기획
실험 조직으로 거듭나기: ① 실험 툴(tool) 도입하기

9분
2021.10.21.7.4K
이런 분들께 이 글을 추천합니다. 그로스(Growth)와 실험 문화를 팀에 도입하고 싶은 분, 가설 검증을 하려는데 시작부터 막막하신 분, 데이터보다는 직감에 의존하시는 분. 이 중 하나라도 해당된다면 재밌게 읽을 수 있습니다. 오늘은 실험 조직으로 거듭나기 1편으로, 실험 환경을 만드는 과정을 살펴보겠습니다.
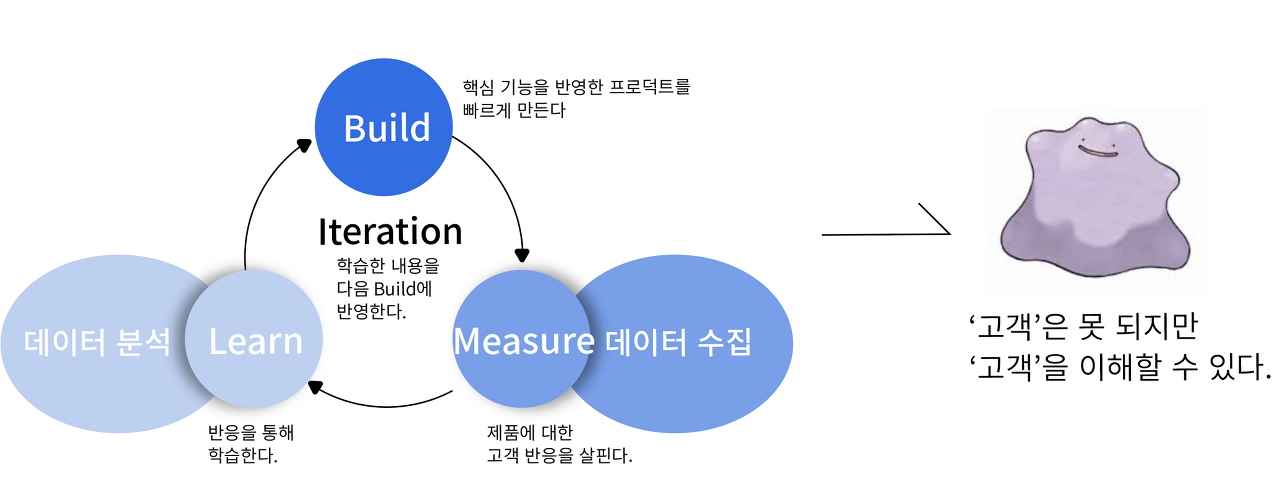
린 모델의 핵심, 고객으로부터 배운다.
'좋은 프로덕트는 고객이 구매한다'는 절대불변의 진실이다. 이때, '좋은 프로덕트'는 '우리'가 아니라, '고객'이 정의한다. 아무리 좋은 프로덕트라고 우리가 생각해도 고객이 별로라고 말한다면 프로덕트는 팔리지 않는다. 따라서, 고객의 시선에서 프로덕트를 만들고 평가해야 한다. 하지만, 아무리 노력해도 '우리'는 생산자이기 때문에 소비자인 '고객'이 될 수 없다.
그래도 걱정하지 말자! 우리가 고객이 될 수 없을지라도 고객과 비슷한 존재는 될 수 있다. 마치 상대의 행동을 보고 그대로 따라 하는 메타몽처럼 고객 피드백과 인사이트를 통해 '고객'을 엿볼 수 있다. 스타트업이 지향하는 '린(Lean) 모델'이 등장하게 된 배경도 이와 같다. 린 모델의 핵심 개념은 '학습(Learn)'에 있다. 처음부터 고객을 100% 이해할 수 없으니, 아예 프로덕트를 작게 먼저 만들고 고객에게 테스트하자는 식으로 접근 방식이 바뀌었다. 이렇게 테스트를 반복하면서 고객에 대해 학습하고 궁극적으로 고객의 생각을 엿볼 수 있게 된다.
고객 데이터, 영양가 높은 귀중한 학습 재료죠
아무것도 없는 상태에서 학습은 일어나지 않는다. 학습이 일어나기 위해선 정보와 인사이트라는 학습 재료가 필요하다. 이전까지 전혀 몰랐던 사실, 새롭게 알게 된 정보나 인사이트 등이 모두 학습을 위한 재료가 된다. 린 모델에서 프로덕트를 빠르게 만들어서 배포하는 이유도 학습에 사용할 데이터를 얻기 위함이다.
어떤 학습 재료를 사용하느냐에 따라 학습 퀄리티가 달라진다. 정보와 인사이트가 가치가 있을수록 더 좋은 학습이 일어난다. 반대로, 아예 잘못됐거나 근거 없는 정보는 차라리 없는 게 낫다. 학습은 그대로 다음 프로덕트에 반영되는데, 어떤 학습 재료를 사용했느냐에 따라서 프로덕트의 방향이 전혀 달라지기 때문이다. 만약 잘못된 정보로 학습한다면, 엉뚱한 프로덕트가 탄생한다.

올바른 고객 데이터에 집중해야 한다. (출처 : man vs wild)
"데이터는 거짓말을 하지 않는다"라는 말처럼, 데이터는 어떤 현상이나 상황을 객관적이고 솔직하게 보여준다. 따라서, 모든 학습은 근거를 갖고 있는 데이터에 기반을 둬야 한다. 이때 '이번에 만든 프로덕트'의 데이터가 메인이 돼야 한다. 몇 달 전의 데이터나 경쟁사의 정보 등은 참고할 수 있으나, 메인이 돼서는 안 된다. 현재의 고객을 이해하기 위해선 현재의 데이터에 가장 집중해야 한다.
스타트업에 관심 많은 사람이라면 '실험'이란 단어를 자주 들어봤을 것이다. 린 모델을 이해하면, 스타트업이 왜 그렇게 실험을 좋아하는지 알 수 있다. 프로덕트는 (1) 고객이 겪는 문제를 찾고, (2) 이를 해결하는 아이디어가 구체화된 끝에 탄생한다. 그리고, 좋은 프로덕트는 고객이 실제로 겪는 '진짜 문제'와 이 문제를 잘 해결하는 '진짜 아이디어'에 뿌리를 둔다. 그렇다면, 문제 및 아이디어가 진짜인지 아닌지 언제 알 수 있을까? 답은 '고객에게 보여주는 순간'이다.
'우리'는 '고객'이 될 수 없다. 문제나 아이디어를 정의할 때도, 관련 데이터를 참고해 "고객은 이런 문제를 갖고 있지 않을까?" "이 아이디어가 고객의 문제를 잘 해결할 수 있지 않을까?"라고 추측할 뿐이다. 즉, 모든 문제와 아이디어는 고객에게 검증받기 전까지 참/거짓을 모르는 가설일 뿐이다.
직접 봐야지 알 수 있다. (출처 : KOSMOS)
실험(Experiment)은 '가설이나 이론이 실제로 들어맞는지를 확인하는 일'을 의미한다. 문제 및 아이디어 가설을 고객에게 검증하는 린 스타트업에게 실험은 떼려야 뗄 수 없는 일이다. 린 스타트업은 반복적인 실험으로 많은 가설 검증을 진행하고, 매 순간 학습을 통해 올바른 방향을 찾는다. "우리가 이번에 설정한 문제 가설을 검증해보니 진짜 문제가 아니었어! 그렇다면, 다른 문제에 집중해보자" "아이디어 가설이 문제를 잘 해결했는데? 이 아이디어를 더 디벨롭하자" 이렇게 [학습 - 제품 개선]의 이터레이션(Iteration)이 반복되어가면서, 진짜 문제와 아이디어를 찾아나갈 수 있다.
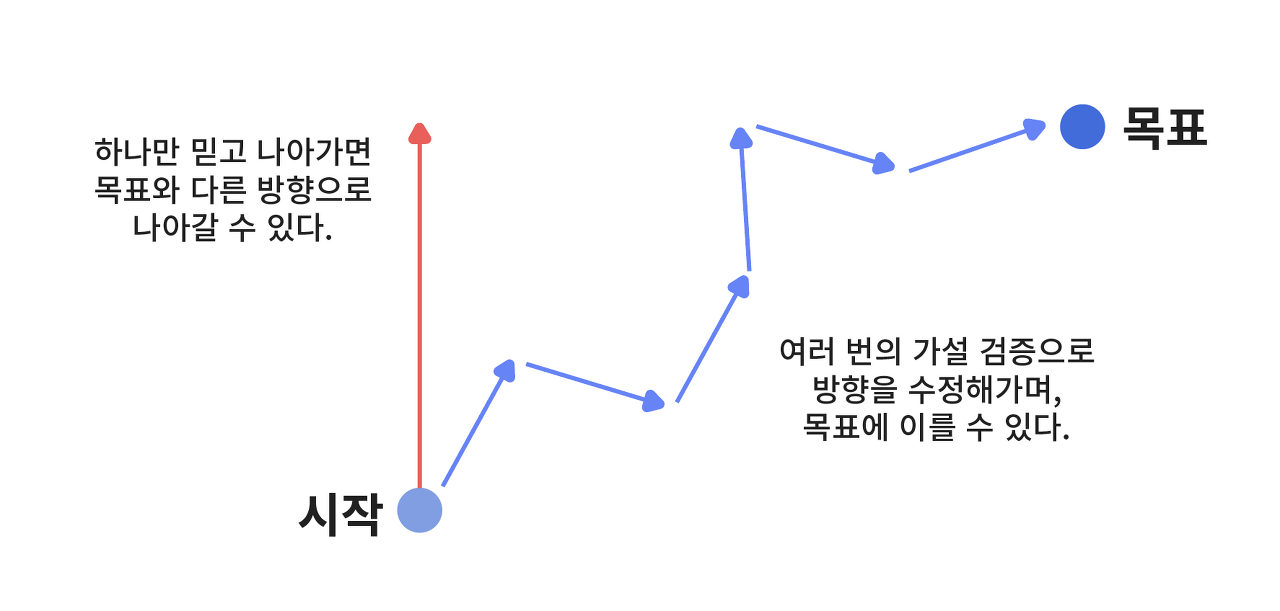
수많은 가설 검증을 통해 목표에 가까워질 수 있다.
이터레이션(Iteration)을 강조하는 린 모델에선 새로운 기능이 빠르게 만들어지고 다시 사라진다. 이때, 새로운 기능이 고객에게 정말 유효한지 알기 위해선, 이를 검증하는 실험 환경을 매번 만들어야 한다.
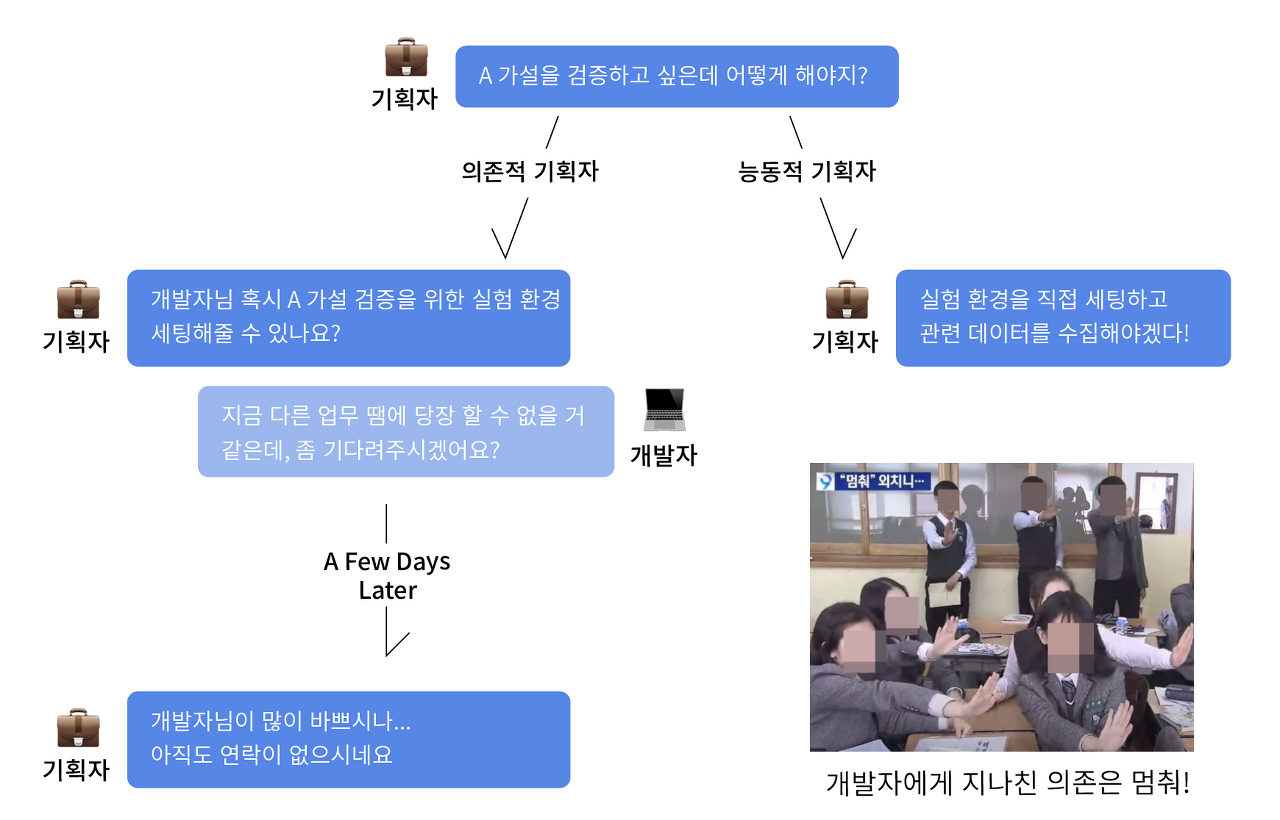
'실험 환경'은 '가설을 검증할 수 있는 관련 데이터를 수집할 수 있는 환경'을 뜻한다. 막상 '데이터 수집'이라 하니 코딩이 필요할 것 같고, 개발자가 없으면 아예 못할 것 같은 느낌이 든다. 근데 새로운 기능이 구현될 때마다 개발자에게 찾아가 실험 환경을 만들어 달라고 할 수 있을까? 개발자가 업무가 많아서 지금 바로 못해준다면? 기획자는 모든 태스크의 선두 주자다. 기획을 시작해야 디자인 작업물이 나오고 개발 결과물이 나올 수 있다. 기획자가 개발자에게 지나치게 의존을 하면, 시작부터 병목이 발생하는 꼴이다.
과거에는 개발자가 직접 데이터를 수집하는 환경을 하나하나 만들어야 했다. A 버튼과 B 버튼을 유저가 눌렀는지 확인하기 위해서 각각에 맞는 코드를 추가해야 했다. 하지만, 데이터 툴이 점점 발전하고 인프라가 구축되면서 상황이 바뀌었다. 이제 코드 단의 입력 없이도 데이터를 수집할 수 있는 실험 환경을 만들 수 있다. 즉, 기획자가 능동적으로 실험을 진행해볼 수 있다.
시중에 다양한 데이터 툴이 존재하는데 이들 모두를 사용한다면 매우 큰 관리 비용이 든다. 반대로, 사용하는 툴이 적다면 가설 검증을 위한 데이터를 충분히 수집하지 못할 수 있다. 따라서, 실험 환경은 '가설을 검증할 데이터를 충분히 수집할 수 있는 정도'일 때 적당하다. 이를 위해 주로 사용하는 툴을 소개하고자 한다.
Google Analytics!
설정한 가설을 검증하기 위해선 데이터를 봐야 한다. 그렇다고 기획자가 데이터 애널리틱스 수준으로 로우 데이터를 뜯어볼 필요는 없다. 대신 가설을 검증할 수 있는 수준으로 데이터를 보고 이해하는 것으로 충분하다.
망고 플레이트를 크롤링해서 얻은 데이터들. 이런 로우 데이터 분석은 데이터 애널리틱스한테 맡기자!
Google Analytics(이하, GA)는 고객 데이터를 수집하고 시각화하는 툴이다. 데이터 툴의 작동 과정은 대략 아래와 같다.
GA는 유저가 어떤 페이지 방문했고, 각 페이지에 얼마나 머무르는지 등 페이지 단의 데이터를 생성 및 전송한다. 그리고 수집한 데이터에 다양한 기준을 적용해 보여준다. 유저의 유입 패턴(ex. 어떤 유저가 방문했는가? 이 유저가 얼마나 주기적으로 방문하는가?)이나, 행동 패턴(ex.유저가 어떤 페이지에 주로 관심을 가졌는가?, 얼마나 사이트에 머무르다가 갔는가?) 등과 같이 말이다. 또한, 세그먼트 설정을 통해 서로 다른 유저 집단 별로 데이터를 확인할 수도 있다.
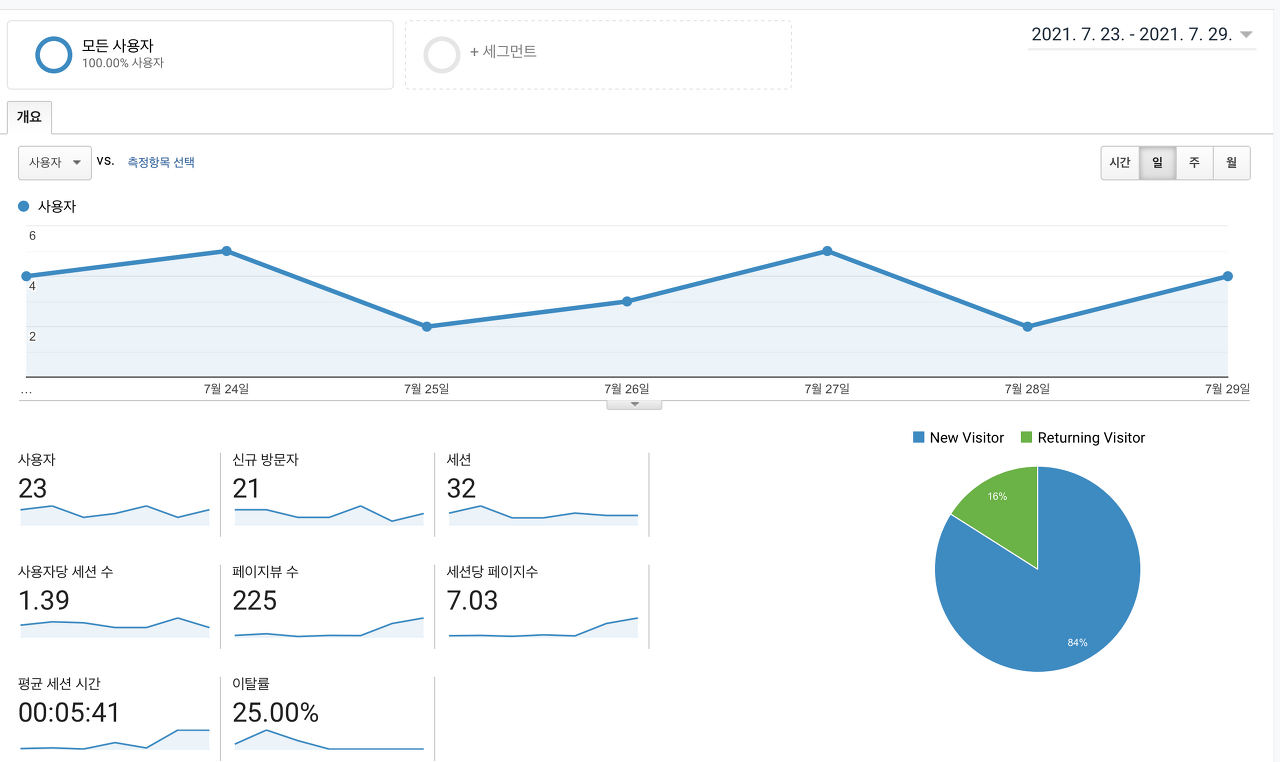
혼자 진행하는 사이드 프로젝트에 적용한 GA 화면이다. 유저 유입 및 행동 데이터를 볼 수 있다.
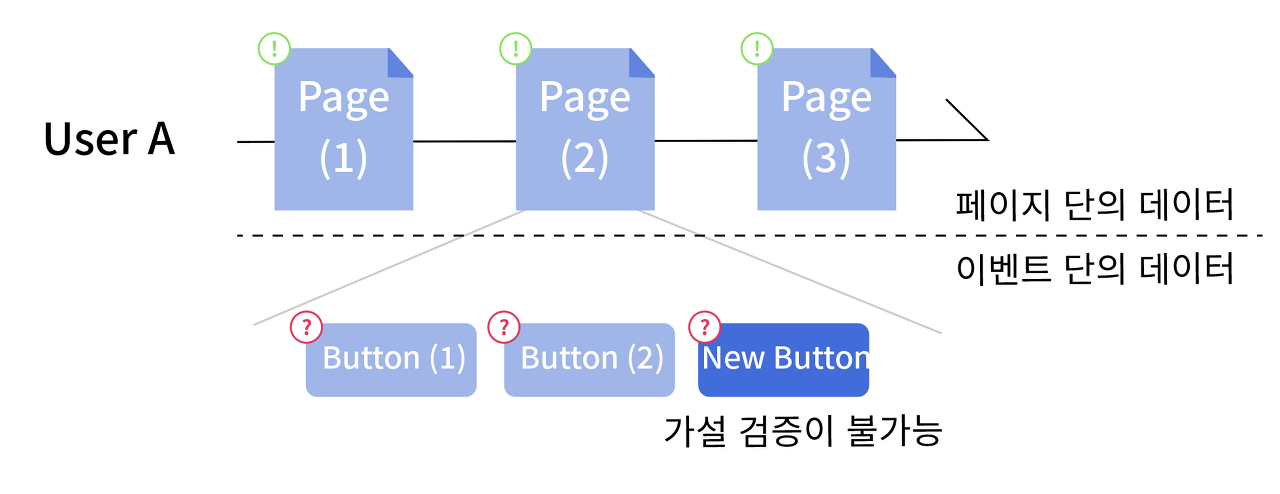
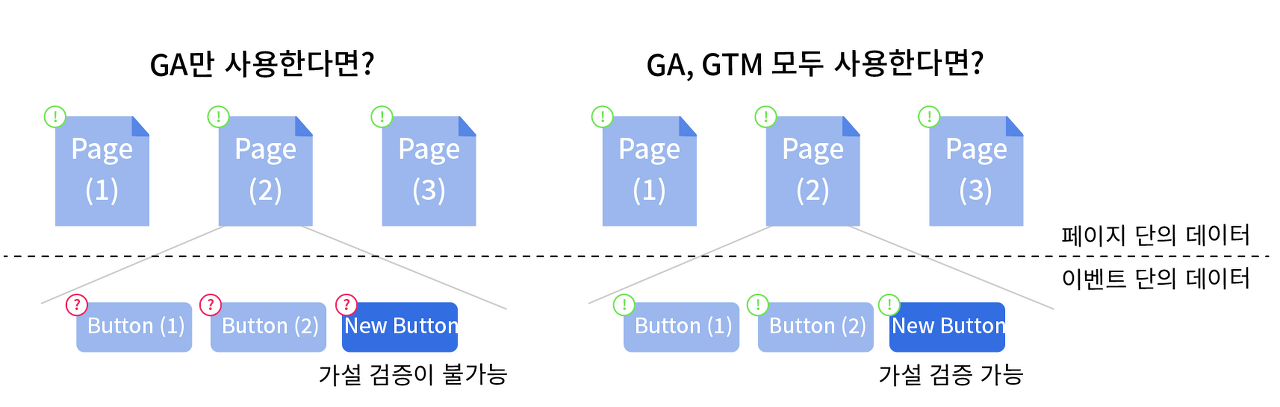
여기까지 보면 GA만으로 모든 게 가능할 것 같다. 하지만, GA만 사용한다면 충분한 실험 환경을 만들지 못한다. 왜냐하면, GA는 페이지 단의 데이터만 생성하기 때문이다. 즉, 이벤트 단의 데이터를 생성하지 못하는 한계가 있다. 물론 GA4.0은 일부 이벤트 트래킹이 가능하나 생략하겠다.
이해를 돕기 위해 예를 들어보자. GA만 있다면 유저가 어떤 페이지에 방문했는지 알 수 있다. 하지만, 페이지에서 어떤 버튼을 눌렀는지는 알지 못한다. '페이지 방문'은 페이지 단의 데이터지만 '버튼 클릭'은 이벤트 단의 데이터이기 때문이다. GA는 이벤트 단의 데이터를 생성하지 못하므로 애초에 수집할 데이터조차 없는 셈이다. 따라서, GA만으로 실험 환경이 충분하다고 말하기 어렵다. 가설을 검증하기 위해선, 더 심도있는 유저 행동 데이터가 필요하다.
Google Tag manager
앞선 GA의 한계를 보완하기 위해 Google Tag manager(이하, GTM)가 함께 사용한다. GTM은 GA가 생성하지 못하는 이벤트 단의 데이터를 대신 생성 및 전송한다. 이 덕분에 유저가 어떤 버튼을 클릭했는지, 페이지에서 얼마나 스크롤했는지 등 더 세부적인 유저 행동을 측정할 수 있다. 이렇게 측정한 데이터는 GA를 통해 확인할 수 있다.
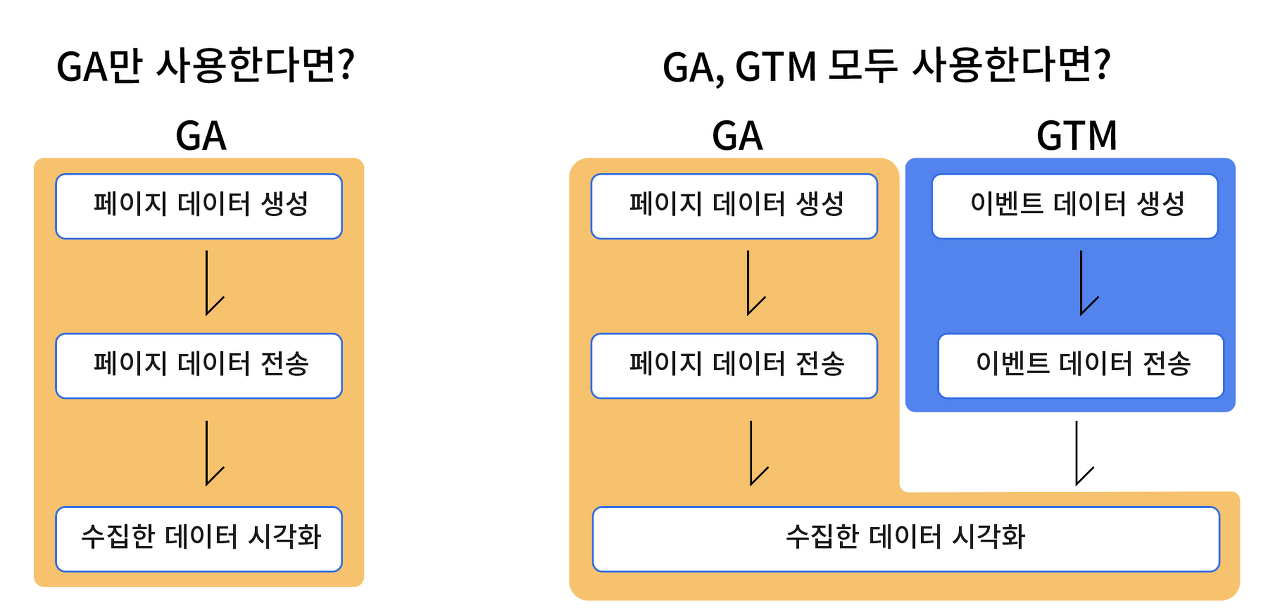
이쯤 되면 GA와 GTM의 관계가 헷갈릴 수 있으니 다시 한번 정리해보자. 결론부터 말하자면 GA가 데이터 수집 툴이라 한다면, GTM은 데이터 생성 툴에 가깝다. 데이터 툴의 원리는 아래와 같다. GA는 (1) 페이지 단의 데이터를 생성 및 전송하고, (2) 전송받은 데이터를 모두 수집해서 보여준다. 여기서 '모두'라는 표현이 중요한데, GA는 자신뿐 만 아니라 다른 데이터 툴이 생성한 데이터도 모두 보여줄 수 있다. (ex) google search console, GTM etc
GTM은 GA처럼 데이터를 수집하고 보여주지 못한다. 그 대신 GA가 생성하지 못하는 이벤트 단의 데이터를 생성할 수 있다. 따라서, GTM이 GA에게 자신이 생성한 데이터를 전송하고, GA는 이를 수집해 시각화한다. 결과적으로, GA는 수집한 모든 데이터(GA가 자체적으로 생성한 페이지 단의 데이터 + GTM이 생성한 이벤트 단의 데이터) 모두를 보여준다.
Google Optimize
넷플릭스의 랜딩 페이지 AB 테스트를 한 번쯤 들어봤을 것이다. 넷플릭스는 여러 개의 버튼 문구 중에서 어떤 게 유저가 가장 많이 누르는지 실험을 진행한다. 이처럼 문구를 어떻게 설정하는지에 따라서 유저의 반응이 크게 달라질 수 있다.
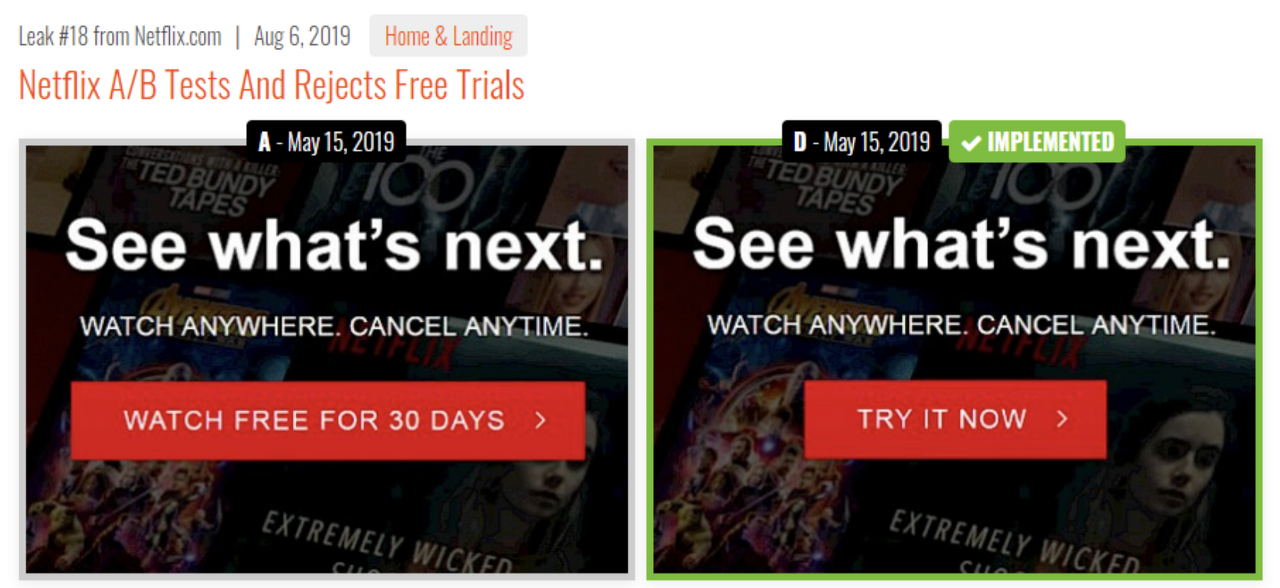
왼쪽은 '30 days'를, 오른쪽은 'now'를 강조한다. (출처 : Digital Native Magazine)
이러한 AB 테스트를 코딩 없이 진행할 수 있게 하는 툴이 Google Optimize다. Google Optimize에서 서로 다른 실험 안(=케이스)을 만들기만 하면, 알아서 유저에게 랜덤으로 보여주고 결과를 측정해준다. 문구, 버튼, GNB 등 페이지를 구성하는 각 요소(element)의 구성, 위치와 디자인 등 AB 테스트를 진행해볼 수 있다.
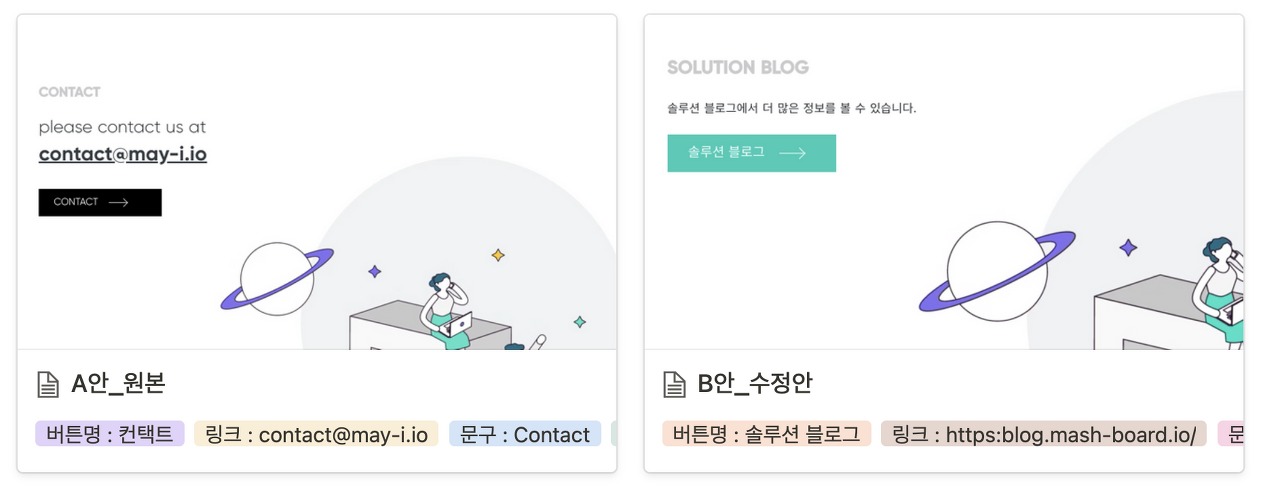
뿐만 아니라, 아예 특정 요소가 있을 때와 없을 때를 두고 AB 테스트를 진행할 수도 있다. 메이아이에선 홈페이지 들어온 유저의 컨택을 늘리는 걸 목적으로 AB 테스트를 진행했다. A안으로 '이메일을 바로 입력하는 창'을, B 안은 '성함 / 이메일 / 회사 정보 등을 입력하는 타입 폼으로 이동하는 버튼'을 설정했다.
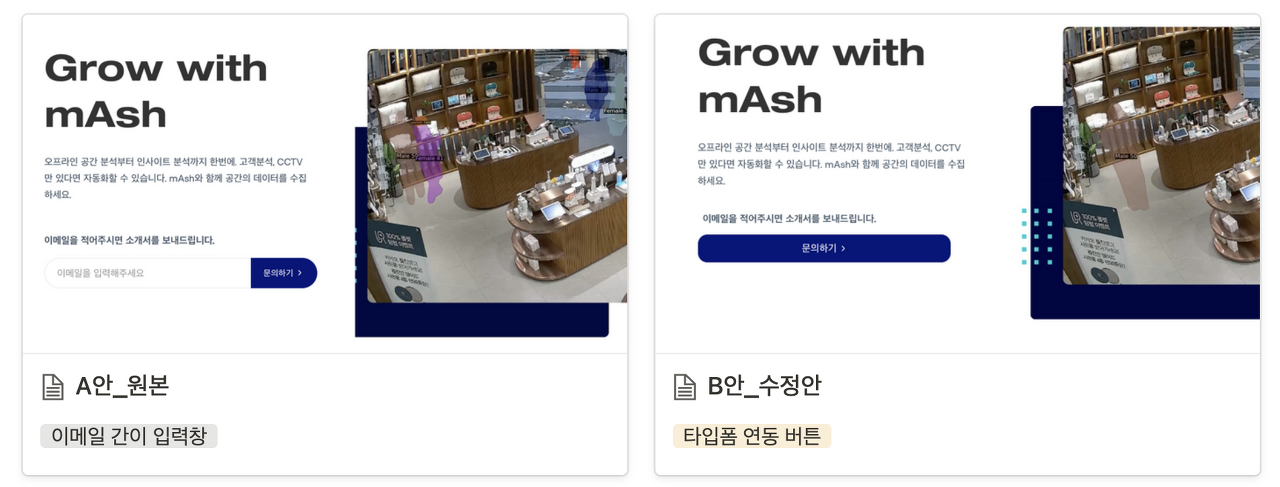
메이아이에서 진행한 이메일 입력창 vs 버튼 AB 테스트. 다양한 실험을 빠르게 진행한다.
Hotjar
Hotjar는 사이트에 접속한 유저가 어떻게 행동하는지를 녹화해서 보여주는 툴이다. GA가 수집한 데이터를 숫자로 보여주는 데 반해, Hotjar는 아예 영상을 보여준다. 유저가 어떻게 프로덕트를 사용하는지 직접 눈으로 보면서 더 깊은 인사이트를 얻을 수 있다. 대신 녹화물을 하나하나 보기엔 오랜 시간이 걸리므로, 보통 GA로 수치를 확인한 후에 더 깊은 분석이 필요할 때 Hotjar을 사용한다.
예를 들어보자. 가격 정책 페이지로 이동하는 버튼을 새롭게 추가했고 이에 대한 고객 반응을 보려고 한다. GTM을 활용하면 이 버튼을 몇 명의 고객이 눌렀는지 알 수 있다. 하지만, 이 버튼을 누르기 직전과 직후의 정보를 얻기 어렵다. 가령 어떤 유저는 가격 정책 페이지로 이동하자마자 다시 뒤로 돌아갈 수 있고, 또 다른 유저는 가격 정책 페이지에서 계속 머무를 수도 있다. 이때 Hotjar를 통해 유저의 실제 행동이 어떤지 알 수 있다.
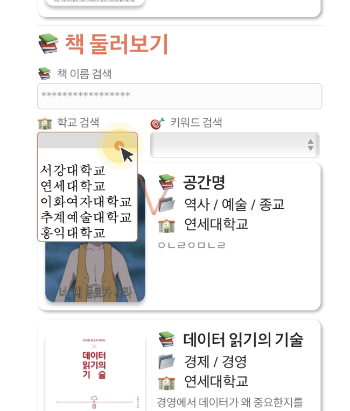
혼자 진행하는 사이드 프로젝트에 적용한 Hotjar 화면이다. 마우스의 흔적을 확인할 수 있다.

배울 게 너무 많다!
위에서 다룬 데이터 툴을 도입하면 최소한의 실험 환경을 완성했다고 볼 수 있다. 하지만, 이건 시작일 뿐이다. 실험 환경을 만드는 일은 가설 검증을 위한 기초 공사를 한 것일 뿐이다.
'실험 환경을 만드는 일'과 '가설을 검증하는 일'은 엄연히 다르다. 제 아무리 고객 데이터를 잘 수집해도, 이 데이터를 분석 및 활용하지 못한다면 데이터는 의미가 없다. 즉, 실험 환경은 가설을 검증할 때 비로소 가치를 갖는다. 이제 실험 환경 만들었으니 다음 글에서는 가설을 세우고 검증하는 방법에 대해 알아보겠다.
<참고 자료>
©️요즘IT의 모든 콘텐츠는 저작권법의 보호를 받는 바, 무단 전재와 복사, 배포 등을 금합니다.