개발
프론트엔드 개발자라면 알고 있어야 할 브라우저의 동작 과정

12분
2022.02.22.47.9K
프론트엔드 개발자에게 있어 브라우저는 거의 모든 것과도 같습니다. 브라우저를 통해 개발을 하고, 브라우저를 통해 테스트와 배포를 진행하며, 최종 사용자들은 브라우저를 통해 웹 어플리케이션에 접속할 수 있습니다. 그만큼 프론트엔드 개발자에게 있어 브라우저란 뗄레야 뗄 수 없는 관계입니다.
하지만 그렇다고 해서 프론트엔드 개발자가 브라우저의 모든 원리에 대해 잘 알고 있는 것은 아닙니다. 브라우저들은 아주 많은 기능을 수행할 수 있는 복잡하고 고도화된 어플리케이션이기 때문입니다. 브라우저 내부에서 일어나는 모든 일들을 이해하는 것은… 너무나도 어렵습니다. 따라서 우리는 작성한 HTML, CSS, JavaScript가 의도한 대로 잘 동작하는지만 확인해도 크게 문제가 되지는 않습니다. 내가 원하는 비즈니스 로직을 작성하기에도 바쁘니까요.
하지만 복잡한 웹 어플리케이션을 만들어야 한다면 이야기가 달라집니다. 방대한 코드를 관리하고, 다양한 인터렉션을 수용할 수 있어야 하고, 화려한 애니메이션을 넣다 보면 결국 브라우저 단에서의 최적화가 필요해집니다. 하지만 브라우저의 동작 원리를 이해하지 않은 상태에서 내 어플리케이션을 최적화할 수는 없습니다. 결국 프론트엔드 개발자는 브라우저라는 플랫폼 위에서 동작하는 어플리케이션을 만드는 사람이니까요.
본 글의 전체 내용은 크게 네 문장으로 요약할 수 있습니다.
1. HTML로부터 DOM 트리를, CSS로부터 CSSOM 트리를 빌드합니다.
2. DOM 및 CSSOM을 결합하여 렌더 트리를 형성합니다.
3. 렌더 트리에서 레이아웃을 실행하여 각 노드의 기하학적 형태를 계산합니다.
4. 개별 노드를 화면에 페인트합니다.
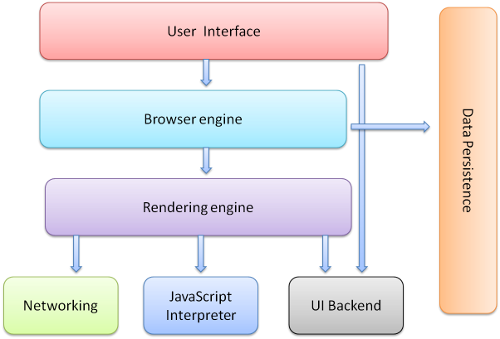
먼저 브라우저를 구성하고 있는 요소들에 대해 알아봅시다. 브라우저는 위의 다이어그램과 같은 여러 단계의 레이어로 구성되어 있습니다.
위에서 보시다시피 각 레이어에서 하는 역할은 정말 다양하고 복잡합니다. 하지만 프론트엔드 개발자의 입장에서 봤을 때, 렌더링 엔진은 우리의 어플리케이션이 직접 동작하는 레이어인 만큼 눈여겨볼 필요가 있습니다. 따라서 지금부터는 렌더링 엔진 레이어에 대해서 좀 더 깊게 알아보도록 하겠습니다.
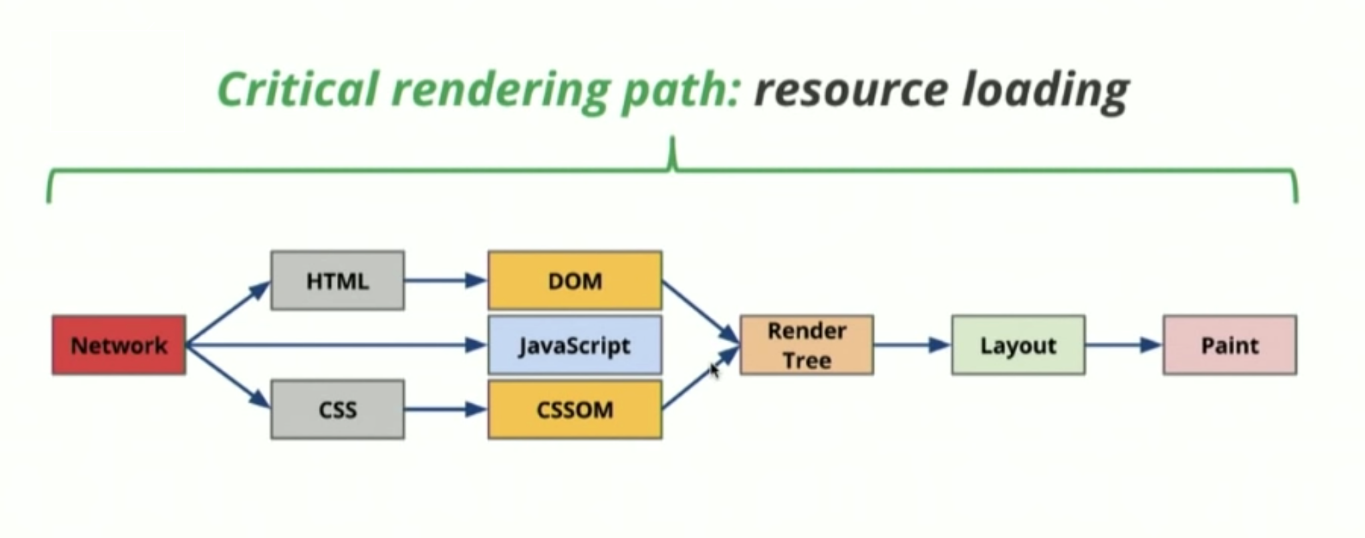
우리가 어떠한 웹 페이지에 접속하게 되면, 네트워크를 통해 해당 웹 페이지의 HTML 문서를 얻어올 수 있습니다. 그러면 렌더링 엔진은 위의 다이어그램과 같은 과정을 거쳐 읽어 들인 HTML 문서를 해석합니다. 브라우저 엔진마다 해석 방식이 조금씩 다를 순 있지만, 크게 다음과 같은 네 단계로 이루어져 있다고 봐도 무방합니다.
위에서 이야기한 모든 과정들을 일컬어 우리는 중요 렌더링 경로(Critical Rendering Path)라고 부릅니다. 각 단계에서 리소스를 로드하는 순서나 작성한 스크립트의 내용에 따라 웹 페이지의 반응 속도가 달라질 수 있습니다. 이러한 과정의 최적화를 통해 프론트엔드 개발자는 렌더링에 걸리는 시간을 개선시키고, 사용자 경험을 방해하지 않을 수 있습니다.
지금부터는 중요 렌더링 경로의 각 단계에 대해 자세히 알아보도록 하겠습니다.
파싱(Parsing)은 토큰화(Tokenize)된 코드를 구조화하는 과정을 말합니다. 이러한 파싱 과정을 전문적으로 해주는 부분을 파서(Parser)라고 부릅니다.
파싱 과정은 입력받은 문자열이 정해진 문법(Grammar)들을 모두 따르는지를 확인하는 과정입니다. 각 문법은 어휘(Vocabulary)와 문법 규칙(Syntax rule)으로 구성이 되어 있는데요. 어휘는 알파벳이나 한글처럼 사용할 수 있는 단어와 그 조합들을 의미하며, 문법 규칙은 어휘 사이에 적용될 수 있는 규칙들을 의미합니다. 가령 숫자의 계산에서 곱하기는 앞뒤로 정수가 와야 하고, 더하기보다 더 높은 우선순위를 갖고 있는 것 같은 규칙들처럼요.
브라우저는 HTML, CSS, JavaScript 세 종류의 언어를 해석할 수 있습니다. 그중에서 JavaScript는 렌더링 엔진 레이어가 아니라 JavaScript 해석기라는 별도의 레이어에서 언어를 해석합니다. 따라서 렌더링 엔진에서는 HTML과 CSS를 파싱합니다.
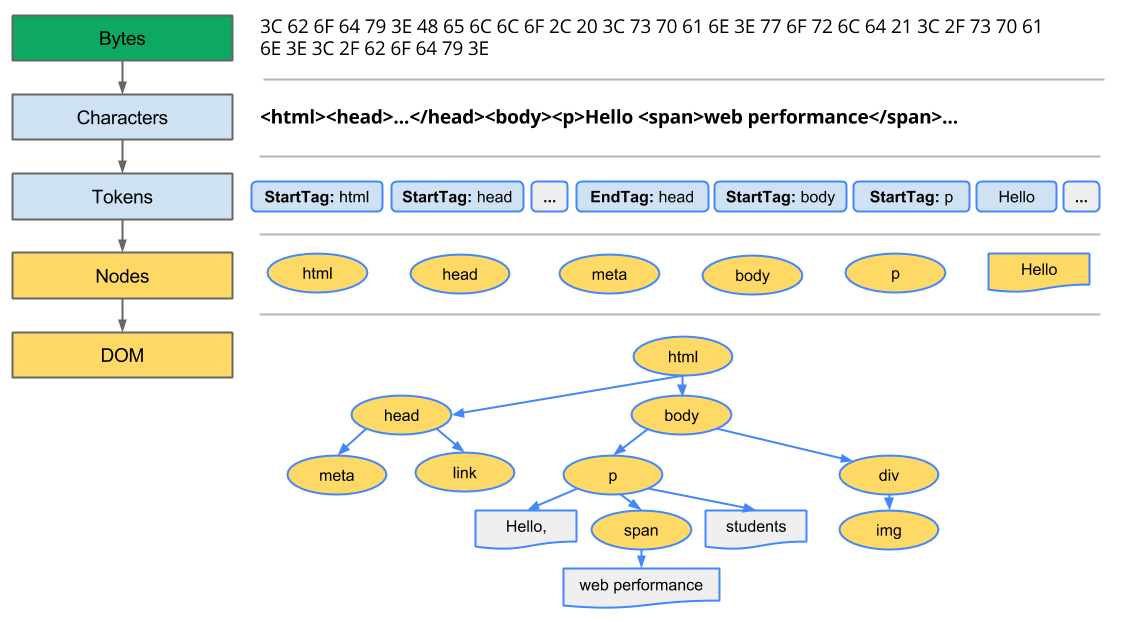
브라우저는 위에서 이야기한 토큰화 된 HTML의 문자열들을 이용해 파스 트리(Parse Tree)를 생성합니다. 파스 트리는 브라우저가 읽어야 할 HTML 코드를 트리 모양으로 구조화하여 나타낸 것입니다.
이러한 파스 트리를 이용해서 바로 렌더를 할 수 있을까요? 그렇지 않습니다. 브라우저는 파스 트리를 이용해 DOM(Document Object Model) 트리를 새로 만들기 때문입니다. 그렇다면 두 트리의 차이점은 무엇일까요?
파스 트리는 토큰화 된 문자열을 단순하게 구조화한 트리에 불과했지만, DOM 트리는 우리가 실제로 상호작용할 수 있는 HTML 엘리먼트로 이루어진 트리입니다. 따라서 우리가 실제로 JavaScript로 상호작용할 수 있는 부분은 DOM 트리죠.
한편, HTML 파서는 다른 파서와 비교했을 때 조금 독특한 특징을 갖고 있습니다. HTML 파서의 첫 번째 특징은 오류에 너그러운(forgiving nature) 속성입니다. 다시 말해, HTML을 파싱하는 도중 어떠한 에러가 발생한다면, 브라우저는 자체적으로 에러를 복구하려 합니다. 아래와 같은 HTML 코드를 생각해봅시다.
<body>
<p class=highlight>Hello
<div><span>World
위 예제는 제대로 작성되지 않은 HTML 코드를 나타냅니다. 최상단에 <html> 태그를 쓰지 않았고, <body>, <p>, <div>, <span> 태그 같은 경우에는 닫는 태그를 작성하지 않았습니다. 또한 클래스 어트리뷰트를 쌍따옴표로 묶어주지도 않았죠. 하지만 이 HTML 코드를 실제로 브라우저에서 실행시켜보면 다음과 같이 완성된 코드가 나옵니다.
<body>
<p class="highlight">Hello</p>
<div><span>World</span></div>
</body>
이러한 규칙들은 HTML Document Type Definition (DTD)에 의해 정의되고 있습니다. HTML 파서는 명세된 규칙들을 따르는 예외 처리를 따로 해주어야 합니다. 그리고 이는 일반적인 파서의 규칙만으로는 적용하기가 어렵습니다.
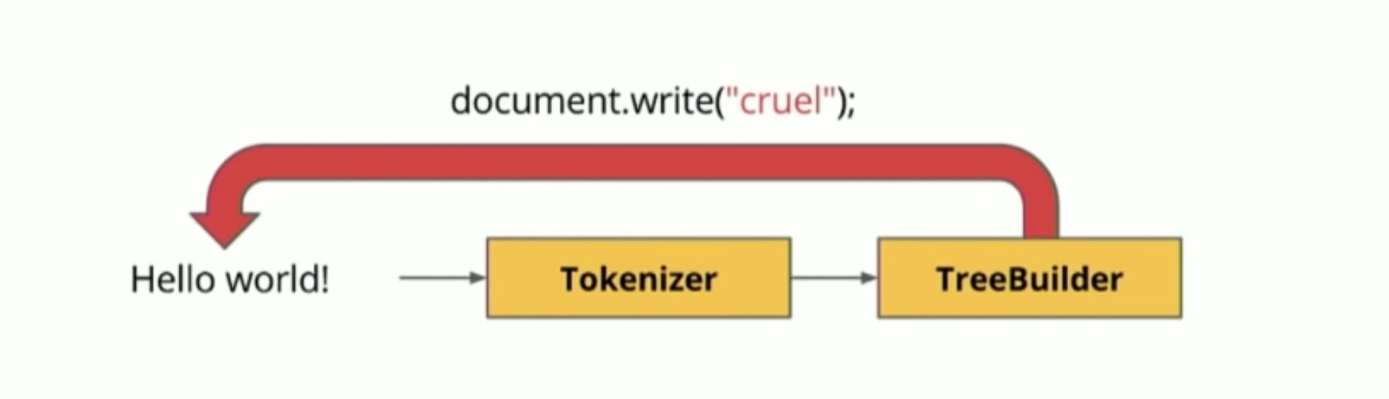
HTML 파서의 두 번째 특징은 파싱 과정이 중단될 수 있다는 것입니다. HTML은 파싱 도중 <script>, <link> 같은 외부 태그를 만나게 되면 HTML 파싱을 즉시 중단합니다. 그리고 해당 태그의 해석을 실행하죠. 만약 해당 태그가 외부 파일을 참조하고 있다면 다운로드를 한 후 해석을 시작합니다.
이는 네트워크를 통해 먼저 받아온 코드부터 해석을 실행할 수 있는 HTML과는 달리 외부 콘텐츠들은 증분적(Incrementally)으로 해석을 할 수 없기 때문입니다. 또 다른 이유는 <script>에 DOM을 직접 수정할 수 있는 내용이 있을 수도 있기 때문입니다. 가령 document.write() 같은 API를 사용하면 HTML을 파싱하고 있는 도중에도 DOM 엘리먼트를 동적으로 삽입할 수 있습니다. 이로 인해 외부 콘텐츠를 해석하고 실행하기까지 HTML의 파싱은 중단됩니다. 이러한 문제점을 해결하기 위해서 스크립트 같은 경우에는 별도의 옵션을 제공합니다.
HTML 파서의 세 번째 특징은 재시작(Reentrant)입니다. 위에서 말한 것처럼 HTML의 파싱 과정은 어떠한 외부의 요인으로 인해 방해받을 수 있습니다. 파싱 중간에 외부의 요인으로 인해 DOM이 추가, 변경, 삭제될 수 있습니다. 이러한 경우에 HTML은 처음부터 다시 파싱 과정을 거칩니다. 즉, 바이트를 문자로 변환하고, 토큰을 식별한 후 노드로 변환하고 DOM 트리를 빌드합니다. 이 때문에 처리해야 할 HTML이 많을 때에는 파싱 시간이 오래 걸릴 수 있습니다.
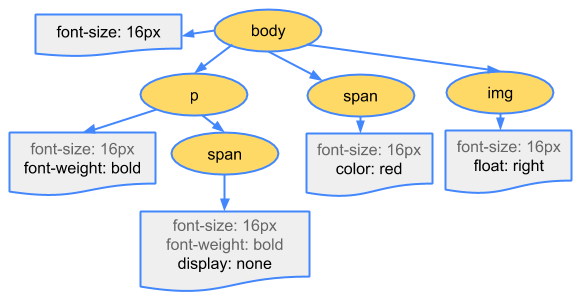
한편 CSS 파싱은 공식적인 명세가 있기 때문에, 파싱 과정이 HTML에 비해 그렇게 복잡하지는 않습니다. 일반적으로 CSS을 링크하는 코드가 HTML 코드 내에 삽입되어 있기 때문에, HTML을 파싱하는 도중에 CSS 파싱이 시작됩니다. 네트워크를 통해 먼저 받아온 코드부터 해석을 실행할 수 있는 HTML 파서와는 달리, CSS 파서는 전체 파일을 모두 다운로드할 때까지 파싱을 시작할 수 없습니다.
전체 CSS 파일을 다운로드한 후 CSS 파싱 과정이 끝나게 되면, 코드에서 명세한 내용과 순서를 바탕으로 DOM과 같은 트리를 구성하는데 이를 CSSOM(CSS Object Model) 트리라 부릅니다. 이 트리에는 스타일, 규칙, 선택자 등의 정보가 노드에 들어가게 됩니다.

한편, 위에서 이야기한 DOM 트리가 구성되는 동안 브라우저는 렌더 트리(Render Tree)를 구성하기 시작합니다. 동의어로는 프레임 트리(Frame Tree)라고도 합니다.
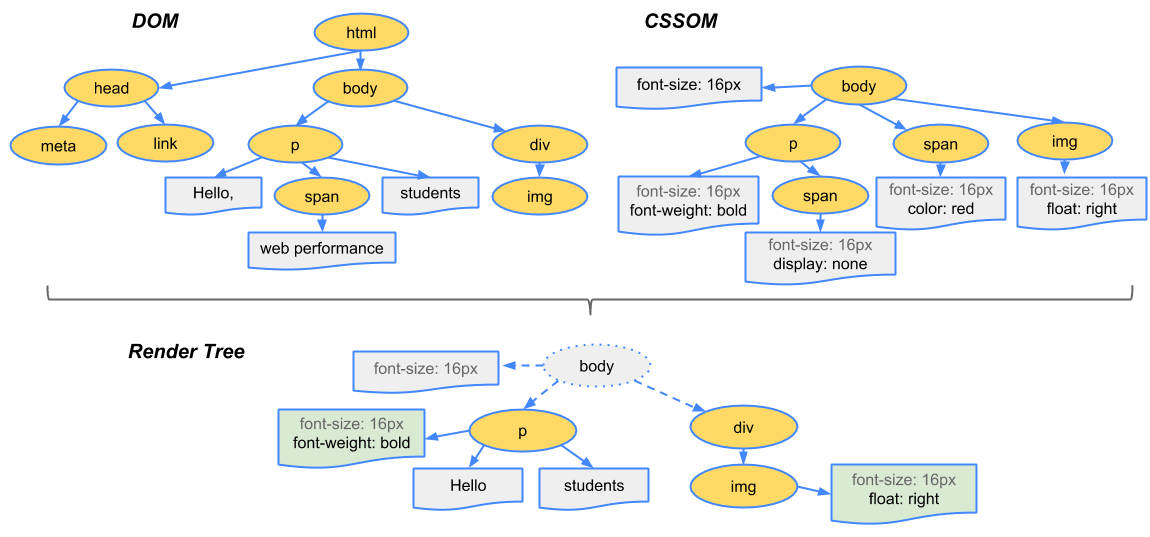
렌더 트리는 기본적으로 화면에 나타나는 요소들을 결정하는 트리입니다. 즉, 어떠한 요소들이 보여야 하는지, 어떤 스타일이 적용되어야 하는지, 그리고 어떤 순서로 나타낼 것인지를 명세하는 트리죠.
렌더 트리는 DOM 트리와 CSSOM 트리를 조합하여 만들어지고, 이때 화면에 그려지지 않는 요소들은 트리에 나타나지 않습니다. 가령 <head>, <script> 같은 태그나 display: none 스타일이 적용된 엘리먼트가 있겠죠. 이러한 태그는 시각적으로 나타낼 것이 없기 때문에 렌더 트리에 그려지지 않습니다. 즉 렌더 트리는 DOM 트리와 정확하게 1:1로 매칭이 되지는 않습니다.
렌더 트리 구성이 끝나면 레이아웃 단계가 이어집니다. 모질라에서는 이 과정을 리플로우(reflow)라고 부르기도 합니다.
레이아웃 단계에서는 렌더 트리에서 계산되지 않았던 노드들의 크기와 위치, 레이어 간 순서와 같은 정보를 계산하여 좌표에 나타냅니다. 이 과정은 HTML의 루트 오브젝트로부터 재귀적으로 실행이 됩니다.
이 과정을 시각적으로 잘 나타낸 영상이 있어 소개해드리고자 합니다.
한편, 레이아웃은 계산의 범위에 따라 전역적 레이아웃(Global Layout)과 증분적 레이아웃(Incremental Layout)으로 구분할 수 있습니다.
전역적 레이아웃은 말 그대로 화면 전체의 레이아웃을 계산하는 것입니다. 가령 새로운 폰트를 적용하거나, 폰트 사이즈가 바뀌거나, 뷰포트의 사이즈 변경 같은 경우가 있을 때 전체 레이아웃을 다시 계산합니다. offsetHeight 같은 일부 DOM 관련 JavaScript API에 접근을 하는 경우에도 전역적 레이아웃이 다시 계산되기도 합니다.
이러한 전역적 레이아웃 단계는 모든 렌더 트리 노드에 대해 기하학적인 계산을 수행하기 때문에, 노드가 많아지게 된다면 그 속도가 느려지게 됩니다. 따라서 브라우저에서는 자체적인 최적화 로직을 탑재하고 있습니다.
그중 하나가 바로 더티 비트 시스템(Dirty bit system)입니다. 더티 비트 시스템은 특정 엘리먼트의 레이아웃이 변경이 되었을 때, 렌더 트리를 처음부터 탐색하면서 레이아웃을 계산하지 않고 특정한 부분만 다시 계산하여 리소스의 낭비를 줄이는 최적화 방법입니다.
증분적 레이아웃은 이러한 더티 비트 시스템을 활용합니다. 레이아웃 과정에서 렌더 트리를 재귀적으로 탐색을 하다가 더티한 엘리먼트들, 즉 레이아웃의 변경이 발생해야 하는 엘리먼트들을 만나게 되면, 그 계산을 즉시 수행하는 것이 아니라 스케쥴러를 통해 비동기로 일괄 작업(batch)을 진행합니다. 이를 통해 연산의 횟수와 범위를 줄일 수 있습니다.
하지만 아주 복잡한 레이아웃의 경우에는 브라우저 단에서의 최적화만으로는 충분하지 않기 때문에, 프론트엔드 개발자 역시 레이아웃 과정의 연산을 최소화하도록 신경을 써야 합니다. 때문에 브라우저처럼 행동하는 것이 필요합니다. DOM의 레이아웃과 관련된 값을 직접 읽어오거나 변화를 주는 JavaScript 코드를 작성해야 한다면, 그러한 구문들을 최대한 묶어야 합니다.
const divWidth = div1.clientWidth;
div2.style.width = `${diwWidth}px`;
const divHeight = div1.clientHeight;
div2.style.height = `${divHeight}px`;
위의 코드는 div1이라는 태그의 너비와 높이 값을 읽어와 div2의 인라인 스타일에 적용하는 방식으로 DOM을 직접 수정하는 코드입니다.
위에서 언급한 바와 같이, 브라우저는 더티한 레이아웃이 발생할 때마다 증분적 레이아웃을 수행하기 위해 레이아웃 계산을 스케쥴러에 등록합니다. 위의 코드는 div2의 너비를 변경한 후 다시 div1의 높이를 불러오기 때문에, 두 과정 사이에서 발생했을 수도 있는 레이아웃의 변경 때문에 불필요한 계산이 추가됩니다. 즉, 레이아웃 관련 값을 읽어오는 부분과 레이아웃을 수정하는 코드가 혼용되었기 때문에 최적화 관점에서 문제가 됩니다.
따라서 위 코드는 아래와 같이 수정함으로써 계산 과정을 줄일 수 있습니다.
const divWidth = div1.clientWidth;
const divHeight = div1.clientHeight;
div2.style.width = `${diwWidth}px`;
div2.style.height = `${divHeight}px`;

마지막 단계는 페인트 단계입니다. 페인트 단계는 말 그대로 레이아웃 단계를 통해 화면에 배치된 엘리먼트들에게 색을 입히고 레이어의 위치를 결정하는 단계입니다. 이 단계 역시 루트 오브젝트로부터 재귀적으로 실행이 됩니다. 또한 레이아웃과 마찬가지로 페인팅에도전역적 페인팅과 증분적 페인팅이 있습니다.
즉, 문서가 클수록 브라우저가 수행해야 하는 작업도 더 많아지며, 스타일이 복잡할수록 페인팅에 걸리는 시간도 늘어납니다. 예를 들어, 단색은 페인트하는 데 시간과 작업이 적게 필요한 반면, 그림자 효과를 적용하면 그것을 계산하고 페인트 하는데 시간과 작업이 더 필요합니다.
페인팅에는 그 순서가 있는데, 이는 z-index 축을 이용한 쌓임 맥락(Stacking context)과도 일맥상통합니다. 때문에 z-index가 낮은 순서대로 먼저 페인팅이 됩니다.
한편 CSS 페인팅 명세에 따르면 블록 단위에서의 페인팅 순서는 다음과 같습니다.
따라서 만약 background-color와background-image 가 함께 세팅되어 있고, background-image로 설정한 외부 리소스의 크기가 크다면 background-color를 먼저 보게 될 것이고, 나중에 이미지가 완전히 로드된 후 background-image로 교체가 될 것입니다.
한편, 글을 마무리하기 전에 오늘 정리한 내용을 바탕으로 가상 DOM(Virtual DOM)의 출현 배경에 대해서도 이야기를 꺼내볼 수 있을 것 같습니다. React와 Vue를 써 보신 분이라면 분명 들어봤을 용어일 텐데, 이 가상 DOM이라는 단어를 들어봤어도 등장 배경에 대해 제대로 이해하지 못하고 쓰는 경우도 많을 것입니다.
일반적으로 중요 렌더링 경로는 초당 60회 정도의 주기로 계산을 수행합니다. 이때 가장 비용이 많이 드는 단계가 바로 레이아웃 단계와 페인트 단계입니다. 때문에 성능 최적화를 위해서는 두 단계에서의 연산을 최소화하는 것이 중요합니다.
JavaScript를 이용해 DOM을 직접 조작하면, 변경 사항이 있을 때마다 잠재적인 레이아웃 단계와 페인트 단계를 초래하게 됩니다. 만약 10개의 DOM 노드를 for 문으로 일일이 수정하게 되면, 하나의 노드에 수정 사항이 생길 때마다 화면을 다시 그리는 과정을 거쳐야 할 수 있습니다. 즉 10개를 한 번에 수정하는 것이 아니라, 하나씩 수정된 노드가 10번에 걸쳐서 다시 화면에 그려질 수 있다는 이야기입니다. 때문에 일반적으로 DOM을 직접 조작하는 것은 비용이 크다고 이야기하죠.
한편 가상 DOM은 실제로 렌더링 되지는 않았지만, 실제 DOM 구조를 반영한 상태로 메모리에 있는 가상의 DOM입니다. 메모리 상에 있고, 실제 화면에 그려요 할 필요는 없기 때문에 실제 DOM보다는 연산 비용이 적습니다. 가상 DOM은 이러한 특징을 바탕으로 위에서 말한 변경 사항들을 한 번에 묶어서 실제 DOM에 반영을 합니다. 물론 레이아웃 단계와 페인트 단계에서 한 번에 변경되어야 하는 사항은 많아집니다. 대신 단 한 번의 계산만으로도 바뀐 DOM을 적용할 수 있기 때문에 연산의 횟수는 최소한이 됩니다.
사실 이 과정은 DOM에 변경사항을 유발하는 스크립트를 묶어서 실행하는 방법으로도 가능합니다. 하지만 가상 DOM을 사용함으로써 이 과정을 모두 자동화할 수 있고, 개발자는 관리할 포인트를 줄일 수 있습니다. 이러한 가상 DOM을 사용하는 대표적인 라이브러리, 프레임워크가 바로 React와 Vue입니다.
오늘은 브라우저의 동작 원리 중에서도 브라우저의 렌더 과정에 대해 알아보았습니다. 이번 글을 통해 브라우저의 렌더 과정에 대한 원리가 궁금한 프론트엔드 개발자 분들께 도움이 되었기를 바랍니다.
<참고 자료>
©️요즘IT의 모든 콘텐츠는 저작권법의 보호를 받는 바, 무단 전재와 복사, 배포 등을 금합니다.