







이미 사용 중인 스크랩북 이름입니다.
다른 이름을 지정해 주세요.
사용성 평가나 설문 조사 그리고 인터뷰와 같은 사용자 조사는 고객 관점에서의 사업 기회 발굴과 디자인 개선에 대한 인사이트를 제공해 줍니다. 그렇지만 단순히 사용자 조사로 수집된 데이터만으로 의미 있는 정보를 제공해 주지는 않는데요. 그 속에 감추어진 의미 있는 정보를 파악하기 위해서는 수집된 데이터 특성에 맞는 적합한 분석을 진행하고, 이를 시각화하는 과정이 필요합니다. 이번 글에서는 객관적인 의사결정을 도와주는 정량적 데이터를 어떻게 분석하고, 시각화할 수 있는지에 대해 살펴보도록 하겠습니다.


모수란 무엇일까? 의외로 많은 사람이 ‘모수’를 ‘모집단’의 수라고 생각한다. 그러면 모집단이란 무엇일까? 물어보면 ‘전체 집단’이라고 한다. 전체 집단은 무엇일까? 그냥 ‘전체 회원’이라고 생각한다. 하지만 ‘전체 집단’을 정의하는 것은 그렇게 간단하지 않다. 이 서비스에서 전체 회원이 매일 들어오지 않는다면, 하루의 회원 활동 스냅샷을 가지고 모집단이라고 할 수 없다. 그러면 전체 회원이 다 들어오는 그날까지의 데이터를 모으면 모집단일까? 그 기간까지의 모든 회원의 형태는 항상 동일할까? ‘모집단’ 개념은 그래서 매우 간단한 듯하면서도 의외로 복잡하고 추상적인 면이 있다.


필자가 경험한 바에 의하면 많은 조직이 데이터 드리븐(Data Driven)이라는 명목하에 단순히 데이터를 뽑아보고 참고만 하거나, 기본적인 데이터 지식도 없이 잘못된 해석을 통해 의사 결정을 하는 경우가 많았다. 그중에서도 대표적으로 데이터의 상관관계와 인과관계를 혼용하여 사용하는 경우가 많다. 그럼 상관관계와 인과관계는 무엇일까? 이번 글은 데이터 기반의 조직에서 알아야 하는 상관관계와 인과관계에 대한 개념을 알아보고, 기획자로서 최소한의 데이터 분석 지식을 겸비하여 올바른 의사 결정을 할 수 있도록 돕고자 한다.


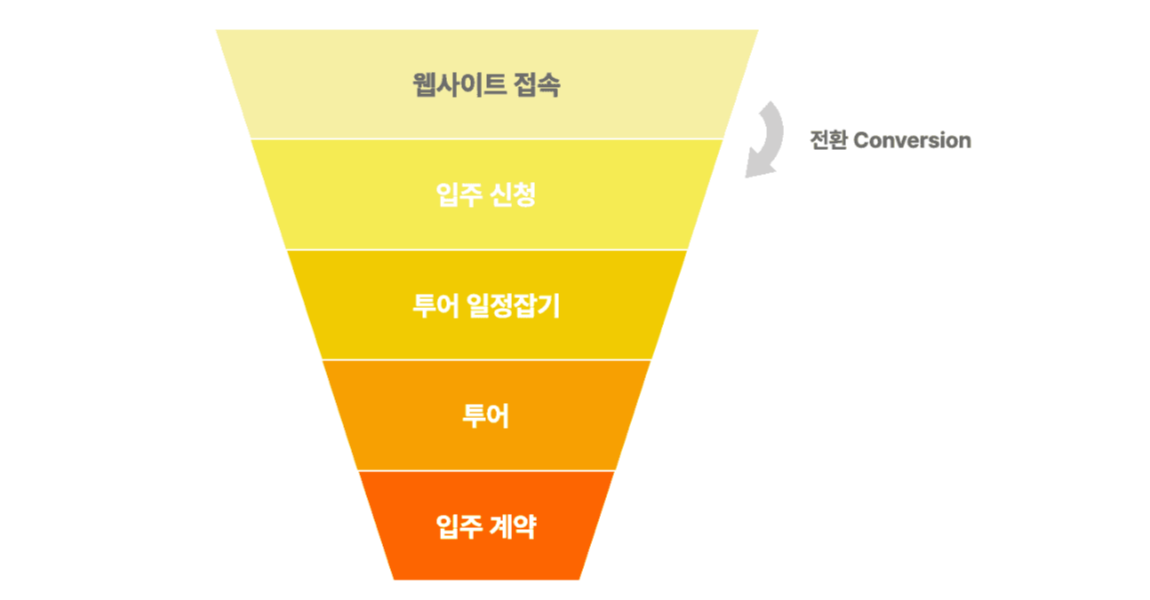
안녕하세요. 데이터리안의 민주입니다. 오늘은 퍼널을 개선하는 방법에 관해 얘기해 보려 합니다. 저는 데이터 분석가로 일하기 전에 ‘셰어하우스’라는 스타트업 창업했던 경험이 있습니다. 처음 셰어하우스를 오픈했더니 입주 경쟁률이 10:1이었습니다. 그런데 시간이 지나면서 점점 입주 경쟁률이 떨어지기 시작했고, 남는 방이 생기는 지경까지 왔습니다. 여러분이라면 이 상황을 어떻게 타개할 수 있을까요? 할인? 후기 이벤트? 아니면 셰어하우스 근처에서 전단지라도 나눠보면 될까요? 이럴 때 퍼널 분석을 사용하면 구체적으로 현상을 파악하고 개선할 수 있습니다.