개발
AWS로 클라우드 시작하기: ④S3 & CloudFront

8분
2022.03.04.6.8K
요즘, 많은 기업들이 채용 과정에서 클라우드 사용 경험을 요구하고 있습니다. 비즈니스 요구사항이 다변화되면서 자유롭게 서버를 확장/축소할 수 있는 클라우드가 많은 기업들에게 사랑받고 있습니다. AWS, GCP, NCP, Azure 등 다양한 클라우드 환경에서 가장 사랑받는 서비스를 꼽자면 AWS일 것 같습니다.
기존 온프레미스에 익숙한 개발자들에게 클라우드는 설정할 것들이 너무 많은 어려운 존재인데요. AWS를 처음 접하는 개발자들이 AWS를 친숙하게 이해하고, 클라우드 설계를 진행할 수 있도록 기초적인 내용을 전달하고자 총 6개의 시리즈로 아래와 같이 진행될 예정입니다.
S3는 Simple Storage Service의 약자로 AWS가 제공하는 클라우드 기반 객체 스토리지 서비스입니다. 일반적으로 클라우드 기반의 Storage는 크게 3가지 형태로 나눠집니다.
1) 파일 스토리지
2) 블록 스토리지
3) 객체 스토리지
AWS는 이중 블록 스토리지와 객체 스토리지를 중점적으로 제공하는데, S3를 이해하기 위해서는 각각의 스토리지 형태가 어떤 특징과 구조로 구성되는지 이해할 필요가 있습니다.
파일 스토리지는 일반적으로 윈도우, 맥과 같이 폴더와 파일을 기반으로 저장되는 구조의 스토리지입니다. 파일을 저장할 때, 파일을 저장할 폴더를 생성하고 해당 폴더의 경로와 파일을 함께 저장해, 여러 계층으로 구성된 폴더와 파일을 구성할 수 있습니다.
파일 스토리지는 폴더/파일 만으로 구성된 간단한 구조이기 때문에, 파일에 대한 정보 외에 부가적인 데이터(메타 데이터)를 함께 저장하기에는 제한적입니다. 또, 계층의 규모가 커질수록(=폴더가 많아질수록) 데이터의 탐색이 느려지고, 자원에 대한 요구가 많아집니다.
블록 스토리지는 블록(block) 단위로 데이터를 저장하는 스토리지 구조입니다. 블록 레벨 스토리지라고도 불리는 이 방식은 클라우드 환경에서 자주 사용되는 스토리지 구조입니다.
블록 스토리지는 데이터를 저장할 때 블록으로 분할한 후, 분할된 블록을 고유한 ID로 구분해 저장합니다. 이 과정에서 블록을 저장할 공간으로 가장 효율적인 스토리지 내 공간을 할당합니다.
데이터를 원본 그대로가 아닌 블록 단위로 분할하여, 독립적으로 저장하는 구조의 특성상 운영체제에 종속적이지 않게 데이터를 저장할 수 있는 장점이 있어, 운영체제 또는 환경을 자주 전환하는 클라우드 환경에서 선호되는 방식입니다. EC2를 생성할 때 저장공간으로 사용하는 EBS(Elastic Block Storage)가 대표적인 예시입니다.
또, 데이터 호출 시에 분할 저장된 블록들을 조합하여 데이터로 돌려주는 구조 덕분에 파일 스토리지에 비해, 탐색 시 더 빠른 효율을 보여줍니다.
반면, 블록 스토리지는 블록 단위로 분할하여 저장하는 그 특성상 스토리지 자체적으로 읽기/쓰기 등의 기능 수행이 불가하고, 파일 시스템과 유사하게 메타데이터를 관리하기 위한 수단이 제한적입니다.
오늘의 주인공 S3가 속한 객체 스토리지는 저장하는 객체(오브젝트) 단위 그 자체만으로 저장되는 평면적 저장 공간입니다. (평면적 = 계층 구조가 없음) 개별 데이터 단위를 데이터 유형의 제약 없이 저장하는 객체 스토리지 구조는 파일 시스템이나 색인 등의 일부가 아닌 데이터 자체로 저장되기 때문에 시스템에 독립적입니다. 또한, 스토리지 자체 권한 관리가 가능하며 개별 객체마다 권한을 부여할 수 있습니다.
블록 스토리지가 갖는 단점에 비하여 객체 스토리지는 데이터 그 자체로 독립적인 저장이 이루어지기 때문에 저장 공간에 대한 확장성이 무한하며(객체 단위로 독립적인 접근이 가능하며), 스토리지의 구조에 따라 다양한 메타 데이터를 객체와 함께 보관할 수 있습니다.
또, 블록 단위로 재조합하는 과정이 포함되지 않기 때문에, 엄청난 크기의 단일 데이터를 저장해야 하는 상황에서 유용하게 활용 가능합니다. 마찬가지로 파일 시스템에 의존적이지 않은 특성상 OS와 같은 시스템에 의존적이지 않습니다.
블록 스토리지와 다른 점은 저장된 데이터의 독립적인 url을 제공한다는 것입니다. 그 자체로 읽기/쓰기가 어려운 블록 스토리지에 비해 객체 스토리지는 저장된 객체 단위로 접근 가능한 경로가 제공되기 쉬운 구조이기 때문입니다.
S3는 위에서 언급한 대로 클라우드 기반의 객체 스토리지로써 저장되는 객체마다 독립적인 접근 경로, 권한, 메타데이터를 제공 및 구성할 수 있습니다.
AWS의 KMS 등을 통해 데이터를 암호화하여 특정 키로 관리되도록 할 수 있으며, 객체의 저장 공간에 정해진 크기가 없이, 필요한 만큼 데이터를 무한히 저장할 수 있습니다. 또, 메타 데이터를 다양한 형식으로 기록하여, 데이터의 백업, 아카이빙 등을 수동/자동으로 관리할 수 있고, 데이터의 접근 빈도에 따라 여러 등급의 스토리지에 나누어 관리할 수 있습니다.
대표적인 예시로 S3 Glacier가 있는데, 이름(빙하)에서 보이듯 자주 사용하지 않는 데이터를 S3 Glacier에 저장하면 엄청나게 적은 비용으로 클라우드 내에 데이터를 보관할 수 있습니다.
1) 처음 클라우드 환경 내 스토리지를 사용하게 되면 데이터 유실에 대한 우려가 있을 수 있습니다. S3는 표준 스토리지 기준 99.99999999%(9가 11개)의 데이터 보존을 제공합니다. 이는 100년이 지나도 10억 개 중 1개조차 손실되지 않는 데이터 보존력을 의미합니다. 또한, 객체 단위로 강한 복원력을 갖고 있어, 사용자가 실수해도 데이터의 복원이 가능합니다. (버전 관리 기능 활용 시)
2) 클라우드 스토리지를 쓰면 비용에 대한 걱정이 생길 수 있습니다. 일반적으로 I/O 성능과 저장공간에 따른 비용 청구가 이루어지는 파일/블록 스토리지와 다르게 S3는 저장된 데이터 공간만큼의 비용 청구가 이루어지며, CDN(CloudFront)와 연계하면 I/O 비용이 거의 발생하지 않습니다.
3) S3를 쓰면 아무나 우리 파일을 보게 되는 것 아닌가라고 우려할 수 있습니다. S3는 기본적으로 퍼블릭 액세스가 차단되며, 개발자가 원하는 경우 객체 단위로 접근을 허용할 수 있습니다. 또 객체 암호화 기능을 통해 객체가 노출되더라도 읽을 수 없도록 조치할 수 있습니다.
CloudFront는 S3와 함께 자주 사용되는 AWS의 CDN(Content Delivery Network)입니다. 데이터의 캐싱을 통해 AWS의 글로벌 인프라를 기반으로 실 사용자와 가장 가까운 서버에서 데이터를 전송해주는 글로벌 서비스입니다.
전 세계에 있는 AWS 데이터 센터마다 CloudFront의 Edge Server가 배치되어 있으며, 사용자가 데이터를 요청할 때 해당 사용자의 위치와 가장 가까운 Edge Server에서 데이터를 전달합니다.
일반적으로 Origin(EC2 또는 S3)의 데이터를 캐싱하여 Edge Server에 캐싱하고, 캐싱된 데이터를 실 사용자에게 반환하는 구조로 사용하며, S3나 EC2에서 데이터를 직접 제공하는 방식에 비해 훨씬 저렴한 금액으로 이용이 가능합니다. 특히, 데이터 캐싱을 위해 S3나 EC2에서 데이터를 호출하는 경우, 해당 캐싱에 사용되는 트래픽은 비용이 청구되지 않습니다. 또 최대 50GB에 까지는 데이터 전송 비용이 청구되지 않습니다.
일반적인 CDN과 같이 Download 방식과 Streaming 방식 모두를 제공하는데, 기본적으로 HTTP, HTTPS 프로토콜을 모두 지원하며, 스트리밍의 경우 RTS로도 제공 가능합니다.


S3와 CloudFront를 간단하게 알아보았습니다. 이제 실제로 두 서비스를 활용해서 정적 웹사이트를 배포하는 과정을 확인해보겠습니다. 정적 웹사이트 배포는 아래 과정을 거쳐 진행합니다.
S3 메뉴에 처음 들어오면, 버킷 메뉴가 있습니다.

생성된 S3 객체에 웹페이지를 업로드해보겠습니다. S3메뉴에서 생성된 버킷 이름을 클릭하고 업로드 버튼으로 파일을 업로드합니다.
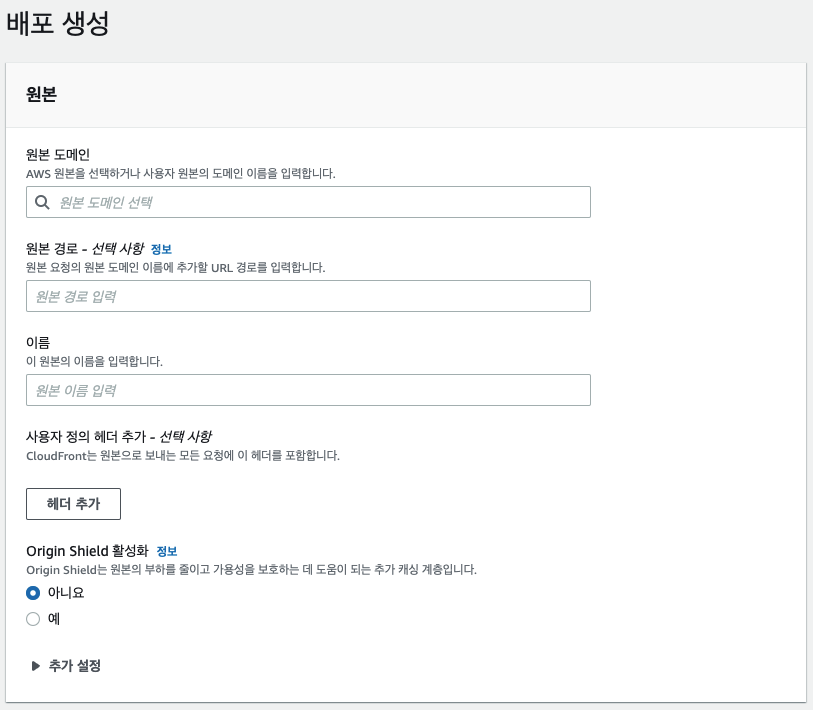

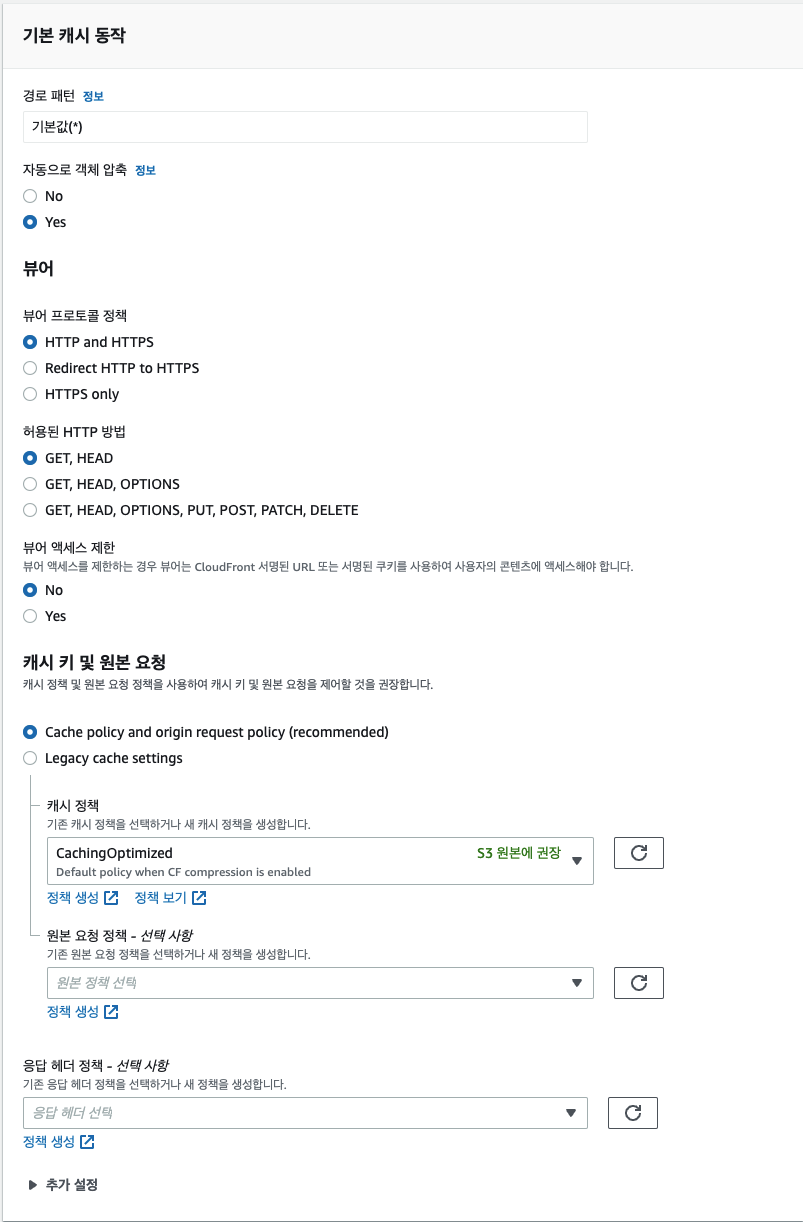
이 외에도 함수 연결(Lambda@Edge)나 설정 메뉴에서 CloudFront와 연계된 다양한 기능 설정이 가능합니다. 특히 설정 메뉴에서는 CNAME을 지정해, 정해진 도메인으로 연결하거나, SSL 인증서를 연결하여 HTTPS를 자체 대응하도록 설정할 수 있습니다.
이번 설정에서는 우선 CloudFront의 작동 확인을 위해 도메인 연결 없이 넘어가고, 다음 단계에서 도메인을 연결해보겠습니다.
생성된 CloudFront의 도메인 이름과, S3에 업로드한 정적 웹페이지의 파일명을 입력해 해당 주소로 이동할 수 있습니다.
생성 시 또는 수정 메뉴에서 기본값 루트로, 기본 html 파일 경로를 입력하면, 파일명을 url 뒤에 붙이지 않아도, 해당 파일이 자동으로 반환됩니다.

S3는 AWS를 사용하면 떼려야 뗄 수 없는, 특히 서비스를 운영할 때는 반드시 사용할 수밖에 없는 다재다능한 스토리지 서비스입니다. 단순 로깅부터, 유저 데이터, 미디어 파일, 정적 파일을 포함해 모든 종류의 파일을 보관할 수 있고, (버전 관리 기능 사용 시) 언제든 데이터를 복구할 수 있습니다.
CloudFront는 심플하게 또는 복잡하게도 사용 가능한 CDN으로 단순한 구조의 정적 웹사이트 배포에도 활용하지만, 글로벌 서비스 운영에 필수적인 기능입니다. 대부분의 경우 S3에 저장되는 파일이 내부에서만 쓰는 문서가 아니라면 S3는 대부분 CloudFront와 함께합니다.
특히 S3와 CloudFront가 조합된 상태에서의 콘텐츠 전달 속도와 관리 편의성은 개발자의 여러 걱정을 크게 덜어주는 중요한 경험이 됩니다. S3와 CloudFront는 대량 사용하더라도 다양한 방식으로 비용 절감이 가능하고 매달 50GB의 데이터 전송 이용료는 무료로 사용 가능하니 이번 기회에 스토리지와 CDN을 AWS로 옮겨보는 건 어떨까요?
©️요즘IT의 모든 콘텐츠는 저작권법의 보호를 받는 바, 무단 전재와 복사, 배포 등을 금합니다.