개발
화해의 Data Warehouse를 소개합니다

5분
2022.06.28.4.9K
국내 유명 IT 기업은 한국을 넘어 세계를 무대로 할 정도로 뛰어난 기술과 아이디어를 자랑합니다. 이들은 기업 블로그를 통해 이러한 정보를 공개하고 있습니다. 요즘IT는 각 기업의 특색 있고 유익한 콘텐츠를 소개하는 시리즈를 준비했습니다. 이들은 어떻게 사고하고, 어떤 방식으로 일하는 걸까요?
이번 글은 국내 화장품 시장의 정보 비대칭 문제를 해결하고 소비자 중심의 뷰티 시장을 만들어 가고 있는 ‘화해’의 데이터팀 이야기입니다. 화해에서 데이터를 활용하는 과정에서 겪은 문제와 이를 해결하기 위해 구축한 Data Warehouse(DW)에 관해 소개합니다.
안녕하세요. 화해 데이터팀 BI/DW 엔지니어 최혜림입니다.
화해팀에는 다양한 직군이 있지만, 대부분의 직군이 업무에 데이터를 활용하고 있는 공통점이 있습니다. 데이터팀에서는 화해팀이 데이터를 더 쉽게, 더 잘 접근할 수 있도록 환경을 구축하고, 데이터 기반 의사결정을 위한 분석을 진행하고, 고객과 비즈니스의 문제 해결을 위한 알고리즘을 개발하는 등의 업무를 하고 있습니다.
지난번 DevDay에서 화해에서 데이터를 활용하는 과정에서 겪은 문제와 그 문제를 해결하기 위해 어떤 고민을 거쳐 Data Warehouse(DW)가 구축되고 있는지 소개하는 세션을 진행했는데, 당시의 발표 자료를 다듬어서 이번 콘텐츠를 통해 전달하겠습니다.
화해의 서비스들은 여러 개의 Database(DB)로 나뉘어서 구동되고 있습니다. 대표적인 게 제품 정보를 담고 있는 DB(이하 제품 DB)와 화해쇼핑과 관련된 정보를 담고 있는 DB(이하 쇼핑 DB)입니다. 화해 앱에서 각각 홈 화면의 제품 정보 부분과, 화해쇼핑 부분이라고 생각하시면 됩니다. 이 두 DB를 예시로 DW 구축까지 어떤 단계를 거쳐서 왔는지 소개하겠습니다.
데이터 소스가 원천 데이터(DB 및 Log)밖에 없던 시점입니다. 브랜드별 매출액을 추출하려면 제품 DB의 제품/브랜드 정보와 쇼핑 DB의 상품/제품/매출 정보를 각각 추출해 로컬에서 R, Python, Excel 등의 도구를 이용해 합치는 단계를 거쳤습니다.
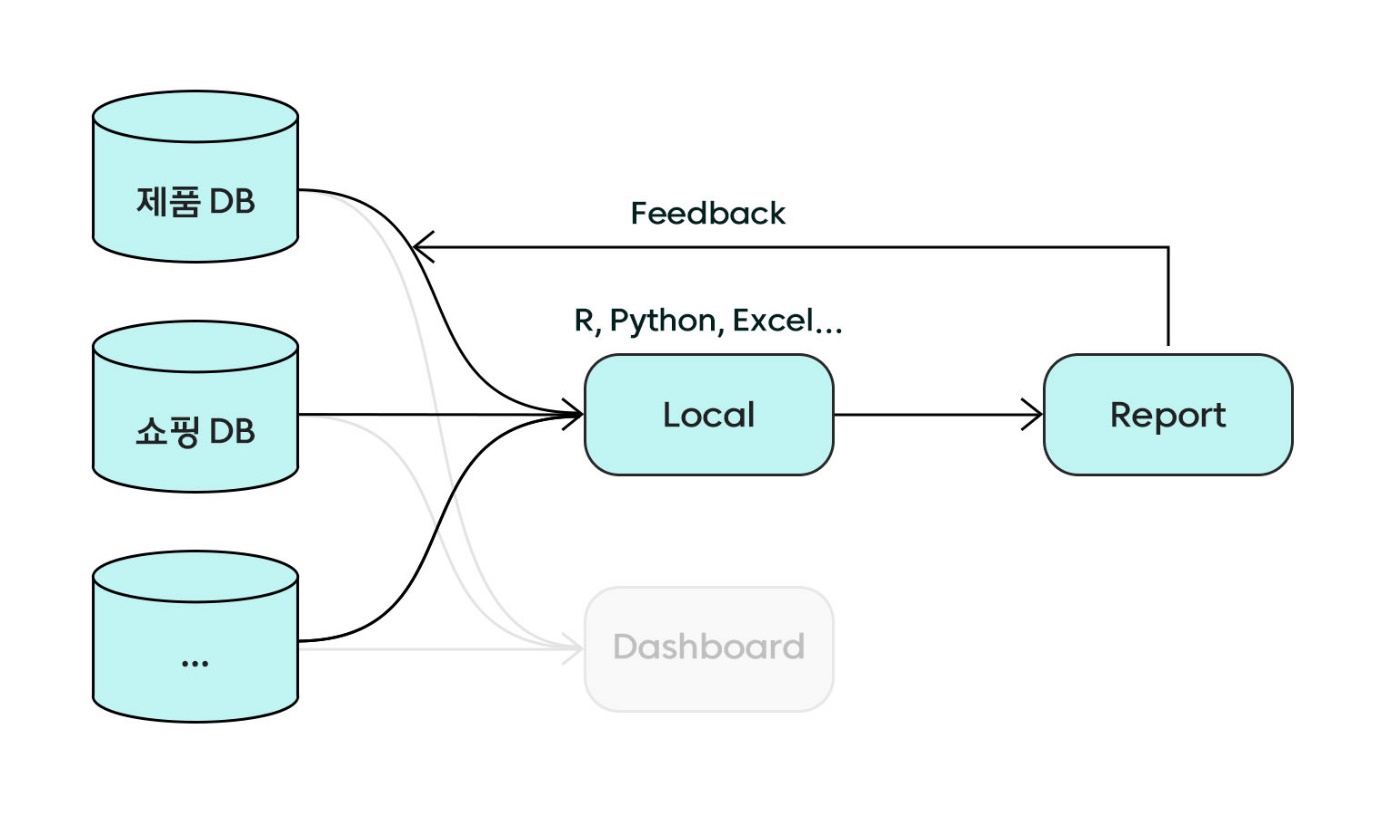
단순한 데이터만 필요할 때는 큰 문제가 없으나, 긴 기간의 통계 데이터나 리텐션 등 복잡한 통계 데이터를 추출하기에는 운영 DB의 부하 문제, 로컬 컴퓨터의 리소스 문제가 있습니다. 무엇보다도 가장 큰 문제는 데이터를 분석하기보다 추출하는데 더 많은 시간이 소모되는 것이었습니다.
보통 분석은 한두 번의 데이터 추출로 끝나지 않는 경우가 많아서 이 과정을 계속 반복해야 하는 것 또한 문제였습니다. 그래서 화해팀에서는 당시에 이용하고 있던 AWS의 Redshift를 이용해 Data Lake를 구축하기 시작합니다.
‘Redshift’라는 한 통에 주요 원천 데이터를 원천 데이터의 스키마와 거의 동일하게 저장해 놓았던 단계입니다. 이 단계에서 운영 DB 부하 문제와 로컬 컴퓨터의 리소스 문제는 해결되었지만, 필요로 하는 데이터의 테이블 및 컬럼, 다른 테이블과의 JOIN Key, 데이터가 쌓일 때의 비즈니스 로직 등을 파악하고 쿼리를 작성해야 하는 불편함이 있었습니다.
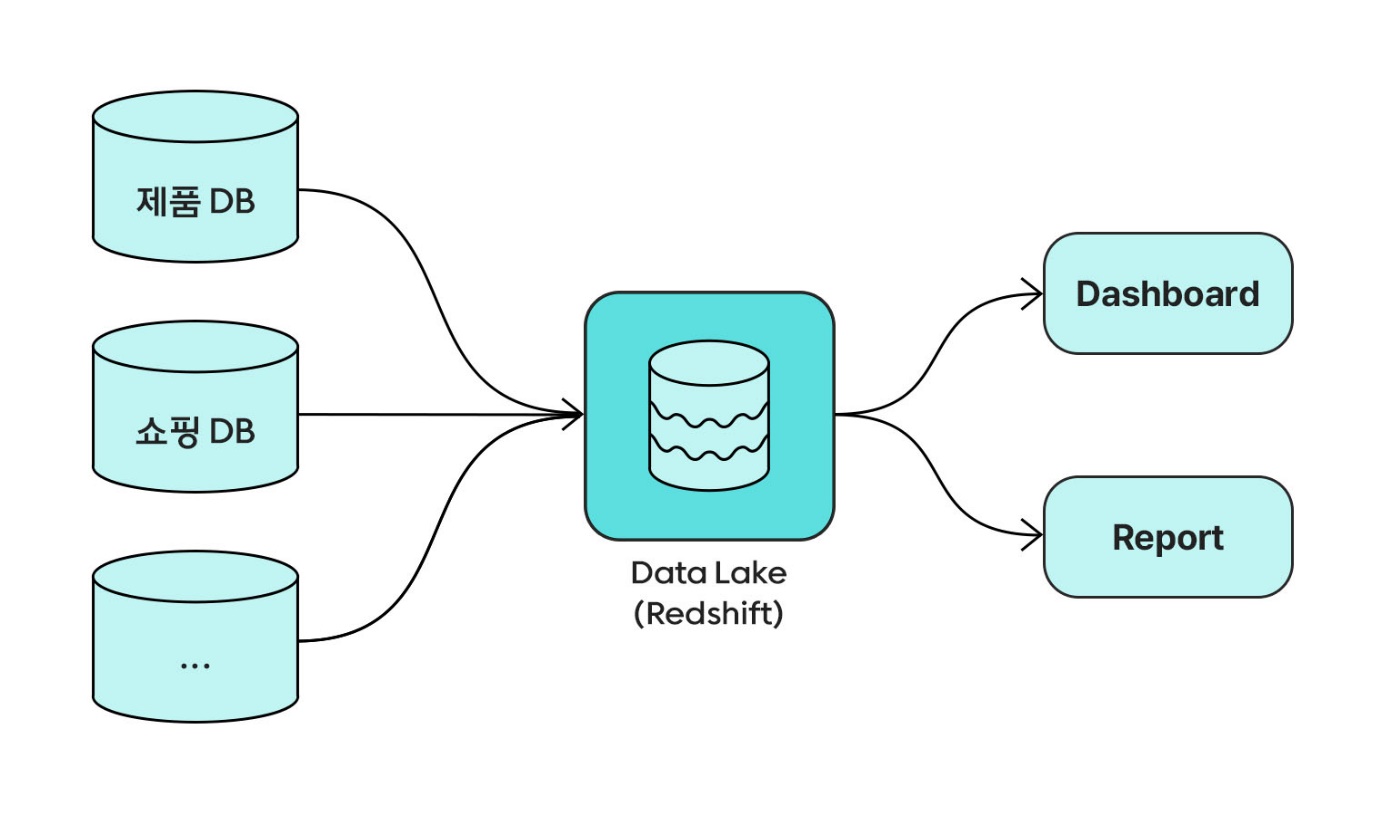
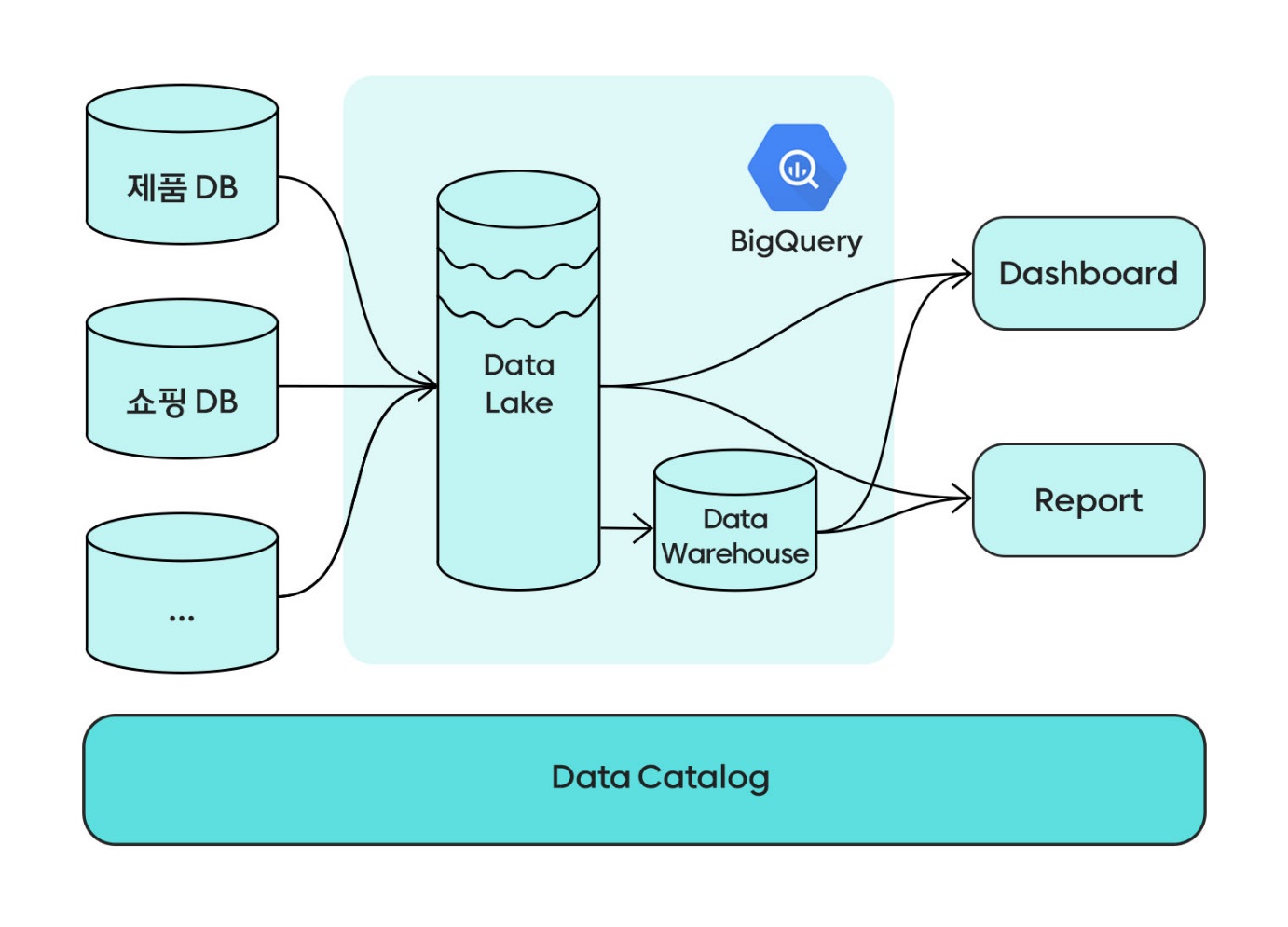
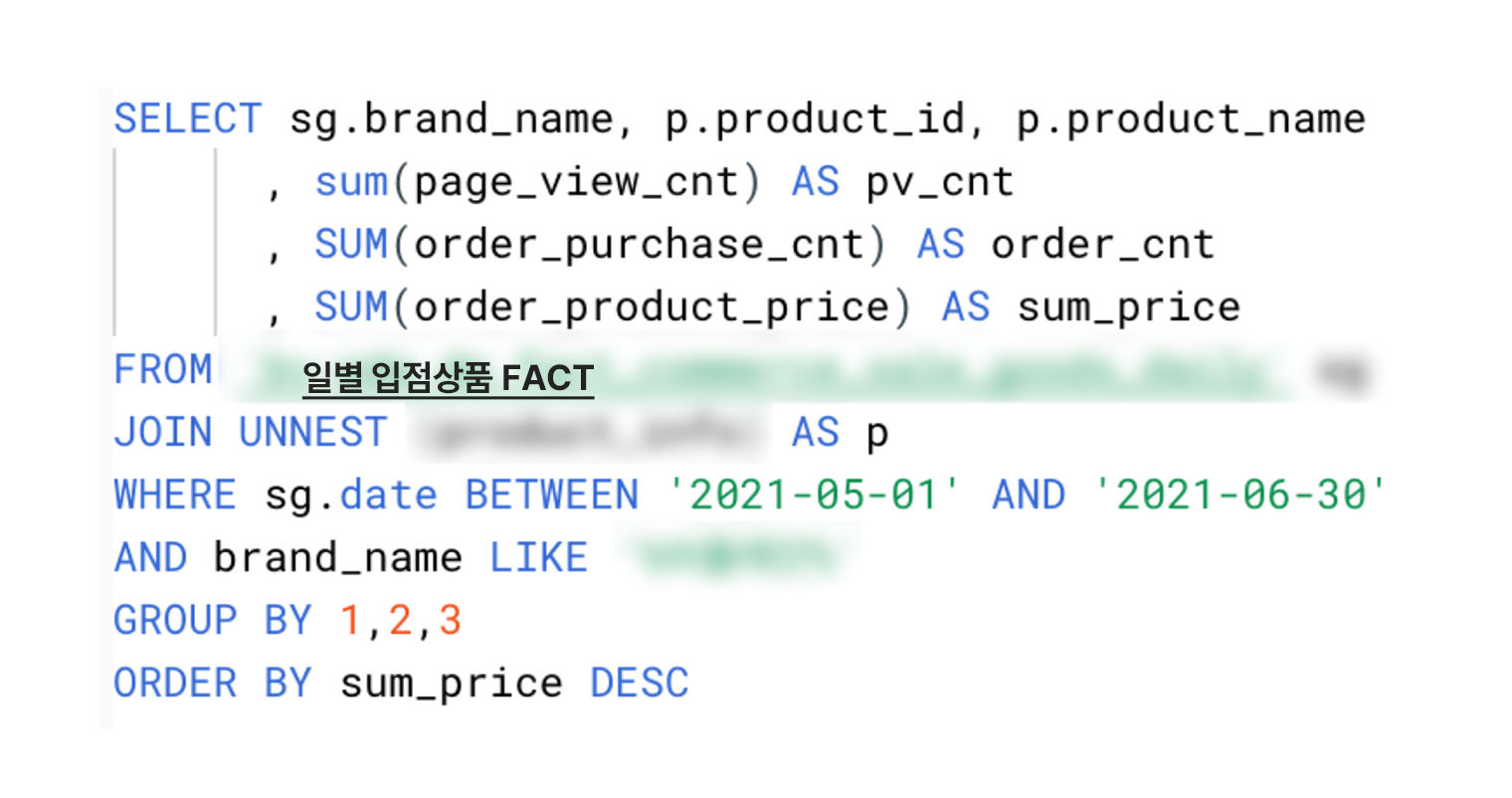
아래 그림은 초기의 Data Lake 구조와 이 구조에서 사용된 쿼리 예시입니다.
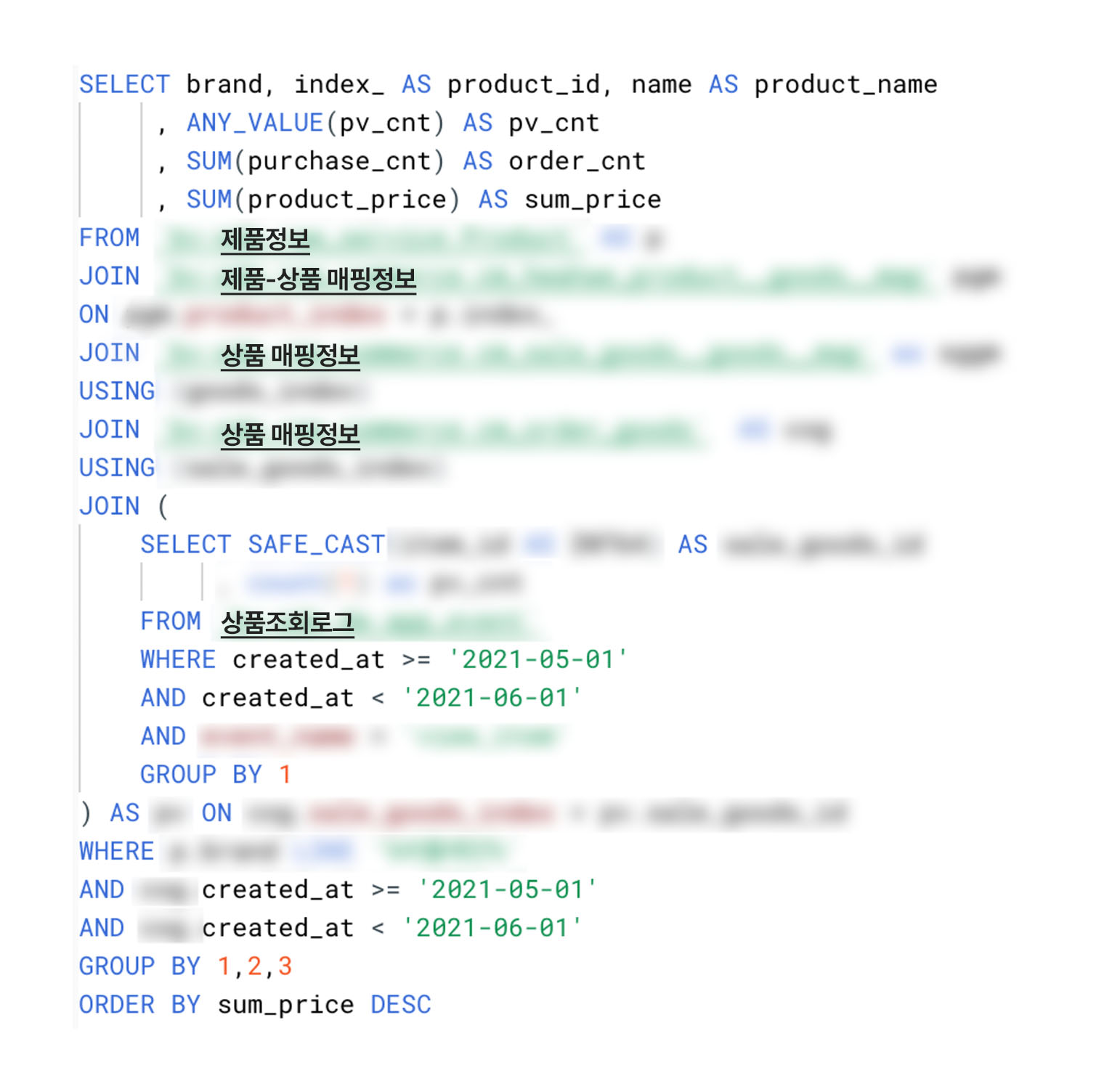
원천 데이터와 스키마가 거의 동일하고, RDB 특성상 여러 단계의 정규화를 거친 스키마 구조를 가지고 있어 여러 번의 조인을 거쳐야 원하는 데이터를 획득할 수 있었습니다. 또한 데이터 사용자가 각자 파악한 비즈니스 로직에 따라 데이터를 추출하다 보니 지표의 기준이 통일되지 않는 것도 문제였습니다.
이런 반복되는 쿼리를 효율화하고 비즈니스 로직 파악에 걸리는 시간을 단축하기 위해 자주 사용되는 쿼리 결과를 미리 테이블로 저장해 초기의 DW가 만들어졌습니다.
‘Redshift’에 있던 Data Lake와 초기 DW 테이블을 ‘BigQuery’로 이관하고, 좀 더 체계적인 DW를 구축하기 위한 논의가 시작된 단계입니다. 제가 화해팀에 합류하게 된 시점도 이 시기였습니다. 또한 이 시기에 데이터 엔지니어 파트에서 테이블, 컬럼에 대한 정의와 DW 생성 로직을 쉽게 파악할 수 있도록 데이터 카탈로그를 구축해 주셔서 테이블이 담고 있는 데이터에 대한 설명도 쉽게 찾아볼 수 있게 되었습니다.
간단히 구조를 도식화하면 아래와 같습니다. 원천 소스에서 데이터를 Data Lake로 가져오고, 가져온 데이터를 가공하여 DW 테이블을 생성합니다. 이 과정에서 데이터 카탈로그를 참조하기도 하고, 결과물을 업데이트하기도 합니다.
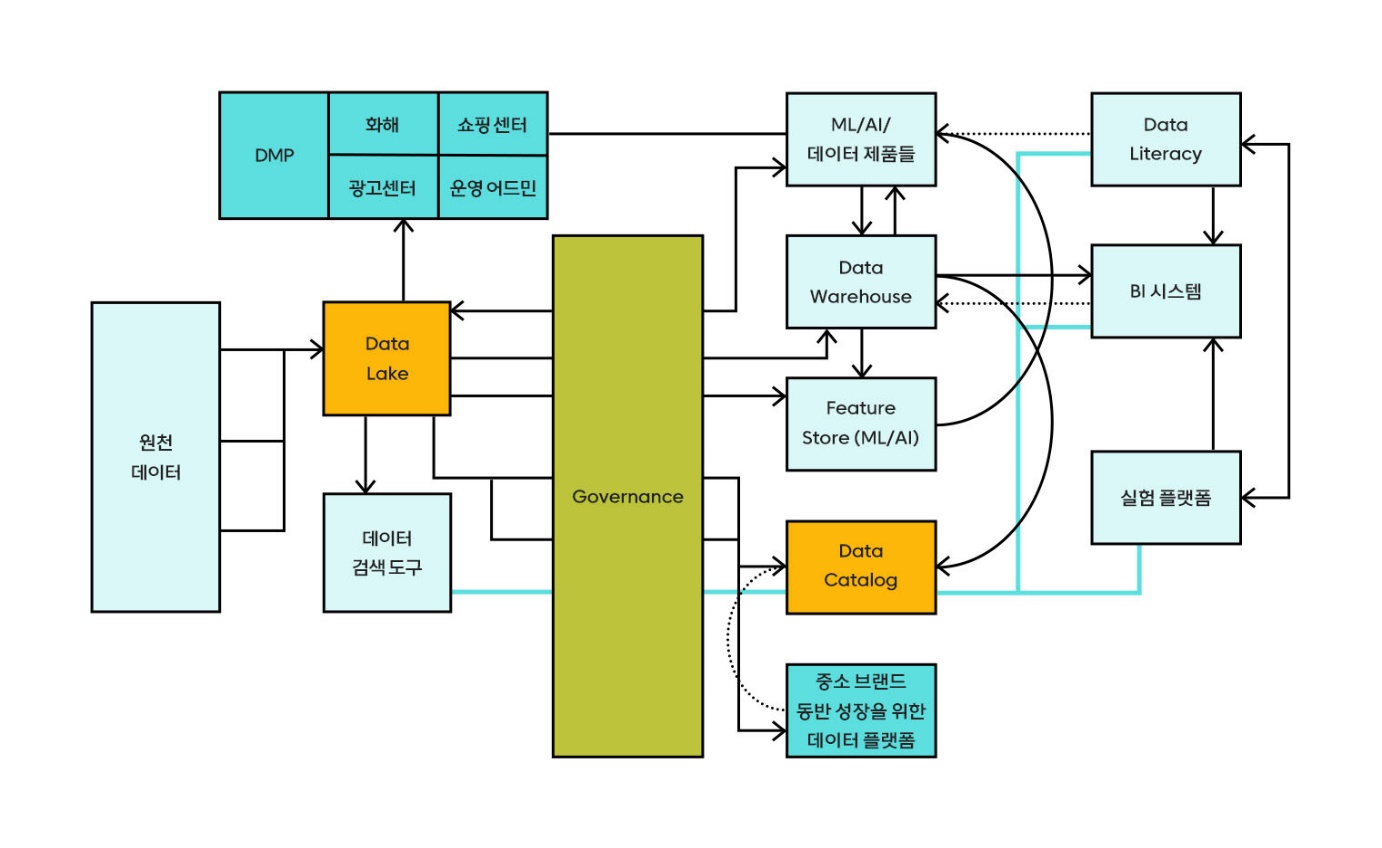
현재의 DW를 구축하기 위해 주제 영역을 잡고, 대시보드 쿼리와 분석에 사용되는 쿼리를 분석하고, 공통으로 자주 쓰이는 Dimension과 Metric을 정의했습니다. 조인이 많이 일어나는 상황을 피하기 위해 디멘전 테이블을 별도로 만드는 케이스는 최소화하고 최대한 반정규화된 FACT 테이블을 설계했습니다. 또한, 이용자가 특정 시점의 데이터임을 명확하게 인지할 수 있도록 테이블마다 기준일자 컬럼을 추가했고, 모수에 대한 정의를 카탈로그에 업데이트했습니다.
현재 4가지 주제 영역에 대해 약 20여 개의 FACT 테이블이 있으며, 대시보드 및 분석에 활발하게 사용되고 있습니다. FACT 테이블은 기존에 데이터를 탐색하던 시간과 복잡한 쿼리로 인한 오류를 많이 줄여주었고, 일관된 기준으로 특정 시점의 지표를 정확하게 측정할 수 있게 해 주었습니다. 자주 추출하는 지표의 경우, 조인이 없어지면서 단순한 쿼리로 원하는 데이터를 확인할 수 있게 되었습니다. 물론 모든 데이터를 DW가 커버할 수는 없으므로 자주 쓰이지 않는 지표들은 Data Lake를 통해서 조회하고 있습니다.
데이터를 확인하는 로직이 단순해질수록 데이터 접근에 대한 장벽은 낮아지기 때문에 자주 쓰이면서 조회가 복잡한 데이터는 FACT 테이블로 생성하기 위한 Backlog에 넣어두었습니다.
주제 영역을 확장해 나가는 것과 동시에 구축된 DW의 데이터를 쉽게 활용할 수 있도록 데이터 카탈로그 기능을 추가하고, 전사 BigQuery 교육 및 데이터 리터러시 교육을 계획하고 있습니다. 데이터를 원하는 화해팀이라면 누구나 쉽게 데이터를 찾아보고, 소비할 수 있도록 하는 것이 목표입니다.
DW가 생기기 전, 데이터 분석을 하려면 데이터 준비를 위한 리소스가 많이 소모되어서 정작 중요한 분석에는 집중할 리소스가 부족해지는 문제가 있었습니다. DW의 주제 영역별로 정리된 테이블들은 이런 데이터 준비에 걸리는 시간을 줄여주고, 데이터 사용자가 본질적인 업무에 집중할 수 있도록 도와주는 역할을 합니다.
DW가 없어도 데이터를 사용하는 게 불가능하지는 않습니다. 다만 비즈니스가 점점 확장되고, 조직이 확대되면서 신규 인원이 계속해서 유입되면 될수록 데이터 준비에 드는 리소스가 늘어나는 문제가 있습니다.
과거에 DW와 BI는 경영진과 공유하는 자료를 작성하는 용도로 주로 사용되었지만, 요즘은 화해팀 구성원 모두가 데이터에 접근할 수 있는 환경이 되었습니다. 잘 정리된 DW가 많은 사람의 수고를 줄여주고, 이에 따라 데이터에 더 쉽게 접근할 수 있으며, 나아가 일상적으로 데이터를 보고 의사결정을 할 수 있는 기반이 된다고 생각합니다.
DW를 포함한 화해의 데이터 플랫폼은 화해팀이 일상적으로 데이터를 소비할 수 있도록 계속해서 발전하고 있습니다. 앞으로도 기대해 주세요! (오셔서 함께하시면 더욱 좋습니다)
지금까지 읽어주셔서 감사합니다.
<원문>
©️요즘IT의 모든 콘텐츠는 저작권법의 보호를 받는 바, 무단 전재와 복사, 배포 등을 금합니다.