역의 주요 관심사입니다. AWS 환경이 지속적으로(continuous) 보안 규정을 준수할 수 있도록 AWS 계정 및 리소스 상태를 점검할 수 있는 환경을 구성하는 것이 목표입니다.
지속적인 보안 규정 준수를 위해서는 리소스의 설정 변경 사항을 추적하고 로깅하는 AWS Config 서비스를 이용합니다. AWS Config를 통해 AWS의 리소스 설정 변경 내역을 확인할 수 있으며, 리소스의 설정이 보안 규정을 위반하는지 지속적으로 모니터링할 수 있습니다. 더불어 잠재적 보안 위협이 될 수 있는 리소스 설정 변경을 탐지하고 위반 사항을 발견해 알려줍니다. 간단한 위반 사항의 경우 자동으로 문제를 해결해주는 기능(Remediation Action)도 제공하고 있어 보안 조직의 업무 효율성이 높아집니다.
실제로 Control Tower의 탐지형 가드레일이 AWS Config 서비스를 기반으로 구현되어 있습니다. 그래서 리소스 설정이 변경되면 AWS Config를 통해 설정이 변경되었음을 Control Tower가 알게 되고, 위반 사항이 있다면 이를 탐지하여 담당자에게 알려주는 역할을 합니다.
또한 AWS Config 서비스에는 규정 준수 팩(Conformance Pack)이라는 기능이 있습니다. 규정 준수 팩 안에는 리소스의 설정을 모니터링하는 각종 규칙이 포함되어 있습니다. 대표적으로 KISA와 AWS가 협업하여 만든 K-ISMS 규정 준수 팩이 있는데, 이 팩의 규칙들은 KISA의 ISMS-P 기준에 맞춰서 작성되어 있습니다. 핑퐁팀은 이 팩을 적용하여 ISMS-P 기준에 맞춰서 클라우드 리소스를 관리할 수 있게 되었습니다.
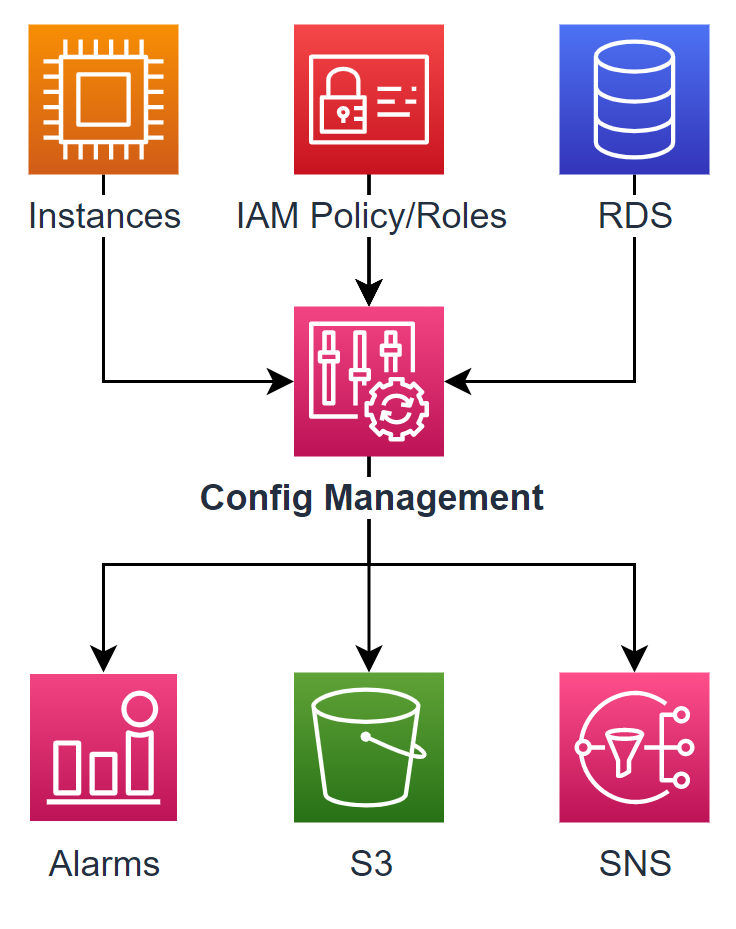
이와 같은 설정 변경 사항의 탐지 및 잠재적 보안 위협 해결은 Control Tower 배포와 동시에 생성된 Audit 계정을 이용합니다. Audit 계정에는 보안 담당자/팀만 접속할 수 있으며, Audit 계정에서는 감사 목적으로 다른 계정의 상태를 점검할 수 있습니다.
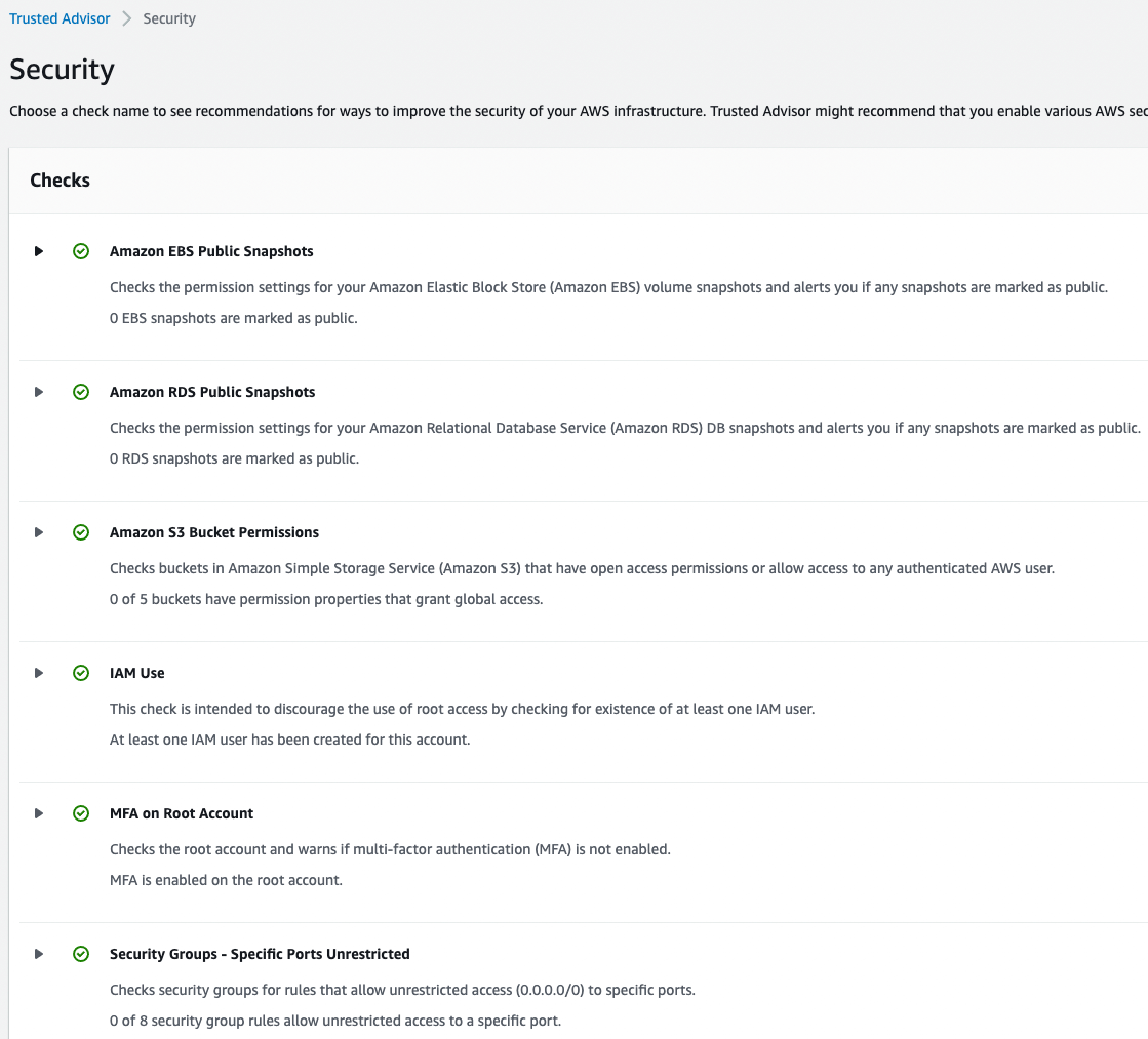
AWS Trusted Advisor 서비스도 모니터링 용도로 사용하기 좋습니다. AWS 계정을 분석하여 보안, 비용, 운영 측면에서 어떤 개선을 할 수 있는지 권장 사항을 알려주는 서비스입니다.
아래는 Trusted Advisor를 실행한 결과입니다. 지면상 생략했지만 다른 부분들도 검사해 줍니다.
로깅 및 모니터링 영역에서는 앞서 살펴본 것과 같은 기술적인 조치를 중점적으로 다룹니다. 하지만 모니터링으로 끝나서는 안 됩니다. 모니터링을 통해 얻은 결과가 담당자에게 빠르게 전달되고, 담당자가 효과적으로 대응할 수 있도록 하는 관리적 프로세스가 구성되어야 모니터링의 효과가 드러납니다. 이와 같은 관리적 프로세스에 대해서는 세 번째 글의 사고 대응 영역에서 자세히 논하도록 하겠습니다.
데이터 보호 영역은 클라우드상에서 다루는 모든 데이터를 암호화 등의 기술적 조치를 통해 안전하게 저장하고 전송하는 것을 목표로 합니다. 특히 핑퐁팀과 같이 인공지능을 연구하는 기업의 경우 데이터 보호는 더욱 중요합니다.
핑퐁팀에서 데이터 보호 영역 강화를 위해 적용한 내용을 소개하겠습니다.
클라우드를 활용해 서비스를 운영하면 다양한 유형의 데이터가 네트워크를 통해 전송됩니다. 네트워크를 통해 전송한 데이터는 라우터나 스위치 등 수많은 장치를 거쳐 목적지에 도달합니다. 이 과정에서 데이터 도청 및 위변조를 방지하기 위해 암호화는 필수적입니다.
먼저 AWS 외부로부터 들어오는 HTTP 요청을 암호화해야 합니다. 핑퐁팀에서는 외부로부터 HTTP 요청을 받기 위해 2가지 서비스를 사용하고 있습니다. 홈페이지와 같이 정적인 콘텐츠를 제공하는 경우에는 CloudFront, 동적인 콘텐츠를 제공하는 경우는 EC2 ALB를 사용합니다.
ALB와 CloudFront 모두 인증서를 이용해 TLS 연결을 할 수 있도록 지원하고 있습니다. AWS Certificate Manager(이하 ACM) 서비스에서 원하는 도메인에 대한 인증서를 생성한 뒤, 각 서비스에 연결하면 이 인증서를 이용해 TLS 통신을 하게 되어 서비스로 들어오는 트래픽이 보호됩니다. (핑퐁팀에서는 사용하고 있지 않지만 API Gateway 서비스에도 적용 가능합니다.)
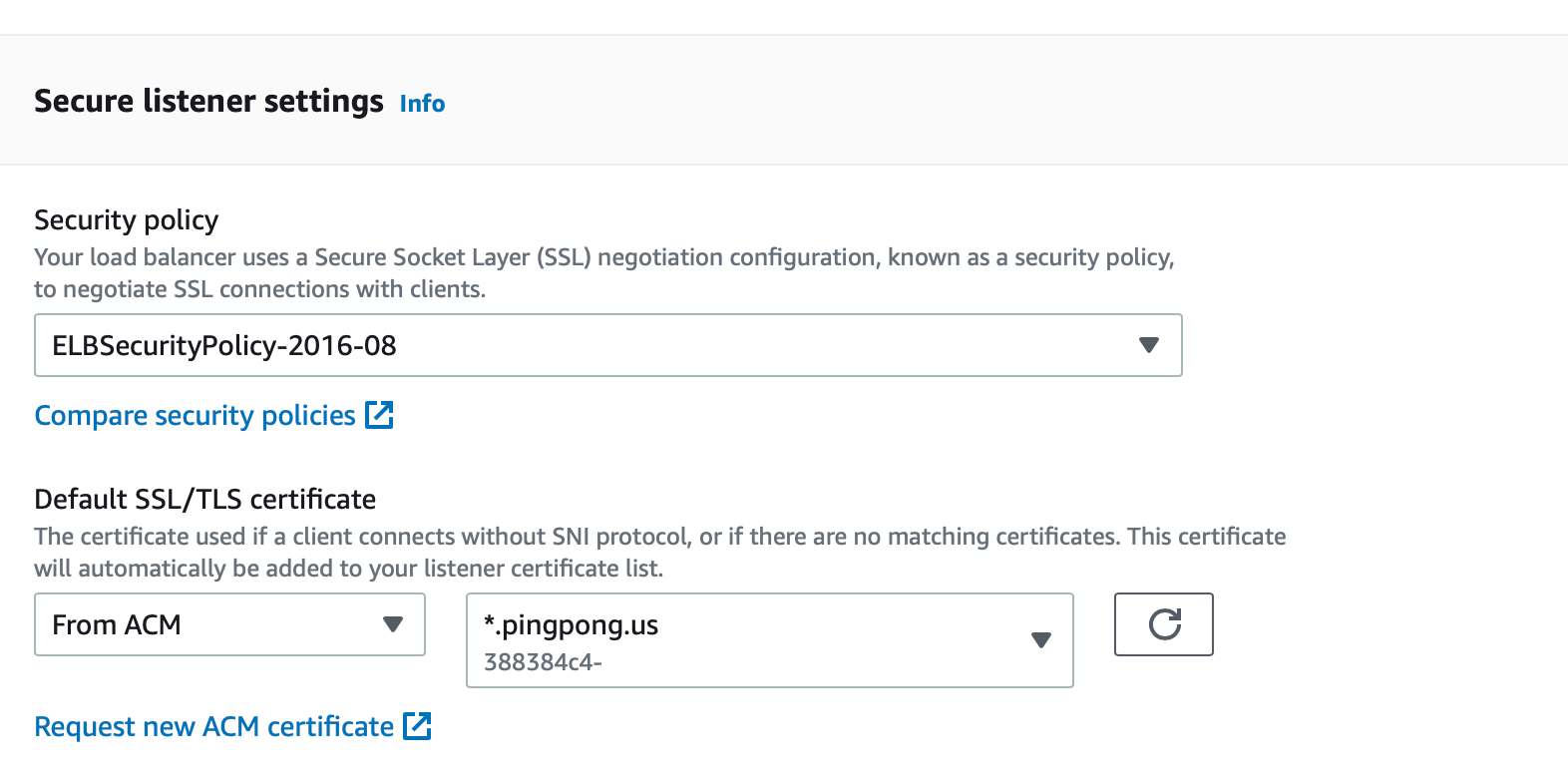
ALB와 CloudFront에서는 HTTP 요청을 받았을 때 자동으로 HTTPS로 Redirect하는 Redirect HTTP to HTTPS라는 기능을 제공합니다. 이 기능을 사용하면 TLS 통신을 강제하여 모든 요청을 보호할 수 있기 때문에 항상 활성화하는 것을 권장합니다. 더 나아가 위에서 소개한 AWS Config 서비스를 통해 Redirect HTTP to HTTPS가 설정되어 있지 않은 ALB 및 CloudFront 리소스를 탐지하고 자동으로 수정해주도록 하여 Continuous Compliance를 달성할 수 있습니다.
AWS의 각 서비스마다 인증서 리전 제약 조건이 있기 때문에 ACM을 통해 인증서를 생성할 때는 리전에 대한 고려가 필요합니다. 예를 들어 ALB와 같이 같은 리전의 인증서만 연결할 수 있는 서비스가 있고, 글로벌 서비스인 CloudFront의 경우 ACM 인증서를 반드시 버지니아 북부 리전(us-east-1)에 배포해야 합니다.
외부로부터 들어오는 요청뿐만 아니라 VPC 내부에서 주고받는 데이터도 암호화 대상입니다. 만약 VPC 내부에서 다양한 서비스, 그리고 DB와 같은 컴포넌트들이 서로 통신하며 데이터를 주고받는다면 TLS를 통해 데이터를 보호해야 합니다.
특히 AWS Aurora, DocumentDB와 같은 관리형 데이터베이스의 경우, 자체적으로 제공하는 TLS 보안 기능을 사용할 수 있습니다. DocumentDB를 예로 들자면, 클러스터에 tls,ParameterValue=enabled,ApplyMethod=pending-reboot 파라미터를 설정하여 TLS 통신을 활성화할 수 있습니다. (자세한 내용은 DocumentDB 공식 문서에서 확인할 수 있습니다.)
핑퐁팀에서는 사용하지 않지만 만약 AWS Client VPN을 통해 AWS의 SDN(Software-Defined Network)에 접속하여 통신하는 경우나 AWS PrivateLink를 통해 On-Premise와 VPC를 연결하는 경우에도 주고받는 모든 요청을 암호화할 것을 권장합니다.
데이터를 보관할 때도 기술적인 조치를 적용하여 데이터를 안전하게 보호해야 합니다. 대표적으로 데이터를 암호화해서 저장하면 데이터 유출 사고가 발생하더라도 데이터 유출로 인한 피해를 최소화할 수 있습니다.
AWS에서 데이터 보관을 위해 가장 많이 사용하는 서비스인 S3 위주로 암호화 기능을 소개하겠습니다.
S3에서는 파일을 안전하게 저장할 수 있도록 서버 측 암호화(Server-Side Encryption, SSE)를 제공하고 있습니다. S3 버킷에서 암호화 기능을 활성화하면 S3에서 파일을 올리거나 다운받을 때 AWS 내부에서 관리되는 암호화 키를 이용해 자동으로 암호화/복호화를 하게 됩니다.
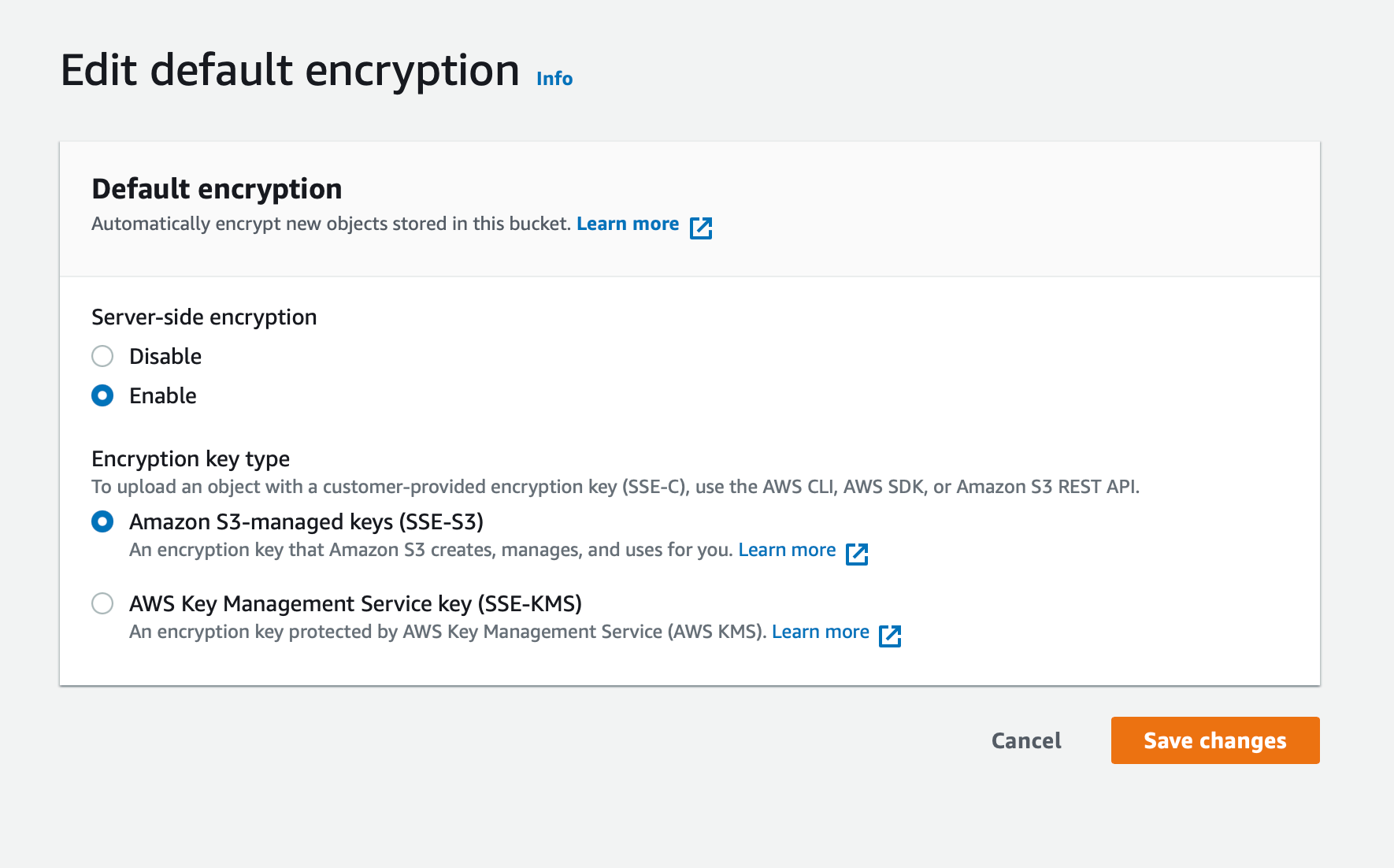
S3에서 제공하는 SSE에는 2가지 옵션이 있습니다. S3가 암호화 키를 관리하는 옵션과 AWS Key Management Service(이하 KMS)를 통해 암호화하는 옵션이 있는데, 각 옵션의 특징은 다음과 같습니다.
SSE는 S3 버킷뿐만 아니라 RDS, EBS Volume, ECR Repository 등 데이터를 보관할 수 있는 대부분의 서비스에서 제공하고 있습니다.
AWS에서 제공하는 SSE는 단점이 하나 존재합니다. 만약 개발자의 인증키가 유출되는 경우, 키를 취득한 공격자가 데이터에 접근하더라도 AWS 입장에서는 사용자를 구분할 수 없기 때문에 공격자가 파일을 다운로드할 수 있게 됩니다. 이러한 사고에서 데이터 유출을 방지하기 위해 파일 업로드할 때 별도의 암호화 키로 암호화하고, 다운로드할 때 복호화하는 클라이언트 측 암호화(Client-Side Encryption, CSE)를 도입할 수 있습니다.
물론 별도로 암호화 키를 관리하고, 파일을 다루기 위해 암/복호화 로직을 추가해야 하는 등 매우 큰 노력과 비용이 소모되지만 중요한 데이터 또는 자주 접근하지 않는 데이터인 경우 CSE는 SSE와 더불어 보안 수준을 높이기 위한 좋은 선택지가 될 수 있습니다.
암호화 키를 편리하게 관리하고자 하드코딩하거나 Docker 이미지 내에 넣어두고 이를 잊어버려 외부에 공개되는 보안 사고는 지금까지도 자주 발생합니다. 이처럼 서비스 개발 과정에서 사용할 암호화 키를 관리하는 것은 굉장히 까다롭습니다. 서비스에서 암호화 키를 안전하게 관리하기 위해 KMS를 활용하는 방법을 소개합니다.
KMS는 봉투 암호화를 이용해 암호화 키를 안전하게 관리합니다. 봉투 암호화는 암호화 키 자체를 봉투 암호화용 키로 한 번 더 암호화하여 암호화 키를 보호하는 방법입니다. 이때 봉투 암호화용 키는 KMS에서 관리하므로 키 유출의 위험이 적습니다. 사용자는 KMS 키의 ID와 키를 사용할 수 있는 권한만 갖고 있으면 KMS에 요청해 데이터를 암/복호화할 수 있게 됩니다.
하지만 암호화할 데이터의 용량이 너무 큰 경우 KMS에 요청을 보내기 어려울 수 있습니다. 이 경우에는 데이터 키 방식을 사용해 클라이언트 측에서 직접 데이터를 암호화할 수 있습니다.
데이터 키 방식은 데이터를 암호화하기 위한 ‘데이터 키’와, KMS 내부에서 관리하는 키로 데이터 키를 암호화한 ‘암호화된 데이터 키’를 사용합니다. 클라이언트는 데이터 키를 통해 데이터를 암호화하고, 암호화된 데이터 키와 함께 저장하는 방식으로 암호화 과정을 처리하며, 복호화 시 암호화된 데이터 키를 KMS에 요청해 실제 데이터 키를 받아 클라이언트에서 직접 복호화하게 됩니다.
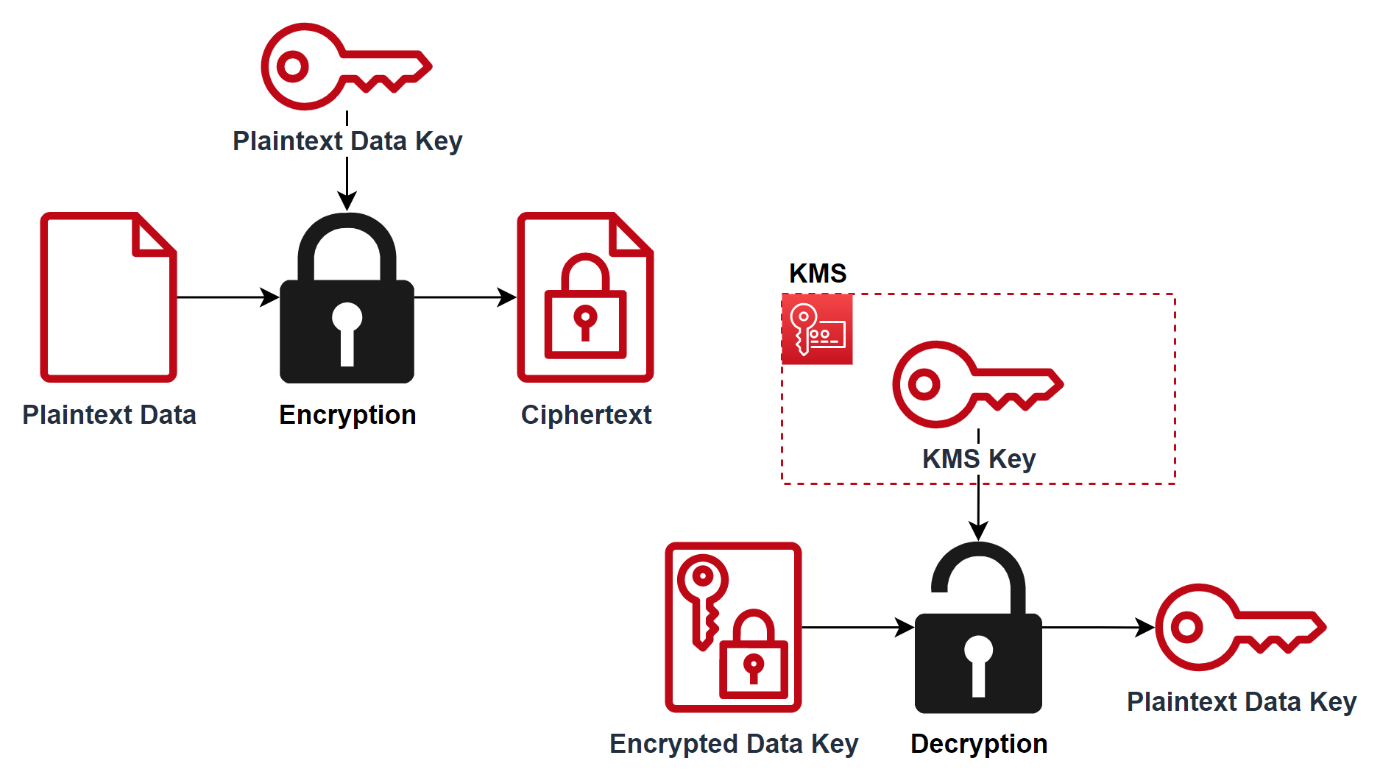
데이터 키 방식을 활용해 파일을 암호화하여 업로드/다운로드하는 데모 앱을 개발했으니, 구현 레벨에서의 이해가 필요할 경우 참고하시면 좋을 것 같습니다.
KMS의 장점은 자동 키 교체입니다. 암호화 키 유출로 인한 영향 범위를 최소화하기 위해 암호화 키를 주기적으로 교체하는 것을 권장하는데, KMS에서는 이를 주기적(1년)으로 자동으로 교체해줍니다. 하지만 암호화 키의 ID는 동일하기 때문에 기존과 동일한 설정에서 동일한 방법으로 암호화 키를 관리할 수 있습니다. 작동 방식이 궁금하시다면 공식 문서를 참고해주세요.
데이터는 그 유형에 따라 필요한 보호 수준이 달라질 수 있습니다. 예를 들어 중요한 비즈니스 지표나 사용자의 개인정보는 다른 데이터에 비해 더 강화된 기준이 필요합니다. 하지만 생성되는 모든 데이터의 암호화 여부나 접근 권한을 일일이 지정할 수는 없습니다. 데이터를 효율적으로 관리하기 위해서는 명확한 정책을 수립하고 팀 전체에 공유해야 합니다.
데이터를 그 중요도에 따라 분류하면 중요도별로 암호화 여부, 접근제어 등 데이터 보호 정책을 달리 적용할 수 있습니다. 데이터 분류 기준이 명확히 정의되면 다음과 같이 데이터 분류표를 작성할 수 있어야 합니다.
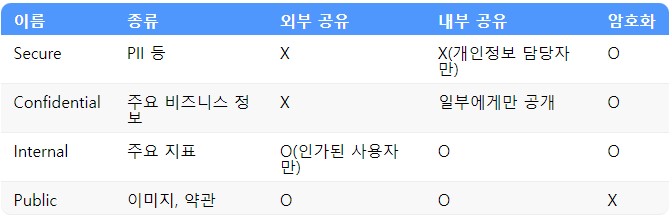
단계는 최소 3단계부터 최대 5단계까지 분류하는 것을 추천합니다. 3개 미만이거나 5개 초과인 경우에는 각 단계에 맞는 적절한 관리 기준을 설정하기 어려워 데이터를 효율적으로 관리하기 어려울 수 있습니다.
개인정보와 같이 민감한 정보는 별도의 분류 정책을 수립하여 더 높은 수준의 데이터 보호 및 관리 방안을 설정해야 합니다. 개인정보가 저장된 S3 버킷은 항상 암호화를 적용하고 Config 서비스를 통해 지속적으로 확인하며, 애초에 개인정보처리자 이외의 사용자는 개인정보가 포함된 S3 버킷에 접근조차 할 수 없도록 설정하는 등의 노력이 필요합니다.
AWS에서 생성하는 모든 리소스는 태그를 붙일 수 있고, IAM 권한을 부여하거나 AWS Config를 통해 보안 규정 준수 정책을 만들 때 활용할 수 있습니다. 실제 태그를 활용하여 데이터를 효율적으로 관리하는 사례들을 소개합니다.

s3:CreateBucket) 데이터 분류 태그가 붙어있지 않으면 버킷 생성 불가
시리즈의 마무리를 장식할 다음 글에서는 나머지 2개 영역인 인프라 보안 영역과 사고 대응 영역을 소개하겠습니다.
<원문>
개발자를 위한 AWS 클라우드 보안 (2) - 로깅 및 모니터링과 데이터 보호
©️요즘IT의 모든 콘텐츠는 저작권법의 보호를 받는 바, 무단 전재와 복사, 배포 등을 금합니다.