개발
단일 프로세스에서 NUMA가 야기한 성능 저하

9분
2022.04.21.6.4K
국내 유명 IT 기업은 한국을 넘어 세계를 무대로 할 정도로 뛰어난 기술과 아이디어를 자랑합니다. 이들은 기업 블로그를 통해 이러한 정보를 공개하고 있습니다. 요즘IT는 각 기업들의 특색 있고 유익한 콘텐츠를 소개하는 시리즈를 준비했습니다. 이들은 어떻게 사고하고, 어떤 방식으로 일하는 걸까요?
이번 글은 ‘전 세계 사람들에게 즐거움을 선사하자’는 비전을 바탕으로 게임을 만들고 있는 ‘넷마블’의 기술분석팀 이야기입니다. NUMA가 무엇인지 알아보고 서버 테스트 과정에서 ‘CPU 쏠림 현상’의 원인을 발견하고 해결해 나간 과정을 공유합니다.
안녕하세요, 넷마블 기술분석팀 고유현입니다.
‘NUMA’라고 들어보셨을까요? NUMA(Non-Uniform Memory Access, 불균일 기억 장치 접근)는 컴퓨터 메모리 설계 방법 중 하나입니다.
2022년을 살아가는 우리가 접하는 PC나 서버는 대부분 멀티코어 CPU를 장착하고 있습니다. 물리적으로는 CPU 1개지만, 그 안에 코어가 여러 개 들어있습니다. 각 코어는 연산을 위해 메모리 컨트롤러를 거쳐 메모리에 접근합니다. 이때, 코어가 메모리에 접근하는 속도를 올리거나 동시 전송량을 늘릴 수 있다면 코어 연산 능력을 높일 수 있습니다. 다만 이들 사이에 오가는 경로 설계 방식으로 인해, 서로 순차 대기해야 하거나 교차로 인한 거리가 증가하면서 병목 현상이 생길 수 있습니다. 또한, 서버 용도로 나오는 메인보드는 CPU를 여러 개 장착할 수 있으므로, 물리적으로 여러 CPU끼리 오가는 경로가 한층 더 쌓입니다.
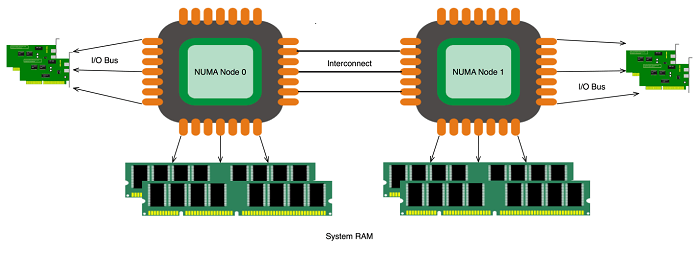
NUMA는 이런 병목 현상을 줄이기 위해 CPU에서 코어가 있는 공간을 독립적인 구획으로 나눠 메모리를 할당하는 방식입니다. 이 독립적인 구획 할당이 NUMA의 특징이자 장단점입니다. (NUMA에 대한 자세한 내용은 아래 링크에서 확인해 주세요.)
이제부터 NUMA가 주는 영향을 살펴보겠습니다.
한창 개발 중이던 서버 성능을 테스트하면서, CPU 쏠림 현상을 접했습니다. 전체 64코어 중 정확히 절반인 32코어에 사용량이 집중됐고, 당연히 목표로 잡은 성능에 도달하지 못하는 이슈가 생겼습니다.
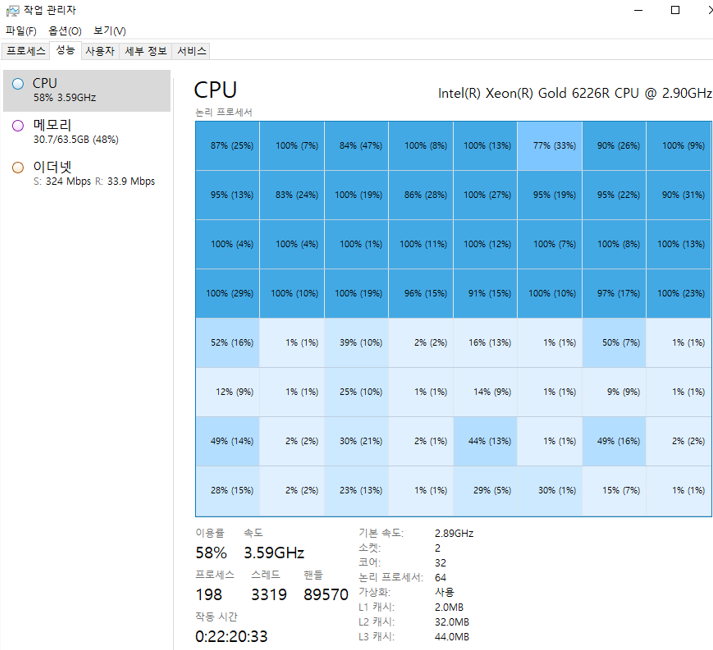
처음에는 NUMA 영향으로 생각하지 못하고, 198로 찍혀있는 프로세스 수가 의심돼 하이퍼스레딩(Hyper Threading)을 활성화했습니다. 하지만, 하이퍼스레딩으로는 해결하지 못했습니다. 그러던 차에 NUMA가 떠올랐고, NUMA를 UMA처럼 동작하도록 Node interleaving 설정을 변경했습니다. Node interleaving 설정을 활성화로 변경하자, 코어 절반에만 몰리던 현상이 해소됐습니다.
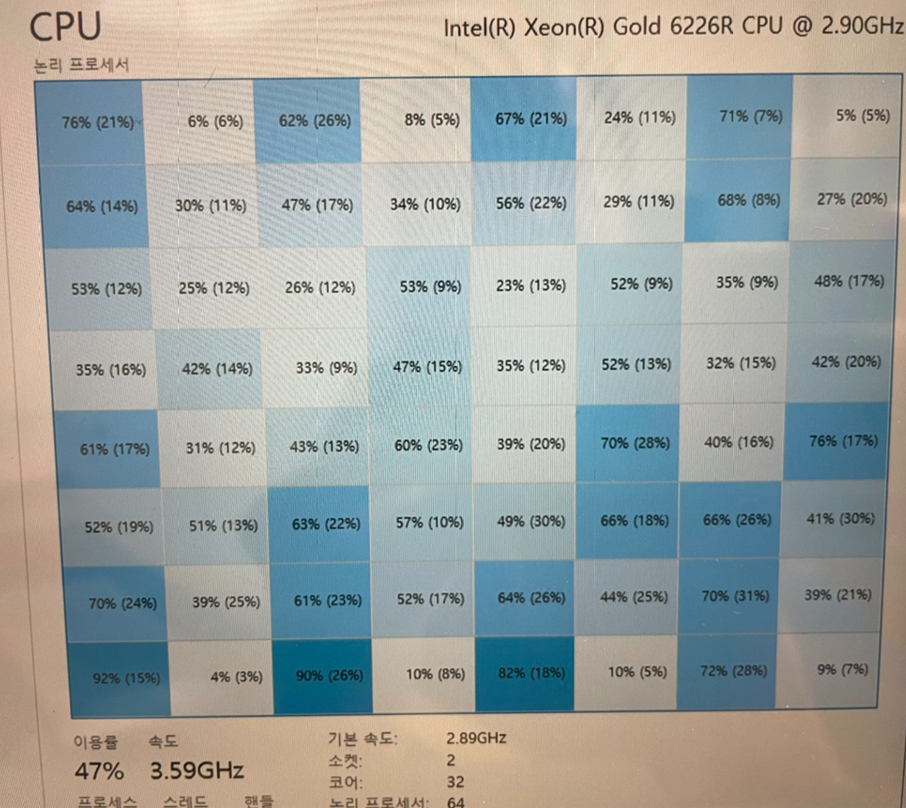
이 CPU 쏠림 현상이 해소된 이유를 더 자세히 알아볼 수 있도록, 상황별로 NUMA가 어떻게 동작하는지 테스트해 보기로 했습니다.
NUMA 옵션으로 인해 단일 프로세스 스레드는 CPU 소켓 하나 안에서만 동작합니다. 이로 인해 쏠림 현상이 발생했다고 가정한다면, 멀티 프로세스 방식으로 프로그래밍해 쏠림 현상을 해소할 수 있습니다. 하지만 단일 프로세스 방식으로 프로그래밍한 작업물을 단시간에 멀티 프로세스 방식으로 변경하기는 쉽지 않고, 다시 처음부터 개발해야 하는 상황이 생길 수도 있습니다.
테스트 환경으로 사용하는 VM이나 일반적인 퍼블릭 클라우드 환경에서는 만나기 힘든 조건일 수도 있습니다. 하지만 MMO 서버를 구성하며 효율과 성능을 끌어올리는 과정에서 마주할 수 있는 문제이므로, 프로그래밍 방식 자체를 바꾸지 않고 분산할 수 있도록 NUMA 불균형을 해소할 방법을 찾기로 했습니다.
사례 조사 결과, 동일한 CPU 소켓에 가용량이 남아 있다면 OS 레벨에서 분배한다는 공식 설명을 찾았습니다. 즉, 단일 프로세스 방식으로 생성한 스레드라고 하더라도, 윈도우 서버에서 설정을 변경해 노드를 분산할 수 있었습니다.
사례조사
윈도우 서버 API 조사
SetThreadAffinityMask function (winbase.h)
SetThreadGroupAffinity function (processtopologyapi.h)
이제부터 실제로 단일 프로세스에서 많은 스레드를 생성했을 때, 같은 소켓 그룹 안에서 분산되는지 확인해 보겠습니다. 또한, 스레드 생성 시점에 그룹을 변경할 수 있는지와 변경할 수 있다면 같은 스레드 별로 미처리 또는 변경하는 시점에 어떤 불균형 현상이 나타나는지도 함께 살펴보겠습니다.
먼저, 스레드 실행 테스트 코드입니다.
void ThreadRun(int node_balancing, int index, int highest_node_number)
{
__lock.lock();
//node 밸런싱 비활성화 시, 그룹 변경 없이 어느 그룹에 할당되는지만 출력
if (node_balancing == 0)
{
GROUP_AFFINITY info;
::GetThreadGroupAffinity(::GetCurrentThread(), &info);
std::cout << "index : " << index << ", "
<< std::this_thread::get_id()
<< " thread use cpu group : " << info.Group
<< ", core affinity : 0x" << std::hex << info.Mask << std::dec
<< std::endl;
}
//node 밸런싱 활성화 시, 그룹을 mod 연산으로 정확히 절반 분배되도록 수행
else
{
GROUP_AFFINITY info;
::GetThreadGroupAffinity(::GetCurrentThread(), &info);
//총 노드 수만큼 모듈러로 분산
info.Group = index % (highest_node_number + 1);
GROUP_AFFINITY prev_info;
::SetThreadGroupAffinity(::GetCurrentThread(), &info, &prev_info);
//최신 정보를 다시 구함.
::GetThreadGroupAffinity(::GetCurrentThread(), &info);
std::cout << "index : " << index << ", "
<< std::this_thread::get_id()
<< " thread use cpu group : " << info.Group
<< ", change groups : " << prev_info.Group << " -> " << info.Group
<< ", core affinity : 0x" << std::hex << info.Mask << std::dec <<
std::endl;
}
__lock.unlock();
//코어 부하 100% 발생하기
int64_t count = 0;
while (__is_thread_run)
{
//release 빌드에서 공란이면 최적화하므로 가벼운 계산을 추가.
count++;
}
}
다음으로 스레드를 생성하는 코드입니다.
int main(int argc, char** argv)
{
if (argc < 2 || argc > 3)
{
std::cout << "Usage : numa_test.exe {thread count}" << std::endl;
return 1;
}
//생성할 스레드 개수
int thread_count = std::atoi(argv[1]);
//노드 밸런싱 여부. 0: 안 함, 그외: 밸런싱 함
int node_balancing = 0;
if (argc == 3) node_balancing = std::atoi(argv[2]);
//해당 머신에서 가장 큰 슬롯 번호
//슬롯 번호는 0부터 시작하며, 값에 +1 을 한 값이 슬롯 수.
ULONG highest_node_number;
::GetNumaHighestNodeNumber(&highest_node_number);
std::cout << "this system has " << highest_node_number + 1 << " nodes." << std::endl;
//스레드 개수 만큼 루프를 돌며 생성.
std::vector<std::thread> thread_list;
for (int i = 0; i < thread_count; i++)
thread_list.emplace_back(ThreadRun, node_balancing, i, highest_node_number);
for (auto& iter : thread_list)
iter.join();
return 0;
}
위 테스트 코드를 실행해 각 케이스별로 CPU 동작 그래프와 스레드 처리가 밀리는지 확인할 수 있는 지표인 프로세서 대기열 길이(Processor Queue Length)를 비교해 보겠습니다.
노드 밸런싱 X/스레드 20
첫 번째, 노드 밸런싱을 비활성화하고 스레드 값을 20으로 설정한 결과입니다.
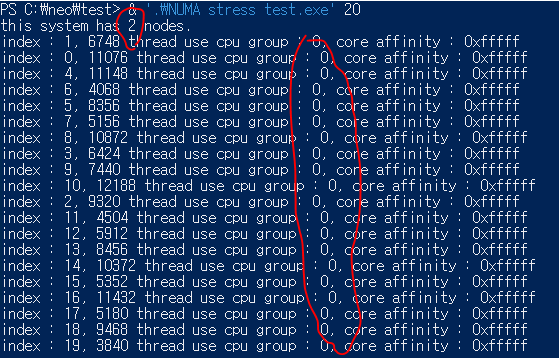
스레드가 CPU 그룹 0번으로만 모두 쏠렸습니다.
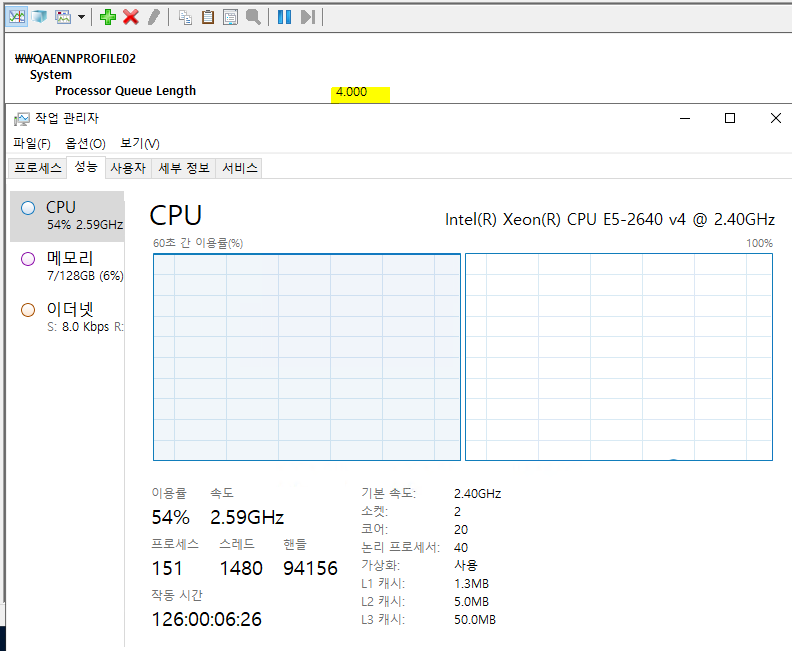
작업 관리자 화면을 보면, 한쪽 노드만 100%를 사용 중이며 총 CPU 사용률은 50%입니다. 프로세서 대기열 길이는 ‘4.000’으로 작은 지연이 있는 정도입니다.
노드 밸런싱 O/스레드 20
두 번째, 노드 밸런싱을 활성화하고 스레드 값을 20으로 설정한 결과입니다.
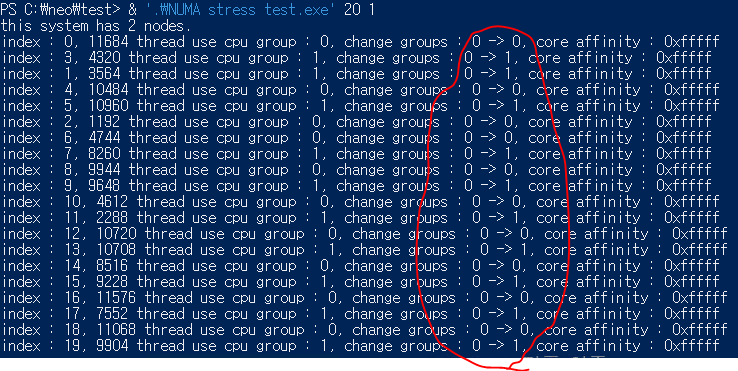
스레드가 CPU 그룹 0번과 1번에 반반씩 분산됐습니다.
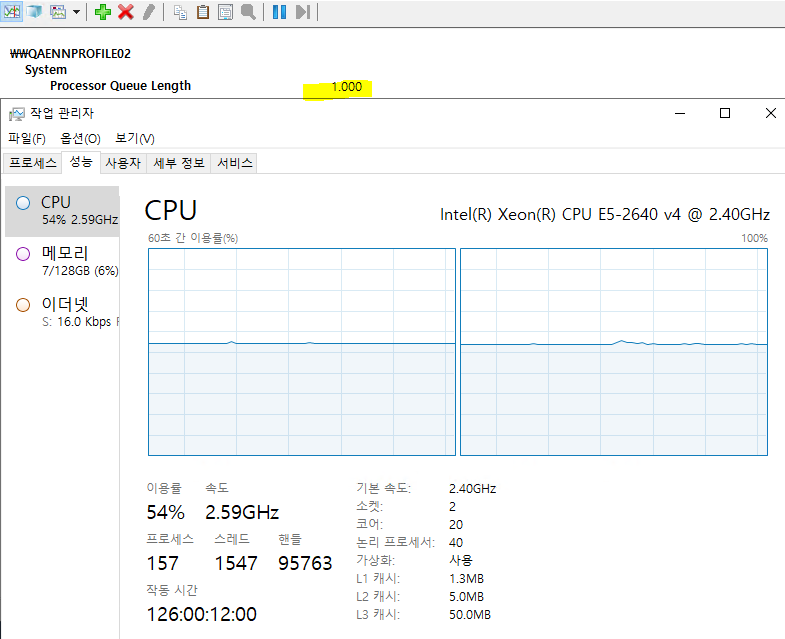
작업 관리자 화면을 보면, 양쪽 노드 각각 50%씩 사용 중이며 총 CPU 사용률은 50%입니다. 프로세서 대기열 길이는 ‘1.000’으로 지연이 거의 없는 정도입니다. 동일한 스레드 값에서 노드 밸런싱을 활성화한 것만으로 확실한 차이가 생긴 것을 볼 수 있습니다.
노드 밸런싱 X/스레드 40
세 번째, 노드 밸런싱을 비활성화하고 스레드 값을 40으로 설정한 결과입니다.
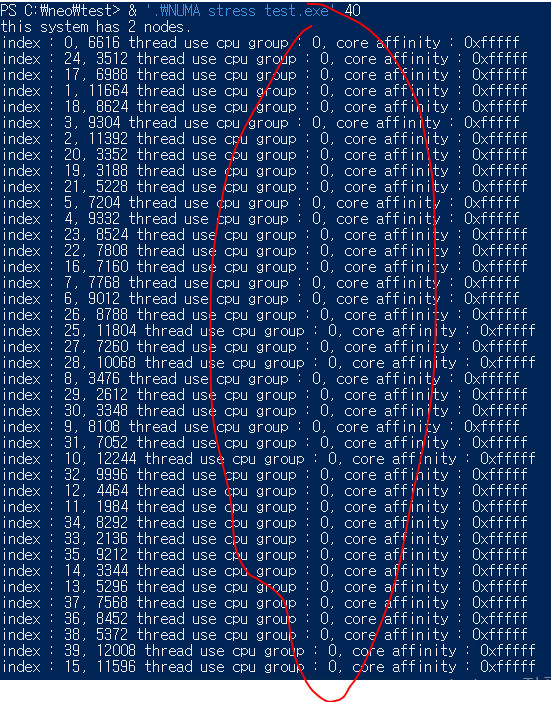
첫 번째 테스트와 마찬가지로, 스레드가 CPU 그룹 0번으로만 모두 쏠렸습니다.
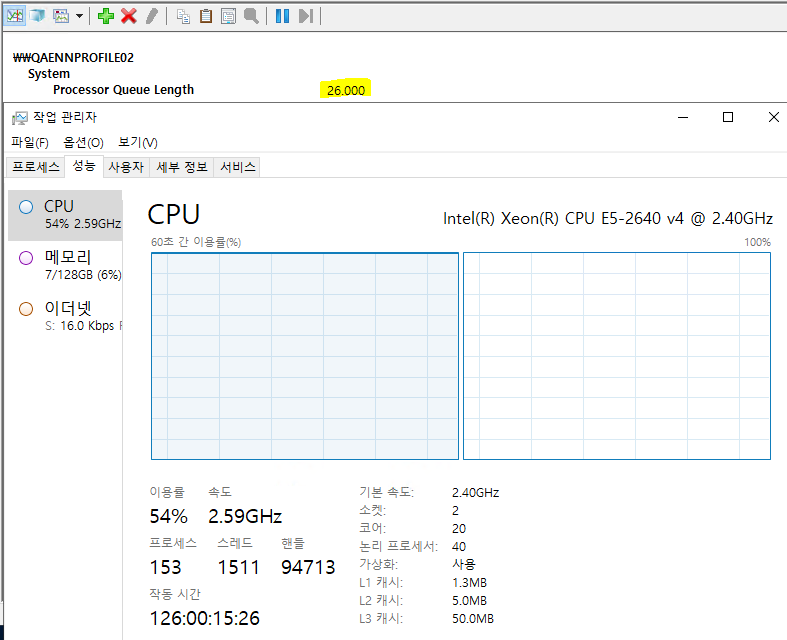
작업 관리자 화면 역시 첫 번째 테스트와 비슷합니다. 한쪽 노드만 100%를 사용 중이며 총 CPU 사용률은 50%입니다. 프로세서 대기열 길이는 ‘26.000’으로 높은 지연이 발생하고 있습니다.
노드 밸런싱 O/스레드 40
마지막으로, 노드 밸런싱을 활성화하고 스레드 값을 40으로 설정한 결과입니다.
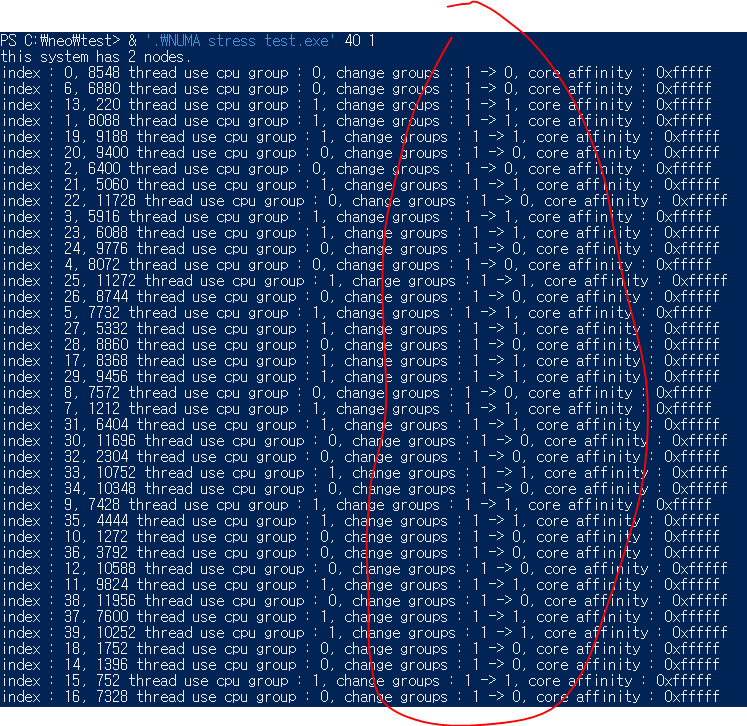
스레드가 CPU 그룹 0번과 1번에 분산됐습니다.
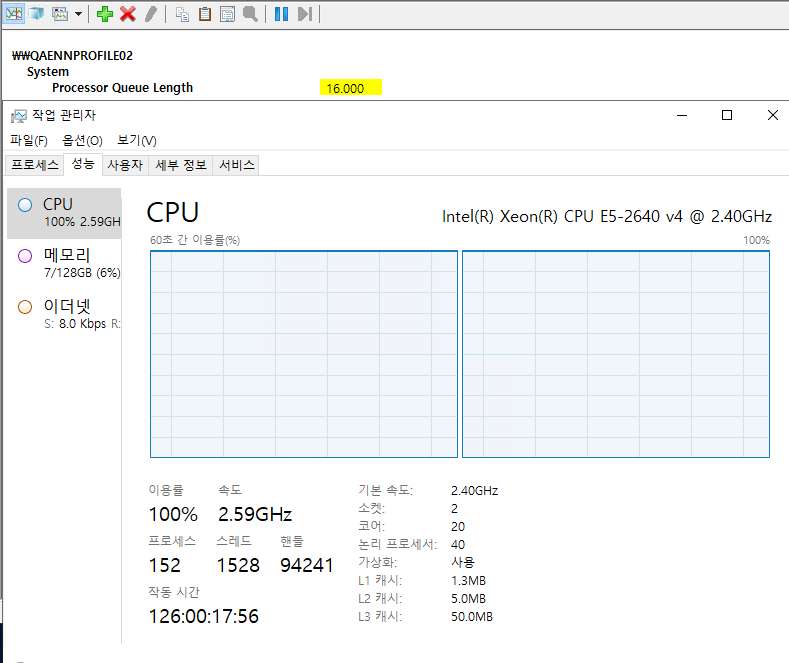
작업 관리자 화면을 보면, 양쪽 노드 모두 100%씩 사용 중이며 총 CPU 사용률은 100%입니다. 프로세서 대기열 길이는 ‘16.000’으로 높은 지연이 발생하고 있습니다만, 노드 밸런싱을 비활성화했던 세 번째 테스트보다는 낮은 지연을 보였습니다. 동일한 스레드 값에서 노드 밸런싱을 활성화한 것만으로도 확실한 차이가 생겼음을 알 수 있습니다.
단일 프로세스 방식으로 프로그래밍했더라도 앞서 미리 찾아봤던 윈도우 서버 API를 사용해 노드를 명시적으로 분배하면 CPU 쏠림 현상(노드 불일치 현상)을 해소할 수 있음을 확인했습니다.
단일 프로세스에서 NUMA 옵션을 최대한 활용하기 위해서는 설계 단계에서부터 고려해서 프로그래밍해야 합니다. 하지만 NUMA와 멀티 프로세스 방식은 상대적으로 설계 복잡성과 의도치 않은 예외 사항 발생 확률 상승효과를 가져올 수 있습니다. 또한, 개발사 대부분 개발 단계에서는 실제 론칭 인프라 환경을 미리 예상하기 힘들기 때문에 쉬이 고려 대상으로 선정해두기도 어렵습니다. (혹시라도 CPU 소켓이 1개인 고처리 머신을 구성하실 수 있다면, 단일 프로세스에서 높은 효율을 내리라 생각합니다.)
서버 애플리케이션은 주로 단일 프로세스로 구동하는 만큼, NUMA 옵션 자체를 비활성화하도록 Node interleaving 옵션을 활성화해 사용하실 것을 추천드립니다. MMO를 지향하는 대용량 서버는 메모리 사용률이 매우 높아, 성능에 적지 않은 영향을 준다는 것을 꼭 명심하셨으면 좋겠습니다.
<원문>
©️요즘IT의 모든 콘텐츠는 저작권법의 보호를 받는 바, 무단 전재와 복사, 배포 등을 금합니다.